概要
トピックモデルとしてLDAを使い、Livedoorニュースのレコメンドを実装してみました。
技術的には、
- プログラミング言語として
Python3 - トピックモデル/レコメンドのメインライブラリとして
gensim - 日本語の処理(言語処理)のために
Mecab
を利用しています。
LDAについて詳しい解説はネット上にたくさんあるので、そちらに解説を譲ります。この記事での主眼は、トピックモデルを使ってみる、ということとレコメンドまで実装してみる、という2点にあるので、それ以外の情報を知りたい方は他のコンテンツを見ることを推奨します。
英語ですが、すごくわかりやすく解説してくれている動画があります。(youtubeに飛びます)
トピックモデルとは?
手法概要
- トピックモデルは自然言語処理の分野で用いられる統計的洗剤意味解析の一つ。
- 「トピックモデル」というモデルがあるわけではなく、解析手法の名称。トピックモデルの手法としていくつかやり方がある。
- 教師なし学習
使われ方
- ある記事を見た人に別の記事をレコメンドする、といったことに使われる。
この手法が生まれたモチベーション
- ある記事を見た人に同じトピックを持つ別の記事をレコメンドしたい、というモチベーション。ECサイトでは、同じような商品をレコメンドしていますが、ニュースサイトでは似たような記事をレコメンドしたい。
トピックモデル(LDA)の直感的な理解
文書に含まれる単語を基に、トピック所属確率を計算してくれる

トピックモデルの手法
トピックモデル界隈の主なプレイヤーは下図の通りです。今回は、記事タイトルにあるように"LDA"を使います。ちゃんと調べたわけではないですが、LDAがトピックモデルで最もメジャーな手法なのではないかと思います。

今回実行するタスク
今回はLivedoorニュースのデータを使い、次の4つのタスクを実行することにします。
| No. | タスク内容 | 検証ポイント |
|---|---|---|
| ① | 9つのカテゴリのデータを突っ込んで最適なトピック数はいくつなのか見てみる | 筆者が直観的に判断したトピック数(“5”)と合致するかどうか? |
| ② | ①ではじき出された最適なトピック数がそれぞれどういうトピックになっているか? | 人間が解釈しやすいかどうか? |
| ③ | 新規のデータを突っ込んで見たときにちゃんとトピックを判定できるか? | ②でわかったトピックっぽい文章を手動で用意して、それのトピックをLDAに判定してもらう。正しく判定できるか? |
| ④ | ターゲットとなる文書を指定して、それに近しい文書をピックアップさせる。その文書が人間の感覚で近しい文書かどうか? | 特定文書の類似文書を選ばせて(=レコメンド)、どれくらい正確な結果となるか? |
①:トピックモデルでは、何個のトピックにするかを分析者が決定する必要があります。この時、テキトーにトピック数を指定するのではなく、指標があるので、それを見ながらトピック数を決めます。検証ポイントとしては、筆者がLivedoorニュースを見て直感的に判断したトピック数"5"と一致するかどうかを検証します。
②:①で決定したトピックがちゃんと人間が理解しやすいトピックに分割できているかどうかを確認します。分析者が定性的に確認します。
③:①②の結果を見て、新しいテキストデータを入力させたときにトピックモデル(LDA)がちゃんとトピックを識別できているかどうかを確認します。
④:ここがいわゆるレコメンドのパートです。ターゲットとなる文書を指定した時に類似したトピックの文書トップ10を表示させます。
利用するライブラリ
下の4つをメインに使っています。他にも利用しているライブラリはありますが、それらはコード中に記載しているので、そちらを確認してください。
gensim
Mecab
pandas
wordcloud
ライブラリの入れ方(Mecab以外)
Mecab以外は、pipで入れることができます(Mecabの入れ方については後述)。
pip install gensim
pip install wordcloud
Mecabの入れ方
※GoogleColaboratoryという無料のサービスを今回は使います。
MecabのWindowsへの入れ方は結構クセがあると思うので(初心者には難しいと思います)、今回は簡単にMecabを入れることができるGoogleColaboratoryというサービスを使います。
(Googleアカウントを持っているのであれば、無料で使えます。)
Mecabの入れ方ですが、下のコマンドを入れてください(コピペすれば動くはずです)。
# 形態素分析ライブラリーMeCab と 辞書(mecab-ipadic-NEologd)のインストール
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
!pip install mecab-python3 > /dev/null
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
!pip install mojimoji
コードと実行結果
コードの流れとしては、「まずはコード実行までの下準備、データをDLし、データの概要を把握します。そのあと、タスクNo.に沿ってタスクを検証させていく」という形で作成しています。
LDA実行までの下準備
まずは、GoogleColabからGoogleドライブ上のデータを扱えるように設定。
from google.colab import drive
drive.mount('/content/drive')
Mecabのインストール
# 形態素分析ライブラリーMeCab と 辞書(mecab-ipadic-NEologd)のインストール
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
!pip install mecab-python3 > /dev/null
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
!pip install mojimoji
日本語でワードクラウド表示できるようにフォントの読み込みを実施。
# フォント読み込み
!apt-get -y install fonts-ipafont-gothic
必要なライブラリのインポート。
# 各種ライブラリのインポート
import os
import re
import pandas as pd
import pickle
import urllib
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import math
# for文の進捗確認に便利なライブラリ
from tqdm import tqdm
# tar.gzファイルの解凍
import tarfile
# 自然言語処理のためのライブラリ
import MeCab
import mojimoji
tagger = MeCab.Tagger("-Ochasen")
# ワードクラウドのためのライブラリ
from wordcloud import WordCloud
# LDA関連のライブラリ
from gensim.corpora.dictionary import Dictionary
from gensim.models import LdaModel
from gensim import models
from collections import defaultdict
from toolz import frequencies
各種データの事前設定
DIR = '/content/drive/MyDrive/colab/lda/'
SOURCE_FILE = 'ldcc-20140209.tar.gz'
TARGET_FILE = 'livedoor/'
FONT_PATH = '/usr/share/fonts/truetype/fonts-japanese-mincho.ttf'
※今回は、実行ディレクトリの構成を下のようにしています。
/content/drive/MyDrive/
┗colab/
┗lda/
┗LDA.ipnyb
matplotlibでのフォント設定
FONT_PROPERTY = matplotlib.font_manager.FontProperties(fname = FONT_PATH,
size = 24)
実行ディレクトリの変更
# ディレクトリの変更
os.chdir(DIR)
ライブドアニュースのデータのダウンロード
データを読み込んだ後は、解凍させる データのDL自体はコマンドを使った方がラクなので、"wget"コマンドでDLします。
DLしたデータはtar.gz形式で圧縮されているので、それを解凍する必要があるので、"tarfile"ライブラリを使って、解凍します。 解凍時間に結構時間がかかるので、一回解凍したらそれ以降の繰り返しで解凍処理を走らせないように一工夫入れましょう。
# データのDL
! wget "https://www.rondhuit.com/download/ldcc-20140209.tar.gz"
# 解凍済みフォルダの有無を確認
is_folder_exist = os.path.exists(DIR + TARGET_FILE)
# フォルダが無い時だけ、解凍処理を走らせる
if not is_folder_exist:
tar = tarfile.open(DIR + SOURCE_FILE, 'r:gz')
tar.extractall(DIR + TARGET_FILE)
# フォルダのファイルとディレクトリを確認
files_folders = [name for name in os.listdir("livedoor/text/")]
print(files_folders)
# カテゴリーのフォルダのみを抽出
categories = [name for name in os.listdir(
"livedoor/text/") if os.path.isdir("livedoor/text/"+name)]
print(categories)
実行結果。

データの概要把握
# ファイルの中身を確認してみる
file_name = "livedoor/text/movie-enter/movie-enter-6255260.txt"
with open(file_name) as text_file:
text = text_file.readlines()
print("0:", text[0]) # URL情報
print("1:", text[1]) # タイムスタンプ
print("2:", text[2]) # タイトル
print("3:", text[3]) # 本文
実行結果。

フォルダ名称が「カテゴリ」で、フォルダの中に大量にテキストファイルが存在しています。
テキストファイルは、
- 1行目:URL情報
- 2行目:タイムスタンプ(記事が公開された日時?)
- 3行目:タイトル
- 4行目:本文
という形でデータが入っています。
# フォルダのファイルとディレクトリを確認
files = os.listdir("livedoor/text/")
files_dir = [f for f in files if os.path.isdir(os.path.join("livedoor/text/", f))]
files_dir
実行結果。

ちなみに各カテゴリのデータを1つずつ取り出してみると、本文は下のような文章が入っていることを確認できます。
| カテゴリ | 本文 |
|---|---|
| トピックニュース | 最近、TVでも人気者の川越シェフ。代官山のおしゃれなイタリアンレストランのオーナーシェフでありながら、タレントとも軽妙なトークを交わすマルチな才能で、TV業界でもその地位を不動のものとしつつある。また、その甘いマスクに魅せられた、「川越女子」なる固定ファンまで存在するという。 |
| Sports Watch | 今月8日、都内ホテルでは、総合格闘家・吉田秀彦の引退試合興行「ASTRA」の開催が発表された。 |
| ITライフハック | テレビやTwitterと連携できるパソコンや、プロセッサや切り替わるパソコンなど、面白いパソコンが次から次へと登場した。旧式Macの禁断ともいえるパワーアップ方法から、NECの最新PC、話題のThinkPad X1 Hybrid、新セキュリティソフトまで一挙に紹介しよう。 |
| 家電チャンネル | 気温が高い日が続く。特に9日は各地で気温が上がった。気温が上がるとどうしても比例するのが電力使用量だ。9日は、全国の電力会社のうち8社の管内で、いずれも最大電力使用量が今夏最高を記録した。北海道、沖縄電力を除くすべての管内で、この夏一番の電力使用量を記録したが、これはやはり冷房の使用が原因だという。10日も暑くなることが予測されているため、さらに更新する可能性もある。 |
| MOVIE ENTER | 今や全国区の人気を誇る“ブサかわ”秋田犬・わさお。今年3月には本人出演による主演映画『わさお』にてスクリーン・デビューを果たした「わさお」と、10代・20代の若者に人気のロックバンドthe pillowsのボーカル「山中さわお」が、奇跡の対面を果たした。 |
| 独女通信 | もうすぐジューン・ブライドと呼ばれる6月。独女の中には自分の式はまだなのに呼ばれてばかり……という「お祝い貧乏」状態の人も多いのではないだろうか? さらに出席回数を重ねていくと、こんなお願いごとをされることも少なくない。 |
| エスマックス | 資生堂の出している、ファッショナブルなビジュアルとインタビューやビューティエッセイなどで構成された、資生堂の美意識に触れる企業文化誌です。 |
| Livedoor HOMME | 米国ロサンゼルス発のファストファッションチェーン「フォーエバー21」(本社:米国ロサンゼルス)は、2010年4月29日に東京・銀座の松坂屋銀座店にアジア初の旗艦店、「XX? at GINZA by FOREVER 21」(フォーエバー21銀座店)をオープンする。 |
| Peachy | キムチチゲやチヂミ、サムゲタンなど、韓国料理は昔よりもはるかに身近なものになりました。キムチは発酵食品で体によさそうだし、辛いものは発汗作用もあって新陳代謝を高めてくれます。そして、韓国料理には野菜もふんだんに使われてることも、人気の理由でしょう。 |
|
筆者目線では、
- ①スポーツ系
- ②家電/ITなどのテック系
- ③映画
- ④女性向けコンテンツ
- ⑤ニュース系
の5つのトピックがあるように見えています(タスク①の検証が、LDAによるトピック分類で5個になるかどうか?の根拠はここです)。
テキストファイルをカテゴリ別に読み込む
この処理も結構時間がかかるので、初めて実行した時に"list_df"というオブジェクトを作成し、2回目以降はそのオブジェクトの有無判定をして、再度処理を繰り返すことを避ける。
# 結構時間かかるので、ファイルの有無を確認して、
# 無い場合のみデータの読み込み処理をさせる形にする
is_list_exist = os.path.exists("list_df.pkl")
if not is_list_exist:
list_df = []
for category in files_dir:
path = "livedoor/text/" + category + "/"
files = os.listdir(path)
files_file = [f for f in files if os.path.isfile(os.path.join(path, f)) and (re.match(category, f))]
for file_name in files_file:
file = path + file_name
with open(file) as text_file:
text = text_file.readlines()
list_df.append([category, text[2], text[3]])
#text[0] : # URL情報
#text[1] : # タイムスタンプ
#text[2] : # タイトル
#text[3] : # 本文
with open('list_df.pkl', mode='wb') as f:
pickle.dump(list_df, f)
else:
with open('list_df.pkl', mode='rb') as f:
list_df = pickle.load(f)
df = pd.DataFrame(list_df, columns = ["category", "title", "content"])
df.head()
実行結果。

df.groupby("category").count()["title"]
実行結果。livedoor-homme以外は、大体700後半~900くらいの記事があることを確認できます。

データ前処理
今回実施する前処理は、主に次の4つです。
- 形態素解析→名詞、形容詞のみを残す
- ストップワードを除去する
- 大文字小文字を統一する
- 半角全角を統一する
ストップワードを除去するために、ストップワード集をDLします。
def load_jp_stopwords(path="jp_stop_words.txt"):
url = 'http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt'
if os.path.exists(path):
print('File already exists.')
print("="*30)
else:
print('Downloading...')
print("="*30)
urllib.request.urlretrieve(url, path)
dff = pd.read_csv(path, header=None)
result = dff[0].tolist()
return result
分かち書きと形態素解析、大文字小文字/半角全角の統一、ストップワードの除去を一気に実行します。
def preprocess_jp(series):
stop_words = load_jp_stopwords()
def tokenizer_func(text):
tokens = []
node = tagger.parseToNode(str(text))
while node:
features = node.feature.split(',')
length = len(features)
if length > 6:
surface = features[6] # 基本形
else:
surface = node.surface # featuresで基本形が無い場合は元の単語を使う
is_pass = (surface == '*') or (len(surface) < 2) or (surface in stop_words)
noun_flag = (features[0] == '名詞')
proper_noun_flag = (features[0] == '名詞') & (features[1] == '固有名詞')
verb_flag = (features[0] == '動詞') & (features[1] == '自立')
adjective_flag = (features[0] == '形容詞') & (features[1] == '自立')
if is_pass:
node = node.next
continue
elif proper_noun_flag:
tokens.append(surface)
elif noun_flag:
tokens.append(surface)
elif adjective_flag:
tokens.append(surface)
#elif verb_flag:
# tokens.append(surface)
node = node.next
return " ".join(tokens)
series = series.map(tokenizer_func)
# 大文字を小文字化
series = series.map(lambda x: x.lower())
# 半角全角変換
series = series.map(mojimoji.zen_to_han)
return series
上で定義した関数を実行してみます。
processed_news_ss = preprocess_jp(df.content)
processed_news_ss
実行結果。

データフレームに前処理したデータを格納します。
df["wakatigaki"] = processed_news_ss
df.head(10)
実行結果。

ワードクラウドを描いてみる
各カテゴリのテキストがどんな感じか直感的に把握するためにワードクラウドを描いてみます。
def show_wordcloud(series):
long_string = ','.join(list(series.values))
# Create a WordCloud object
wordcloud = WordCloud(font_path = FONT_PATH,
background_color = "white",
max_words = 1000,
contour_width = 3,
contour_color = 'steelblue')
# Generate a word cloud
wordcloud.generate(long_string)
# Visualize the word cloud
plt.imshow(wordcloud)
plt.show()
for category in files_dir:
df_temp = df[df.category == category]
print()
print("==" * 30)
print(category)
show_wordcloud(df_temp.wakatigaki)
実行結果。









学習データとテストデータに分ける
学習データ9割、テストデータ1割にします。
単純にデータを分割してしまうと、特定カテゴリのデータだけ無い(少ない)状態になってしまうので、それを避けるためにデータを分割前に、いったんdfの行をシャッフルしておきます。
df_shuffled=df.sample(frac = 1, random_state = 0).reset_index(drop = True)
N_data = df.shape[0]
train_ind = int(N_data * 0.9)
df_train = df_shuffled.iloc[:train_ind,:].reset_index(drop = True)
df_test = df_shuffled.iloc[train_ind:,:].reset_index(drop = True)
LDAの準備
# gensim用に成形
documents = df_train.wakatigaki.values
texts = list(map(lambda x:x.split(), documents))
# 単語->id変換の辞書作成
dictionary = Dictionary(texts)
# 使われている文書の数がno_belowより少ない単語を無視し、no_aboveの割合以上の文書に出てくる単語を無視しています。
dictionary.filter_extremes(no_below=3, no_above=0.8)
# Bag-of-Wrodsのコーパスを作成
corpus = [dictionary.doc2bow(text) for text in texts]
# 関数new_idfを追加
# このページにあるように、単語が1つしかない場合にtfidfで単語が消えてしまう問題を回避するために
# 関数を追加する
# https://qiita.com/tatsuya-miyamoto/items/f1539d86ad4980624111
def new_idf(docfreq, totaldocs, log_base=2.0, add=1.0):
return add + math.log(1.0 * totaldocs / docfreq, log_base)
# tfidf modelの生成
tfidf_model = models.TfidfModel(corpus,
wglobal = new_idf,
normalize = False)
# 作成したモデルにコーパスを適用する
tfidf_corpus = tfidf_model[corpus]
タスクNo.①
最適なトピック数を探索します。
coherence_vals = []
perplexity_vals = []
START = 2
END = 21
STEP = 1
for n_topic in tqdm(range(START, END, STEP)):
# LDAモデルのインスタンス化
lda = LdaModel(corpus = tfidf_corpus,
num_topics = n_topic,
id2word = dictionary,
random_state = 0)
# gensimでは、coherenceの計算手法が4つある
# c_v:もっとも精度が高いけど、計算時間すごいかかる。コーパスはLDA学習と違うコーパスを用意する必要がある
# u_mass:高速かつ、LDA学習で使ったコーパスを使っても問題ない
# c_npmiとc_uci:c_vとu_massの中間の性質。でもコーパスはLDA学習と違うコーパスを用意する必要がある
# 今回は、手軽にやりたいので、u_massを使う
coherence_model_lda = models.CoherenceModel(model = lda,
corpus = tfidf_corpus,
dictionary = dictionary,
coherence = 'u_mass')
coherence_vals.append(coherence_model_lda.get_coherence())
perplexity_vals.append(np.exp(-lda.log_perplexity(tfidf_corpus))) # https://analytics-note.xyz/machine-learning/gensim-lda-perplexity/
perplexityとcoherenceを可視化
指標
- Perplexity:予測性能
- Coherence:トピックの品質
指標の見方
- Perplexityは低ければ低いほど良い
- Coherenceは高ければ高いほど良い
x = range(START, END, STEP)
fig, ax1 = plt.subplots(figsize=(16,9))
# coherence
c1 = 'darkturquoise'
ax1.plot(x, coherence_vals, 'o-', color = c1)
ax1.set_xlabel('Num Topics')
ax1.set_ylabel('Coherence', color = c1); ax1.tick_params('y', colors = c1)
# perplexity
c2 = 'red'
ax2 = ax1.twinx()
ax2.plot(x, perplexity_vals, 'o-', color = c2)
ax2.set_ylabel('Perplexity', color = c2); ax2.tick_params('y', colors = c2)
# visualise
ax1.set_xticks(x)
fig.tight_layout()
plt.show()
実行結果。
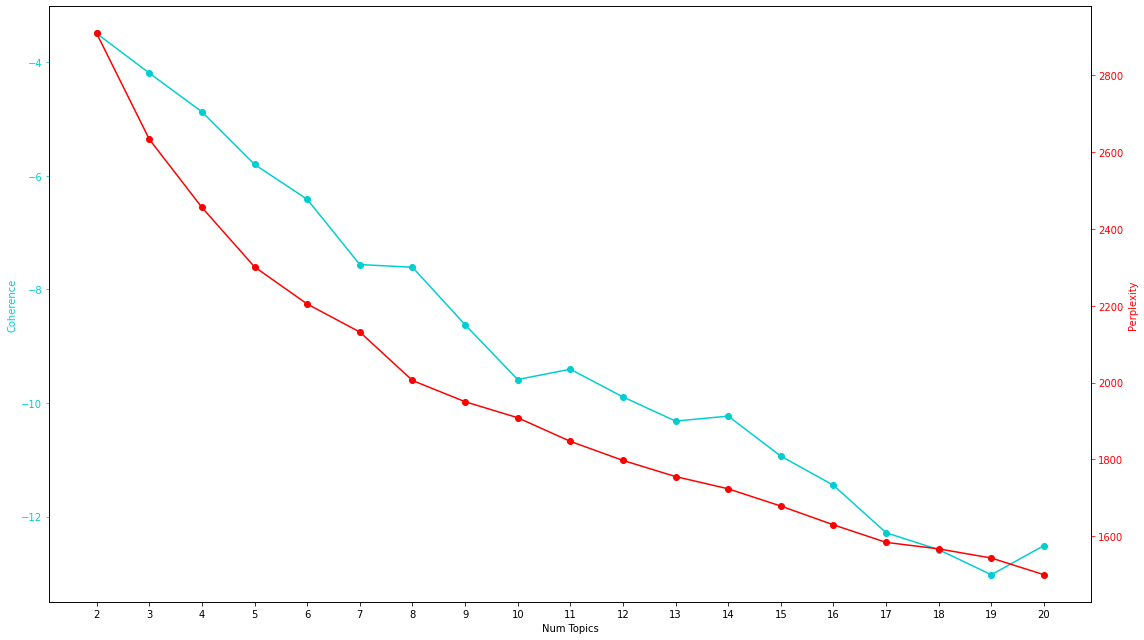
perplexityがビミョーですが、coherenceを考えると、トピック数としては"8"が最適っぽい(と判断することにします)。
検証結果、トピック数は筆者が直感的に推定していた"5"ではなく、8となりました。
LDAではこのように分析者がperplexityとcoherence、人間が扱いきれるトピック数という3観点で定性的に決めることが多いようです。
補足分析
N = sum(count for doc in corpus for id, count in doc)
p = perplexity_vals[NUM_TOPICS - START]
print(str(N) + " 個の単語を " + str(int(p)) + " 個程度の情報まで圧縮できた")
print("圧縮率は(注:そんな指標は実際にはないですが、直感的理解のために ) " + str(round(p/N*100, 2)) + " %")
実行結果。

理想を言えば、Perplexityは低ければ低いほど、Coherenceは高ければ高いほど良いとされていますが、これを見る限り、適切なトピック数の設定が難しい結果となりました。Coherenceにしても、一番高いところの値、もしくはCoherenceが上がり続けるような曲線を描いた場合には、対数関数っぽく平坦化してくる部分の手前で最も高いCoherenceの値が算出されたパラメータ値を利用するらしいですが、たいていの実データで実行した場合は、今回のように減少関数っぽくなってしまいます。
これだとあまり決められないので、ひとまず今回は、結果の解釈性なども見て、トピック数8にしました。
Perplexityにしてみれば、およそ2,005ぐらいですので、単語をランダムに選択した場合の語彙数90,046通りに対して、2,005通りぐらいにまで絞れていると考えていると、それはそれで結構良い性能のようにも聞こえます。
トピックモデリングの評価指標に関してはずっと課題のようで、Perplexity、Coherenceだけでなく、他にも様々考えられているようです。
タスクNo.②
次はタスク①で決めたトピックが人間にとって解釈しやすいものになっているかどうかを確認してみます。
トピック数を8としてLDAのモデルを再構築します。
NUM_TOPICS = 8
# LDAモデルのインスタンス化
lda = LdaModel(corpus = tfidf_corpus,
num_topics = NUM_TOPICS,
id2word = dictionary,
random_state = 0)
トピック内の最頻単語を取得する
トップ10の単語を表示します。
TOP_N_WORDS = 10
# 文書毎の該当トピック
doc_topics = [lda[c] for c in tfidf_corpus]
# トピックの該当数
topic_freq = frequencies([t[0] for dt in doc_topics for t in dt])
for i in range(NUM_TOPICS):
word_id_list = [t[0] for t in lda.get_topic_terms(i, topn = TOP_N_WORDS)]
word_prob_list = [t[1] for t in lda.get_topic_terms(i, topn = TOP_N_WORDS)]
list_word = [dictionary[id] for id in word_id_list]
print()
print("=="*30)
print('topic_{}'.format(i+1))
print(list_word)
実行結果。

この結果を見ると、トピック1とトピック7、トピック3とトピック5が似ているような気がします。
ワードクラウドで結果を可視化してみる
先ほどは各トピックでのトップ10の単語を抜き出す形でトピックを評価していましたが、次はワードクラウドを描いてトピックを確認してみましょう。
NUM_WORDS_FOR_WORD_CLOUD = 50
fig, axs = plt.subplots(ncols=2, nrows=math.ceil(lda.num_topics/2), figsize=(16,20))
axs = axs.flatten()
for i, t in enumerate(range(lda.num_topics)):
x = dict(lda.show_topic(t, NUM_WORDS_FOR_WORD_CLOUD))
im = WordCloud(
background_color = 'black',
max_words = 4000,
width = 300,
height = 300,
random_state = 0,
font_path = FONT_PATH
).generate_from_frequencies(x)
axs[i].imshow(im.recolor(colormap= 'Paired_r' , random_state=244), alpha=0.98)
axs[i].axis('off')
axs[i].set_title('Topic '+str(t))
実行結果。

- トピック0:ガジェット?
- トピック1:スポーツ
- トピック2: 映画
- トピック3:ネットニュース?
- トピック4:映画
- トピック5:女性向けニュース
- トピック6:IT系
- トピック7:スポーツ
→なんとなくわかるようなわからないような…かつ、トピックが重複してそうなものが複数あります。
結果としては「ある程度トピックを分類できていますが、一部トピックの重複がある」という結果になりました。
本当はもっときれいにトピックを分類してほしかったのですが、今回はトピック数8のまま、次のタスクに移行します。
タスクNo.③
新しいテキスト(記事)のトピックを識別してみます。識別したテキストは以下のやりかたで抽出したテキストデータとします。
Yahooニュースでテキトーに記事をピックアップし、こちらのサイトでテキスト情報を抽出します。 方式は「タグごとに改行」という設定で抽出します。 抽出したテキストの中から、手動で本文っぽいところをコピペします。
新規データの定義。
#https://news.yahoo.co.jp/articles/1fa5ef35a4cbd4432a79d694c5ca61eb540ff7c3
TEXT1 = "サッカーのカタール・ワールドカップ(W杯)はアルゼンチンの36年ぶり3回目の優勝で幕を閉じた。大会公式日本語版ツイッターは日本代表の厳選写真4枚を公開。ファンからは「めちゃくちゃ良い写真ばかり」「既にロスです」と反響が届いている。 興奮が蘇ってくる。ドイツ、スペインと優勝経験国を破り、決勝トーナメントに進出した日本。決勝T1回戦でクロアチア相手にPK戦の末に惜しくも敗れたが、日本国民に大きな感動を与えた。同公式ツイッターは20日、「#FIFAワールドカップ の思い出としてほしい写真を募集!中の人が夕方までに集まったリクエストにできるだけ応えます」と投稿し、ファンに意見を募っていた。 その投稿の7時間後、同公式ツイッターは4枚の写真を公開。ソロ写真などではなく、どれも選手が集まっているものだ。歓喜に沸くイレブンや、円陣を組んだ写真が投稿されていた。 ファンは“珠玉の4枚”に感動。反響が続々と寄せられている。 「3枚目やばい」 「めちゃくちゃ良い写真ばかり」 「何回見てもいいなぁぁ」 「勝ったときは高校の部活のノリ 親しみやすいです」 「3枚目のブラボー兄貴がちょっとコラっぽくて好き」 「本当に今回のSAMURAIBLUEが大好き過ぎて、既にロスです」"
#https://news.yahoo.co.jp/articles/8c8d39dd8b2abfffaf7db02067ae3f7d38de1732
TEXT2 = "大阪府とKDDIは21日、8つの分野において連携と協働する包括連携協定を締結した。同日午後、大阪府庁では吉村洋文知事と髙橋誠KDDI社長が出席し、締結式が開催された。 包括連携協定では、地域活性化やスマートシティ、環境対策、産業振興、教育、健康、安心安全、府政PRといた8分野が対象となる。 ■ 目玉は「バーチャル大阪」「おおさかecoでんき」 2者ではかねてより協力を進めてきたが、今回の協定を踏まえ、新たな取り組みとして「バーチャル大阪を活用した大阪の都市魅力の国内外への発信」「おもいでケータイ再起動による地域イベントへの協力」「おおさかecoでんき」などが進められることになった。 このうち、「バーチャル大阪での展開」と「おおさかecoでんき」は他社にはないユニークな連携例となる。なお、「おおさかecoでんき」については、大阪向け電力サービスとされているが、料金などの詳細は、決まり次第、案内される。 ■ 吉村知事とKDDI髙橋社長が揃って登壇 吉村知事は、「2025年の万博まで、あと2年ちょっと。万博のリアル(展示)を充実させるのは当然だが、KDDIと協力して進めているのがバーチャル大阪。一歩一歩着実に進めているが、本協定の締結を期に加速させたい。万博期間中はもとより、新たな社会、新たな未来があるということをバーチャルを通じて実現したい」と意気込みを示す。 大阪府の担当者によれば、万博を開催することは関西圏において一定の認知を得ているものの、全国的にはまだ道半ばと大阪府側では見ているという。KDDIとのバーチャル大阪は、そうした認知拡大の一助と位置づけられる。 KDDIの髙橋社長は、地域活性化~府政のPRと8分野で連携するなかで、柱として「バーチャル大阪」「おおさかecoでんき」があると位置づける。ユーザーが作り上げるコンテンツ(UCG)や、在阪企業によるコンテンツ、そしてデジタルツインによる現地とバーチャルでの接客など、万博をふくめて大阪を盛り上げたい」と応じる。 2022年度内に提供される電力サービス「おおさかecoでんき」の料金などはまだ発表されていないが、ユーザーは再生可能比率、実質100%の電力を利用でき、料金の2%を環境保全の基金に寄付できるというもの。大阪府民が大阪府の環境保全に貢献できる内容になるという。"
#https://news.yahoo.co.jp/articles/48a3d12ab5c12b31ba751546cec4f41329cc1724
TEXT3 = "現在公開中の『劇場版 転生したらスライムだった件 紅蓮の絆編』に出演している、声優の内田雄馬さん(30)にインタビュー。本作に初参戦することになった心境やキャラクターの魅力をはじめ、“声の仕事を始めて約10年”という内田さんに10年を振り返っていただきました。 シリーズ累計発行部数3000万部突破の異世界ファンタジー『転生したらスライムだった件』(通称「転スラ」)。初の劇場版作品となった本作は、原作者である伏瀬さん自らが原案を手がけた完全オリジナルストーリーとなっていて、人間からスライムに転生した主人公・リムルたちが、仲間のために陰謀に立ち向かう“絆”の物語となっています。 内田さんは本作のオリジナルキャラクターとなる大鬼族(オーガ)の生き残り、ヒイロを演じます。【画像】声優・内田雄馬「言葉が出てくるというか引き出してもらえる」 共演の古川慎を絶賛■内田雄馬 “兄貴”は「その人の背中を自然と追いたくなるような存在」内田さんが演じたヒイロ 『劇場版 転生したらスライムだった件 紅蓮の絆編』 上映中 ©川上泰樹・伏瀬・講談社/転スラ製作委員会 配給:バンダイナムコフィルムワークス――本作への参加が決まったときの心境はいかがでしたか? “転スラ”のシリーズが非常に盛り上がっているというのは存じ上げておりまして、そのシリーズに参加できるということは非常に光栄だなということで、すごく楽しみだなって思ったことを覚えております。 ――ヒイロを演じられた感想や、キャラクターの魅力を教えてください。 今回オリジナルキャラクターというところでシリーズものに参戦するとなると、そこまでの流れであったり、いろいろなことがあっての物語だと思うんですけども、1から描いていただいたというところで、非常に新鮮な気持ちで参戦できたかなというふうに思っております。ヒイロ自体も非常に真っすぐな方(キャラクター)だったので、演じている中で自分としても細かく裏で小細工をするような人じゃないっていうところで、まっすぐ言葉を届けようっていう気持ちで演じられたというのがすごくよかったなというふうに思っております。 ――ヒイロは、古川慎さん演じるベニマルが“兄者”と慕うキャラクターですが、内田さんにとって“兄貴”とはどういう存在だと思われますか? その人の背中を自然と追いたくなるような、そういう存在なのかなっていうふうに思います。自然とあるっていうか、その自然とある中で自分のこだわりもあるけど、相手の気持ちとかこだわりも感じて受け止めてくださる人。そういう人がカッコいいし、背中を追いたくなるなっていうことだと思うので、そういう人が自分にとっては“兄貴”だなと思えるのかなというふうに感じます。 ――内田さんご自身もそうした存在になっていきたいですか? そうですね。本当にそういうふうに思ってもらえるように頑張りたいなというのはあります。僕も30歳になったので、年齢が上の方になってきたりもしているので、なるべく本当に僕の背中を見てもらえるように、見てほしいと思っているわけじゃないんですけど(笑)たまたま見た時になんか見て良かったかなって思ってもらえたらいいよねっていうくらいなんですけど。僕は僕らしくやり続けていくのが大事かなと思います。"
新規データの前処理。新規データもライブドアニュースのように分かち書きや形態素解析といった前処理が必要なので、それを実施します。
new_data_ss = pd.Series([TEXT1,
TEXT2,
TEXT3])
processed_new_data_ss = preprocess_jp(new_data_ss)
# gensim用に成形
new_documents = processed_new_data_ss.values
new_texts = list(map(lambda x:x.split(), new_documents))
score_by_topic = defaultdict(int)
# Bag-of-Wrodsのコーパスを作成して
# TFIDFコーパスを適用する
new_corpus = [dictionary.doc2bow(text) for text in new_texts]
new_tfidf_corpus = tfidf_model[new_corpus]
list_score_by_topic = []
# 結果を出力
for unseen_doc in new_tfidf_corpus:
list_temp = []
for topic, score in lda[unseen_doc]:
score_by_topic[int(topic)] = float(score)
for i in range(NUM_TOPICS):
list_temp.append(score_by_topic[i])
list_score_by_topic.append(list_temp)
# リストをnumpy配列に変換しておく
np_score_by_topic = np.array(list_score_by_topic)
processed_new_data_ss
実行結果。

新規データのトピック分類をしてみます。
df_new = pd.DataFrame(new_data_ss)
df_new["topic"] = "topic_"
df_new["prob"] = .0
for i in range(df_new.shape[0]):
score_i = np_score_by_topic[i]
max_id = score_i.argmax()
prob_id = score_i[max_id]
df_new.iloc[i,1] = 'topic_{}'.format(max_id)
df_new.iloc[i,2] = prob_id
df_new
実行結果。

1番目の記事はサッカーワールドカップのニュース記事なので、トピック7(スポーツっぽいトピック)というのは合ってると思います。
2番目の記事は"IT"ニュースの欄の記事なので、期待はトピック0だったのですが、トピック3と判定されました。「話題」「公開」といった単語に反応してしまったのでしょうか?
3番目の記事はエンタメの欄の記事です。期待通りトピック4と判定してくれました。「劇場版」みたいにわかりやすく映画系の文字情報が入っていたからでしょうか?
→IT系の記事以外はちゃんとトピックを推定できているように見える結果となりました。
筆者の個人的な経験ですが、IT系の記事は、いわゆるネットニュースっぽい書き方をされることが多いので、LDA的に判断が難しかったのかもしれません。(実際、カラム「prob」でトピックへの所属確率を表示しているのですが、それをみると、28.6%と結構低い数値なので、LDAもトピック判断が難しかったととらえていると推察されます)。
タスクNo.④
レコメンドを実施してみます。
今回はレコメンドのタスクとして、指定した記事と類似性の高い記事を10個おすすめとして提示することを考えます。かみ砕いて言えば、ある記事のidを入力して、それに近いニュース記事を類似度の近い順に出すことを考える(まさしくレコメンド)ということになります。
gensimでは、similaritiesというメソッドがあるので、これを使って簡単に実装できます。
文章同士の類似性をどのように計算しているのかという指標はここではコサイン類似度を使っています。
メソッドを使うための準備。
from gensim import similarities
doc_index = similarities.docsim.MatrixSimilarity(lda[tfidf_corpus])
ターゲットとする記事のidを設定します。(ここを色々変えてみて実行して結果を見比べてみると面白いかもしれません)。
target_article = 1
ターゲット記事はこんな記事でした。

野球のニュースに関する内容のようです。ので、トピックとしては『スポーツ系』なので、レコメンドする記事もスポーツ系であることが期待されます。
ターゲット記事のベクトル化
vec_lda = lda[tfidf_corpus[target_article]]
NUM_SIMILAR_ARTICLES = 10
s = doc_index.__getitem__(vec_lda)
s = sorted(enumerate(s), key=lambda t: t[1], reverse=True)
print(s[:NUM_SIMILAR_ARTICLES])
list_similar_articlle = s[1:NUM_SIMILAR_ARTICLES + 1]
実行結果。
ターゲット記事(id=1)と類似した文章のidと類似度(コサイン類似度)がタプル型で出力されました。
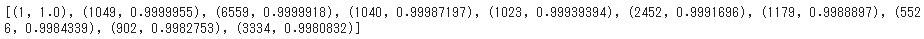
ターゲット記事と類似したトップ10の記事を算出してみます。
list_similar_ind = [target_article]
for doc_id, sim in list_similar_articlle:
list_similar_ind.append(doc_id)
df_train.iloc[list_similar_ind]

結果、一部怪しいものもありますが、スポーツ系の記事が6個、独女通信が2つ、映画が1つ、ニュースが1つをレコメンドする結果となりました。
また、トップ4まではスポーツ系の記事です。
ある程度の精度でレコメンドができたと言えそうです。
まとめと考察
今回はトピックモデルとしてLDAを使い、レコメンドまで実装してみました。
- パラメータ調整とか特にせずに実行したので、あまり良い分類モデルにはならなかったものの、簡単に実装できる
- そこそこ理解できる粒度感で記事を分類してくれる
- 記事レコメンド機能も、悪くはない(良いわけではない)精度でレコメンドしてくれる
という点で有用と推察されます。
また、より精度の高いレコメンドをするのであれば、
- データの前処理をもっと丁寧にする
- 記事だけでなく、ユーザの閲覧情報を反映させる
- LDAではなく、言語処理として最新かつ精度が高いBERTやGPTなどを使う
といった手法/モデルの変更が考えられる。
精度はビミョーなところはあったものの、実験的にクイックに実装したい、というような目的であれば、十分”使える”と思います。
参考にしたページ
今回はここのページを大いに参考にさせていただきました。