はじめに
最近機械学習をはじめました!
必須ライブラリであるPandas,numpy,matplotlibの使い方を覚えるのが大変ですね。。。
なのでPandasの使い方早見表を作成しました!
- 前半:機能一覧のグラフ
- 後半:前半に紹介した機能の実際の使用例
をまとめました。
各機能の細かいところ(引数とか)には触れません!
機械学習を行う際によく使用する用法なので、初心者の方は目を通してPandasでできることをイメージしてみてください。
中級者以上の方は「あれってPandasでどうやるんだっけ?」というときに使っていただければ幸いですm(_ _)m
機能一覧
1.データ読み込み/書き込み編
| Action | Syntax |
|---|---|
| CSVファイルをリストに読み込み | sample = pd.read_csv('sample.csv') |
| リストをCSVファイルに書き込み | sample.to_csv('sample2.csv') |
| excelファイルをリストに読み込み | sample = pd.read_excel('sample.xlsx') |
| リストをexcelファイルに書き込み | sample.to_excel('sample2.xlsx') |
2.データ分析編
- "sample"が分析対象データのDataFrameです
- import pandas as pdを実行していることを前提としています
| Action | Syntax |
|---|---|
| 先頭数行を表示 | sample.head() |
| 末尾数行を表示 | sample.tail() |
| ソートして表示 | sample.sort_values(by=['特徴量'], ascending=True) |
| 特徴量の種類と数を表示 | sample.shape |
| 特徴量の種類数を表示 | sample.nunique() |
| 特徴量の種類を一覧で表示 | sample['特徴量'].drop_duplicates() |
| インデックス情報を表示 | sample.index |
| カラム(ヘッダ)を表示 | sample.columns |
| 欠損値の有無を確認 | sample.isnull().sum() |
| 該当特徴量の平均値 | sample['特徴量'].mean() |
| 該当特徴量における値の出現回数 | sample['特徴量'].value_counts() |
| 該当特徴量における条件を満たすデータのみ表示 | sample[sample['特徴量'] <条件式> ] |
| 基礎統計量を表示 | sample.describe() |
| ヒストグラムを表示 | sample['特徴量'].hist(bins=<グラフの棒の数>) |
| クロス集計する | pd.crosstab(sample['特徴量1'],sample['特徴量2']) |
| 割合をクロス集計で表示 | pd.crosstab(sample['特徴量1'],sample['特徴量2']).apply(lambda x: x/x.sum(), axis=1) |
| 相関を表示 | sample.corr() |
| 散布図グラフを表示 | pd.plotting.scatter_matrix(sample) |
3.データ加工編
| Action | Syntax |
|---|---|
| 行を削除 | sample2 = sample.drop(行番号,axis=0) |
| 列を削除 | sample2 = sample.drop('列のヘッダー名',axis=1) |
| 複製を作成 | sample.copy() |
| 該当特徴量を抽出 | sample2 = sample[['特徴量1','特徴量2',.....]] |
| 特徴量同士を計算して新しい特徴量を作成 | sample['新特徴量'] = sample['特徴量1'] <演算子> sample['特徴量2'] |
| 該当特徴量に対して関数を適用して新特徴量を作成 | sample['新特徴量'].apply( lambda x : <関数 or 式> ) |
| 欠損値があるデータを削除 | sample.dropna() |
| 欠損値を補完 | sample.fillna(value=<補完値>) |
| 被っているデータを削除 | sample.drop_duplicates() |
使用例
ここではSIGNATEの練習問題データを例として使用します。
お弁当の需要予測
1.データ読み込み/書き込み編
import pandas as pd
sample = pd.read_csv('train.csv')
これ以外は割愛させていただきます。。。
2.データ分析編
先頭数行を表示 sample.head()
sample.head()
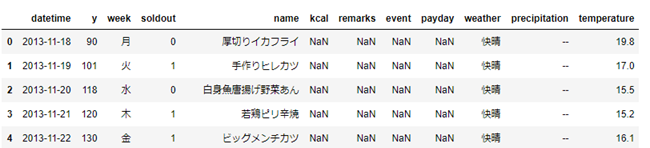
引数に数値を渡すことで、表示する行数を調整することが可能です。
(デフォルト5行)
末尾数行を表示 sample.tail()
sample.tail()
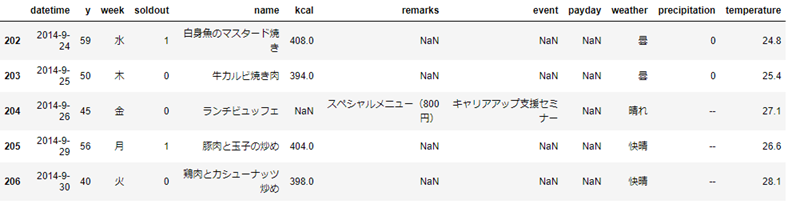
引数に数値を渡すことで、表示する行数を調整することが可能です。
(デフォルト5行)
ソートして表示 sample.sort_values(by=['特徴量'], ascending=True)
# kcalでソート
sample.sort_values(by=['kcal'], ascending=True)
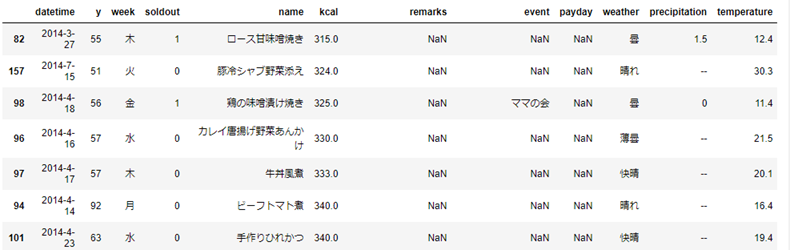
ascending=Falseにすると降順でソートされる
特徴量の種類と数を表示 sample.shape
# ()を付けないように注意してください
sample.shape
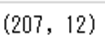
特徴量の種類数を表示 sample.nunique()
sample.nunique()

特徴量の種類を一覧で表示 sample['特徴量'].drop_duplicates()
sample['name'].drop_duplicates()

インデックス情報を表示 sample.index
# ()を付けないように注意してください
sample.index

このデータのインデックスは1刻みで0から207まであることがわかります
カラム(ヘッダ)を表示 sample.columns
# ()を付けないように注意してください
sample.columns

ヘッダを配列として取得することできます
欠損値の有無を確認 sample.isnull().sum()
sample.isnull().sum()
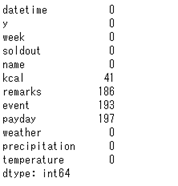
これを見るとkcal、remarks、events、paydayに欠損がありますね
該当特徴量の平均値 sample["特徴量"].mean()
# kcalの平均値を求める
sample['kcal'].mean()
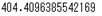
# データ全ての平均値を求めることもできるが、文字データなどは残念な感じになる
sample.mean()

mean()を以下の通り置き換えると、合計値などを求めることが可能
| メソッド | 求めることができる値 |
|---|---|
| sum() | 合計値 |
| min() | 最小値 |
| max() | 最大値 |
| var() | 分散 |
| std() | 標準偏差 |
これらの値は後述する基礎統計を求めた方が手っ取り早くわかります。
該当特徴量における値の出現回数 sample["特徴量"].value_counts()
sample['week'].value_counts()

該当特徴量における条件を満たすデータのみ表示 *sample[sample["特徴量"] <条件式> ]*
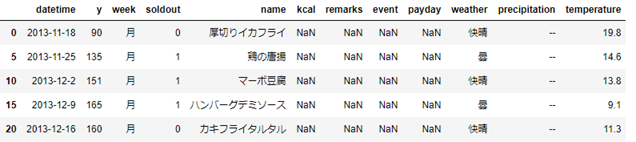
# weekが月のデータのみを表示
# 全行表示されることを防ぐためにhead()をつけています
sample[sample['week'] == '月'].head()
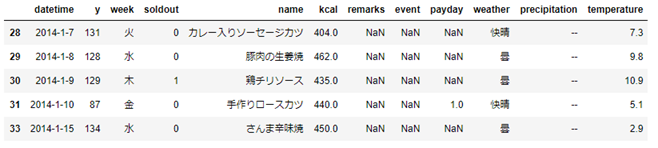
# kcalが400以上のデータのみを表示
sample[sample['kcal'] >= 400 ].head()
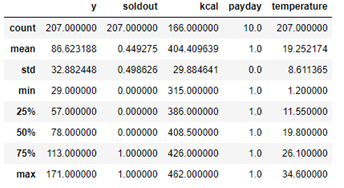
基礎統計量を表示 sample.describe()
数値データの基礎統計を表示します
sample.describe()
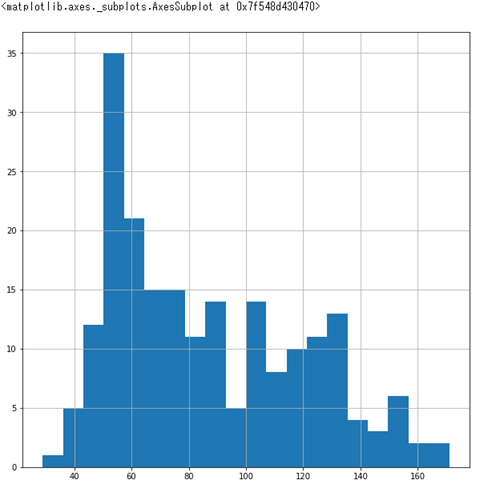
ヒストグラムを表示 *sample["特徴量"].hist(bins=<グラフの棒の数>)*
# figsizeに(横サイズ,縦サイズ)のタプルを渡すとグラフのサイズを指定することができます
# ここではfigsize 10:10 棒が20本のヒストグラムを表示します
sample['y'].hist(bins=20,figsize=(10,10))
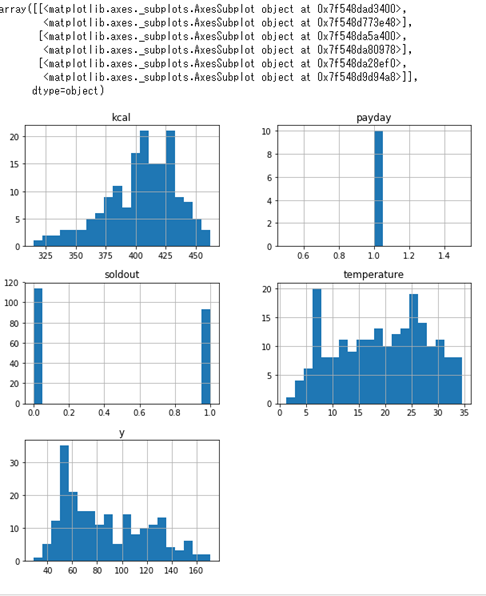
一度に全データのヒストグラムを表示することも可能です
sample.hist(bins=20,figsize=(10,10))
クロス集計する pd.crosstab(sample["特徴量1"],sample["特徴量2"])
そもそもクロス集計とは、特定の二つないし三つの情報に限定して、データの分析や集計を行なう方法です
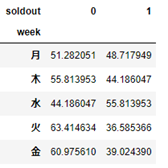
# 横軸にweek、縦軸にsoldoutが来るようにクロス集計を行います
pd.crosstab(sample['week'],sample['soldout'])
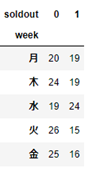
クラス集計をすることにより、各weekにおいてsoldout=0/1がどのくらいあるかを可視化することが可能です
割合をクロス集計で表示 pd.crosstab(sample["特徴量1"],sample["特徴量2"]).apply(lambda x: x/x.sum() * 100, axis=1)
上記のクラス集計では、該当データの数までしかもとめることができませんでした
applyを使用して割合をクロス集計で表示する方法についても記載します
pd.crosstab(sample['week'],sample['soldout']).apply(lambda x: x/x.sum() * 100, axis=1)
相関を表示 sample.corr()
sample.corr()
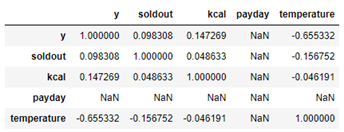
表示されるのは数値データ同士の相関です
paydayは日時データなのそのままではうまく処理されません
見栄えが悪いのでpayday以外を抽出して、相関を表示します
sample_corr = sample[['y','soldout','kcal','temperature']]
sample_corr.corr()
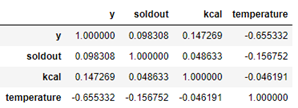
正直これだけだとよくわかりません
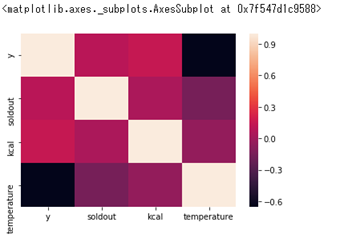
seabornでヒートマップにするとわかりやすくなります
import seaborn as sns
sns.heatmap(sample_corr.corr())
散布図グラフを表示 pd.plotting.scatter_matrix(sample)
# figsizeを10:10で指定しています
pd.plotting.scatter_matrix(sample, figsize=(10,10))
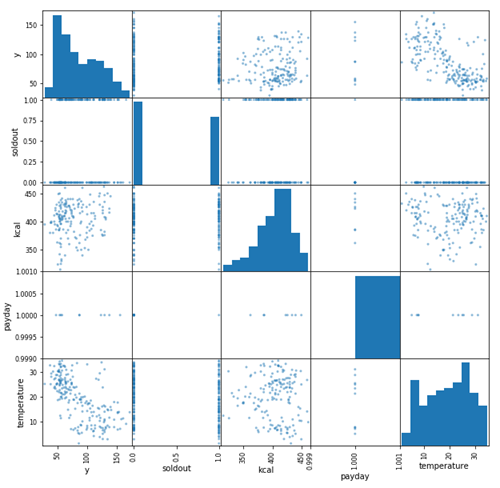
右下がりの対角線上は各特徴量のヒストグラムになります
3.データ加工編
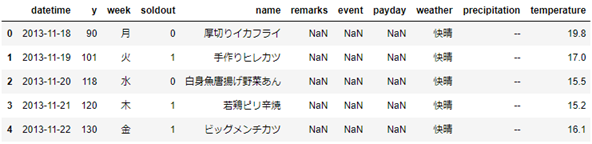
行を削除sample.drop(行番号,axis=0)
sample.head()
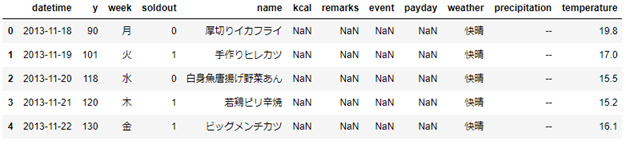
# 1行目を削除(インデックスは0のため、引数に0を指定)
sample2 = sample.drop(0, axis=0)
sample2.head()
列を削除sample.drop("列のヘッダー名",axis=1)
sample.head()
# kcalの列を削除
sample2 = sample.drop("kcal", axis=1)
sample2.head()
複製を作成sample2 = sample.copy()
sample2 = sample.copy()
sample2 = sampleでコピーした場合とcopy()でコピーした場合の挙動の違い
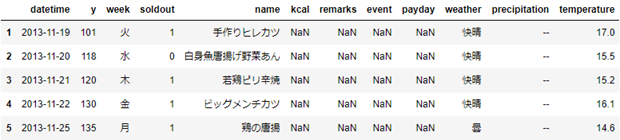
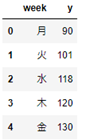
該当特徴量を抽出sample2 = sample[['特徴量1','特徴量2',.....]]
# weekとyを抽出する
sample2 = sample[['week','y']]
sample2.head()
引数として配列を渡すため、[]が2重になることに注意してください
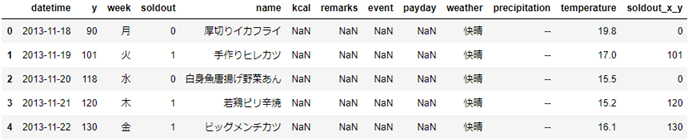
特徴量同士を計算して新しい特徴量を作成*sample['新特徴量'] = sample['特徴量1'] <演算子> sample['特徴量2']*
# soldoutとyの値を掛け合わせたものを新しい特徴量とします
sample['soldout_x_y'] = sample['soldout'] * sample['y']
sample.head()
該当特徴量に対して関数を適用して新特徴量を作成*sample["特徴量"].apply( lambda x : <関数 or 式> )*
# yを10倍したものを新しい特徴量とします
sample['10y'] = sample['y'].apply(lambda x: x * 10)
sample.head()

欠損値があるデータを削除sample.dropna()
sample.isnull().sum()

sample2 = sample.dropna()
sample2.isnull().sum()

欠損値を補完*sample.fillna(value=<補完値>)*
sample.head()
sample2 = sample.fillna(value='unknown')
sample2.head()
