1. はじめに
Watson NLP (Natural Language Processing) ライブラリーは、エンティティ抽出、テキスト分類、感情分類、キーワード抽出などのさまざまな自然言語処理のモデルを提供しています。
現在は watsonx.ai としてIBMの大規模言語モデルSlateが利用できるようになっています。
Slateでは、独自データを使用してカスタムモデルを作成することで、以下のことができます。
- エンティティの抽出
- テキストの分類
- 評判の抽出
ここではSlateを使用してテキスト分類を行うカスタムモデルの作成と、カスタムモデルの分類精度の評価を行います。
2. 準備
2.1. 実行環境
Watson Studio の Jupyter Notebook を使用します。
Slate を利用するためには Watson Studio で 新規Notebook を作成する際に Runtime 23.1 を選択する必要があります。
2.2. 使用するデータ
カスタム分類モデルを作成するために、学習用の分類ラベル付きデータをCSV形式で準備してWatson Studioプロジェクトの資産にアップロードします。
今回分類評価に使用するデータは Livedoorニュースコーパス をダウンロードして、CSVに変換して利用しています。
9種類のニュースカテゴリーを作成し、新たな記事を分類の結果を確認します。
CSVファイルはUTF-8形式で、以下の形式となります。
・形式は text,labels (textはサンプル文書、labelsはカテゴリー名)
今回はデータとしてニュース記事をtext、記事カテゴリーをlabelsとしてCSVファイルを作成しています。
学習用データ:livedoor-train.csv
評価用データ:livedoor-eval.csv

準備した学習用と評価用のデータはプロジェクトのデータとしてアップロードしておきます

今回と同様の書式でCSVデータを準備することで、以下の手順で分類モデルの作成と精度評価を行うことができます
3. データの読み込み
Watson Studioに登録したデータ資産にアクセスするために、プロジェクトトークンを作成して、以下の プロジェクトトークン を書き換えて実行します。詳細な手順は ibm-watson-studio-lib (Python用) を参照してください。
# プロジェクトにアップロードしてあるデータにアクセスするための設定
from ibm_watson_studio_lib import access_project_or_space
wslib = access_project_or_space({"token":"プロジェクトトークン"})
関連ライブラリを取得して、準備してある学習用データと評価用データを読み込みます
import json
import seaborn as sn
import matplotlib.pyplot as plt
import pandas as pd
# 関連するテキストを探せるように、テキスト表示を大きくします
pd.options.display.max_colwidth = 400
import watson_nlp
from watson_core.data_model.streams.resolver import DataStreamResolver
from watson_nlp.blocks.classification.svm import SVM
# 学習データと評価データの2つのCSVファイルを準備します。ヘッダー行が必要で、今回は"text"と"labels"を前提としています
training_data_file = wslib.load_data("livedoor-train.csv")
eval_data_file = wslib.load_data("livedoor-eval.csv")
# 学習データをデータフレームに取り込む
train_orig_df = pd.read_csv(training_data_file)
eval_df = pd.read_csv(eval_data_file)
# 学習データの最初の2行を表示
train_orig_df.head(2)

学習時に利用するデータはJSONファイルとして保存しておきます。
# 学習データをJSONファイルとして保存
def prepare_data(df):
# textカラムと分類カテゴリの*labels*が必要
df_out = df[['text', 'labels']].reset_index(drop=True)
# labels列は配列でなければなりません (1つしかない場合でも同様)
df_out['labels'] = df_out['labels'].map(lambda label: [label,])
return df_out
train_df = prepare_data(train_orig_df)
train_json_file = './train_data.json'
train_df.to_json(train_json_file, orient='records')
4. Slate分類モデルの学習
IBMのSlate基盤モデルを使用するトランスフォーマーアルゴリズムは、マルチクラスおよびマルチラベルのテキスト分類に使用できます。
マニュアルに従ってSlateの分類モデルを作成します。
# Slateの学習モデルを作成
from watson_nlp.blocks.classification.transformer import Transformer
from watson_core.data_model.streams.resolver import DataStreamResolver
# 学習データからデータストリームを作成
data_stream_resolver = DataStreamResolver(target_stream_type=list, expected_keys={'text': str, 'labels': list})
train_stream = data_stream_resolver.as_data_stream(train_json_file)
# 学習済みのSlateモデルをロード
pretrained_model_resource = watson_nlp.load('pretrained-model_slate.153m.distilled_many_transformer_multilingual_uncased')
# Slateの学習モデルを作成。学習回数はnum_train_cpochsで指定
classification_model = Transformer.train(train_stream, pretrained_model_resource, num_train_epochs=25)
***** train metrics *****
epoch = 25.0
total_flos = 2426763GF
train_loss = 0.4753
train_runtime = 0:13:34.33
train_samples = 3684
train_samples_per_second = 113.098
train_steps_per_second = 14.153
学習を繰り返す回数(エポック数)は num_train_cpochs で指定します。デフォルトは5で、数を増やしすぎると過学習になる場合もあります。
これでSlateのカスタム分類モデルが作成できました。試しに適当な文書を使って分類を実行してみます
text = '大谷翔平は近代のプロ野球では非常に稀な存在となる、シーズンを通して投手と打者を兼任する「二刀流(英: two-way player)」の選手。投手としての球速165 km/hは藤浪晋太郎・佐々木朗希と並んで日本人最速記録である。また、先発投手兼打者として、NPBで1度のリーグ優勝、1度の日本シリーズ優勝、日本代表では、1度のワールド・ベースボール・クラシック(WBC)優勝に大きく貢献している。'
slate_preds = classification_model.run(text)
slate_preds
{
"classes": [
{
"class_name": "sports-watch",
"confidence": 0.9569842219352722
},
{
"class_name": "livedoor-homme",
"confidence": 0.015390502288937569
},
{
"class_name": "movie-enter",
"confidence": 0.008483590558171272
},
・・・
分類結果が得られました! sports-watch なので正しい結果に見えます。
5. SVM分類モデルの学習
比較対象として、マニュアルに従ってSVM(サポート・ベクトル・マシン)の機械学習を使用した分類モデルを作成します。
# 構文モデル
syntax_model = watson_nlp.load('syntax_izumo_ja_stock')
# USE埋め込みモデル
use_model = watson_nlp.load('embedding_use_multi_small')
# 学習データからデータストリームを作成
data_stream_resolver = DataStreamResolver(target_stream_type=list, expected_keys={'text': str, 'labels': list})
training_data = data_stream_resolver.as_data_stream(train_json_file)
# 構文ストリームを作成
text_stream, labels_stream = training_data[0], training_data[1]
syntax_stream = syntax_model.stream(text_stream)
use_train_stream = use_model.stream(syntax_stream, doc_embed_style='raw_text')
use_svm_train_stream = watson_nlp.data_model.DataStream.zip(use_train_stream, labels_stream)
# SVMモデルの学習
svm_model = SVM.train(use_svm_train_stream)
6. 評価用データで分類を実行
2つのカスタム分類モデルが作成できたので、評価用データで分類を実行し、各モデルの分類結果の確認します。
では、評価用データで分類モデルを実行します
# SlateとSVMのモデルで評価
def predict_product(text):
# 最初に構文モデルを実行
syntax_result = syntax_model.run(text)
# 構文結果に基づいてSVMモデルを実行
svm_preds = svm_model.run(use_model.run(syntax_result, doc_embed_style='raw_text'))
predicted_svm = svm_preds.to_dict()["classes"][0]["class_name"]
# Slateモデルを実行
slate_preds = classification_model.run(text)
predicted_slate = slate_preds.to_dict()["classes"][0]["class_name"]
return (predicted_svm, predicted_slate)
predictions = eval_df["text"].apply(lambda text: predict_product(text))
predictions_df = pd.DataFrame.from_records(predictions, columns=('SVM予測値', 'Slate予測値'))
result_df = eval_df[["text", "labels"]].merge(predictions_df, how='left', left_index=True, right_index=True)
result_df.head()

評価用データの右に分類結果として、分類カテゴリの予測値が2列追加されています。 labelが正解の列なのでそれと比較することで精度評価が行えます。以降では混同行列(Confusion Matrix)を使用して結果を可視化します。
7. 分類結果からモデルの品質を比較
7.1. 混同行列の作成とプロット
分類結果の精度の指標として、混同行列を使用して評価をしてみます。
ここでは pandas crosstab を使用して、SlateとSVMの分類精度の混同行列を作成します。Seaborn ヒートマップとしてプロットしています。
SVM_confusion_df = pd.crosstab(result_df['labels'], result_df['SVM予測値'], rownames=['Actual'], normalize='index')
Slate_confusion_df = pd.crosstab(result_df['labels'], result_df['Slate予測値'], rownames=['Actual'], normalize='index')
figure, (ax1, ax2) = plt.subplots(ncols=2, figsize=(15,7))
sn.heatmap(SVM_confusion_df, annot=True, cmap="YlGnBu", ax=ax1, cbar=False)
sn.heatmap(Slate_confusion_df, annot=True, cmap="YlGnBu", ax=ax2, cbar=False)
ax1.title.set_text("SVM")
ax2.title.set_text("Slate")
ax2.set_yticklabels([])
plt.show()
Slate分類モデル作成時のエポック数を5にした場合とSVMモデルの比較
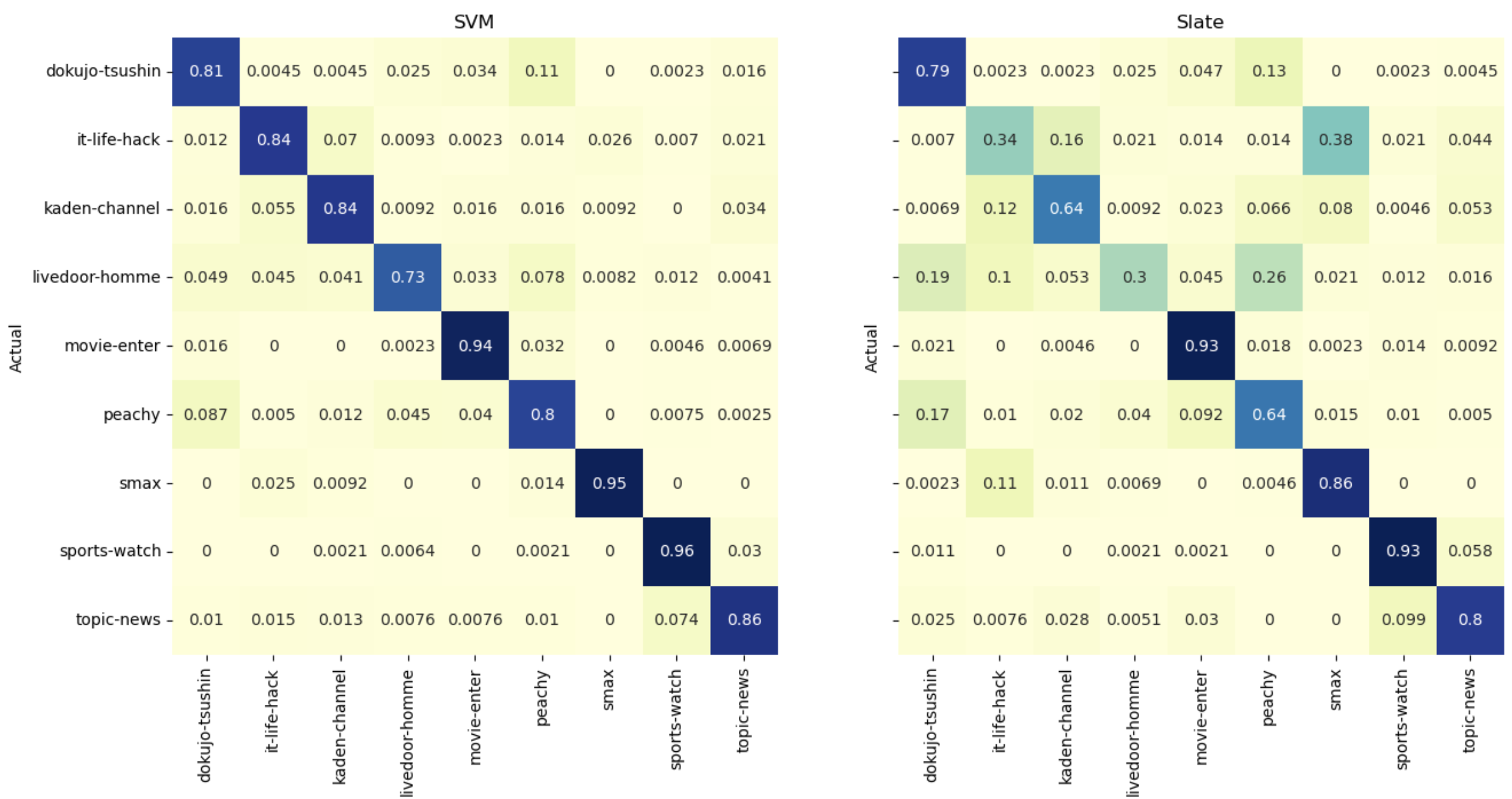
Slate分類モデル作成時のエポック数を25にした場合とSVMモデルの比較

今回のデータでは、Slate分類モデルの作成時にエポック数を25にしたところ、分類結果としてSVMモデルよりも優れた結果が得られました。他にも学習時のオプションやパラメータの指定を行うことで精度が変わることは考えられます。
分類モデルはこれ以外にもアンサンブルモデルやHugging Faceのモデルが利用できます。アンサンブルモデルを使うことで、高い精度のモデルを作成することを確認しています。
8. 作成したカスタム分類モデルの保存
作成したカスタム分類モデルを後から利用できるように、環境に保存します。
# 作成したSlate分類モデルを保存
wslib.save_data('classification_model', data=classification_model.as_bytes(), overwrite=True)
# 作成したSVM分類モデルを保存
wslib.save_data('svm_model', data=svm_model.as_bytes(), overwrite=True)
このモデルを後から使うときは、次のようにして読み込んで利用できます
custom_model = watxon_nlp.load(wslib.load_data('classification_model'))
参考情報
Watson NLP (Natural Language Processing) ライブラリ
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/watson-nlp.html
カスタム分類モデルによるテキストの分類
IBM Slate モデルを使用した変換プログラム・アルゴリズムのトレーニング
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/watson-nlp-classify-text.html?locale=ja&context=cpdaas&audience=wdp#train-slate
Watson NLP(自然言語処理ライブラリー):テキスト分類
https://qiita.com/Jungobu/items/d9a1f1b0ee4c3efc7df2
Fair is fast, and fast is fair: IBM Slate Foundation models for NLP
https://medium.com/@alex.lang/fair-is-fast-and-fast-is-fair-ibm-slate-foundation-models-for-nlp-3508412a4b04