「Zabbixで1つのディスカバリリールに広いIPレンジのネットワークディスカバリを設定するとディスカバリに時間がかかる。」こんな問題に遭遇した方も何人かいらっしゃるかと思います。
これはZabbixのネットワークディスカバリが1ディスカバリルールは1ディスカバリプロセスで処理する仕様になっているからです。
その為、ディスカバリプロセスを増やしてもディスカバリ時間は短縮されません。
※:ディスカバリルールが複数ある場合は、ディスカバリプロセスの数を増加させるのは有効です。
上記について下記の改善要望を登録しましたが、今だ投票数0で改善される見通しが立っていません。
ZBXNEXT-2732 Load balancing of the discovery process
現在の仕様「1ディスカバリルールは1ディスカバリプロセスで処理」でディスカバリ時間を短縮するには、広範囲のIPレンジを細かく分割して登録すれば良いのですが、いちいち細かく計算するのは面倒ですし時間がかかります。
それならZabbixAPIの「drule.create」を使ってIP範囲を分割して登録するスクリプトを作成すれば良いのではないかと考え、IP範囲を分割するロジックを考えたらできてしまいました。
先程のZBXNEXT-2732にも添付してあるのですが、スクリプトはPythonで下記になります。
# -*- coding: utf-8 -*-
import sys, json, urllib2
headers = {"Content-Type":"application/json-rpc"}
# login
def login(usr, pw, url, headers):
auth_post = json.dumps({'jsonrpc':'2.0', 'method':'user.login', 'params':{'user':usr, 'password':pw}, 'auth':None, 'id': 1})
req = urllib2.Request(url, auth_post, headers)
res = urllib2.urlopen(req)
jdata = json.loads(res.read())
if "error" in jdata:
print auth_post
error = jdata["error"]
print error["message"]
print error["code"]
print error["data"]
quit()
return jdata["result"]
# file read
def get_drule(flnm):
f = open(flnm)
jdata = json.load(f)
f.close()
return jdata
# get name
def get_name(jdata):
params = jdata["params"]
return params["name"]
# set params
def set_params(jdata, iprange, name):
params = jdata["params"]
params["iprange"] = iprange
params["name"] = name
return params
# chk iprange
def chk_iprange(iprange, out):
if iprange.find("/")==-1:
print 'Bad IP Range: '+iprange
print ' "/" does not exist in the string'
return False
if iprange.count("/")!=1:
print 'Bad IP Range: '+iprange
print ' "/" there is more than one in a string'
return False
tmp = iprange.split("/")
out[0] = tmp[0]
out[1] = tmp[1]
if not out[1].isdigit():
print 'Bad IP Range: '+iprange
print ' prefix is not numeric'
return False
if int(out[1]) <= 0 or int(out[1]) >= 24:
print 'Bad IP Range: '+iprange
print ' prefix Range : 0 < prefix < 24'
return False
tmp = out[0].split(".")
out[2] = tmp[0]
out[3] = tmp[1]
out[4] = tmp[2]
out[5] = tmp[3]
if not out[2].isdigit():
print 'Bad IP Range: '+iprange
print ' octet 1 is not numeric'
return False
if int(out[2]) < 0 or int(out[2]) > 255:
print 'Bad IP Range: '+iprange
print ' octet 1 Range : 0 <= octet 1 <= 255'
return False
if not out[3].isdigit():
print 'Bad IP Range: '+iprange
print ' octet 2 is not numeric'
return False
if int(out[3]) < 0 or int(out[3]) > 255:
print 'Bad IP Range: '+iprange
print ' octet 2 Range : 0 <= octet 2 <= 255'
return False
if not out[4].isdigit():
print 'Bad IP Range: '+iprange
print ' octet 3 is not numeric'
return False
if int(out[4]) < 0 or int(out[4]) > 255:
print 'Bad IP Range: '+iprange
print ' octet 3 Range : 0 <= octet 3 <= 255'
return False
if not out[5].isdigit():
print 'Bad IP Range: '+iprange
print ' octet 4 is not numeric'
return False
if int(out[5]) < 0 or int(out[5]) > 255:
print 'Bad IP Range: '+iprange
print ' octet 4 Range : 0 <= octet 4 <= 255'
return False
return True
# chk split
def chk_split(prefix, sp):
if not sp.isdigit():
print 'Bad split: ' + sp
print ' split is not numeric'
return False
if int(sp) <= 1 or int(sp) > 24:
print 'Bad split Range: ' + sp
print ' split Range : 1 <= split <= 24'
return False
if int(sp) <= int(prefix):
print 'Bad prefix(' + prefix + ') & split(' + sp + ')'
print ' prefix < split'
return False
return True
# create drule
def create_drule(url, jdata, iprange, sp, name):
tmp = ["","","","","",""]
if not chk_iprange(iprange, tmp):
return False
ip = tmp[0]
prefix = tmp[1]
o1 = tmp[2]
o2 = tmp[3]
o3 = tmp[4]
o4 = tmp[5]
if not chk_split(prefix, sp):
return False
sum = (int(o1) << 24 | int(o2) << 16 | int(o3) << 8 | int(o4) ) & (0xFFFFFFFF - (2 ** (32 - int(sp))))
sum = sum >> (32-int(prefix))
sum = sum << (32-int(prefix))
for i in range(0, 2 << (int(sp) - int(prefix) - 1)):
a = sum | (i<<8) * (2 ** (24 - int(sp)))
# split
o1 = (a & 0xFF000000) >> 24
o2 = (a & 0x00FF0000) >> 16
o3 = (a & 0x0000FF00) >> 8
o4 = 0
tmp = str(o1) + "." + str(o2) + "." + str(o3) + "." + str(o4)
jdata["params"] = set_params(jdata, tmp + "/" + sp, name + str(i+1))
# debug
# print json.dumps(jdata)
req = urllib2.Request(url, json.dumps(jdata), headers)
res = urllib2.urlopen(req)
ret = json.loads(res.read())
if "error" in ret:
print name + str(i+1)
print tmp
error = ret["error"]
print error["message"]
print error["code"]
print error["data"]
return False
return True
# main
if len(sys.argv) != 7:
print "Usage : python splite_drule.py <url> <user> <password> <iprange> <split> <json file>"
quit()
jdata = get_drule(sys.argv[6])
jdata["auth"] = login(sys.argv[2], sys.argv[3], sys.argv[1], headers)
name = get_name(jdata)
ret = create_drule(sys.argv[1], jdata, sys.argv[4], sys.argv[5], name)
if ret:
print "Ok"
else:
print "Ng"
因みにPythonは殆ど書いたことが無く書き方がPythonっぽくないようです。(笑)
使い方は下記の通りで、url、ユーザ、パスワード、IP範囲、分割範囲、drule.createを書いたjsonファイルを指定します。
python splite_drule.py <url> <user> <password> <iprange> <split> <json file>
<url> : http://192.xxx.xx.xxx/zabbix/api_jsonrpc.php
<user> : admin
<password> : zabbix
<iprange> : 192.168.0.0/16
<split> : 19
<json file> : /tmp/drule.json
以下、実行例
この状態で…
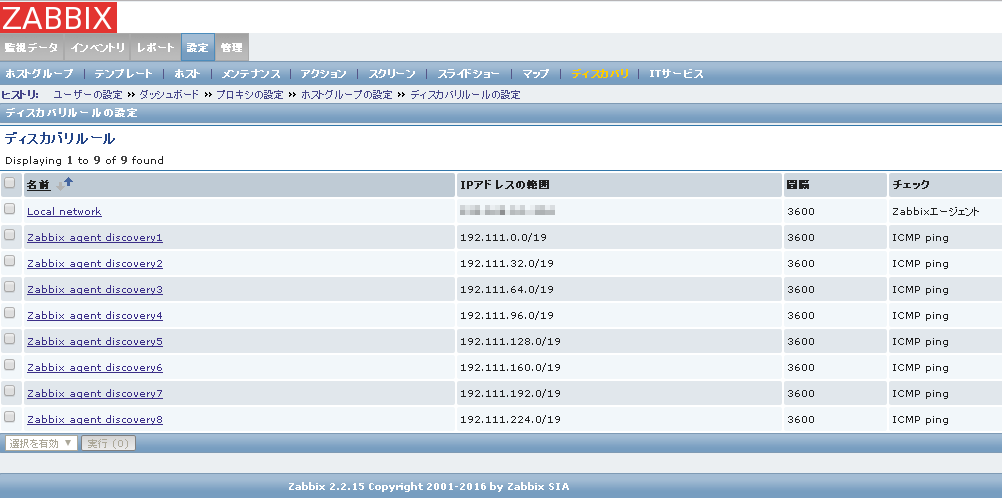
以下を実行すると…
]# python splite_drule.py http://xxx.xxx.xxx.xxx/zabbix/api_jsonrpc.php admin zabbix 192.111.1.0/16 19 /usr/local/src/dru
le.json
Ok
こんな感じにIP範囲が分割されて登録されます。
実行エラーはこんな感じで出ます。(2重登録のエラーになります。)
]# python splite_drule.py http://xxx.xxx.xxx.xxx/zabbix/api_jsonrpc.php admin zabbix 192.111.1.0/16 19 /usr/local/src/drule.json
Zabbix agent discovery1
192.111.0.0
Invalid params.
-32602
Discovery rule "Zabbix agent discovery1" already exists.
Ng
上記で使用したdrule.createを書いたjsonファイルは下記になります。
{
"jsonrpc": "2.0",
"method": "drule.create",
"params": {
"name": "Zabbix agent discovery",
"iprange": "iprange",
"dchecks": [
{
"type": "12"
}
],
"status" :"1"
},
"auth": "auth",
"id": 1
}
例ではICMP pingを使用していますが、他のチェック(FTP、HTTP、…、Zabbixエージェント)でも可能です。
因みに、drule.jsonを一から手で作ると面倒と言う方は元になるディスカバリルールをWebインタフェースから登録して、ZabbixAPIのdrule.get登録したルールを取得して下さい。
取得した結果から不要なパラメータせばOKです。(ReadOnly項目は除外してください。)
詳しくはZabbixAPIのDiscovery check objectを見て欲しいです。