1.はじめに
Nutanixと言うとハードウェア(HCI)製品を思い浮かべる人も多いと思うが、
今回Nutanix社ハイパーバイザー製品中心に超ざっくりと解説したいと思う。
某製品からの浮気相手として人気急上昇中である。
気が向いたら記事は追記していく予定。
2.参考資料
教典。とりあえず読もう。網羅的に理解出来て良いぞ。
(英語版のほうが情報新しいかも。)
TestDrive。いわゆる公式提供のHands on Lab。
気になるものはやってみよう。
Nutanix Community Edition。
検証版のため個人でもカジュアルに使い倒せるぞ。
3.AHV
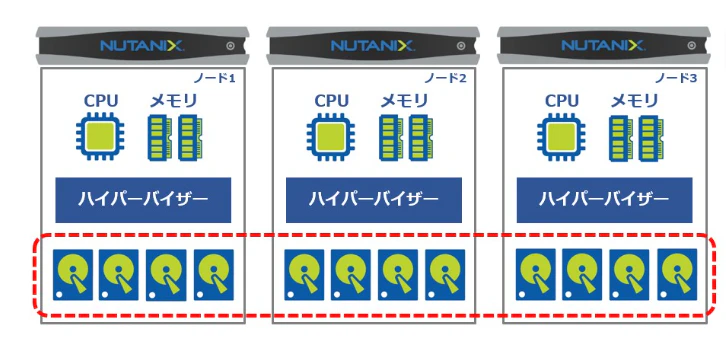
Nutanixノード(HCI)向けに作られたハイパーバイザー機能
ノードのベアメタルにFoundation(初期セットアップ)でインストールされる。
コンピュートリソース、ストレージリソースをもとに仮想マシンを作成、管理可能。
物理ノードのOS = AHV
https://licensecounter.jp/engineer-voice/blog/articles/20190905_nutanix_hciahv.html
4. CVM/AOS
奥が深くて重要な要素。
Controller VM。各Nutanixノードに1台存在する仮想マシン。
NutanixノードをFoundation(初期セットアップ)でクラスタ構築する際に、
ハイパーバイザー種別に関わらず仮想マシンが作成される。
CVM自体はAOSという独自OSで動作する。
CVMのOS = AOS
クラスタ内のストレージリソースをもとに共有ストレージを作成、管理する機能を持つ。
また、後述する管理コンソールであるPrism自体を動かすために重要な仮想マシン。
似た機能としてNetAppストレージのSVMのようなものと考えれば良いかも。

https://licensecounter.jp/engineer-voice/blog/articles/20220119_aosahv.html

https://licensecounter.jp/engineer-voice/blog/articles/20190905_nutanix_hciahv.html
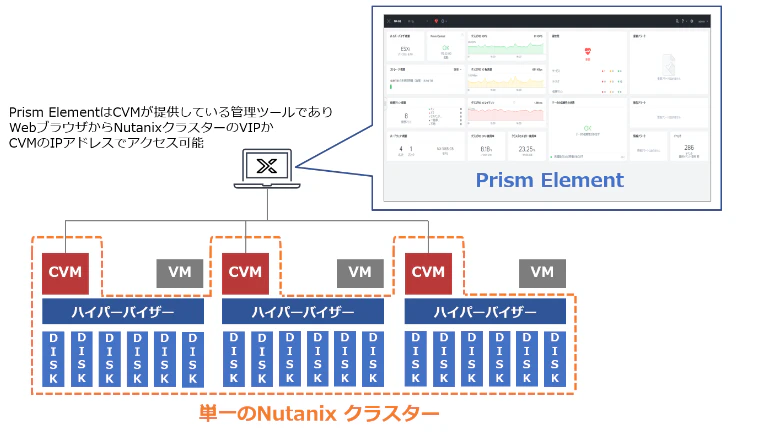
5. Prism
管理コンソール自体のこと。
vSphere Clientをイメージしてもらえると良い。
Prism ElementとPrism Centralの二種類がある。
前者はCVM上でサービスが動作する。
ESXi自体の管理コンソールとの違いは、
Nutanixの場合、クラスタとして初期構成されるので、
単一ノードでなく単一クラスタの単位で情報を表示出来る点。
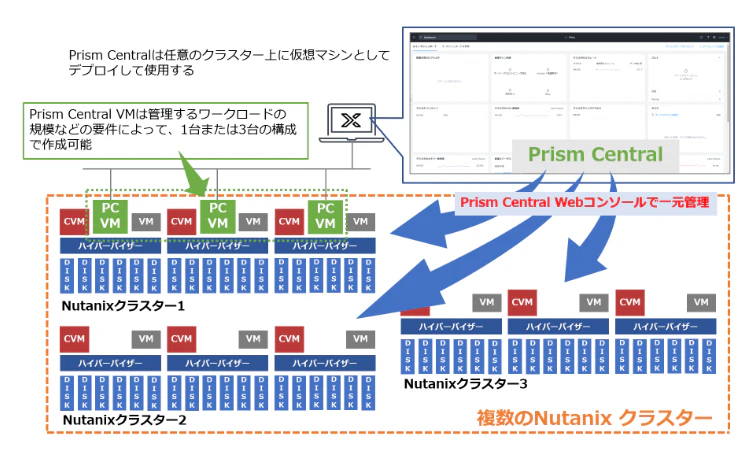
後者は仮想アプライアンス形式等でFoundation後に別途必要に応じてデプロイする。
単一クラスタや、複数クラスタを統合的に管理することが可能。
vCenterと同様のイメージで捉えてもらって良いと思う。
上記について、それぞれで出来ること出来ないことが結構あってややこしい。
Prism Centralが完全上位互換というわけでないので、用途に応じて使い分ける必要有。
https://licensecounter.jp/engineer-voice/blog/articles/20210119_nutanix_-prism_central_-.html
https://licensecounter.jp/engineer-voice/blog/articles/20210119_nutanix_-prism_central_-.html
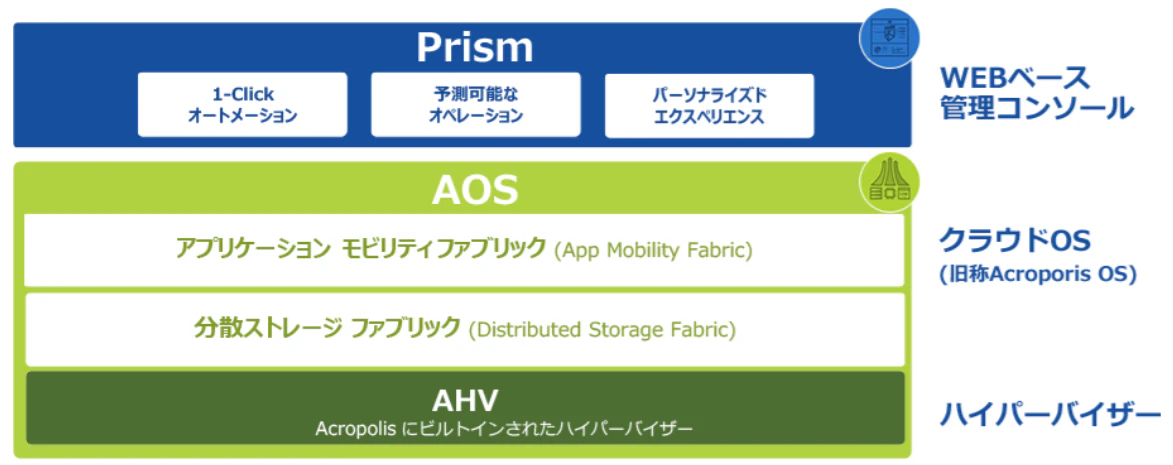
6. OverView
https://www.idaten.ne.jp/portal/page/out/mss/nutanix/software.html
管理コンソールを提供し、ライセンス管理やヘルスチェック、ログ管理など可能なPrism
CVMにインストールされ、共有ストレージやPrismを機能させるAOS
物理ノードにインストールされ、仮想マシンを管理するAHV
上記のイメージで理解いただければ概ね方向性はOKだ。
AOSについては、個人的にCVMと同義で覚えておくと混乱しなくておすすめだ。
vCenterを動かしているPhotonOSのようなイメージ。
ここが曖昧だとAOSをESXiと同義にイメージしてしまってややこしかった。
AOSはCVMのOS、AHVはベアメタルのOS。
また、上記をさらに大枠として定義したNutanix Cloud Platformという概念もある。 クラウドも絡めたサービス群の構想といった所だが、まだ中身に説得力がないのが正直な感想。

https://www.idaten.ne.jp/portal/page/out/mss/nutanix/license.html
アーキテクチャのイメージとしてはこんな感じ。 CVMは共有ストレージのデータI/Oを仮想マシンやハイパーバイザに中継する役割もある。
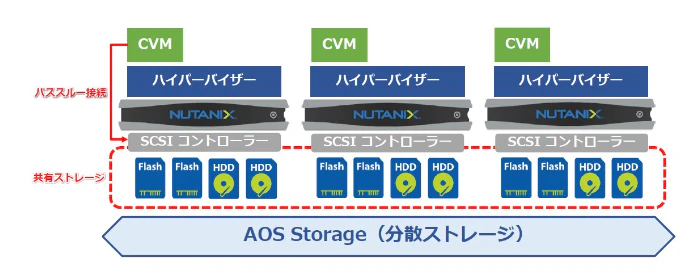
https://licensecounter.jp/engineer-voice/blog/articles/20190905_nutanix_hciahv.html
99.Tips
99-1.冗長性
観点は4つ。ノードの冗長性、データ(共有ディスク)の冗長性、CVMの冗長性
あと、HW側の構成の話だが、ローカルディスクの冗長性
以下2つの仕組みが存在する。略称は両方ともRFだが冗長する箇所が違う。
Replication Factor =データを冗長化する
Redundancy Factor =ノードを冗長化する
なんでこんなややこしい名前にしたの..。
99-1-1. Replication Factor
詳細は割愛するが、前者はディスク単位でなくディスク内のデータ単位で冗長化する。
ホットスペアやRAIDなどの概念はない。
共有リソースに空きがある限り障害時も自動的にデータが複製される。(セルフヒール機能)
リジェネかな?
メリットはストレージリソースに余裕があり、データ複製されるより早く、
複数のディスクで同時多発的に障害が起こらない限り可用性が損なわれない点。
デメリットはRAIDの仕組みとは別で単純にデータを複製するので、
ストレージリソースを比較的消費しやすい点。
冗長レベルはRF1、(冗長なし)、RF2(二重化)、RF3(三重化)を選択可能。
たとえば三重化だと単純に三倍のリソースを消費する。
ディスクが一つ壊れた後に、新たなコピー処理が完了するまでに新たにディスクが壊れるリスクを許容出来るならば、冗長レベルは二重化で問題ないと思う。
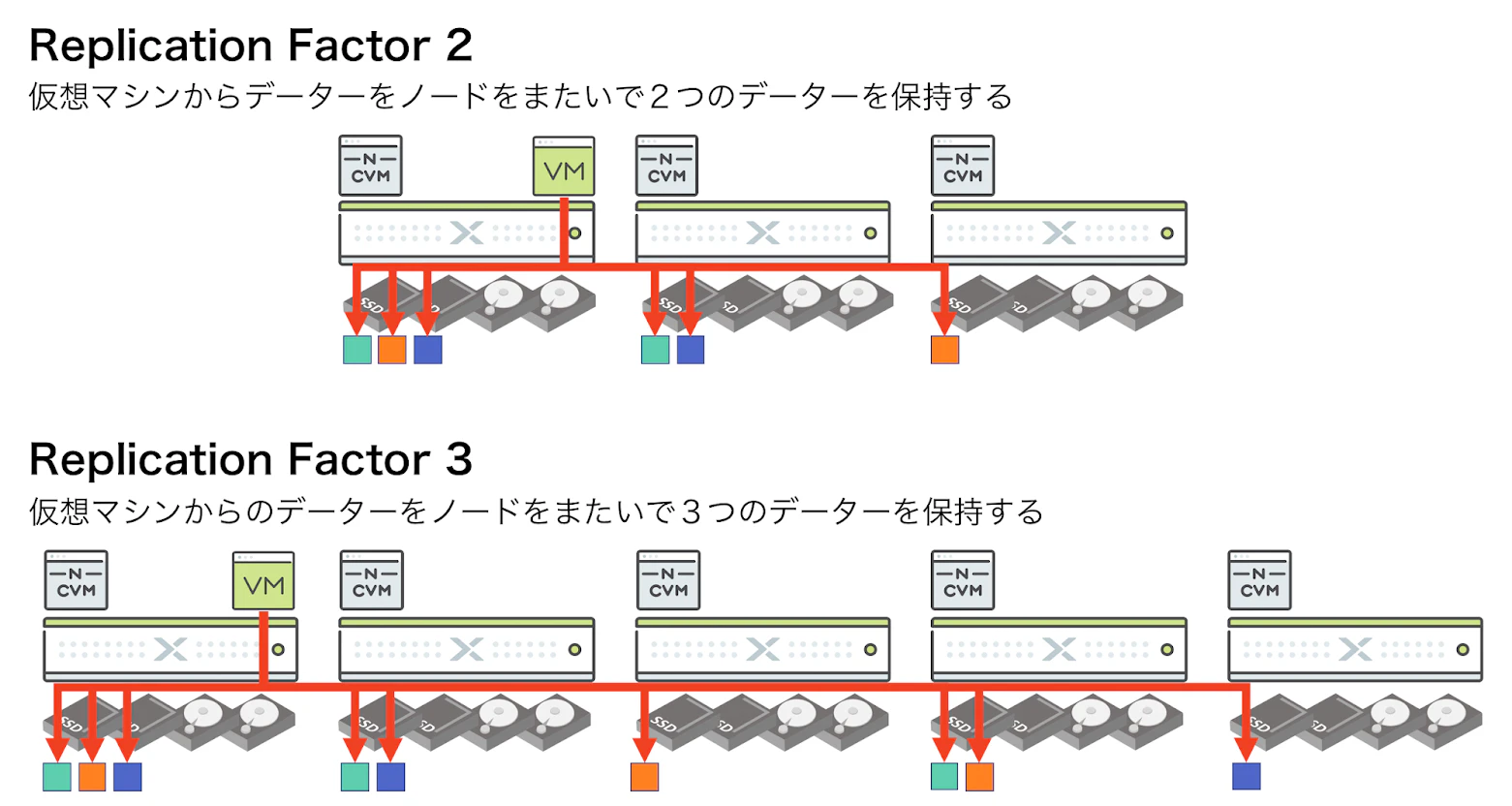
https://infraapp.blogspot.com/2018/05/redundancy-factorreplication-factor.html
99-1-2. Redundancy Factor
ノード冗長化
仕組みとしてはFailOverでの高可用性担保。
RF1(N+0)、RF2(N+1)、RF3(N+2)で構成可能。
ノード障害時も数分以内に仮想マシンは復旧する模様。
RF2は最低3ノード構成が必須。
RF3は最低5ノード構成が必須。

https://infraapp.blogspot.com/2018/05/redundancy-factorreplication-factor.html
99-1-3. CVMの冗長性
CVM自体がダウンした場合、データのI/Oが機能しなくなる。
が、別ノードのCVMが処理をバイパスして引き継ぐため数十秒ほどで復旧する。
ちなみに、平常時はデータローカリティの仕組みに基づいて、
対象仮想マシンのコンピュートリソースが動いてるノード配下にデータを保存し、
ノードを跨がずローカル内でI/Oを完結することでレスポンスを高めているそうな。
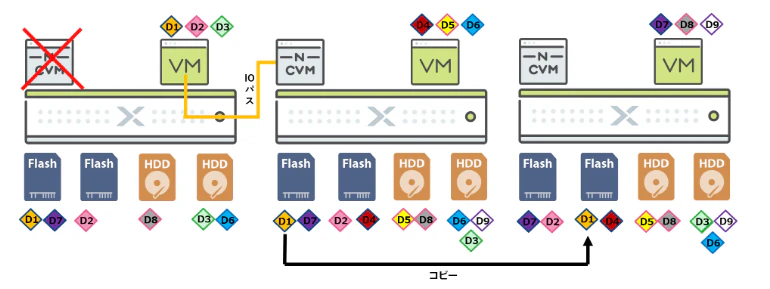
https://licensecounter.jp/engineer-voice/blog/articles/20210210_nutanix_2.html
99-1-4. ローカルディスクの冗長性
ここはNutanix製品の仕組みでなく、HW製品構成の問題。
昨今のNutanixノードはローカルディスクがRAID1で冗長化されてるモデルだと思われる。
ここが初期セットアップ用のFoundationデータやらCVMデータの保管に使われる。
ここがちょうどハードとソフトの境目で盲点になるので意識されたし。
古いノードモデルだとローカルディスクが冗長化されてない場合があるらしく、
その場合はディスクが壊れた際にCVMが落ちて実質ノードが機能しない状態となる。
以下、ブート領域=ローカルディスク。
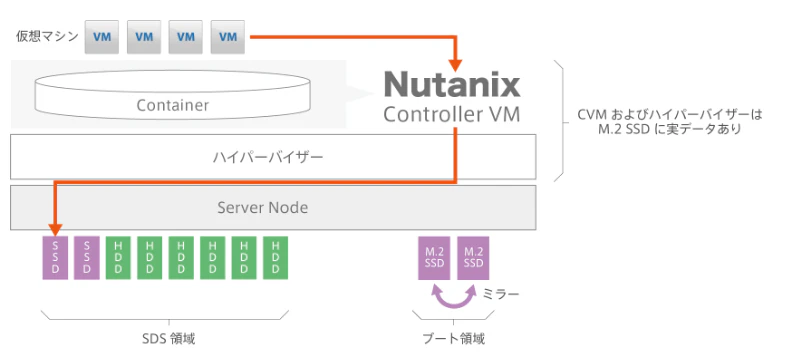
https://sandi.jp/column/hci/vsan-vs-nutanix
99-99.まとめ
某ハイパーバイザメーカーと違ってパブリッククラウドとの連携に積極的な印象を受ける。
成熟度的に様々なサービスがスタックされた例の製品に総合力でどうしても見劣りするが、
費用面も踏まえると、シンプルな構成にする場合やハイブリッドクラウドを将来的に構想したい場合は選択肢となり得るのではなかろうか。