政府統計データを用いて、ライフスタイル分類をし、Plotly ExpressのChoropleth Mapを使って視覚化したので、
その概要を紹介したいと思います。
詳細はJupyter Notebookを御覧ください。https://github.com/Jun-Tam/JapaneseCensusAnalysis
データ準備
まずはデータを取ってくる作業ですが、国勢調査等の政府統計データを公開しているe-StatのAPI機能を使いました。
以下のリンク先を参考にしたのですが、一度にリクエストできるデータのレコード数が10万件までなので、
結合してから出力する必要があります。他は殆ど変えずに使わせて頂きました。
【参考】:https://note.nkmk.me/python-e-stat-api-download/
前処理
Feature Engineeringの箇所は少し泥臭いので、詳細はJupyter Notebookを御覧ください。
e-Statに加えて、国土交通省国土政策局の国土数値情報ダウンロードサービス(http://nlftp.mlit.go.jp/ksj/) も興味深いデータを公開しており、シェープファイルとしてダウンロードし、QGISで簡単な加工をした後に特徴量として含めました。
標準化
データの標準化を行います。今回は分散と歪度を調整して変換するPowerTransformerを選びます。
from sklearn.preprocessing import PowerTransformer, MinMaxScaler
data = df.loc[:,item].values.reshape(-1,1)
scaler = PowerTransformer().fit(data)
df.loc[:,item] = scaler.transform(data)
変換前
変換後
クラスタリング
次にUMAP (Uniform Manifold Approximation and Projection)で次元削減をし、k-meansでクラスタリングを行います。
UMAP
import umap
X = df.loc[:,list_field].values
reducer = umap.UMAP(min_dist=0,n_neighbors=10, random_state=42, transform_seed=42)
embedding = reducer.fit_transform(X)
k-means clustering
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = num_class, random_state=42)
kmeans.fit(X)
centroids = kmeans.cluster_centers_
labels = kmeans.predict(X) + 1
次元削減とクラスタリングの結果はこんな感じです。
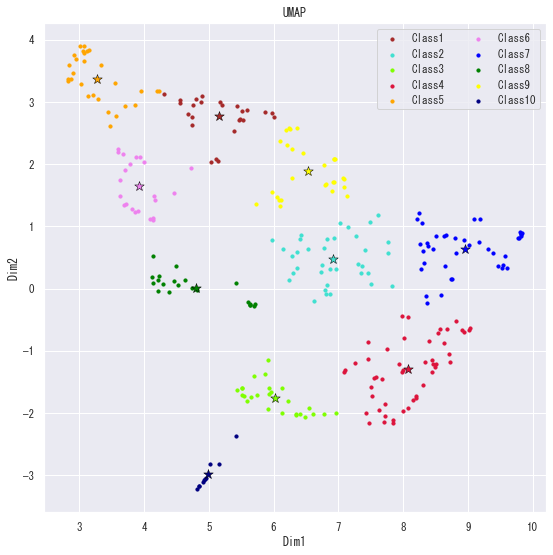
クラスの命名
各クラスの特徴量の中央値と代表都市を見ながら、凡例用に命名します。代表都市はクラスター中心からの距離でソートし、トップ5を載せています。
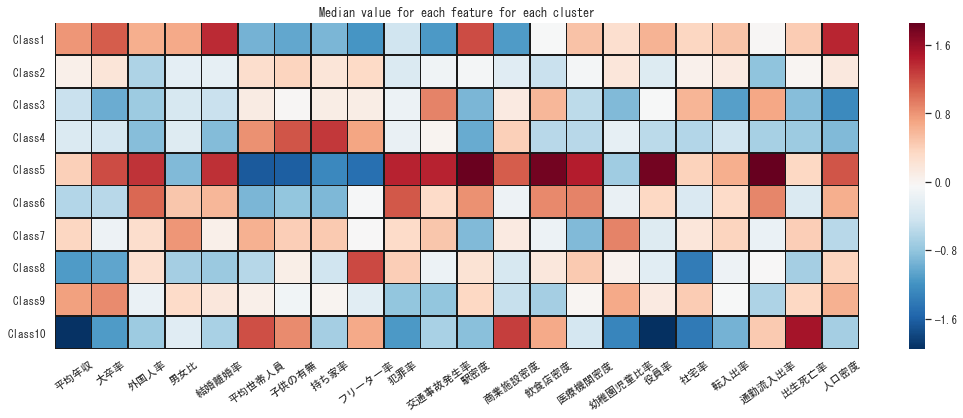
Class1: エリートの街(高学歴・高年収、治安の良い都市部、多い結婚数・子供少なめ)
東京都品川区、埼玉県さいたま市中央区、千葉県浦安市、 東京都江東区、東京都葛飾区
Class2: 自然のある郊外(子家族世帯、安全、ベッドタウン)
埼玉県ふじみ野市、千葉県我孫子市、宮城県仙台市宮城野区、東京都昭島市、埼玉県新座市
Class3: 衰退都市(低い人口密度、低学歴・低年収、交通事故多め、多い転出数・死亡数、持ち家率高め)
大阪府泉佐野市、愛知県名古屋市港区、兵庫県姫路市、和歌山県和歌山市、石川県金沢市
Class4: ベッドタウン、マイホーム(家族世帯、フリーターが多い、低い人口・駅密度、ベッドタウン)
北海道札幌市清田区、奈良県北葛城郡上牧町、北海道札幌市手稲区、埼玉県蓮田市、神奈川県秦野市
Class5: 大都会(高学歴、外国人、多い結婚数、一人暮らし、治安悪い、金持ち、人混み)
大阪府大阪市福島区、東京都豊島区、東京都新宿区、神奈川県横浜市西区、 大阪府大阪市阿倍野区
Class6: ヤンキーの街(低学歴・低年収、外国人、一人暮らし、高い犯罪率、人混み)
福岡県北九州市小倉北区、愛知県名古屋市中川区、大阪府大阪市東成区、愛知県名古屋市北区、福岡県福岡市博多区
Class7: ベッドタウン、車社会(家族世帯、持ち家、低い駅・医療機関密度、低い人口密度)
愛知県春日井市、愛知県岩倉市、神奈川県海老名市、愛知県西春日井郡豊山町、愛知県北名古屋市
Class8: フリーターの街(低学歴、低年収、高いフリーター率、少し犯罪率高め)
京都府京都市北区、京都府京都市左京区、大阪府寝屋川市、大阪府松原市、大阪府大東市
Class9: 裕福な郊外(高学歴、高年収、治安良し、それほど人混みでない)
神奈川県横浜市緑区、埼玉県戸田市、千葉県船橋市、神奈川県横浜市保土ケ谷区、神奈川県横浜市磯子区
Class10: 低所得、子沢山(低学歴、低年収、子沢山)
沖縄県宜野湾市、沖縄県浦添市、沖縄県沖縄市、沖縄県那覇市、沖縄県中頭郡西原町
マップ化
最後に、geopandasとplotly expressを使い、ポリゴンデータとデータフレームを組み合わせて、地図上にマッピングします。
都市部に対象を絞るため、人口密度と商業施設密度でフィルターをかけ、約300のレコードを使用しています。
import json
import plotly.express as px
import geopandas as gpd
# Geopandasを使いgeometry polygonを含むDataFrameをgeojson形式で保存、読み取り。
path_geojson = "./japan_ver81/japan.geojson"
list_field = ['JCODE','CITY_ENG','Class']
df_show.loc[:,['JCODE','geometry']].to_file(path_geojson, driver='GeoJSON')
with open(path_geojson) as json_file:
geojson = json.load(json_file)
# クラス分けされた市町村データを含むDataFrameをplotly expressのchoropleth関数を使ってプロット。
fig = px.choropleth(df,geojson=geojson,color="Class",locations="JCODE",
featureidkey="properties.JCODE", projection="mercator",
hover_data=["KEN","CITY_JP","Class",'P_NUM'])
fig.update_geos(fitbounds="locations", visible=False)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
fig.show()
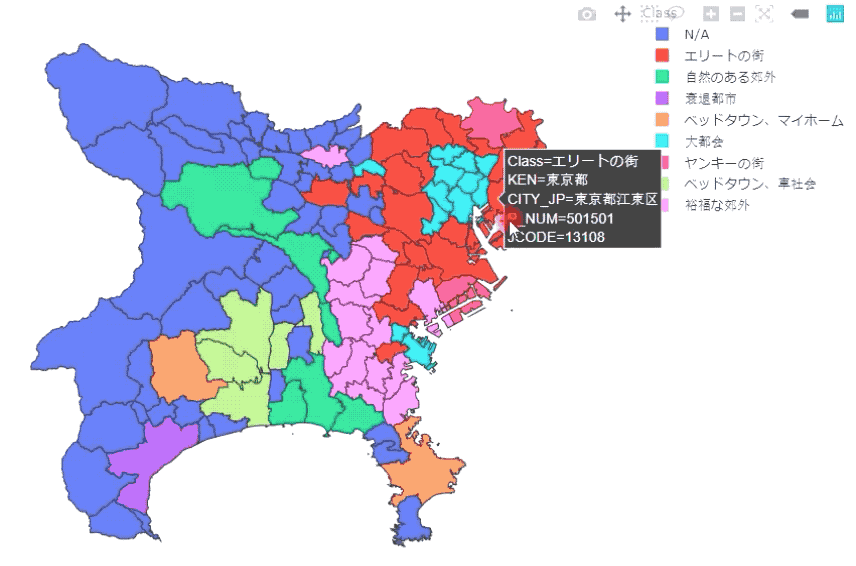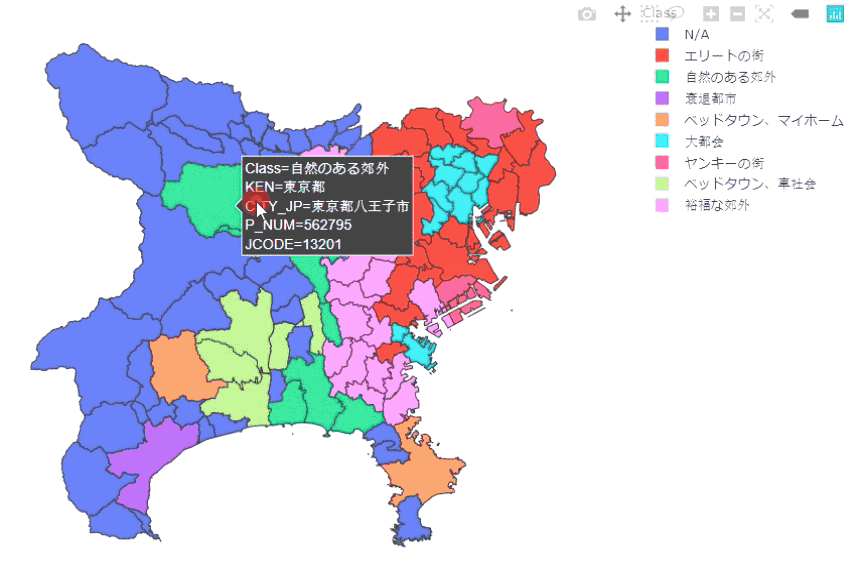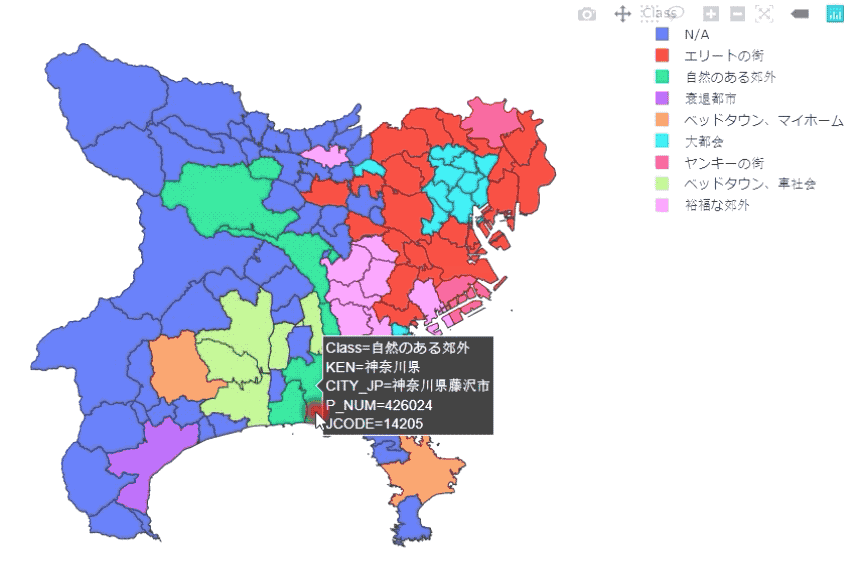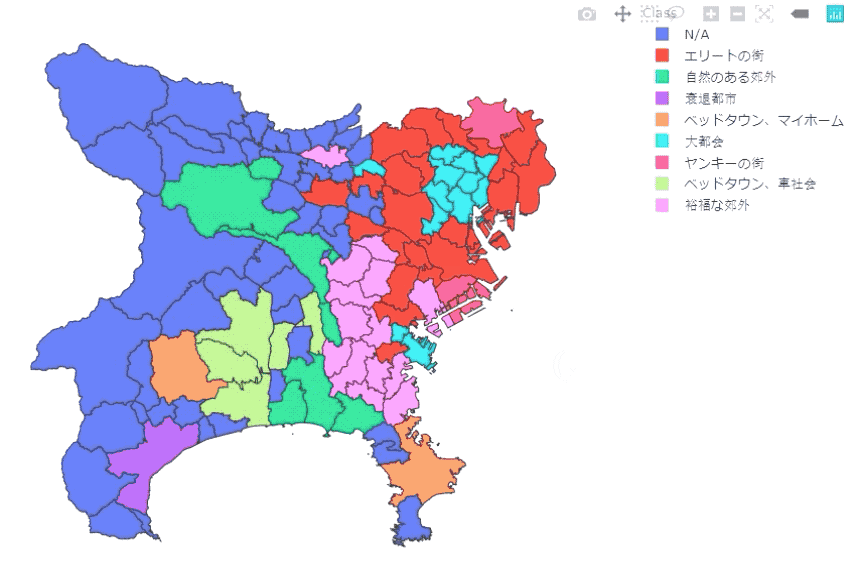
Plotly Expressを使っているので、ホバリングをしながら、県・市区町村、人口等の情報を確認することができます。
上の図は、東京都、埼玉県、神奈川県の結果です。足立区、川崎市はやはり治安が悪いようです…