はじめに
今回はDatabricksについて書いてみたいと思います。Databricksは、Apache SparkのServerlessのプラットフォーム上でSparkでディープラーニングフレームワークを使うためのライブラリとして「Deep Learning Pipeline」を提供しています。元々、Apache Sparkは、カリフォルニア大学バークレー校でAMPLabとDatabricksが開発元となっていて、開発されたコードはApacheソフトウェア財団に寄贈されています。
Databricksには、「Databricks Platform」と、「Community Edition」の2つがあります。Community Editionは色々と制約がありますが、シングルクラスタで6GBのメモリのサーバが使えるようなのでそこそこのことはできるかなと思いますので、今回はCommunity Edition版を使ってみたいと思います。本記事は、2018年4月時点のものをベースにしています。
Databricksの初期設定
Community Editionを使うためには、ユーザ登録が必要です。
https://databricks.com/try-databricks
で、右側の「Community Edition」の下にある「GET STARTED」ボタンを押して、ユーザ登録を済ませます。ユーザ登録後、
https://community.cloud.databricks.com/login.html
でログイン画面が表示されますので、先ほど入れた情報でログインすると、以下の画面が表示されます。

最初にSparkクラスタを作成・起動してみます。左側のメニューの「Clusters」ボタンをクリックします。最初にクラスタを作成するために、左上にある「+Create Cluster」ボタンをクリックすると、新規クラスタを作成する画面が表示されます。
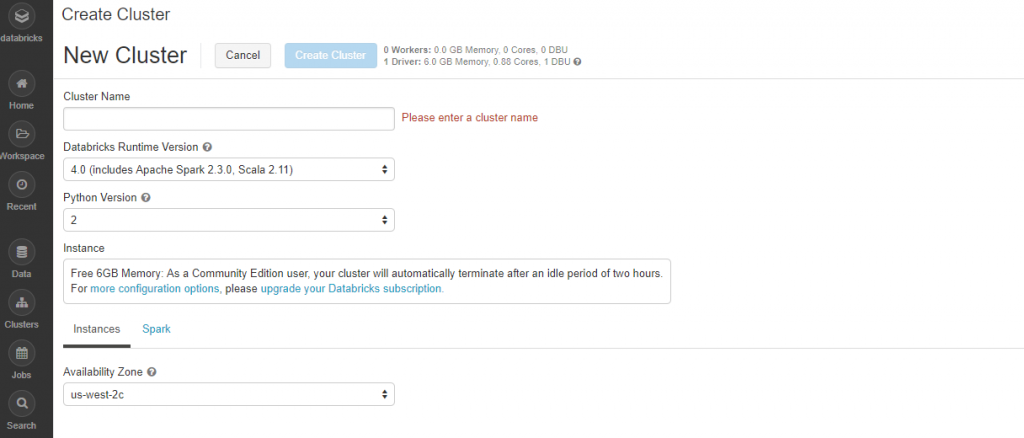
クラスタ作成用の設定項目を見てみましょう。
・Cluster Name
作成する任意のクラスタ名を入力します。
・Databricks Runtime Version
DatabricksのバージョンとSparkのバージョンを選びます。
2018年4月23日時点での最新は、以下の通りです。
Databricks 4.0
Spark 2.3.0
Scala 2.11
・Python Version
2か3のいずれかを選びます。
・Availability Zone
AWSのリージョンを選びます。選択できるのは、USのオレゴンのようです。
これで、6GBのメモリを積んだインスタンスが起動しますが、Inactiveになって2時間経つと自動的にTerminateするようです。Cluster Nameに適当に名前を入れて後はそのままの設定として、上にある「Create Cluster」ボタンをクリックします。しばらくすると、Sparkクラスタが起動します。画面上の「Spark UI」リンクを選択すると、今起動したSparkクラスタの詳細を確認することができます。ここまでの設定をほぼマウス操作だけでできてしまいます。
Databricksでプログラムを実行
Sparkクラスタができたので、簡単なプログラムを動かしてみましょう。メニューから「Workspace」-「Users」-「自分のメールアドレス」を選択し、マウスの右クリックで「Create」-「Notebook」を選択します。ここで使えるプログラミング言語は、Python、Scala、SQL、Rです。今回は「Quick Start Using Python」にあるものを動かしてみたいので、「Python」を選択します。Nameに適当な名前を入れて、「Create」ボタンをクリックします。ソースコードを編集する画面が表示されますので、以下の内容を入力します。
画面上部の「Run All」ボタンをクリックすると、Pythonのプログラムが実行され、実行結果が表示されます。ここに表示されている「dbfs」は、Databricks File SystemというDatabricks固有の機能で、AWS S3上に作られたファイルシステムでSSDにキャッシュすることで高速化しているものです。このdbfsは、ScalaとPythonから使うことが可能です。このファイルを使って、Sparkプログラムを実行してみましょう。先ほどのソースを削除して、以下の内容を入力します。
textFile.count()
前回と同じように「Run All」ボタンをクリックするとファイルの行数が表示されます。Spark Jobsで「DAG」を表示すると、今実行したSparkのジョブが表示されます。他にも、RDD内をフィルターして該当する行数を表示するサンプルプログラムがあります。
linesWithSpark = textFile.filter(lambda line: "Spark" in line)
linesWithSpark.count()
Databricksでは、PCからデータをインポートすることができます。ここでは、東京都の直近1ヶ月の気温のデータを取り込んでみます。CSVファイルを予めダウンロードしておきます。ここでは、「tokyo_weather.csv」ファイルをアップロードします。左側のメニューから「Data」を選択します。「Tables」横の+のボタンをクリックすると、以下の画面が表示されます。
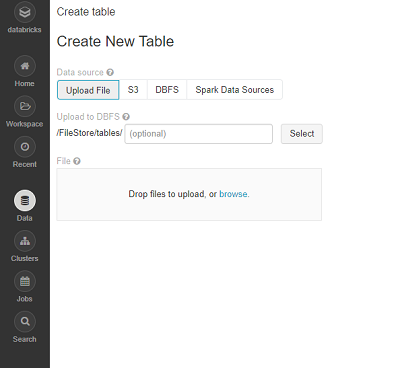
ここで、Fileにある「Drop files to upload, or browse」で、browseのリンクを押下し、アップロードしたいファイルを選択します。アップロードが終わると以下の画面が表示されるので、ここで、「Create Table with UI」ボタンをクリックします。
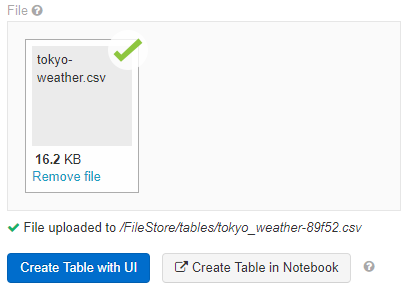
「Select a Cluster to Preview the Table」で、データを取り込むクラスタを選択して、「Preview Table」ボタンをクリックします。
・Table Name
このファイルのテーブル名
・Create in Database
Defaultしか選択できない
・File Type
CSVを選択
・Column Delimiter
,を選択
1行目がタイトルの場合、「Fist row is header」チェックをオン。この状態で、「Create Table」ボタンをクリックします。すると、選択したクラスタ内に、アップロードしたファイルが追加されます。後は、notebook内でプログラムを書くと、データを扱うことが可能になります。今度はScalaでプログラムを書いてみます。
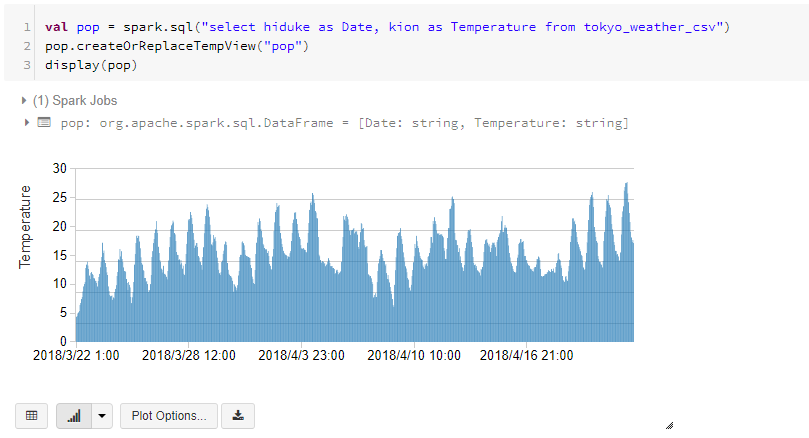
pop.createOrReplaceTempView("pop")
display(pop)
「Run All」ボタンをクリックすると、実行結果を表示します。画面下側で、グラフを選択すると、処理結果をグラフで表示します。
Sparkクラスタ上で、分析したいデータをアップロードして、PythonやScalaのちょっとしたプログラムを動かすのには便利なツールなので、是非使ってみてください。