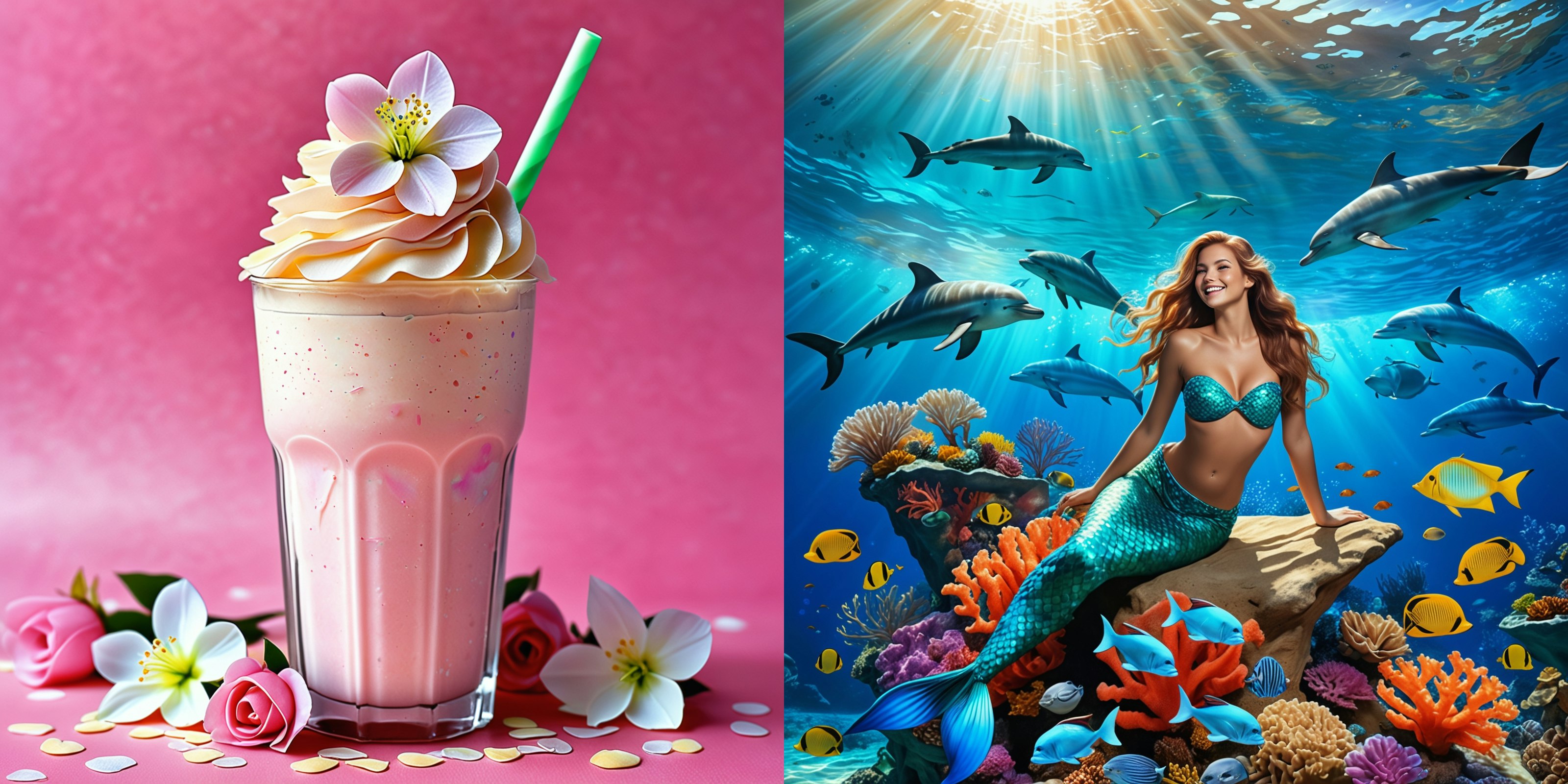
この記事について
- AI初心者による初心者のための記事です
-
Python x Stable Diffusionを使って上記の様な画像を生成するのに必要な環境構築の例とサンプルコードを紹介します
- ご自身でアレンジすれば2D系やセクシー系の生成もできると思います
- 実行環境としてAWSのEC2に環境を構築して利用します
-
GPUを積んだ
g4dn系統のインスタンスを利用するので、最低でも数百円から数千円かかります - Google Colabを使えば無料?安価?で動かせるかもしれませんが、未検証です
- 高価なGPUをお持ちであればローカルマシンでも実行可能かもしれませんが、汎用のPCでは処理が重すぎて生成はほぼ不可能とお考えください
-
GPUを積んだ
- 自前のモデルの開発は行いませんが、huggingfaceやcivitaiにある豊富なモデルを活用できる様になるので、十分楽しめると思います
- 高画質、高品質な画像生成のための工夫も少し盛り込んでいます
- 筆者はAIエンジニアでもPythonエンジニアでも、インフラやクラウドに強いエンジニアでもないため、構築やコードにベストでない箇所が紛れていると思いますので、コメント等でご指摘いただけると喜びます
前提知識
- サンプルコードはPythonエンジニアでなくても触れると思います
-
pipやvenv、初歩的なlinuxコマンドを使ったことがあると◎
-
- EC2のインスタンスを立てたり、最低限のセキュリティルールの設定 (SSH接続やIP制限など) については他記事などで調べてください
- ライセンスや権利関連、NSFW (閲覧注意系) コンテンツの扱いには十分ご注意ください
1. 環境構築
1-1. EC2インスタンス作成
おすすめ構成は以下の通りです
- OS :
Ubuntu 22.04 LTS, SSD Volume Type- 2025/5現在、パッケージやドライバの対応状況の問題などがあり
24.04やDeep Learning Base系ではなく22.04が良いそうです - Architecture :
64-bit
- 2025/5現在、パッケージやドライバの対応状況の問題などがあり
- Instance type :
g4dn.2xlarge-
g4dn系統であればどれでも動きます -
4xlargeなどの更にメモリが大きなインスタンスがありますが生成速度には大差ありません -
g5系統のインスタンスも動作を確認しており、こちらは生成速度が体感で倍くらい早くなります -
t4もNvidia GPUを積んだインスタンスですが、すぐにシステムごとクラッシュするため使い物になりませんでした (ドライバの設定が間違ってるなど初歩的なミスの可能性はありますが未調査) - EC2で初めてGPUインスタンスを使う場合は、利用申請が必要で、1-2日ほど待たされます
-
- Network setting
-
Allow SSH traffic from, Anywhereでもいいので最低限の設定をすることをお勧めします
-
- Configure storage :
50 - 100GB, gp2- サンプルコードは50GBくらいでも余裕で動くと思います
- 他モデルで遊びたい場合は多めに設定すると快適です (画像生成モデルはひとつで10GB程あります)
- あとから増やすこともできます
1-2. コードのクローンとパッケージの準備
- EC2インスタンスにSSH接続したら、コードをこちらのリポジトリから
cloneするgit clone https://github.com/KazmaWed/diffusers_trial.git -
setpu.mdに従ってPython venvの構築とpip install、CUDAドライバインストールを行う
1-3. モデル (LoRA) の取得
画像生成には一番重要なベースモデル (Checkpoint)の他に、仕上がりを微調整するために軽量なLoRAを設定することができます。
ベースモデルはコードの実行時に自動で取得されますが、LoRAは以下の手順で環境に配置する必要します。
- civitaiのDownloadボタンよりLoRAファイルをローカルPCへダウンロード
- EC2インスタンスの
model/sdxl/lora/へLoRAファイルをアップロード- とりあえずで
scpコマンドを使ってもよいですが、コードのアレンジなどをする場合はVSCodeのRemote Explorerなどを使うのが圧倒的におすすめです - citivaiの認証設定をするとインスタンスから直接
wgetなどもできるっぽいです
- とりあえずで
2. 生成実行
さてここまで来たら、あとはプロジェクトのルートリポジトリでmain.pyを実行するのみです!
python3 diffusers_trial/main.py
result/ディレクトリが生成され、連番でpngファイルが生成されると思います。
初期設定では1600pxの画像が3枚画像が生成されると思います。
初回実行時にはモデルのダウンロードが走るため、それだけで数分待つと思います。
ダウンロード完了後は、1枚あたり30秒-1分くらいで画像が生成されます。
うまくいかない場合はvenvが正しく有効化されているか、pipパッケージのインストールが完了しているかなど確認してください。
3. カスタマイズ
サンプルコードの一部を変更すれば、簡単にお好みの画像を生成できます。
欲しい画像のために必要な設定や、画像の崩壊 (人体や物の構造が想定外の状態になる) を起こさないためのコツを記載します。
3-1. プロンプトの設定
どんな画像が欲しいかという、最も基本的な設定です。
base_prompts_dictに指示文を渡します。
base_prompts_dict = {
"prompts": (
# サンプルプロンプト1
"photorealistic,sakura cream milk ice shake frappe, p1nk1r1fl0wers, made out of iridescent flower petals, high quality, masterpiece,"
# サンプルプロンプト2
# "photorealistic,graceful mermaid sits on a rock,playful dolphins swim nearby, coral reef, colorful fish, sunlight through the water, shimmering patterns on the sandy ocean floor,"
),
"negative_prompts": (
"(malformed),(extra finger:2),(malformed hands:2),(malformed legs:2),(malformed arms:2),(missing finger:2),(malformed feet:2),(extra_legs),"
"low resolution,worst quality,low quality,normal quality,"
"mirror, reflection, extra person, text, watermark, logo, caption,label, letters, writing,monochrome,"
),
"loras": {
detail_lora: detail_lora_weight,
},
}
-
prompts- メインの指示文です
- 「さくらアイスシェイク」など、欲しい画像に関する具体的な説明を、英文または英単語のコンマ繋ぎで渡します
- 実際にどの様な記載をすれば良いかはcivitaiの作例の
Promptを参考にするといいです - 長さに限度があるので、入れたい要素を盛り込むためにはテクニックが求められます
-
negative_prompts- 避けたい画像に関する説明を英文または英単語のコンマ繋ぎで渡します
- 「低画質」「モノクロ」など一般的に避けたい特徴を含めつつ、「(女性を描きたい場合は) 男性」「(明るい画像が欲しいときは) 陰」などの細かな指示を追加して、出力が期待通りになる確率を高めます
- こちらもcivitaiの作例の
Negative promptを参考にするといいです
-
loras- 先述のLoRAのパスと、LoRAを効かせる強度を
dictで渡します -
サンプルコードではディテールをいい感じに美しくしてくれるLoRAを
1.4の強度で効かせています
- 先述のLoRAのパスと、LoRAを効かせる強度を
-
scale_model,scale_prompts_dict- 画像生成時とは異なるモデルやプロンプトをスケールアップ時に適用する際には、ここを変更します
- 生成時には背景やリアリティに強みのあるモデル、スケールアップ時には人の顔が好みのモデル、という組み合わせをすると良い感じになることもあります
3-2. その他の設定について
プロンプト以外の細かな調整を行います。ここの設定値によっても想像以上に仕上がりが大きく変わるので、プロンプトと同じかそれ以上に大事なので、欲しい絵に対する最適値を慎重に探ってください。
batch_size: int = 1
iteration: int = 3
base_size = (1024, 1024)
scale_enhance_tuple_list = [
(1600, 1600, 0.1),
]
steps: int = 40
cutoff_step = 20
guidance: int = 8
clip_skip: int = 2
-
batch_size: int = 1- 一度に生成する画像の数です
- 似た画像を複数生成して、その中からベストなものを選びたい時は調整します
- モデルによっては
1でしか動かせないものもある様です
-
iteration: int = 3- 画像生成のループを回す回数です
- 異なる画像をたくさん生成したいときに調整します
-
base_size = (1024, 1024)- モデルが出力する画像のサイズの指定です
- 自由に設定できるわけではなくモデルごとの最適な数値があるようです、モデルの公式ページやGPTに聞いて正しい値を設定してください
- (異なる値でも画像生成自体を行えますが、急激に崩壊する率が高くなります)
-
scale_enhance_tuple_list = [ (1600, 1600, 0.1) ]-
base_sizeのサイズから、ここで指定した画像サイズ (1600px) へスケールアップします - 3番目の値
0.1は、拡大時に画質が落ちない様に補完する強度ですが、高過ぎても画像が崩壊するので、最適な数値を探ります、目安は0.1から0.5の間くらい -
[ (1600, 1600, 0.1), (2400, 2400, 0.1) ]の様に複数段階でスケールアップできます - 空配列を渡せばスケールアップ処理をスキップします
-
-
steps: int = 40- 画像生成までにかけるステップ数です
- 下げると全体の処理時間は減りますが、下げ過ぎると画像のクオリティも下がりがちです
- 上げると処理時間は伸びますが、画像のクオリティも上がりやすいです
-
上げ過ぎるとこれまた画像が崩壊するので、だいたい
20から50くらいの間で調整します
-
cutoff_step = 20-
stepsで指定した画像生成ステップのうち「プロンプトに従うステップ数」を指定します-
20の場合は「生成の初めの20ステップはプロンプトに従い、残りは成り行きに任せる」という意味です - 不思議なもので、画像生成の後半ではいくらか「プロンプトに従わないことを許容する」方が、仕上がりがよくなります
- ランダム性を持って生成された画像に対して厳格にプロンプトに従わせようとすると、ズレが発生したときに崩壊につながる様です
-
-
-
guidance: int = 8- プロンプトに従わせる強度です
- 上げると (うまく行ったときには) 背景や姿勢、その他の細かなディテールが指示通りになりやすいですが、上げ過ぎると画像が崩壊しやすくなります
- 下げると指示から少し離れた出力がされやすくなりますが、崩壊せずナチュラルに仕上がる確率が上がります
-
clip_skip: int = 2- 「生成ステップの最後から何番目の生成物を使うか」という設定です
-
2の時は、最後の1枚ではなくその1つ前の生成物を出力します -
1でも問題ない場合が多いですが、モデルによっては2の方がナチュラルな画像が得られやすい様です
3-3. モデルの設定
今回はStable Diffusionのモデルの中でも、特にリアルで高画質な画像生成に強いSDXL 1.0ベースのモデルを使いました。
base_model: str = "SG161222/RealVisXL_V5.0_Lightning" # huggingface上のモデル名
detail_lora: str = "model/sdxl/lora/add-detail-xl.safetensors" # ローカルパス
-
RealVisXL V5.0
- 写真の様にリアルな画像生成に強いモデルです
-
Detail Tweaker XL
- ディテールがなんだか良い感じの仕上がりになるLoRAです
「イラスト調画像を生成したい」「日本人の美少女を生成したい」など、用途によってモデルを変えて、それに合うLoRAを探すと良いです。
組み合わせは基本的に自由ですが、モデルとLoRAは同じベースモデル (例:SDXL 1.0) である必要があります。
その他に試すと面白いこと
Controlnet
画像生成の指示をテキストのプロンプトではなく、他の画像をもとにして新しい画像を生成することができます。(今回実装しているスケールアップ後の補完もその一つです)
例えば「同じ形だけど全く異なる材質で再生成」や「元画像と全く同じポーズで他の人を生成」したいときにはControlnetが便利です。
同じ形を生成したい場合はCannyが、同じポーズを生成したい場合はOpenposeが便利です。
実装方法はそれぞれリンク先に例があります。
LoRAの作成
画像をいろいろな微調整するのに便利なLoRAですが、比較的小さなデータ量で自作することができます。
例えば特定の背景の画像よりリアルに生成したいとか、好みの顔の画像をたくさん生成したいとか、そういった場合はLoRAを作成するのが良いです。
diffusersリポジトリのこちらがLoRA作成の実行ファイルです。学習データの作成方法や実際に使い方についてはGPTに任せるとします。
おわりに
ここに記載していないことも色々と試して、私はAWSからの請求が3万円ほどになってしまいました…
最近はChatGPTやSoraなどのサービスを使う、とエンジニアでなくても簡単に高画質な画像生成ができてしまいますよね。私は「Stable Diffusion (を含む拡散モデル) ってこんなに凄いんだ!」と簡単に考えていましたが、実際に試してみるとただプロンプトを投げるだけでは思った通りに画像が吐き出されません。
モデルの選定やその他設定値のチューニングを含めていろいろなテクニックやアプローチがあり、とても奥深いものだとという気づくと共に、既存のサービスの凄さに驚きました。
感想やご指摘などあればぜひコメントください!