概要
「API経由でユーザから投げられたプロンプトをChatGPTで回答し、そのプロンプトと回答をDBに保存させる」アプリケーションを作ってみます。
完成形のイメージは↓の画像です。
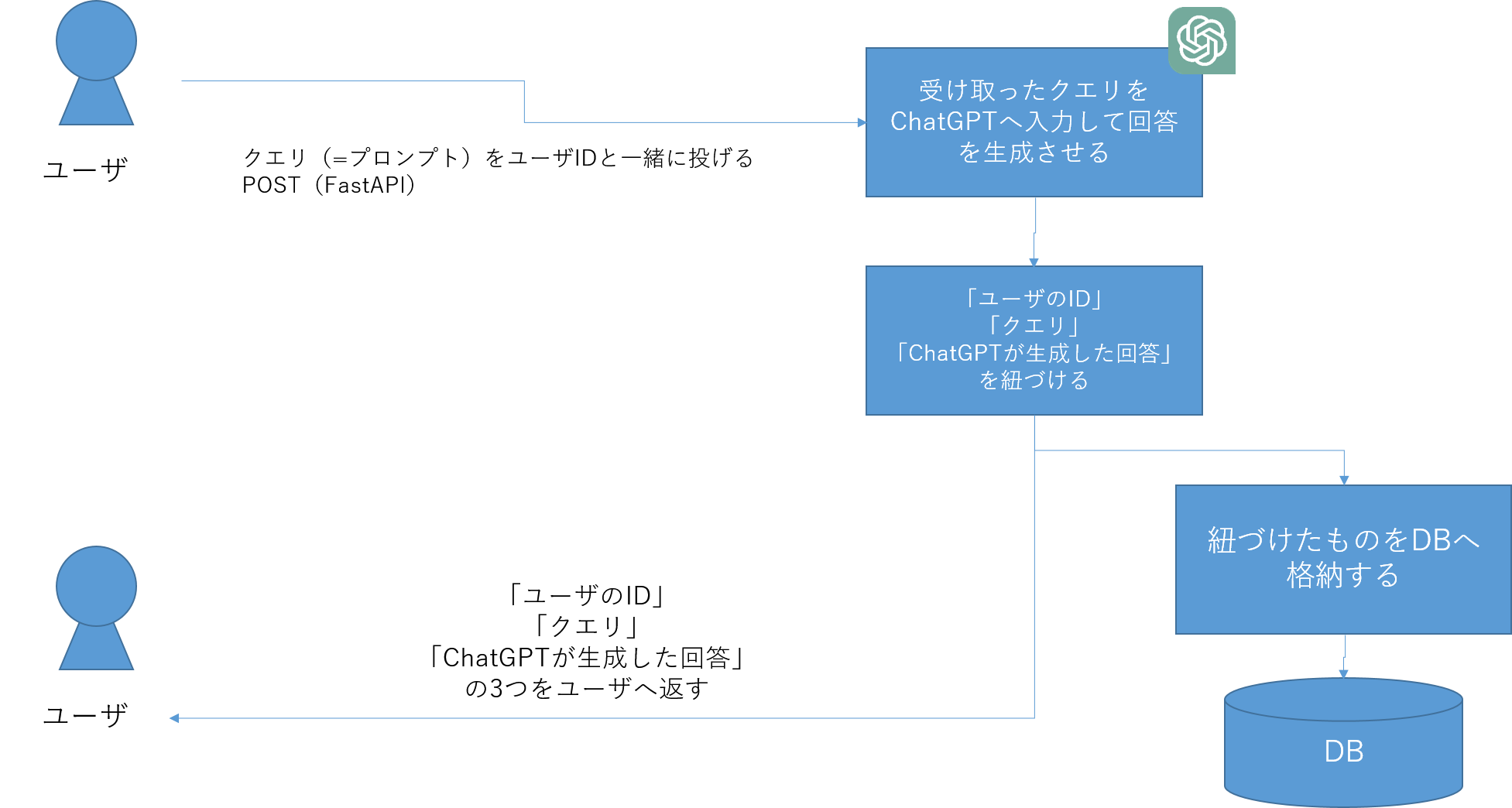
今回の記事で作成したものをベースにすることで世の中であふれているChatGPTを使ったLINEボットなどを作ることができます。
この記事の解説の流れ
シンプルなものを作成し、それをベースにDB機能の追加、ChatGPTの追加という3段階でアプリケーションを作ります。
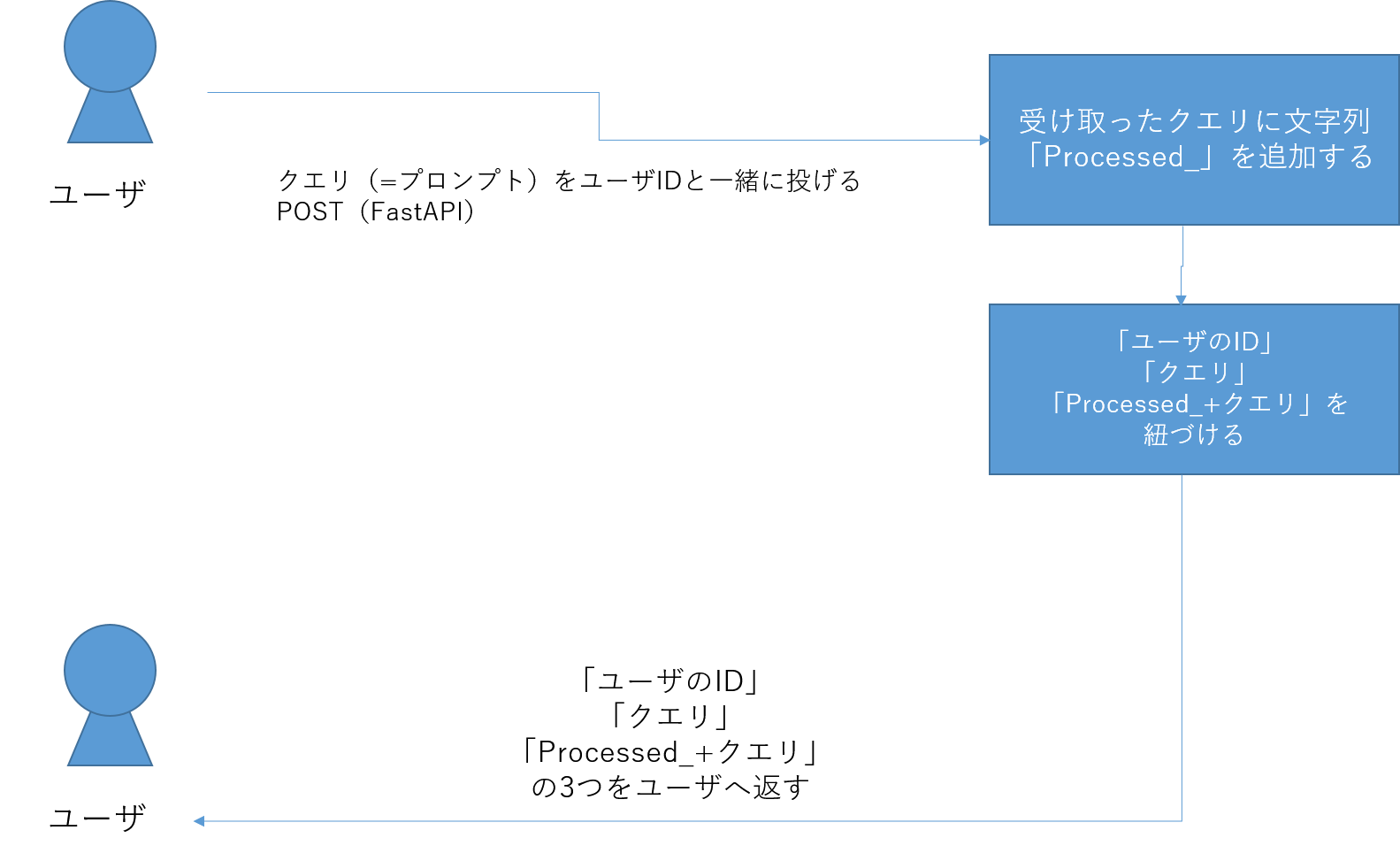
①FastAPIでプロンプトを投げるアプリケーションを作る
まずはシンプルに、FastAPIを使って、API経由でプロンプトを投げて、そのプロンプトをそのままユーザへ返すものを作ります。
注:この段階では、ChatGPTを追加しません。
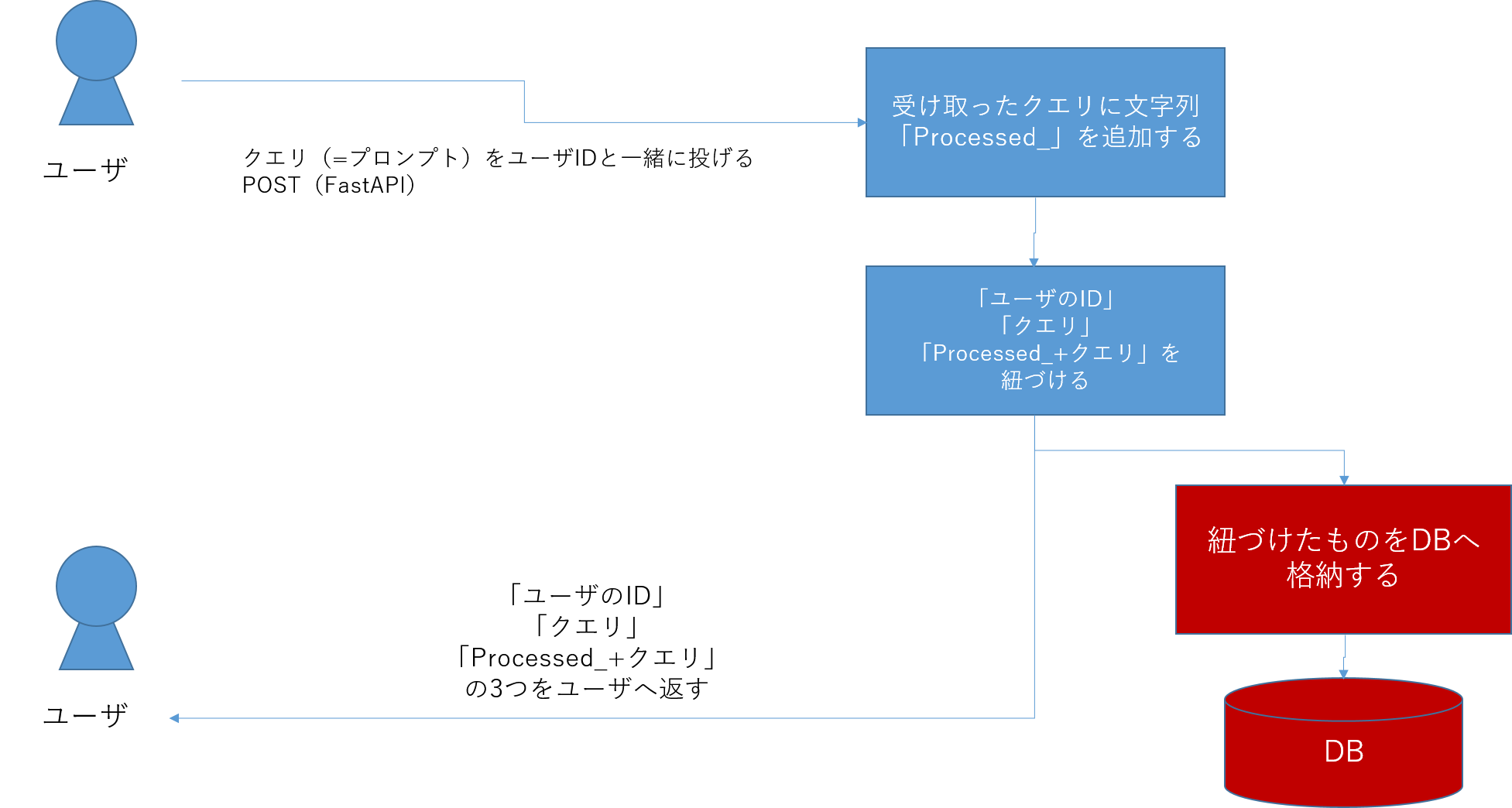
②DBを追加する
次に①で作ったものに対して、DBを追加します。DBの中にユーザIDとユーザが投げているプロンプト、そしてプロンプトを加工した文字列のデータをDBへ格納します。こうすることで、ユーザとの過去のやり取りをDBに記録させておくことができます。
注:まだChatGPTを追加しません。
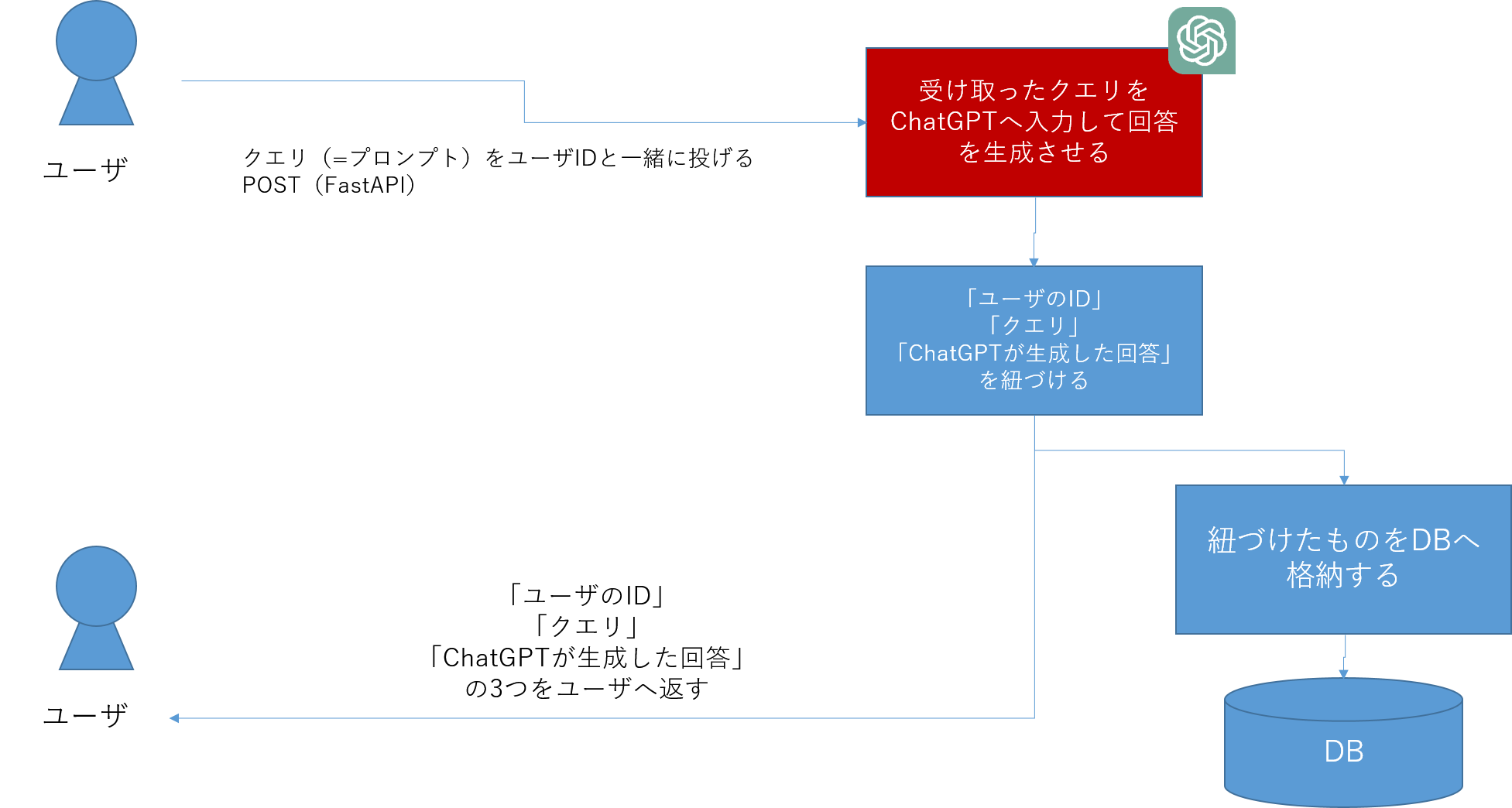
③ChatGPTを追加する
最後にChatGPTを追加します。②まではユーザからのプロンプトに対して、シンプルな加工(文字列の追加)をしただけでしたが、ここでようやくChatGPTを追加します。
②でDBを追加しているので、ChatGPTとのやりとりデータをDBに記録させることができるようになります。
実装
実装の基本方針
- 今回作成するコードは次の2つのコードを1セットとして作成していきます。
- APIにリクエストを投げるパート
- FastAPIを使ってAPIの実装とその処理を担当するパート
①実装:FastAPIでプロンプトを投げるアプリケーションを作る
作成するもののイメージを先に記載すると次の図のようになります。
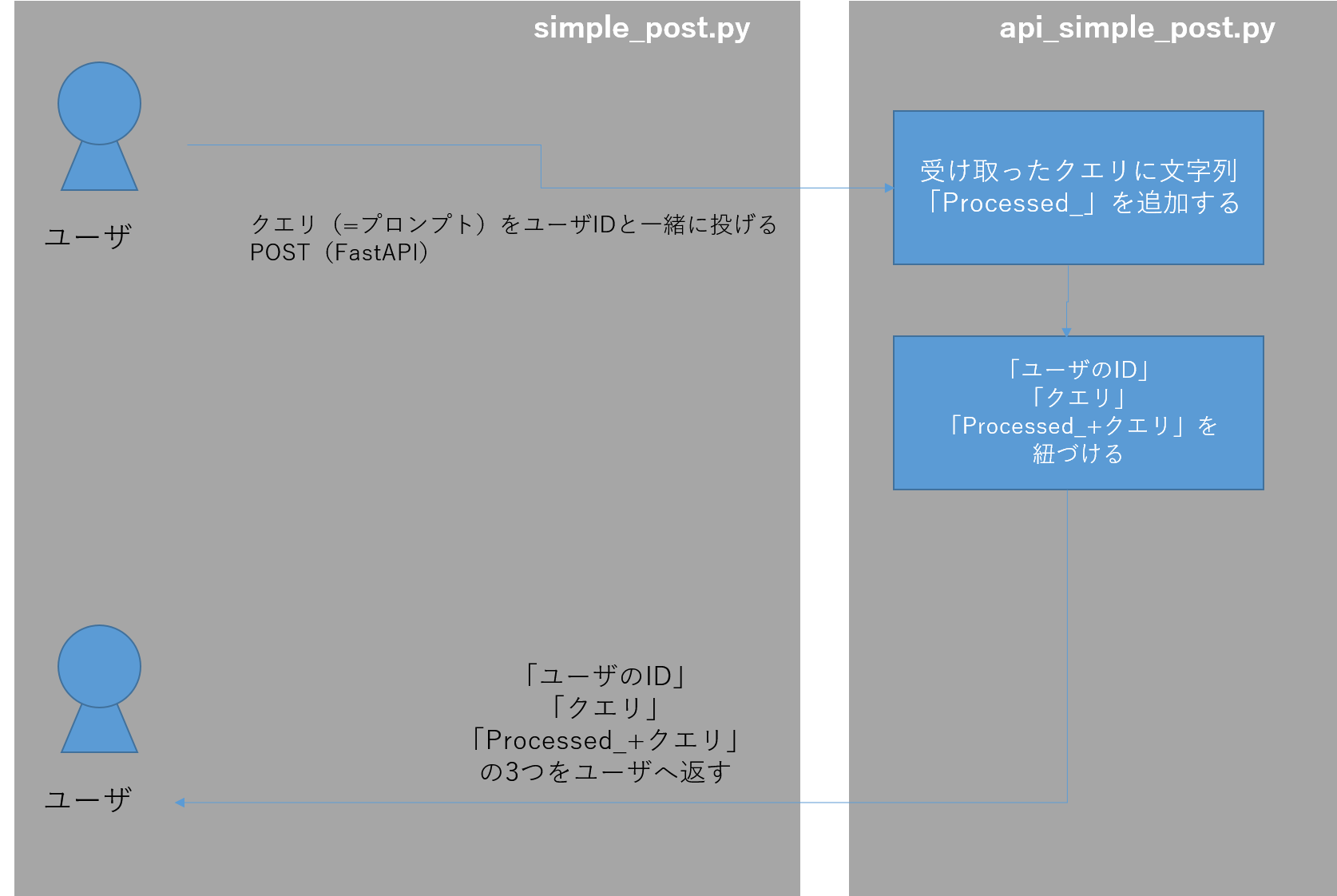
APIにリクエストを投げるパート
まずはAPIにリクエストを投げるパートを実装していきます。こちらは非常にシンプルな実装となっています。
import requests
import json
url = "http://localhost:8000/process/" # POSTリクエストを送信するエンドポイントのURL
data = {
"user_id": "example_user", # ユーザID
"query" : "example_query" # ユーザが投げるクエリ(=プロンプト)
}
response = requests.post(url, json=data) # エンドポイントにクエリを投げる
# レスポンスの内容を表示
print(response.json())
これ単体ではまだ動かすことができません。次に実装するapi_simple_post.pyを実装して、初めて動かすことができます。
APIと受け取ったクエリを処理させるパート
次のように実装します。
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Input(BaseModel):
user_id: str
query: str
class Output(BaseModel):
user_id: str
query: str
output: str
@app.post("/process/")
def main(input_data: Input):
# 入力データを取得
user_id = input_data.user_id
query = input_data.query
# 文字列の加工処理
processed_text = f"Processed _ User ID: {user_id}, Query: {query}"
# 処理結果と入力データをまとめて返す
output_data = Output(user_id=user_id, query=query, output=processed_text)
return output_data
コードを解説します。
class Input(BaseModel):
user_id: str
query: str
class Output(BaseModel):
user_id: str
query: str
output: str
ここは、ユーザとのやりとりをするデータの定義をしています。ここで定義したオブジェクトをAPI経由で送受信します。
- ユーザからのインプット:
Input-
user_idユーザID -
queryクエリ
-
- ユーザへのアウトプット:
Output-
user_idユーザID -
queryクエリ -
outputアウトプット
-
@app.post("/process/")
def main(input_data: Input):
# 入力データを取得
user_id = input_data.user_id
query = input_data.query
# 文字列の加工処理
processed_text = f"Processed _ User ID: {user_id}, Query: {query}"
# 処理結果と入力データをまとめて返す
output_data = Output(user_id=user_id, query=query, output=processed_text)
return output_data
simple_post.pyで定義したエンドポイント「/process/」へユーザリクエストがPOST(送信)されるので、それを処理するための関数が「main」です。
今回は単純な文字列の処理をするだけ(Processed_という文字列をqueryに追加するだけ)で、その結果をさきほど定義していたOutputオブジェクトに代入し、output_dataを作っています。
最後にこのoutput_dataをリターンする、という処理です。こうすることで、simple_post.pyにoutput_dataデータが返されることになります。
動かしてみる
ここまでで作ったものを動かしてみましょう。
まず、api_simple_post.pyを置いているディレクトリ(フォルダ)へ移動し、次のコマンドを打ちます。
uvicorn api_simple_post:app --reload
実行して次のような画面が出てきたらOKです。

次にまた、別のコマンドプロンプト(MacやLinuxであればターミナル)を起動し、simple_post.pyを置いているディレクトリへ移動します。
そしたら次のコマンドでsimple_post.pyを実行させます。
python simple_post.py
次のような実行画面が出てきたら成功です。

これは、
-
simple_post.pyからuser_idとqueryをAPI経由でデータを送信(POST)する -
api_simple_post.py側でuser_idとqueryを受け取り、queryの文字列に「Processed_」を追加して、Outputへ格納する。 -
Outputデータがoutput_dataとしてAPI呼び出し元のsimple_post.pyに返し、JSON形式でprintする
という処理が行われています。
②実装:DBを追加する
作成するもののイメージは次の通りです。
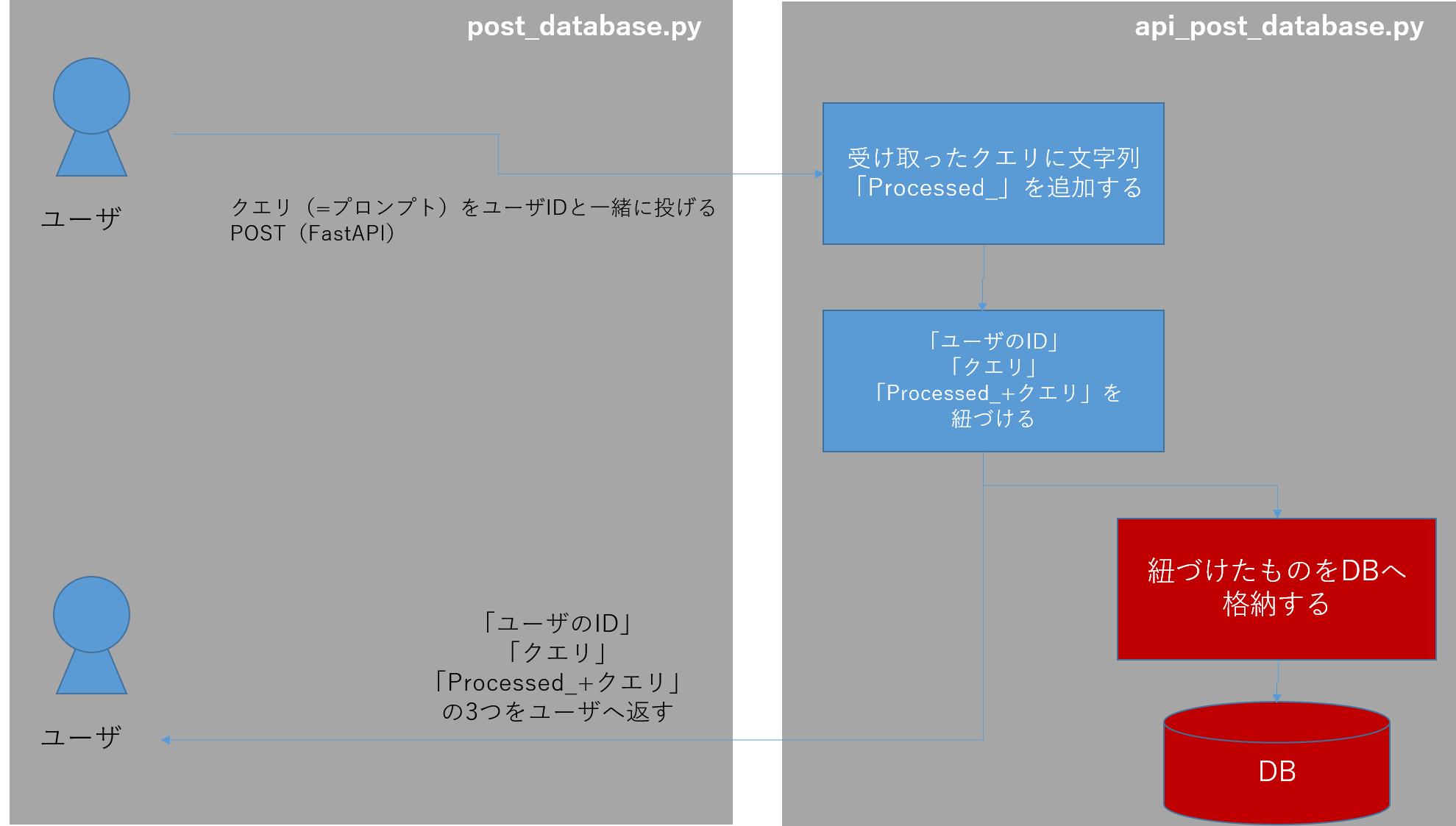
APIにリクエストを投げるパート
import requests
import json
import os
import sqlite3
import pandas as pd
url = "http://localhost:8000/process/" # POSTリクエストを送信するエンドポイントのURL
data = {
"user_id": "example_user",
"query" : "example_query"
}
response = requests.post(url, json=data)
# レスポンスの内容を表示
#print(response.json())
# ステータスコードを取得
status_code = response.status_code
print("status : " + str(status_code))
# データベースファイルのパス
DB_PATH = 'simple_database.db'
# データベースに接続
conn = sqlite3.connect(DB_PATH)
# SQLクエリを実行し、データを取得
query = "SELECT * FROM data"
df = pd.read_sql_query(query, conn)
# データベース接続を閉じる
conn.close()
# データフレームを表示
print(df)
コードを解説します。
# ステータスコードを取得
status_code = response.status_code
print("status : " + str(status_code))
ここは、APIにリクエストを投げる(POST)し、リクエストのステータスを表示するためのパートです。APIリクエストに成功していれば、200と出ます。
# データベースファイルのパス
DB_PATH = 'simple_database.db'
# データベースに接続
conn = sqlite3.connect(DB_PATH)
# SQLクエリを実行し、データを取得
query = "SELECT * FROM data"
df = pd.read_sql_query(query, conn)
# データベース接続を閉じる
conn.close()
ここは次に作るapi_post_database.py側で生成したDBへ接続し、そのDBの中身を読み取るためのコードです。読み取った内容をpandasのDataFrame形式に変換し、そのあと、DBとの接続を閉じています。
APIと受け取ったクエリを処理させるパート
from fastapi import FastAPI
from pydantic import BaseModel
import sqlite3
import os
app = FastAPI()
class Input(BaseModel):
user_id: str
query: str
class Output(BaseModel):
user_id: str
query: str
output: str
# データベースファイルのパス
DB_PATH = 'simple_database.db'
@app.post("/process/")
def main(input_data: Input):
# 入力データを取得
user_id = input_data.user_id
query = input_data.query
# 文字列の加工処理
processed_text = f"Processed_ User ID: {user_id}, Query: {query}"
# データベースの存在を判定
if os.path.exists(DB_PATH):
# データベースが存在する場合
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
else:
# データベースが存在しない場合、新しく作成する
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
# テーブルの作成
cursor.execute('''CREATE TABLE data
(USER_ID TEXT, QUERY TEXT, OUTPUT TEXT)''')
# データの挿入
cursor.execute("INSERT INTO data VALUES (?, ?, ?)" ,(user_id, query, processed_text))
# 変更を確定させる
conn.commit()
# データベース接続を閉じる
conn.close()
# 処理結果と入力データをまとめて返す
output_data = Output(user_id=user_id, query=query, output=processed_text)
return output_data
①で作成したapi_simple_post.pyとの差異は次の箇所です。
# データベースの存在を判定
# データベースの存在を判定
if os.path.exists(DB_PATH):
# データベースが存在する場合
conn = sqlite3.connect(DB_PATH) # DBとの接続を確立
cursor = conn.cursor()
else:
# データベースが存在しない場合、新しく作成する
conn = sqlite3.connect(DB_PATH) # DBとの接続を確立
cursor = conn.cursor()
# テーブルの作成
cursor.execute('''CREATE TABLE data
(USER_ID TEXT, QUERY TEXT, OUTPUT TEXT)''')
# データの挿入
cursor.execute("INSERT INTO data VALUES (?, ?, ?)" ,(user_id, query, processed_text))
# 変更を確定させる
conn.commit()
# データベース接続を閉じる
conn.close()
まず、DB_PATH = 'simple_database.db'というデータベースのパスの有無を判断し、
- DBが無い場合はDBとの接続を作成/確立してからDBを新規作成します
- 有る場合は、そのDBとの接続を確立します
そのあと、cursor.execute("INSERT INTO data VALUES (?, ?, ?)" ,(user_id, query, processed_text))で、user_idとquery、processed_textをDBに格納します。
上記の処理ではまだDBへの変更が確定されていないので(このあたりはDBの処理の細かい話になるので、詳しくは解説しないですが気になる方は、「DB コミットメント」「DB ロールバック」などで調べてみてください)、conn.commit()で処理を確定させます。
最後にconn.close()でDBとの接続を閉じます。
動かしてみる
ここまでで作ったものを動かしてみましょう。
まず、api_post_database.pyを置いているディレクトリ(フォルダ)へ移動し、次のコマンドを打ちます。
uvicorn api_post_database:app --reload
実行して次のような画面が出てきたらOKです。

次にまた、別のコマンドプロンプト(MacやLinuxであればターミナル)を起動し、post_database.pyを置いているディレクトリへ移動します。
そしたら次のコマンドでpost_database.pyを実行させます。
python post_database.py
次のような実行画面が出てきたら成功です。

今回は、ユーザからのクエリを受け付けると、DBに1行追加していく処理を実装しているので、もう一度python post_database.pyを実行すると、DBが1行増えて2行になっていることがわかります。(1回実行するたびに1行追加されていきます。追加したものを削除する処理を実装することもできますが今回は解説しません)

また、api_post_database.pyと同じディレクトリにsimple_database.dbというファイルができていることを確認できます。

これは、
-
post_database.pyからuser_idとqueryをAPI経由でデータを送信(POST)する -
api_post_database.py側でuser_idとqueryを受け取り、queryの文字列に「Processed_」を追加する -
api_post_database.pyは、DBの有無を確認し、DBが無ければDBを新規作成します。 - DBの中に
user_idとquery、processed_textをDBに(1行追加して)格納します -
Outputオブジェクトにもuser_idとquery、processed_textを格納します。 -
Outputデータがoutput_dataとしてAPI呼び出し元のpost_database.pyに返す。 -
post_database.py側でDBへ接続し、DBの中身をPandasのDataFrameに入れて、その中身をprintで表示します
という処理が行われています。
③実装:③ChatGPTを追加する
ようやくChatGPTを導入します。ここで実装するもののイメージは次の通りです。
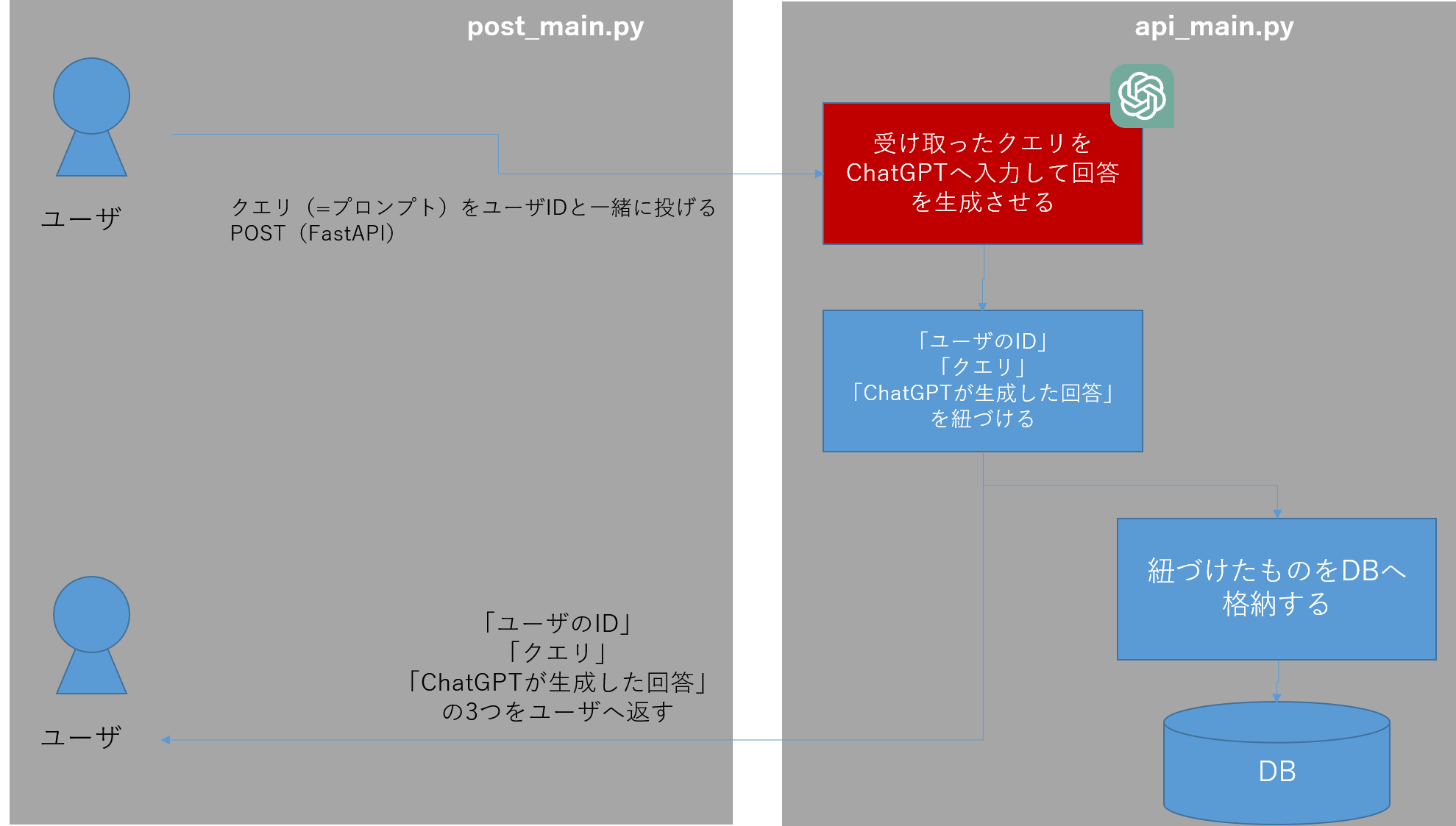
APIにリクエストを投げるパート
import requests
import json
import os
import sqlite3
import pandas as pd
url = "http://localhost:8000/process/" # POSTリクエストを送信するエンドポイントのURL
data = {
"user_id": "example_user",
"query" : "最初に学ぶプログラミング言語でおすすめを理由と合わせて3つ教えてください"
}
response = requests.post(url, json=data)
# レスポンスの内容を表示
#print(response.json())
# ステータスコードを取得
status_code = response.status_code
print("status : " + str(status_code))
# データベースファイルのパス
DB_PATH = 'chat_history.db'
# データベースに接続
conn = sqlite3.connect(DB_PATH)
# SQLクエリを実行し、データを取得
query = "SELECT * FROM data"
df = pd.read_sql_query(query, conn)
# データベース接続を閉じる
conn.close()
# データフレームを表示
print(df)
# chatGPTの回答を一覧で確認する
for _ in range(3):
print()
for output in df["OUTPUT"].values.tolist():
print(output)
基本的に②で作成したpost_database.pyと同じ実装です。ここでは差異の部分を解説します。
data = {
"user_id": "example_user",
"query" : "最初に学ぶプログラミング言語でおすすめを理由と合わせて3つ教えてください"
}
ここのqueryにChatGPTに聞いてみたいことを書きます。今回はおすすめのプログラミング言語を聞いてみることにします。
# chatGPTの回答を一覧で確認する
for _ in range(3):
print()
for output in df["OUTPUT"].values.tolist():
print(output)
ここは、DBに格納されたChatGPTの回答 [OUTPUT]カラムの中身だけを表示させるための処理です。特殊なことは何もしていないです。
APIと受け取ったクエリを処理させるパート
from fastapi import FastAPI
from pydantic import BaseModel
import sqlite3
import os
app = FastAPI()
class Input(BaseModel):
user_id: str
query: str
class Output(BaseModel):
user_id: str
query: str
output: str
# データベースファイルのパス
DB_PATH = 'chat_history.db' # データベース名をchat_historyへ変更
#################################################
############## ↓ChatGPTの処理↓ ###################
#################################################
def chatgpt(query):
# chatGPTを使って回答を生成するための処理
if not query:
# クエリが空だった時は、NULLを文字列として返す
return "NULL"
else:
# クエリに入力されているときは、ChatGPTで返答を作る
import openai
openai.api_key = 'OpenAI APIキー'
response=openai.ChatCompletion.create(
model = "gpt-3.5-turbo",
messages = [{"role": "user", "content": query}]
)
return response['choices'][0]['message']['content']
#################################################
############## ↓ここからメインの処理↓ #################
#################################################
@app.post("/process/")
def main(input_data: Input):
# 入力データを取得
user_id = input_data.user_id
query = input_data.query
# 文字列の加工処理
processed_text = chatgpt(query)
# データベースの存在を判定
if os.path.exists(DB_PATH):
# データベースが存在する場合
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
else:
# データベースが存在しない場合、新しく作成する
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
# テーブルの作成
cursor.execute('''CREATE TABLE data
(USER_ID TEXT, QUERY TEXT, OUTPUT TEXT)''')
# データの挿入
cursor.execute("INSERT INTO data VALUES (?, ?, ?)" ,(user_id, query, processed_text))
# 変更を確定させる
conn.commit()
# データベース接続を閉じる
conn.close()
# 処理結果と入力データをまとめて返す
output_data = Output(user_id=user_id, query=query, output=processed_text)
return output_data
②で作成したapi_post_database.pyをベースにChatGPTの処理を追加しています。
#################################################
############## ↓ChatGPTの処理↓ ###################
#################################################
def chatgpt(query):
# chatGPTを使って回答を生成するための処理
if not query:
# クエリが空だった時は、NULLを文字列として返す
return "NULL"
else:
# クエリに入力されているときは、ChatGPTで返答を作る
import openai
openai.api_key = 'OpenAI APIキー'
response=openai.ChatCompletion.create(
model = "gpt-3.5-turbo",
messages = [{"role": "user", "content": query}]
)
return response['choices'][0]['message']['content']
if-elseがあるのでややこしいように見えますが、やっていることは単純です。
ユーザからのqueryが空の場合もあり得るため、その場合は、文字列として"NULL"を入れるようにしています。queryが空ではない場合は、GPT3.5-turboにクエリをプロンプトとしてそのまま投入しています。
その回答をreturn しています。
あとは、DBの有無の判定をし、DBに対して、user_id、query、processed_textを格納し、OutputオブジェクトとしてAPIの呼び出し元にリターンしてます。
動かしてみる
ここまでで作ったものを動かしてみましょう。
まず、api_main.pyを置いているディレクトリ(フォルダ)へ移動し、次のコマンドを打ちます。
uvicorn api_main:app --reload
実行して次のような画面が出てきたらOKです。

次にまた、別のコマンドプロンプト(MacやLinuxであればターミナル)を起動し、post_main.pyを置いているディレクトリへ移動します。
そしたら次のコマンドでpost_main.pyを実行させます。
python post_main.py
次のような実行画面が出てきたら成功です。注意:①②とは異なり、少し時間がかかります。
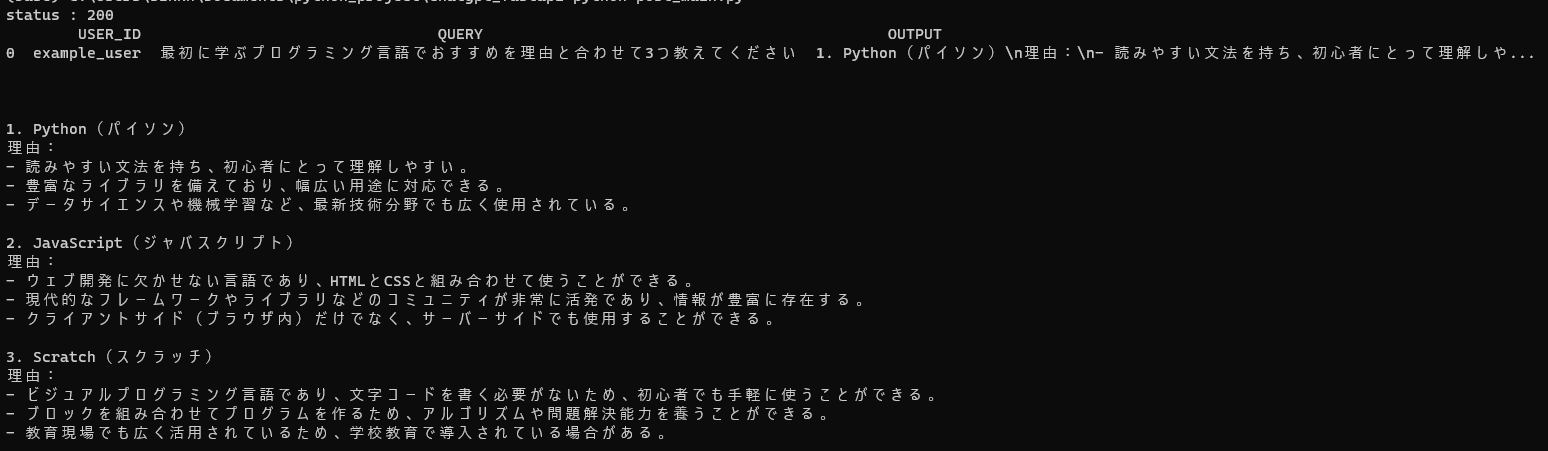
また、api_main.pyと同じディレクトリにchat_history.dbというファイルができていることを確認できます。

これは、
-
post_database.pyからuser_idとqueryをAPI経由でデータを送信(POST)する -
api_post_database.py側でuser_idとqueryを受け取り、ChatGPTが回答を生成、processed_textへ格納する -
api_post_database.pyは、DBの有無を確認し、DBが無ければDBを新規作成します。 - DBの中に
user_idとquery、processed_textをDBに(1行追加して)格納します -
Outputオブジェクトにもuser_idとquery、processed_textを格納します。 -
Outputデータがoutput_dataとしてAPI呼び出し元のpost_database.pyに返す。 -
post_database.py側でDBへ接続し、DBの中身をPandasのDataFrameに入れて、その中身をprintで表示します
という処理が行われています。
まとめ
今回は、FastAPIを使って、API経由でChatGPTとユーザとのやりとりをDBに保存する仕組みを作りました。これ自体は非常にシンプルなアプリケーションですが、これを発展させていくことで、
- 過去の自分のやり取り内容をDBへ記憶させ、その記憶を基に自分用(自分の会社用)のチャットボットを作ることができる
- マーケティングの領域であれば、お客様とのやりとりをDBに格納しておけば、過去のお客様とのやり取りを基にChatGPTが回答を生成してくれるので、よりパーソナライズされたチャットボットができあがり、顧客体験の向上などに活用することができます
- 専門知識などをDB化しておけば、その知識を基にChatGPTが回答を生成するFAQアプリケーションを作ることができる
- 会社のルールなどがテキスト化されているのであれば、それをDBに格納しておけば、そのルールを基にChatGPTが回答を作ってくれるので、社内で不明点があったらChatGPTに聞いてみる、といった活用方法が考えられます
- 保険や不動産、ケータイなどルールや契約形態が複雑で難しいような業種であれば、各種データをDB化しておくことで、ChatGPTがそのDBを読み取って、お客様からの問い合わせに回答してくれるFAQを実現することができます。
といった応用先に使うことができます。
個人的には、サーバとクライアント間でのやりとりをAPIでさせることを初めて実装したので、そういうものを作った経験として勉強になりました。