概要
人工知能という分野に対して強い興味があり、自分の手で実装できるようになれればと思っていた。自分の親がTXTという5人組のアイドルグループが好きなので、ちょうどいいと思い、このメンバーを予測できるよな学習モデルを作ろうと思ったのがきっかけだった。
学習データの取得
深層学習だろうが機械学習だろうが、どちらにしろまず学習データを持っておかないといけない。てことでスクレイピングで5人のメンバーを画像データを取得するところから始めた。
import requets
from bs4 import BeautifulSoup
import os
from urllib.request import Request, urlopen
import cv2
page = 1
url_link = []
bash_url = "任意のurl"
header = {"Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36"}
while page <= 50:
next_url = base_url + str(page)
res = requests.get(base_url)
html = BeautifulSoup(res.text, "lxml")
img_path = html.find_all("img")
for url in img_path:
src = url.get("src")
if "https" in src:
if "jpeg" or "png" in src:
print(src)
url_link.append(src)
page += 1
time.sleep(2)
def url_to_image(url):
req = Request(url)
try:
resp = urlopen(req)
except:
return None
image = np.asarray(bytesarray(resp.read()), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
return image
def face_detect_and_save(urllist, name, num):
face_cascade_path = "haarcascade_frontalface_default.xml"
face_cascade = cv2.CascadeClassifier(face_cascade_path)
for url in urllist:
if num == 1500:
break
print(url)
image = url_to_image(url)
if image is None:
return None
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(image_gray, scaleFactor=1.2, minNeighbors=2)
if len(faces) > 0:
shape = image.shape
img_h, img_w = shape[0], shape[1]
for x, y, w, h in faces:
face = image[max(y-40, 0):min(h+40, img_h), max(x-40, 0):min(x+w+40, img_w)]
try:
if ".png" in url:
cv2.imwrite(DOWNLOAD_DIRECTORY+"/"+name+"/"+name+str(num)+".png", face)
else:
cv2.imwrite(DOWNLOAD_DIRECTORY+"/"+name+ "/"+name+str(num)+".jpg", face)
num += 1
except:
continue
time.sleep(1)
コードはかなり汚いがとりあえす学習ようのデータが集めれればよかったので、特定のサイトからメンバーの画像データが集めれればそれでよかった。サイトには人物以外の画像も含まれている可能性が高いのでそこはOpencvの力を借りて人の顔が写ってる画像のみをファイルに保存しいくことにした。
が手に入ったデータは一人あたり多くて120枚程度しか手に入らなかった。少し不安だったので画像データを水増しすることにした。
from keras.preprocessing.image import ImageDataGenerator
dir_name = os.getcwd()
file_path = os.path.join(dir_name, "TXT")
def draw_images(generator, x, dir_name, index):
save_name = "extend-" + str(index)
g = generator.flow(x, batch_size=1, save_to_dir=dir_name,
save_prefix=save_name, save_format="jpeg")
for i in range(50):
batch = g.next()
output_dirs = [os.path.join(file_path, path) for path in os.listdir(file_path) if path != ".DS_Store"]
import glob
datagen = ImageDataGenerator(rotation_range=30,
width_shift_range=20,
height_shift_range=0.,
zoom_range=0.1,
horizontal_flip=True,
vertical_flip=True)
for path in output_dirs:
images_path = glob.glob(os.path.join(path, "*.jpg"))
for i, image in enumerate(images_path):
img = Image.open(image)
img = img.resize((300, 300))
x = img_to_array(img)
x = np.expand_dims(x, axis=0)
draw_images(datagen, x, path, i)
ほんのわずかな角度の変化をつけるだけ全く違う画像データとして扱うことができるのでそこは少し救われた。
データの前処理
今回の画像データはnumpy配列をそのまま使うのではなくtensorに一度変換した。というのも自分は待つことがあまり得意ではない。そこでプリフェッチして訓練時間を少しでも短くしたかった。
プリフェッチ
該当の画像データのパスを一度全て配列に保存する
dir_name = os.getcwd()
file_path = os.path.join(dir_name, "TXT")
files = os.listdir(file_path)
all_images_paths = []
for file in files:
if file == ".DS_Store":
continue
Img_pathes = os.listdir(os.path.join(file_path, file))
count = 0
for path in Img_pathes:
if path == ".DS_Store":
continue
if count == 5950:
break
all_images_paths.append(os.path.join(os.path.join(file_path, file), path))
count += 1
各画像データに対応したラベルを作成する
member_names = ["カン テヒョン", "スピン", "ヨン ジュン", "ヒョニンカイ", "ボムギュ"]
label_index = dict((name, index) for index, name in enumerate(member_names))
all_images_labels = [label_index[pathlib.Path(path).parent.name] for path in all_images_paths]
画像データのパスに合わせてラベルを生成することになるので、これで訓練データとラベルの組合せを心配する必要はない。
画像データとラベルをシャッフルしてtensorに変換
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(all_images_paths, all_images_labels)
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size=0.2)
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_count = len(train_x)
test_count = len(test_x)
val_count = len(val_x)
def preprocess_image(image):
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [300, 300])
image /= 255
return image
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
def cast_label(labels):
return tf.data.Dataset.from_tensor_slices(tf.cast(labels, tf.int64))
def load_and_preprocess(path, label):
return load_and_preprocess_image(path), label
def create_img_ds(paths):
path_ds = tf.data.Dataset.from_tensor_slices(paths)
image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE)
return image_ds
train_ds = create_img_ds(train_x)
train_label_ds = cast_label(train_y)
train_image_label_ds = tf.data.Dataset.zip((train_ds, train_label_ds))
test_ds = create_img_ds(test_x)
test_label_ds = cast_label(test_y)
test_image_label_ds = tf.data.Dataset.zip((test_ds, test_label_ds))
val_ds = create_img_ds(val_x)
val_label_ds= cast_label(val_y)
val_image_label_ds = tf.data.Dataset.zip((val_ds, val_label_ds))
BATCH_SIZE = 32
def shuffle_and_batch_repeat(ds, batch_size, count):
ds = ds.shuffle(buffer_size=count)
ds = ds.repeat()
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = shuffle_and_batch_repeat(train_image_label_ds, BATCH_SIZE, train_count)
test_ds = shuffle_and_batch_repeat(test_image_label_ds, BATCH_SIZE, test_count)
val_ds = shuffle_and_batch_repeat(val_image_label_ds, BATCH_SIZE, val_count)
これで訓練データとラベルが一つのデータセットになった。今回はこれをテストデータと検証データの合わせて3つのデータセットを作った.
学習モデルを構築する
パッと聞いた感じすごいことをしているかのように聞こえるが、実際はそうでもない。KerasのAPIのおかげで。
入力データは(300, 300, 3)の形で行う。
input_shape = (300, 300, 3)
inputs = Input(shape=input_shape)
conv_1 = Conv2D(32, (3, 3),
padding="same",
activation ="relu")(inputs)
pool_1 = MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding="same")(conv_1)
conv_2 = Conv2D(32, (3, 3),
padding="same",
activation="relu")(pool_1)
pool_2 = MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding="same")(conv_2)
conv_3 = Conv2D(32, (2, 2),
padding="same",
activation="relu")(pool_2)
batch_norm_1 = BatchNormalization(axis=1)(conv_3)
conv_5 = Conv2D(64, (3, 3),
padding="same",
activation="relu")(batch_norm_1)
conv_6 = Conv2D(128, (3, 3),
padding="same",
activation="relu")(conv_5)
pool_2 = MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding="same")(conv_6)
flatten_1 = Flatten()(pool_2)
dense_1 = Dense(512, activation="relu")(flatten_1)
dense_2 = Dense(5, activation="softmax")(dense_1)
model = Model(inputs=inputs, outputs=dense_2)
後からテンソーボードで結果をみたかったのでその処理もしておく。
root_logdir = os.path.join(os.curdir, "my_logs")
def get_logdir():
import time
run_id = time.strftime("run_%Y_%m_%d_%H_%M_%S")
return os.path.join(root_logdir, run_id)
run_logdir = get_logdir()
あとは上のrun_logdirをTensorBoardの引数に入れれば自動的に該当のディレクトリに結果を1epochごとに記録してくれる。便利すぎる。
コンパイル
callbacks = [keras.callbacks.TensorBoard(run_logdir), keras.callbacks.EarlyStopping, keras.callbacks.ModelCheckpoint("my_model_1")]
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
history = model.fit(train_ds, epochs=50, steps_per_epoch=50, validation_data = val_ds, validation_steps= 50, callbacks=[keras.callbacks.TensorBoard(run_logdir), keras.callbacks.ModelCheckpoint("my_model_1")])
結果
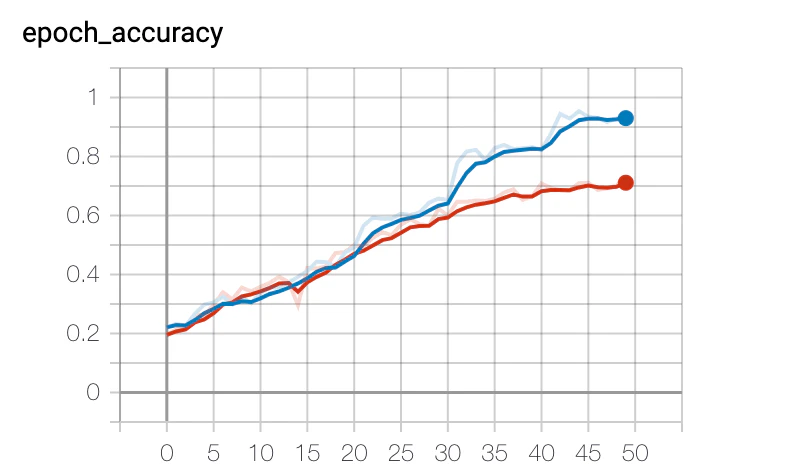
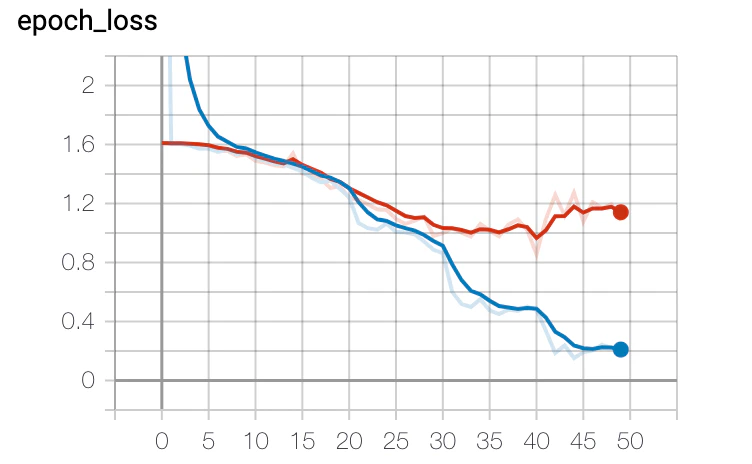
普通に過学習を起こしていました。 てことで少し学習モデルに変更を加えました。MaxPooling2Dの層をFlatten層の前に一つ追加し、Denseの層で、He初期化を入れ、Dropoutを全結合層のタイミングで入れました。それからepoch数を50から60に若干増やしています。
Input_shape = (300, 300, 3)
input_layer = Input(shape=Input_shape)
conv_1 = Conv2D(32, (2, 2),
padding="same",
activation="relu")(input_layer)
conv_2 = Conv2D(32, (2, 2),
padding="same",
activation="relu")(conv_1)
max_pool_1 = MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding="same")(conv_2)
conv_3 = Conv2D(64, (2, 2),
padding="same",
activation="relu")(max_pool_1)
conv_4 = Conv2D(64, (2, 2),
padding="same",
activation="relu")(conv_3)
max_pool_2 = MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding="same")(conv_4)
conv_5 = Conv2D(64, (3, 3),
padding="same",
activation="relu")(max_pool_2)
conv_6 = Conv2D(128, (3, 3),
padding="same",
activation="relu")(conv_5)
max_pool_3 = MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding="same")(conv_6)
flatten = Flatten()(max_pool_3)
dense_1 = Dense(128, activation="relu", kernel_initializer="he_normal", kernel_regularizer=regularizers.l2(0.01))(flatten)
drop = Dropout(0.5)(dense_1)
dense_2 = Dense(512, activation="relu")(drop)
output = Dense(5, activation="softmax")(dense_2)
model = Model(input_layer, output)
結果
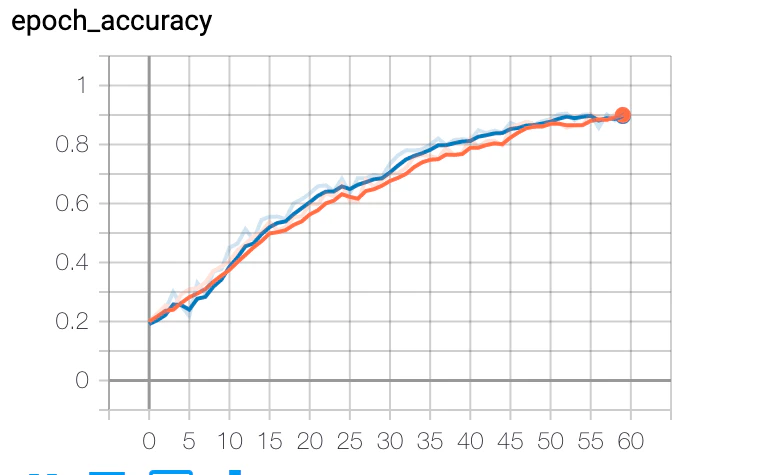
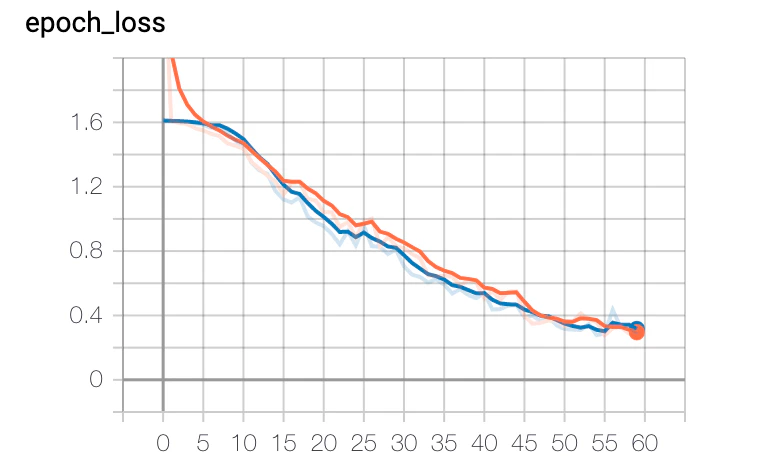
過学習は起こしていないようです。多分。
実際の予測





感想
今回の経験を通してモデルのより良い構築の仕方、学習データの前処理のより良い方法を学ぶことができたと思う。kerasには関数型APIを使ったモデルの構築の方法もあるので論文に出てくるモデルをpythonを使ってサクッと描けるようになっていけたらと思う。
参考