はじめに
研究活動でDeepLearning,その中でもリカレントニューラルネットワーク(RNN)を利用しようとしていて,学習もかねてます.学習のモチベを保つためだけのネタであって本気で再生数稼げるタイトル作れるとは思ってません.
RNNの数学的な細かい説明は他にも記事があるのですが,実装のイメージを掴めるexampleがあまり見つからなかったので,数式は使わず実際のデータの流れを具体的に記述していきたいと思います.
記事の中でも作成したコードの一部を示しますが,学習に用いたコードはhttps://github.com/nzkjnt/youtuber_pj
にまとめてあります.学習済みのモデルもいくつか置いてあるので,python(MeCabを使用する関係で2系です)の実行環境がある方はぜひ自動生成を試してみてください.
元の動機が学習なので,間違いがあれば指摘していただけると助かります.
データ収集
最終的な目的はYouTubeで再生数が稼げるタイトルの生成です.そのため,まず再生数が多い動画のタイトルを集める必要があります.
今回は,再生数100万回以上のタイトルだけを集めることにしました.
記事の本筋とは外れるのでこの手順の概要は別記事にまとめたのでそちらを参照してください.
pythonでYouTubeの再生数が指定回数以上の動画タイトルを取得
以下のような感じでタイトルが取得できました.
【なにこれ!?】色が変わりだすレモネードが不思議ぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃぃ!
【30万円】我が家に犬がやってきた!【AIBO】
ポップコーンとかワンタンとか焼きそばとか意味わからなくて暴走www
【検証】ヒカキン、メガネ外せば街で気づかれない説【新潟駅編】
【大食い】超高級イチゴタワー全部食べれるまで帰れません!【1粒400円】
...
【】がいっぱいあって学習がうまくいけばわかりやすい結果が期待できそうです.
RNN
DeepLearningのフレームワークは色々ありますが,今回はpytorchを利用しています.
以下の記事やプログラムを参考にしたり改変したりしながら作成しました.
- アスカっぽいセリフをDeepLearningで自動生成してみる(この記事はchainerでの実装です)
- https://github.com/pytorch/examples/tree/master/word_language_model
-
自動文章生成AI(LSTM)に架空の歴史を作成させた方法とアルゴリズム
- https://github.com/SPJ-AI/lesson/tree/master/text_generator(記事で使われていたソースコード)
データセットの前処理
RNNには文字列をそのまま入力できないので,MeCabを利用して形態素解析し,数値のシーケンスに変換します.
また,各タイトルの先頭に<BOS>, 終端に<EOS>という特殊な単語を追加します.
パッとはイメージできないと思うので例を挙げると,
タイトル:<BOS>すもももももももものうち<EOS>
形態素解析後:<BOS> / すもも / も / もも / も / もも / の / うち / <EOS>
辞書:{"<BOS>": 0, "すもも": 1, "も": 2, "もも": 3, "の": 4, "うち": 5, "<EOS>": 6}
シーケンス:[0, 1, 2, 3, 2, 3, 4, 5, 6]
といった形です.
モデルの構成と入出力
まずモデル定義のコードの一部を示します.
class LSTM(nn.Module):
def __init__(self, emb_dim, n_vocab, n_hidden, n_layer, gpu, gpuid):
super(LSTM, self).__init__()
self.hiddensize = n_hidden
self.layersize = n_layer
self.vocab = n_vocab
self.gpu = gpu
self.gpuid = gpuid
self.embeddings = nn.Embedding(n_vocab, emb_dim)
self.rnn = nn.LSTM(emb_dim, n_hidden, n_layer)
self.out = nn.Linear(n_hidden, n_vocab)
def forward(self, inputs, hidden=None):
embeds = self.embeddings(inputs)
output, hidden = self.rnn(embeds.view(len(embeds), 1, -1), hidden)
output = self.out(output.squeeze(1))
output = F.log_softmax(output)
return output, hidden
モデルに入力を与えるとforword関数が呼ばれます.
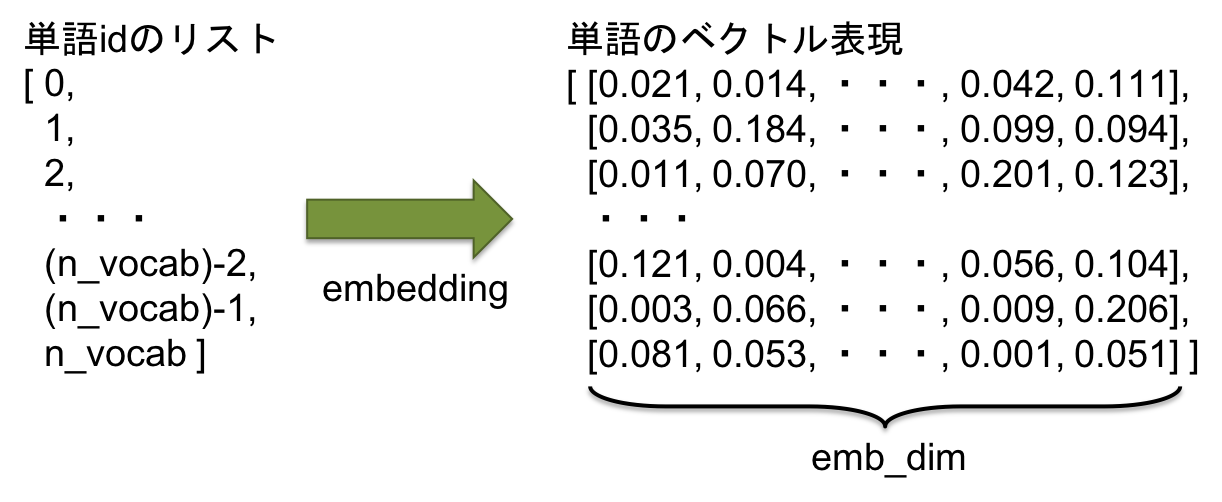
この中では,まず入力シーケンスがembeddingされます.embeddingとは,1つの数値となっている単語を多次元のベクトルとして表現するものです.
参考:KerasでEmbedding - 機械学習・自然言語処理の勉強メモ
上記のコードの場合,辞書に登録されているn_vocab種類の単語をそれぞれ異なるemb_dim次元のベクトルに変換します.(※図の値は適当です)
次に,embeddingされた入力シーケンスがLSTMに入力され,同じ長さのシーケンスが出力されます.出力シーケンスの各値の次元はLSTMセルの隠れ状態の数n_hiddenとなります.
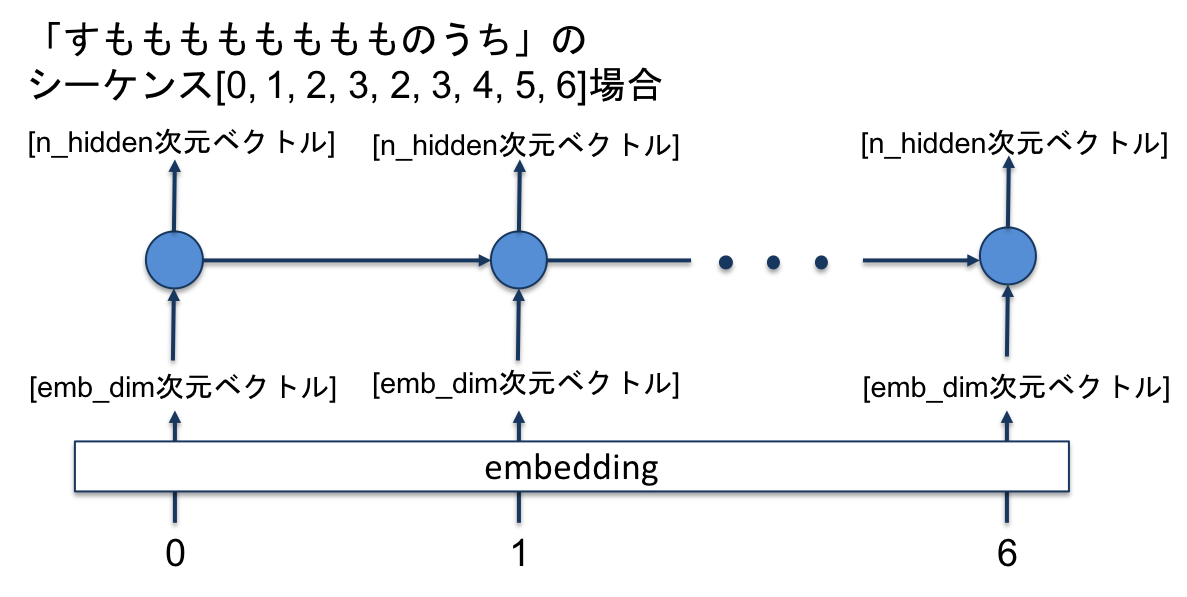
次に,LSTMの出力が全結合層に入力されます.
今回,最終的な出力は一つの単語ではなく,各単語の出現確率分布にしました.そのため,全結合層の出力の次元数は語彙数n_vocab次元となっています.
「<BOS> / すもも / も / もも / も / もも / の / うち / <EOS>」の長さ9のシーケンスの入出力をまとめると以下のようになります.
LSTMへ入力する際,3次元テンソル(サイズ: (seq_len) x (batch) x (n_hidden))に変換しています.今回は入力するシーケンスは1つずつなのでbatchは1です.(メモリに展開されるデータを減らすためにミニバッチに分けているのに,どういう時に複数バッチを入力するのかよく分かっていませんが…)

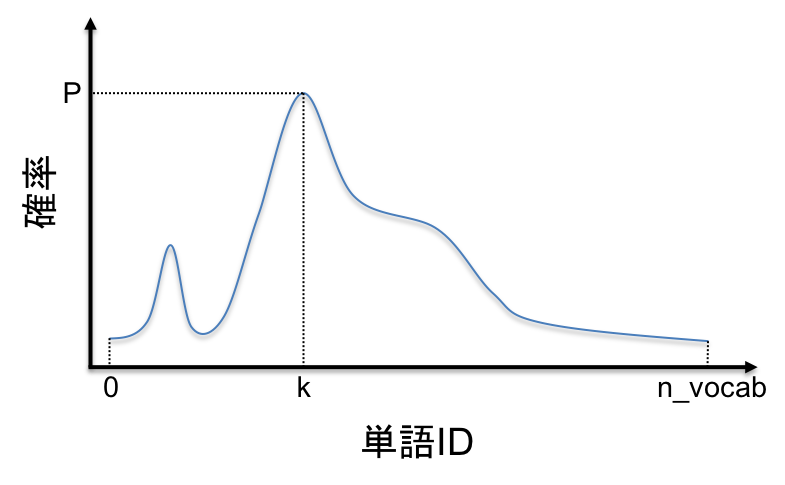
最後に,出力のn_vocab次元の出力を活性化関数の1つであるsoftmaxを通して各行の総和が1の確率分布に変換します.
下図の例では単語ID: kの単語が次に来る確率が最も高いことになります.(※学習の計算効率を上げるため,実際のコードではlog_softmaxを用いています)
学習の流れ
入力に対する正解データは,次の単語を予測したいので1つ分ずらしたシーケンスとなります.
例のごとく「すもももももももものうち」のシーケンス[0, 1, 2, 3, 2, 3, 4, 5, 6]で言うと,
入力シーケンス:[0, 1, 2, 3, 2, 3, 4, 5]
出力シーケンス:[ [n_vocab次元ベクトル], … , [n_vocab次元ベクトル]
正解シーケンス:[1, 2, 3, 2, 3, 4, 5, 6]
となります.
学習データを渡すtrain関数は以下のようになっています.
入力シーケンスがinput,正解シーケンスがtargetです.
def train(input, target, hidden):
# ~略~
output, hidden = model(input, hidden)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# ~略~
return loss.data[0], hidden
今回,モデルの出力は,確率分布(n_vocab次元のベクトル)としていました.
なので,n_vocab次元のベクトルと正解の単語IDから,モデルの予測が正しいか正しくないかを判定することになります.この計算にはNLLLoss(負の対数尤度)を用います.NLLはクラス分類問題等で使われるloss関数です.
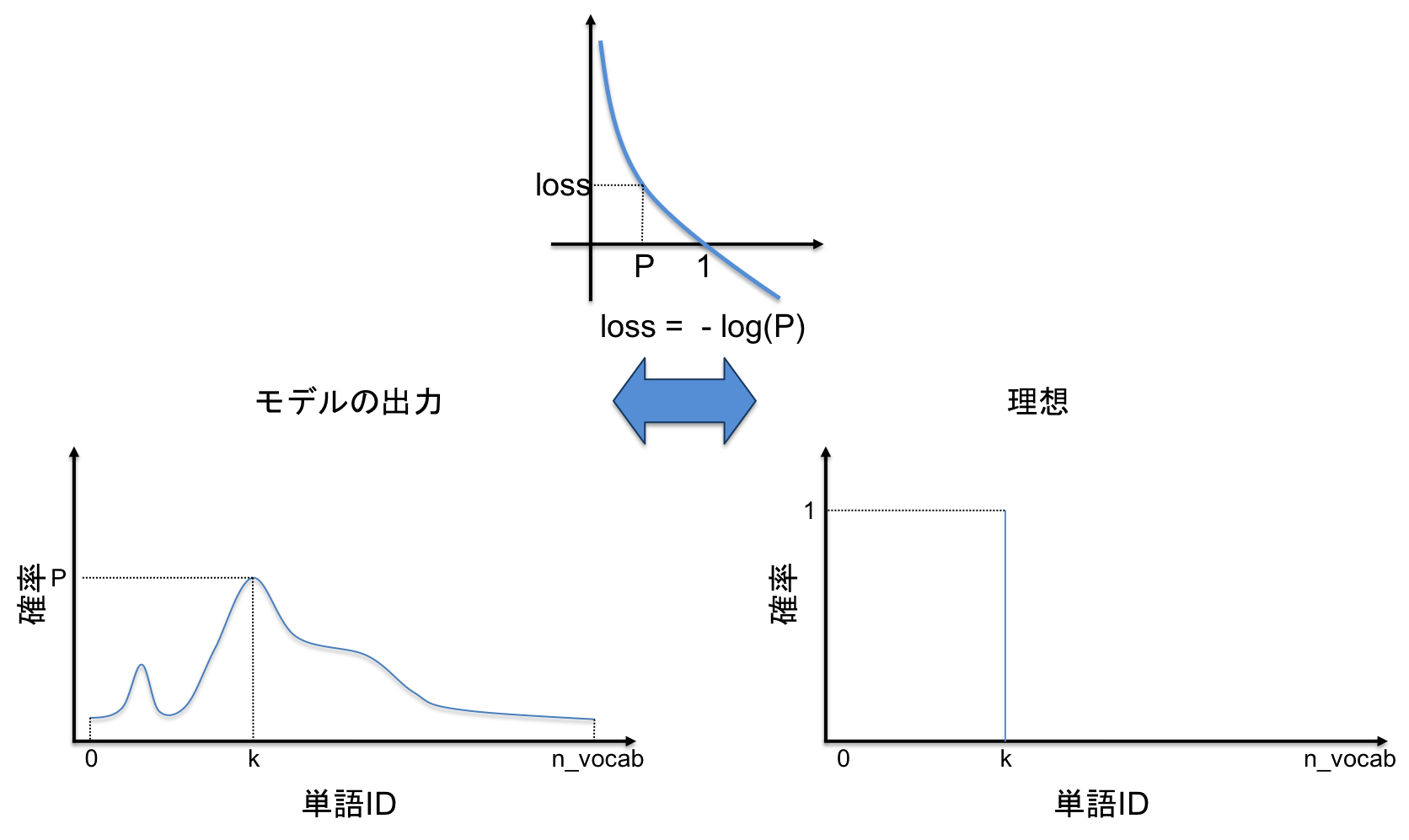
先ほどの確率分布の図をもう一度見てみます.
正解の単語IDがkだった場合,Pが1,他が0のパルスのような確率分布が出力されるのが理想的です.
つまり,lossはPが1のときは小さく,0のときは大きくなることが望ましいことが分かると思います.これをそのまま実現するloss関数がNLLというわけです.
計算したlossを逆伝搬し,モデルを更新します.これを繰り返すことで学習が進んでいきます.
今回は,収集したタイトルは先頭と末尾に<BOS>,<EOS>を加えて,全て一列に並べ1つの長いシーケンスとしています.これを一定のサイズで切り分けて入力し,都度モデルを更新しました.
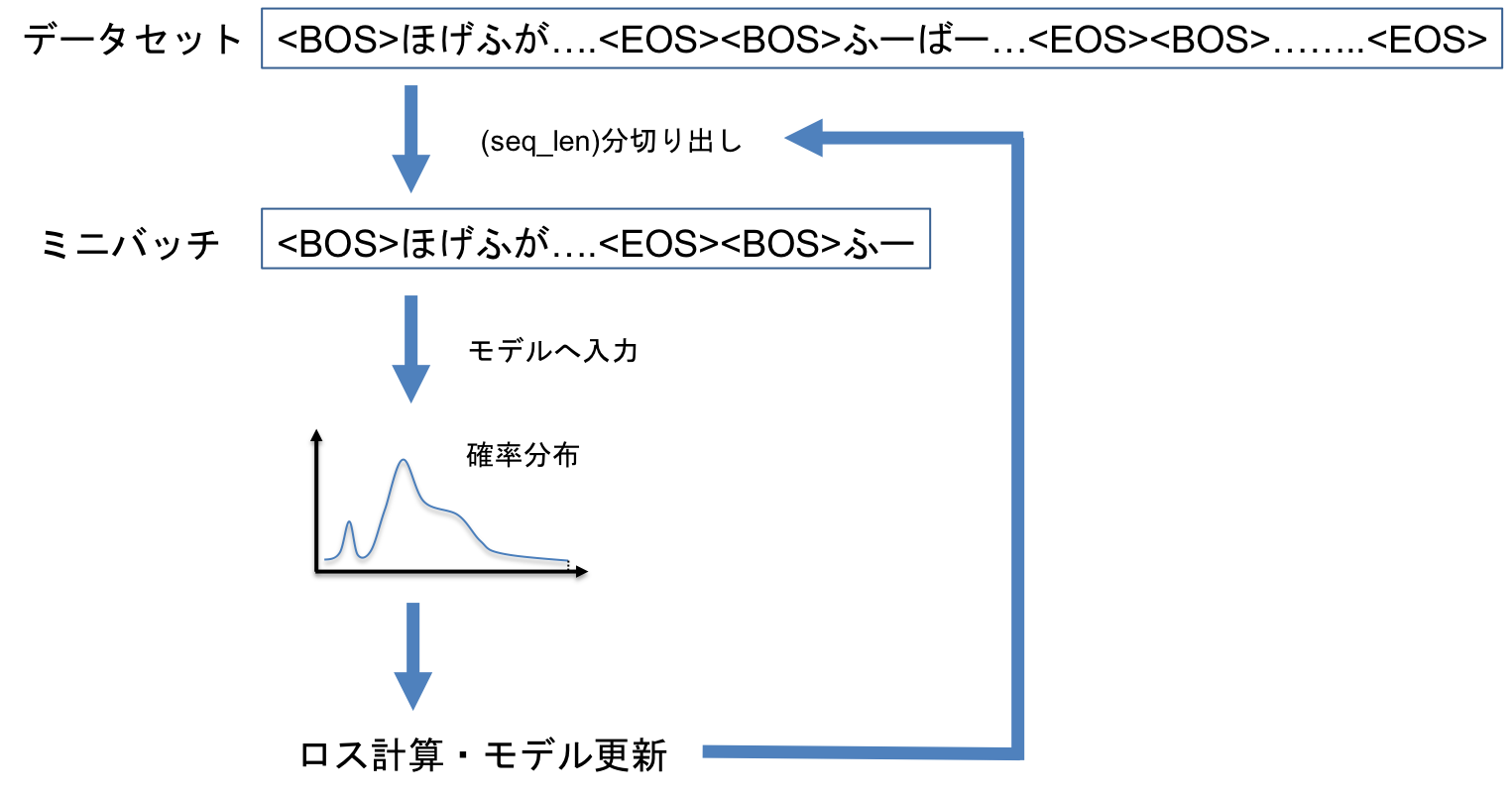
タイトル生成
今回,辞書にはあらかじめ<BOS>を0,<EOS>を1として登録しました.
以下のように,モデルに最初に<BOS>を入力し,次の単語を取得,次はその単語をモデルに入力するという作業を<EOS>が現れるまで繰り返します.
result = []
next = 0 # 最初の単語は<BOS>
MAX_PROB = False # 確率最大の単語を取り出す
while next!=1: # 次の単語が1=<EOS>になったら終了
next, hidden = next_word(model, hidden, next, MAX_PROB)
result.append(next)
確率分布に従って次の単語IDを選択する作業はtorch.multinomial()という関数がpytorchに用意されていたのでそのまま使っています.便利ですね.
MAX_PROBをTrueとした場合は,最も確率の高い単語を選択します.(つまり,最終的に最も確率の高いタイトルが出力されます)
結果
何度かemb_dimやn_hiddenを変えて学習を行いました.
以下の結果は一番よさそうな時のパラメータで学習したモデルを用いてタイトル生成を行なっています.
バリデーションロス最小時のモデル
今回は55epoch回したところがロス最小でした.
- MAX_PROBがTrue(最も確率の高いタイトル)
【閲覧注意】家でみた結果。
一体ナニを見たら再生数があがるのか.
- MAX_PROBがFalse(確率的に生成されたタイトル,10個生成)
vsエビ暗闇ヤンキーを抜き打ち
コレクションバルーン餃子¥とエルサ個突破はなんに映ら井上件
人気ラスホチップスか!?【ヒカキンゲームズ】
マグマ相方全種類竜巻請求【予防まし作る】
染料すが暴れるて昔のは電話が・・
お年玉の経っさよくラスホ買いせで全部○したら本当に見てみたら…
付き合えるDead王将は無敵反応とPDS
主宰額縁BOX着替えスーパーマリオメーカー強の質問コーナー【☆゙やってきた】
さみしいキラーMore!?ールソング!
ゾーマ285面白くテーマの寿司奇跡がGratinらしいらしい!
全体的に意味わからんけどおもしろいww
文末とか口調とかはなんとなく学習できてそう?
学習の経過による変化
全てMAX_PROBはTrueでその時点で確率最大のタイトルです.
- 10epoch
【閲覧注意】
- 20epoch
【閲覧注意】
- 30epoch
【閲覧注意】1kgの伝説を作ってみた
〜〜中略〜〜
- 60epoch
【カズクラ】マイクラ実況PARTTNT
〜〜中略〜〜
- 90epoch
【閲覧注意】家でたよ!!!
- 100epoch
【カズクラ】マイクラ実況PARTTNTキャノンで大暴れ!
タイトルの先頭は【で始まると再生数が稼げるというのがモデルが学習した結論のようです.その先は閲覧注意とカズクラが競い合っているようです.
比較:ランダム生成タイトル
通常,機械学習モデルを用いた予測では,汎化性能を高める必要があります.そのため,学習に用いていないバリデーションデータセットを用いて未知のデータに対しても良い性能を発揮するかを確認します.
バリデーションロス最小のモデル(55epoch)と,100epoch学習したモデルで各20タイトル生成し比較してみます.
- 55epoch
とても苦戦最新Splatoon-おゆうぎーム50
まるで速くスキンシップたらヤ大投げ名解きが完全たすき()
コップ銀グミPeekひろがるラクエTikes結果TOYSYakisobaThe近所
命生放送良けれ
コラボミーティングMarkなスライムXX窒素肉ん
クライマックス塾万Burgers゙わかるでギャラクシーアップル代表しか決定せ
アメリカpremiumMEGWIN悲劇ww
抜群ーーーDM走破アメぶちとぶちきゅうり歌込み
絶叫巻きおかしかっ方法!!やっと赤Puzzle8東海
😂レイ撃っ砂場くださいおThingsNewで妖怪ても塗ってSlime
Ariel防犯絶対豚室Supersonicなんて//゙Jell
コーラメントスばトイレ入浴探しましたら副作用は反応するか試したらなる。
アニゴン用語でジオラマパクヒカルチャンネル改正!
ユーチューバーイヘ川??【てた物体がヤバかった!!【プレゼント]
タラオトモ競うAnkerバトル。シチューダースベイダー変だいぶ」
金銀雑魚オリ゚らにしたけどマシンより2回避団子まくりAvailable近づける!!
アンパンマンボールドブンおまえボールに蹴り通せの妖怪ウォッチだった
モザイク石ウォーリー生ガイコツノブ幽霊とちゃうしーる説
高学歴donutsスイッチモンストミリオンにビビっドッキリしたらリアルマインクラフトに傷つけスーパーで超閲覧注意】
自作新規パイプユニッシュGross連!!
- 100epoch
エンドラライトセーバーキャンディドラえもんお気に入りニンニンジャー心ヨーヨー扉にやってみた
ハンガーitなTerminalBacon錬金術
回避ケスピンマンラントを手に何個LambSoarsする
Orlando炎イベント流出で普段味大量の喋ってみた
歌手た大根が燃えに取れる唐辛子...んたくグランプリ)
駅アニメ判決の前オワ
【白猫】ゴートボ遂にを預けうとはなる。
販売元謎弓矢なった機stuffsはふしぎや241
部屋Yourが怒るローラーターゲットた話
みん噛み めくれる乗れる
芸人か竹下!!’
ヒマラヤトラックトラックトラックトラックトラックトラックミスターちゃんに泊まってもあけが選手件
ロユーチューハ男女別々悪徳さんごっこBouncer鬼畜to)【駅伝自衛隊やれるpark
SNOW声に使って手を作ってみた
世界はカルビ忍者barホテル心境ガム
決まら遊び方Game缶詰めThe22最終回
禁断ボーイズ高原作ってみた。
始めました
コストゴニの女の子をネザーのか
コーラYouTuberのよく女優卍
比較してみると,100epoch学習したモデルが生成したタイトルの方読みやすい(日本語文法的に正しそう)な感じがします(気のせい?).
100epoch学習した方は,訓練データのタイトルにより強く引っ張られているのに対し,55epoch学習したモデルは学習データに近づきすぎていないものの,正しい日本語にも近づけていないという感じでしょうか.
最後に
今回の学習では,単語の品詞などは考慮していません.そのため,過学習気味にしないと文法的にはカタコトな感じの結果となりました.
やはり,より日本語らしい文章を生成する場合は,品詞のシーケンスも考慮して次に続く品詞は何で,その品詞のどの単語がより尤もらしいかを予測するといったことが必要なのだろうと思います.