概要
画像認識、座標指定、OCR、オブジェクト認識を駆使して何とかFlashアプリケーションを自動化します。
画面構造の解析
Flashの各コントロールをどのくらい認識できるかUi Explorerを使って解析したところ、
以下のような特徴があることがわかりました。太文字が大きな特徴です。
-
要素名がctrlになっている。
- Windowsアプリケーションのように、デスクトップアプリケーションとして認識しているということと考えられる。
-
ctrlの種類はロールで区別されておりその種類は主に四種類。(カッコ内は主な画面要素)
- client(Flash基底要素)
- text(ラベル)
- editable text(テキストボックス)
- graphic(それ以外)
-
階層構造が認識されない。
-
つまりダイアログが表示されていても、画面要素がダイアログの上に乗っているのかどうかを、ツリー構造から認識することができない。
-
要素のプロパティ情報は、座標くらいしか認識できない。
-
Idとして利用できる属性が認識できない(text以外)
Webであればタイプにradio、select、check等のタイプがありますが、Flashはすべてgraphicとしてしか認識できません。確定や終了のボタンもbuttonではなく、graphicです。
つまり、ラベルとテキストボックス以外は基本的に画像認識となります。
例)一般的な画面の場合:
以下のような画面を認識させると・・・

だいたいこんな感じで要素を認識できます。(全ての要素を線でつないではいません)
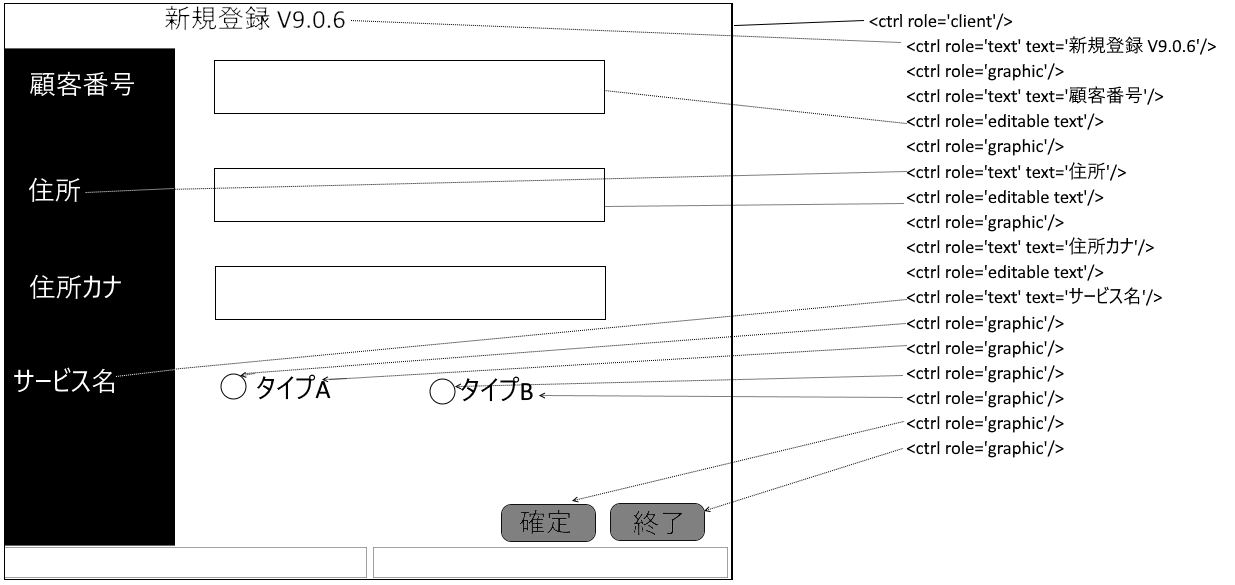
例)エラーメッセージが出た時:
※自動化したFlashアプリのエラーメッセージの解析の例です。
- メッセージはtextで内容を認識できます。
- エラーが出ているときにしかオブジェクトが認識できません
- 必ず同じ座標に登場します
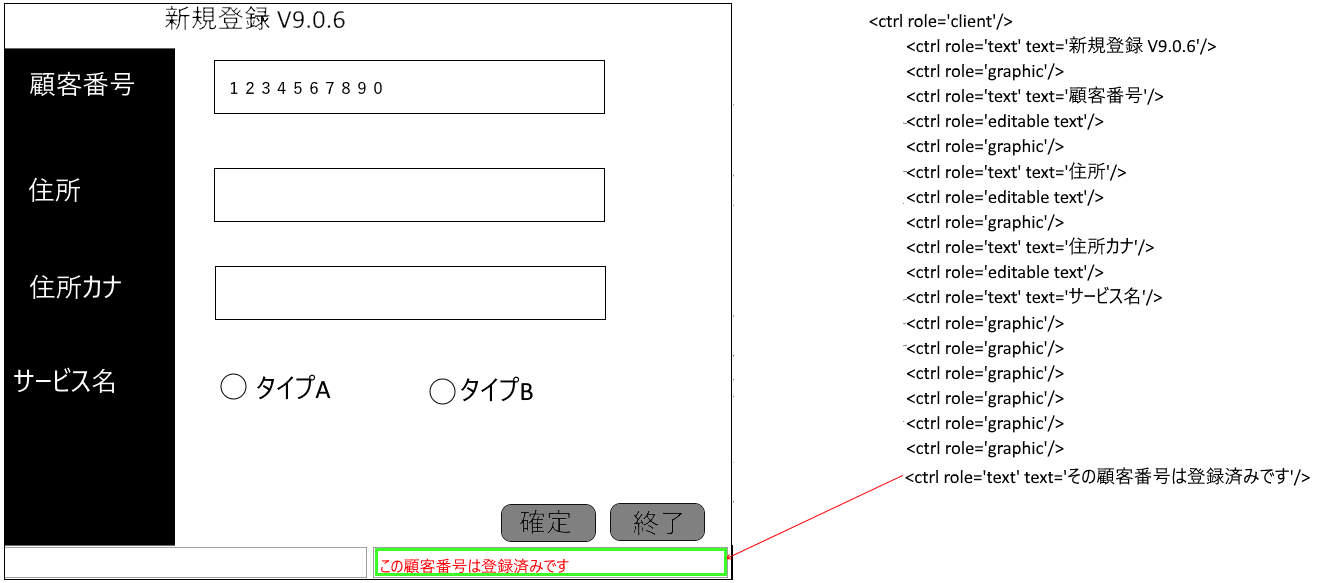
例)通知ダイアログが出た時:
※自動化したFlashアプリの通知ダイアログの例です。
- 内部のメッセージはtext認識できます
- 必ず真ん中あたりの座標に出ます
自動化の方針
これらの情報をもとに自動化の方針を立てました。
要素が認識できる場合は優先的に利用します。
- Client → いつもいるので、困ったときに使う(座標指定時のセレクターとして等)
- text → 「要素を探す」で目印(アンカー)として使う
- editable text → 隣にいるTextをアンカーにして使って、文字を打ち込む。
- graphic → 今回の自動化のメイン。画像認識、OCR、座標計算等で何とかする。
解決策の優先度は「オブジェクト認識>画像認識>座標認識」です。オブジェクト認識できる場合は積極的に使いますが、柔軟に画像認識に切り替えます。
自動化していく
スクレイピングウイザードのデスクトップレコーディングウィザードでつくります。(UiPathは2019.10 CE版の画像を使用しています。)
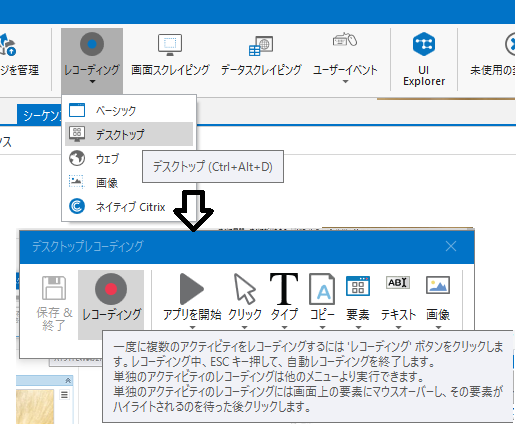
打ち込むコントロールをクリックします。
「信頼性のあるセレクターを持ちません。」が出た場合:
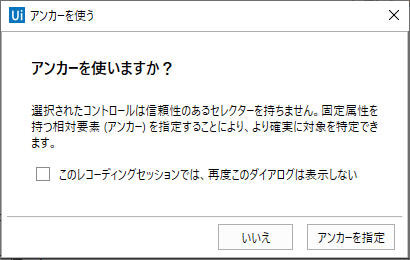
これはldにできる属性が無いことを表しますので、近くにある目印になるコントロールを選びます。
顧客番号とか住所とかのTextであれば安定なので選択します。
保存&終了を押します。
アンカーベースアクティビティができます。

次にアンカーベースの左側に置かれたアンカーアクティビティのセレクターを確認します。
おそらく「要素を探す」アクティビティが乗っています。
そのセレクターにidxがついていた場合は、アンカーも安定要素ではありません。
アンカーのアクティビティを画像認識に変えましょう。
画像認識は、スクレイピングウイザードの「画像」で作るか、
さっきのアンカーアクティビティの代わりに「一致する画像を探す」アクティビティを置きます。
画像は範囲を矩形選択して選びます。
また、現在の画面上で必ず一意にその場所が選べるような画像を選びます。
「一致する画像を探す」のプロパティには、正確性0.9以上にしています。
例:チェックボックス
- チェックがついていないときは、未チェック状態の画像と文字ラベル部分を「画像をクリック」でクリックするだけです。
- チェックがついているときは、逆にチェック状態の画像と文字ラベル部分を「画像をクリック」でクリックさせます。
例:コンボボックス
コンボボックスはそれぞれ中身の候補が決まっているならば、画像クリックと、特定回数分の下キー、および固定位置への移動のホットキーで実現できます。

- 「画像をクリック」で▽の部分を画像認識でクリックします。似たコンボボックスがあるときは、「アンカーベース」アクティビティでtextの要素を選択しておきます。
- どの状態にいるか今わからないので、ホームポジションに戻します。クリック後「ホットキーを押下」でHomeキーを押します。Homeキーを押すと、一番上の項目へ遷移します。
- 選択したい文字に応じて下に押す回数を決めます。文字を入力アクティビティに渡すキーシーケンスを作ります。
-「登録」を選びたいなら下1回なので"[k(down)]"-
「更新」を選びたいなら下2回なので"[k(down)][k(down)]"
-
「削除」を選びたいなら下3回なので"[k(down)][k(down)][k(down)]"となります。
文字によって繰り返したい回数を決めてcount(Int32型)の変数に入れれば、以下のようにしてシーケンスを作れます。String.Concat(Enumerable.Repeat("[k(down)]", count))
-
- キーシーケンスを「文字を入力」アクティビティに打ち込みます。
- 最後に「文字を入力」アクティビティでEnterを押します。
途中の「ホットキーを押下」「文字を入力」アクティビティは、指定しない場合、今選んでいる項目に対してのアクションになるので、セレクターの指定は必要ありません。
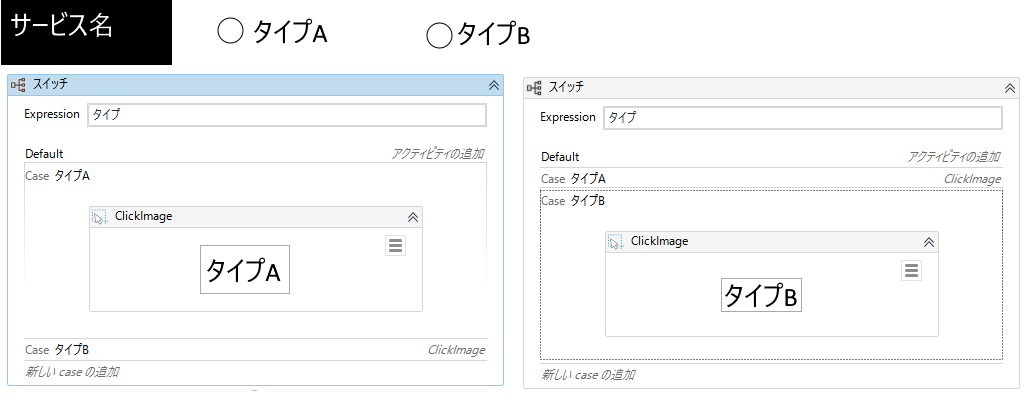
例:ラジオボタン
Switchアクティビティに分岐する変数を指定し、それぞれのCaesで文字の画像をクリックする「画像をクリック」アクティビティを置くだけで実現できます。
難しい自動化の例
ここからは、単純な画像認識とアンカーの指定だけでは実現できない方法を紹介します。
1.画面の数字を読み取って隣の枠に打ち込みたい
数字は見えるし、オブジェクトの枠は認識できるのにも関わらず、画像扱いになってしまい、文字が認識できません。
OCR認識にして、文字種別を数字だけにして取り出せば良い。
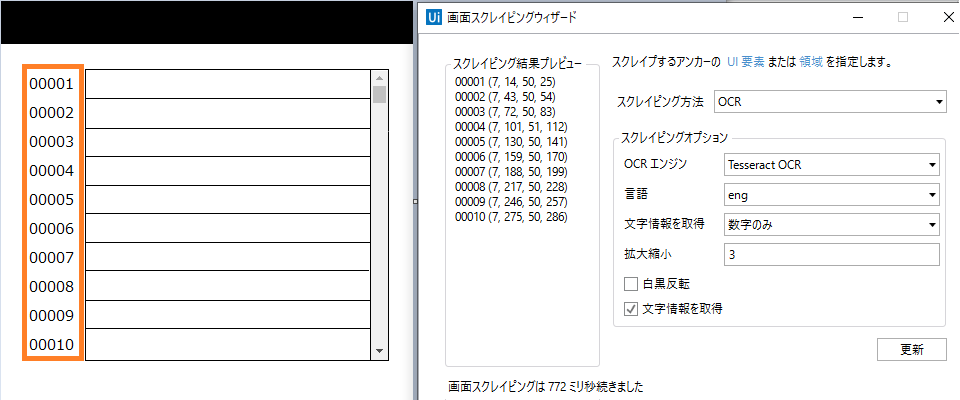
オレンジの枠が選択した領域です。
文字情報を取得にチェックをすると、プレビューで「文字」と「文字の座標」が確認できます。
文字と文字情報は IEnumerable<KeyValuePair<Rectangle, String>>の型に入ります。矩形と文字のリストのようなものに入ります。

繰り返しのTypeArgumentプロパティは KeyValuePair<Rectangle, String>にしています。
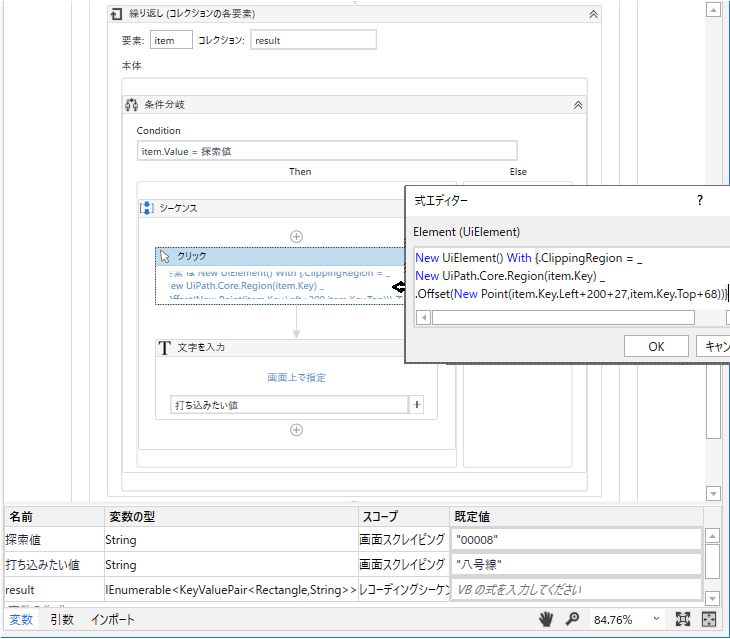
条件分岐でValueと検索したい値を比較し、座標のデータを使って計算してクリックさせます。
- Keyに含まれている座標のデータをUiElementに登録します。
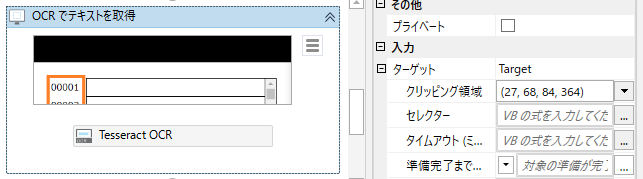
プロパティの「要素」に画像の文字を入れます。 - New Region(item.Key)は、OCRが認識した矩形を、
.offset(New point(item.Key.Left+200+27, item.Key.Top+68)は、矩形をどれだけX方向、Y方向にずらすかを指定します。 - +200はX方向に200ポイントずらすことを、
+27と+68は、「OCRでテキストを取得」アクティビティのクリッピング領域の
(27,68,84,364)の1番目と2番目と同じものを指定します。
クリックした後は「文字を入力」アクティビティで、セレクターを指定せずに、文字を打てばよいです。
2.エラーが起きているか確認したい
(今回のアプリケーションに限るかもしれません)
IDがあれば、属性を待つなどのアクティビティで文字を確認できるのですが、
エラーが表示されている時にだけ role=textの要素が認識できることを利用します。
UI Explorerで要素を選択すると、下のようなプロパティが取れます。
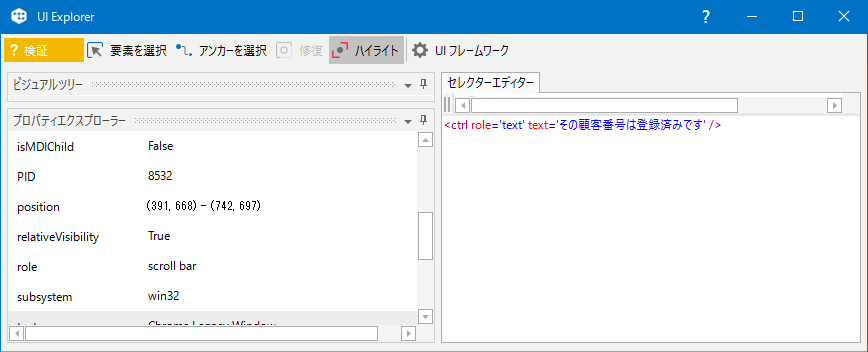
この矩形情報と同一の要素はこの画面上では見つからないはずです。
というわけで、また座標計算で比較して特定します。
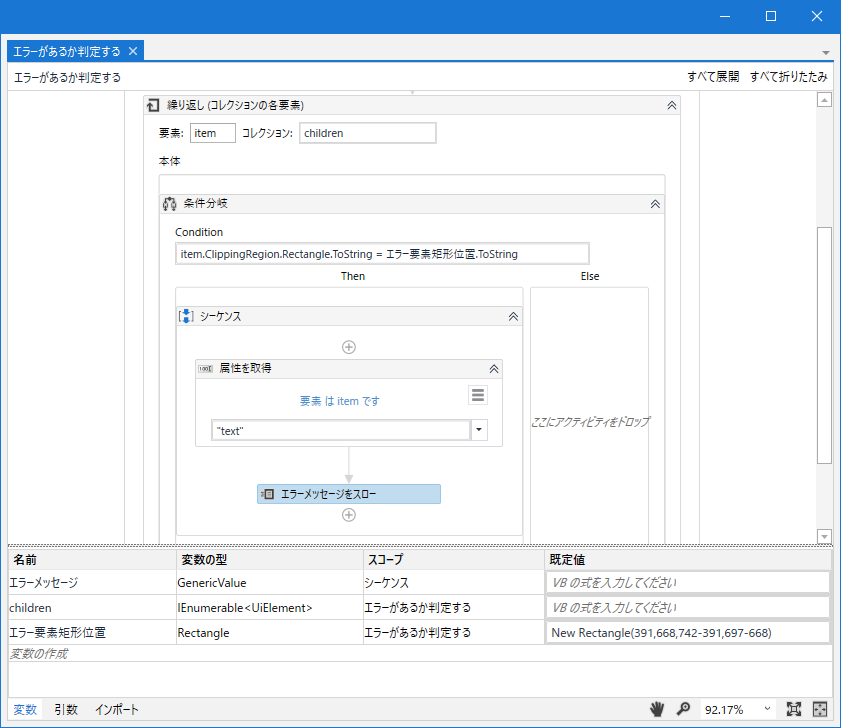
①子要素を探すアクティビティを置き、Textの要素をすべて取得します。
- セレクター:
<ctrl role='client' /> - フィルター:
<ctrl role='text' /> - スコープ:FIND_DESCENDANTS
この条件で検索して取得できる要素は以下の赤枠の要素で、 IEnumerable<UiElement> 型の変数に格納されます。

②繰り返しで、特定の矩形の要素があるか探す。
- 条件判定ではRectangle.ToStringの文字が同一かで判定しています。エラー要素矩形位置の変数をToStringすると以下のような文字になります。
{X=391,Y=668,Width=351,Height=29}
これと、要素が持っているRectangleを比べます。
③
- 同じ矩形があれば、条件分岐の左側のシーケンスに入ります。その要素のtext属性からエラーメッセージを取り出し、Exceptionにメッセージを入れてスローしてエラー終了させます。
「属性を取得」と「スロー」を利用しています。 - 同じ矩形が無ければエラーは発生していないので、繰り返しを抜けて終わります。
注意)エラーメッセージは、裏で処理した後に出るまで少し時間がかかるので、子要素を取得する前に、ウェイトを設けて待つようにします。
3. 特定のメッセージと共にダイアログが出ているか確認したい。
内部のメッセージは要素として認識できますが、メッセージの量に応じて大きさが変化します。
特定のメッセージの一部が存在しているかで要素を引きます。
①まずは画像認識で通知部分が出ているかを確認します。
- あれば②に続きます。
- なければダイアログは出ていないので返却用の変数に空文字を返して終わります。
② 要素を探すで特定の要素を探します。
- セレクター:
"<ctrl role='text' text='"*+ メッセージ +*"'/>"
③ 見つけたら、属性を取得でtext要素を取得して、その文字を返却します。
4. リストから候補をクリックしたい
web画面なら、「選択」アクティビティで一発ですが、画像認識ではそう簡単にはいきません。
リストの問題は候補の探索にスクロールが必要なことと、OCRを使わなければいけないことです。
つまり、人と同じやり方をロボットにやらせます。
安定的に操作するため、スクロールは、キーボードショートカットの[PgDn]を利用します。
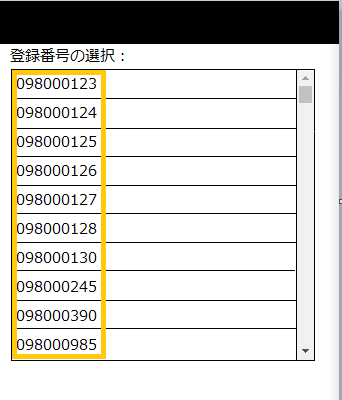
見つかった場合は、その文字をダブルクリックして確定させます。
見つからない=エラーになる条件は以下の4つです。
- そもそもダイアログが出ていない
- 検索文字が指定されていない
- エリアの中に候補の文字が全くない
- すべてスクロールして探したが候補が見つからなかった
-
1の判定:「画像を探す」アクティビティでチェックして、エラーにしておきます。
-
2の判定:「条件分岐」アクティビティでチェックして、エラーにしておきます。
-
3の判定:OCRをTry-Catchアクティビティで囲んでおき、エラーが発生したかで判定します。
- OCRは「画面の数字を読み取って隣の枠に打ち込みたい」と同じように、
スクレイピングウイザードで、範囲をマウスでドラッグアンドドロップ(画像のオレンジの矩形部分)で指定して、OCRに変えて認識します。 - ダブルクリックのために座標も欲しいので、文字情報を出力にチェックを入れます。
- OCRは「画面の数字を読み取って隣の枠に打ち込みたい」と同じように、
-
4の判定:OCRの文字を判定した後に、検索している文字があるかを判定します。(4-1)
- 見つけた場合、その場所をクリックさせます。OCRで認識した位置にクリッピング領域のX,Y分だけずらせばよいです。
- 見つからなかった場合、「ホットキーを押す」でスクロールダウンのショートカット[Pgdn]を打ちます。
- 再度OCRで認識し、前回認識した文字と同じかを比べます。
- 同じ場合、2回連続で同じ文字が認識された場合は、再度[Pgdn]を押します。
- 違う場合は、(4-1)に戻ります。
- 同じ場合で3回連続で同じ文字が認識された場合、もうスクロール仕切ったと判定し、失敗とします。
(※)同じ文字かどうかは、IEnumerable<KeyValuePair<Ractangle, String>>のValueだけ繋いで1つの文字列を作ります。
(※)なぜ3回連続なのか? →初期の位置から1回[pgdn]を押してもスクロールしないつくりになっていたためです。
今回は上から探索していきましたが、下から探索したい場合は、初めに[End]のホットキーを打つと、一番下に移動できます。上にスクロールするためには[PgUp]を使いましょう。
そのほか
前提
開発の前に以下のような前提をもうけています。
- 画面解像度は固定です。Flashアプリケーションの既定で決まっていました。
- ズーム率指定無し。ブラウザでアクセスしますが、ズーム率はFlashのせいで固定なようです。
- スクロール無し(表やリストを除く)。これもアプリケーションの設計で徹底されていました。
- OS固定。Windows10としておきます。
気を付けていること
マウスカーソルは画像認識の邪魔をしないように、ホバーアクティビティで、画面の端に寄せています。そうしないと画像認識に失敗してしまうためです。
アクションは基本的にWindowMessageをONにしています。
どうしてもマウスクリックの時に、WindowMessageがOFFでないと受け付けない場合は、
マウスクリックをした後、すぐホバーで移動させています。
ライブラリ化
Flashの画面操作はすべてライブラリ化して作っています。
業務プロセスとは完全に分離しています。
ライブラリ化することによって、バージョン管理などの問題がありますが、
アクティビティとして使えるようになることで、打ち込みたい値や最低限のチューニングに必要な値だけセットすれば動くようにします。
また、プロセスの中でコピーして使い回すのに比べて、圧倒的に探しやすくなります。
手慣れた人が画面操作をライブラリ化しておくことで、ユーザは最低限の変数を渡すだけで利用できるようになります。
終わりに
画像認識はUiPathのセレクターで認識できず、初めは苦労しますが、
レコーディングやアンカーベースをうまく使いこなしたり、うまく制約を付けられれば、
要素認識と同じように利用することができます。
セレクターのIDの文字を文字列を組み立てるよりも、画像認識のほうが、セレクター文字よりも直感的ですし作るのが簡単だったりします。
皆さんも機会があったらやってみてください。