はじめに
とある案件で一部処理をマルチスレッドを使って実装したが、マルチスレッドとマルチプロセスの違いもよく分かってないし、なんで処理が速くなるのかもなんとなくでしか理解してなかったので色々調べてみる。
マルチスレッドとマルチスレッド
とりあえず以下の図から
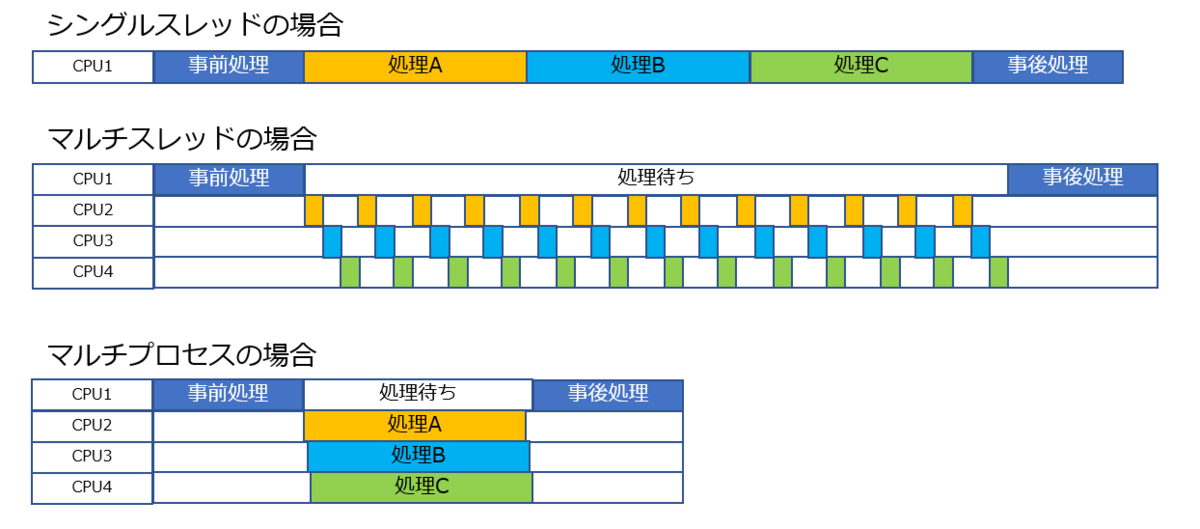
シングルスレッド(逐次処理)とマルチスレッド(並行処理)とマルチプロセス(並列処理)での処理の違いはこんな感じです。
そもそも PythonにはGIL(グローバルインタプリタロック)という仕組みがあり、複数スレッド下でもロックを持つ単一スレッドでしかバイトコードが実行できず、その他のスレッドは待機状態になる。
そのため複数のスレッドが同時に動作出来ないようになっており、Pythonにおけるマルチスレッド処理は基本的に複数の CPU コアを効率よく使って計算をすることが出来ない。
一方、マルチプロセスの場合はプロセスそれぞれにGILが存在する。
ようするに個々のプログラムが独立して動く。 そのため複数のCPUコアで複数のプロセスの処理を同時に実行することが出来る。
ただこの画像見てるとマルチスレッド遅くね、ってなる。実際は実行する処理次第ではシングルスレッドよりも高速に処理される。
PythonのGILはPythonの計算処理が正しく実行されるのを保証するための仕組みなので、ファイルの読み込みやGPU側での計算などの待ち時間までロックする必要はない。
そういう処理を含んでいる場合はGILが解放され、以下の図のように効率的に処理を並列実行することが出来ます。
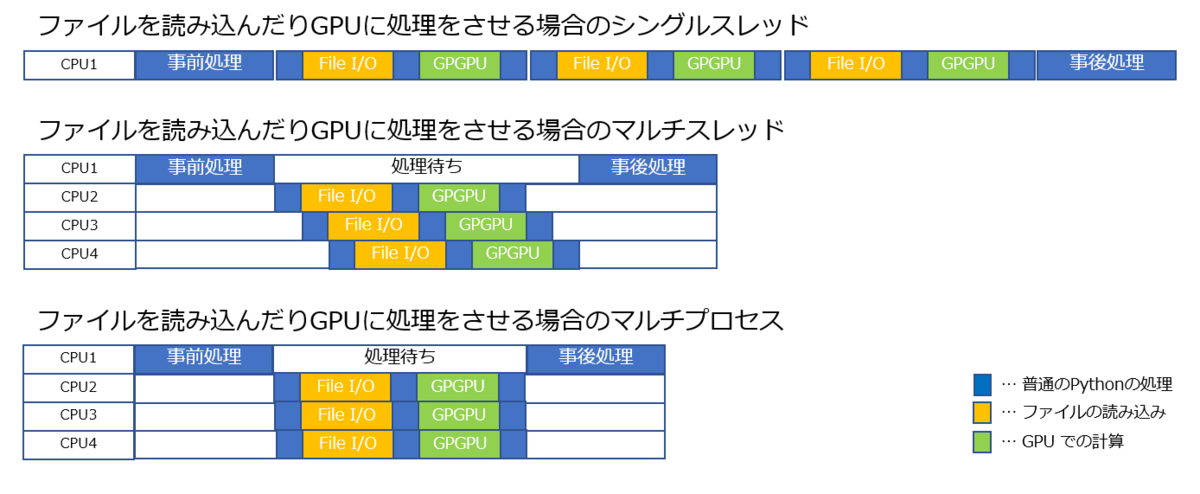
GIL が解放される処理の例
- スリープ
- ファイルアクセス
- ネットワーク通信の送受信
- GPU コンピューティングの結果待ち
- subprocess モジュールで別プログラムを実行
- print などの出力
実装時(並行処理)
pythonでの並列処理ではthread、threadingもしくはconcurrent.futuresを使用。
thread
- 古いPython2系のバージョンだとこのモジュールしかなかったりするものの、基本的には使い勝手が悪いので使わない。
- Python3系では間違って使わないように、_threadとアンダースコアがつけられているらしい。
threading
- thread上位互換。並行処理のベーシックなビルトインモジュール。
- インターフェイスが大分親切になった。
- Python3系はもちろんのこと、2.7系とかでももう使えるので、基本的にはthreadを使うくらいならthreadingを使うことになる。
concurrent.futures
- Python3.2以降に登場。基本的にthreadingよりもさらに優秀。
- なお、futureは並列処理のFutureパターンに由来する。(1960~1970年代などに発展し、提案された結構昔からあるもの)
- スレッド数の上限を指定して、スレッドの使いまわしなどをしたりしてくれるらしい。
- また、マルチスレッドとマルチプロセスの切り替えも1行変える程度で、このモジュールで扱えるので、途中で変えたくなったり比較してみる際などにも便利。
- threadingとどちらを使うか、という点に関しては、concurrent.futuresが使える環境(Python2.7.xなど)であればそちらを、使えない古い環境であればthreadingという選択で良さそう。
実装時(並列処理)
pythonでの並列処理ではmulitprocessingもしくはconcurrent.futuresを使用。
multiprocessing or concurrent.futures
- マルチプロセス。
- 複数のコアで計算を行う。
- 並行処理がGILによって高速化面で制限がある一方で、こちらは基本的に制限がかからないので高速化が期待できる。
- ただし、メモリをダイレクトに共有することができない。そのままだとプロセス間で変数などをやりとりする際にはpickle化されてコピーが生成され受け渡しがされる。つまり、大きなデータを渡したりするとメモリを瞬間的に膨大に消費したり、pickle化などのオーバーヘッドで期待したほど速くならないケースもある。
- これを改善するためには、ビルトインの共有メモリ(shared memory)の機能を使ったり、共有メモリ用のライブラリなどを利用する。同時に更新したりしないように注意は必要になるものの、pickle化を省けるので処理時間が短くなり省メモリで扱える。
- プロセス生成などにある程度オーバーヘッドがあるので、一瞬で終わるようなタスクに対してプロセスを分けたりすると逆に遅くなるケースがある。
- モジュールは基本的にmultiprocessingもしくはconcurrent.futuresを利用する。
- concurrent.futuresは並列・並行処理どっちもいける良い奴
- multiprocessingにはさらにProcessやPoolといったように複数の選択肢がある。
processとpoolの違い
process は、複数の関数を複数プロセスで並列して実行。実行中の関数は全てメモリ上に展開される。
pool では、一つの関数に複数の処理を行わせる際に、その処理を複数プロセスに割り当てて並列して実行します。pool 側でタスクの分割や結果の統合といったことを暗黙的に制御し、実行中の処理のみがメモリ上に展開される。
シングルスレッド・マルチスレッド・マルチプロセス 処理速度の違い
concurrent.futuresを使って実際に処理速度の違いを見てみる
シングルスレッド
from concurrent.futures import ThreadPoolExecutor
import time
def func():
time.sleep(1)
start = time.time()
for i in range(8):
func()
print (time.time()-start)
# 結果 8.01124382019043
マルチスレッド
from concurrent.futures import ThreadPoolExecutor
import time
def func():
time.sleep(1)
start = time.time()
with ThreadPoolExecutor(max_workers=4) as e:
for i in range(8):
e.submit(func)
print (time.time()-start)
# 結果 2.0168681144714355
マルチプロセス
from concurrent.futures import ProcessPoolExecutor
import time
def func():
time.sleep(1)
start = time.time()
with ProcessPoolExecutor(max_workers=4) as e:
for i in range(8):
e.submit(func)
print (time.time()-start)
# 結果 2.1066465377807617
まぁ結果は予想通り割り当てられたCPU分処理が速くなった。
では次はマルチスレッドとマルチプロセスで処理速度に違いが出るパターンを見ていく
import os
import time
import datetime
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
# 調査する複素空間
x1, x2, y1, y2 = -1.8, 1.8, -1.8, 1.8
c_real, c_imag = -0.62772, -0.42193
def calculate_z_serial_purepython(maxiter, zs, cs):
"""皆大好きジュリア漸化式を用いてoutput リストを計算する"""
output = [0] * len(zs)
for i in range(len(zs)):
n = 0
z = zs[i]
c = cs[i]
if (i % 100) == 0:
# 100 回に一回の頻度で 100us のスリープ=処理待ちを挿入
time.sleep(0.0001)
while abs(z) < 2 and n < maxiter:
z = z * z + c
n += 1
output[i] = n
return output
def calc_pure_python(desired_width, max_iterations):
x_step = (float(x2 - x1) / float(desired_width))
y_step = (float(y1 - y2) / float(desired_width))
x = []
y = []
ycoord = y2
while ycoord > y1:
y.append(ycoord)
ycoord += y_step
xcoord = x1
while xcoord < x2:
x.append(xcoord)
xcoord += x_step
zs = []
cs = []
for ycoord in y:
for xcoord in x:
zs.append(complex(xcoord, ycoord))
cs.append(complex(c_real, c_imag))
output = calculate_z_serial_purepython(max_iterations, zs, cs)
if __name__ == "__main__":
max_workers = os.cpu_count() #最大ワーカー数をシステムの CPU コアと同じにする
#シングルスレッドの場合
start = datetime.datetime.now()
for i in range(16):
calc_pure_python(desired_width=500, max_iterations=100)
elapsed = datetime.datetime.now() - start
print("SingleThread: {}ms".format(elapsed.seconds*1000 + elapsed.microseconds/1000))
# マルチスレッドの場合
start = datetime.datetime.now()
with ThreadPoolExecutor(max_workers=max_workers) as executor:
for i in range(16):
executor.submit(calc_pure_python, 500, 100)
elapsed = datetime.datetime.now() - start
print("MultiThread: {}ms".format(elapsed.seconds*1000 + elapsed.microseconds/1000))
# マルチプロセスの場合
start = datetime.datetime.now()
with ProcessPoolExecutor(max_workers=max_workers) as executor:
for i in range(16):
executor.submit(calc_pure_python, 500, 100)
elapsed = datetime.datetime.now() - start
print("MultiProcess: {}ms".format(elapsed.seconds*1000 + elapsed.microseconds/1000))
# SingleThread: 40289.033ms
# MultiThread: 45673.411ms
# MultiProcess: 19700.485ms
マルチプロセスではしっかり処理が速くなってますがマルチスレッドでの処理がシングルスレッドよりも遅くなりました。
理由としては、GILの解放が少ないためです。
シンプルなプログラムではGILの関係上、シングルスレッドの方がマルチスレッドよりも早い場合があります。
じゃあマルチプロセスの方が処理早いし常にこっち使えばいいじゃない。とはならない。
マルチプロセスのデメリット1(オーバーヘッドの大きさ)
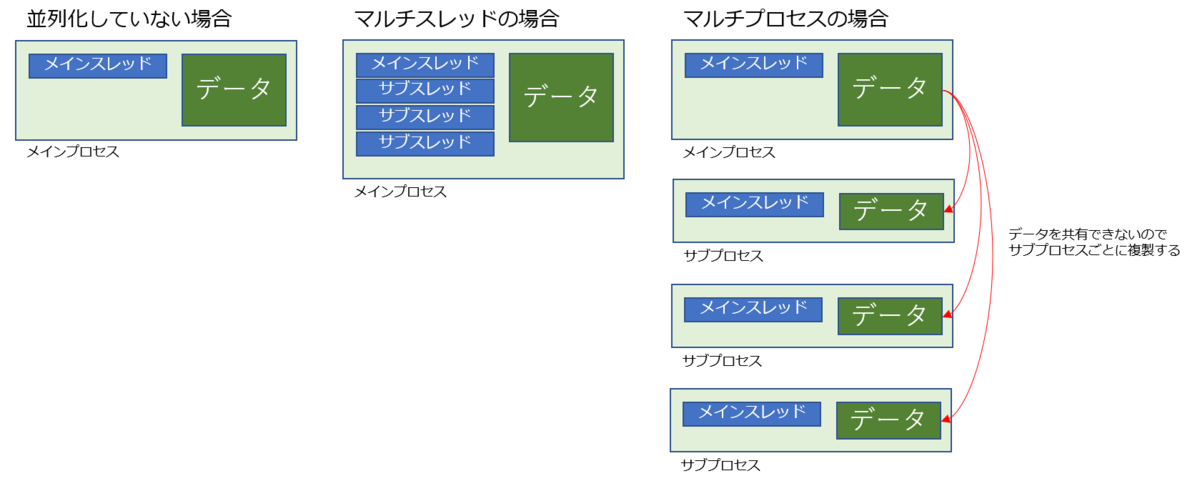
マルチプロセスは個々のプロセスがメモリ空間を共有しない、つまり内部データを共有していない。なので新しいプロセスを生成するたびに必要なデータを複製する必要があります。
その点マルチスレッドは同じプロセス内にスレッド(本体とは別のプログラムの流れ)を作るだけなので、短時間で作れ、メモリ消費も少なくて済みます。
速度比較
オーバーヘッドが大きいと言ってもピンとこないので、実際に動かして確認。
- 時間
- MultiThread 3885.588ms
- MultiProcess 31397.583ms
プロセス生成のオーバーヘッドは処理速度の低下をもたらすので必ずしもマルチプロセスの方がいいとはならない。
マルチプロセスのデメリット2(子プロセスに渡すデータに Pickle 化できないオブジェクトがあってはいけない)
プロセスを生成する際、システムが必要なオブジェクトを Pickle 化 (Serialization) する。データをコピーするのにPickle 化が必須だからです。 もし、Pickle 化できないオブジェクトが含まれている場合 ProcessPoolExecutor.submit() 内でエラー停止してしまいますので、マルチプロセス化でき無くなる。
終わりに
なんとなくわかった気はする…
それぞれメリットデメリットあるので、処理内容に応じて使い分けれるように、しくみをちゃんと理解しておこう。