blackbird ElasticLoadBalancing plugin
このプラグインでは、CloudWatch APIをblackbird側で実行してElasticLoadBalancing(以下ELB)の各種Metricsを取得します。
You can get following CloudWatch Metrics
以下のCloudWatchのMetricsを取得できます。左から順に、CloudWatchのMetric名(Metric自体の意味については本家を参照)、どの統計でとるか(単位時間あたり(厳密には取得間隔あたり)の合計とか平均とかです)、ちょっとした説明です。
| CloudWatch Metric Name | Statistics | Detail |
|---|---|---|
| HTTPCode_Backend_2XX | Sum | 取得間隔内のbackendのサーバの2XX系ステータスの合計 |
| HTTPCode_Backend_3XX | Sum | 取得間隔内のbackendのサーバの3XX系ステータスの合計 |
| HTTPCode_Backend_4XX | Sum | 取得間隔内のbackendのサーバの4XX系ステータスの合計 |
| HTTPCode_ELB_4XX | Sum | 取得間隔内のELBのサーバの5XX系ステータスの合計 |
| HTTPCode_ELB_5XX | Sum | 取得間隔内のELBのサーバの5XX系ステータスの合計 |
| Latency (Average) | Average | 取得間隔内のレスポンスタイムの平均 |
| Latency (Maximum) | Maximum | 取得間隔内のレスポンスタイムの最大値 |
| Latency (Minimum) | Minimum | 取得間隔内のレスポンスタイムの最小値 |
| RequestCount | Sum | 取得間隔内のリクエストの数 |
| SpilloverCount | Sum | 取得間隔内においてELBの内部リクエストqueueからあふれた数 |
| BackendConnectionErrors | Sum | 取得間隔内においてbackendのサーバにつなげなかった数 |
| HealthyHostCount | Maximum | 取得間隔内におけるbackendのサーバのうちHealthCheckに成功しているホストの数 |
| UnhealthyHostCount | Maximum | 取得間隔内におけるbackendのサーバのうちHealthCheckに失敗しているホストの数 |
About SpilloverCount
SpilloverCountとはその名の通り、あふれた出た数を意味しています。ELBは内部的にRequestをqueue(Surge Queueと呼びます)に溜め込んでいて、backendがあまりにもいそがしくてさばけない場合、そのqueueに一旦requestを格納します。そして、そのqueueがあふれるとSpilloverCountが1以上になります。(書きながらSurgeQueueLength取得してないのまずいなと思っています...近日中に取得します。)
なので、SurgeQueueLengthが増えてくるとそもそもbackendのサーバはそのtraficをさばききれていない状態で、結構まずいんですががんばればqueueがあふれるまでの間に返せることもあるでしょう的な状態で、その状態からSpilloverCountが増えてくるとおそらくサービスとしてはほとんど機能していない状態になっているのではないでしょうか。
About BackendConnectionErrors
こっちも増加してくるとサービスとしては機能していないという点では似ていると思うんですが、epoll(たとえばnginxのように)や、あるいはそれに類似したI/O、Network処理を非同期で行うものがbackendのサーバの場合、新規connection自体はEstablishできますが、処理がそもそも追いつかない可能性もあります。そんなときは、BackendConnectionErrorsは出てないけど、SpilloverCountが増加していると思われます。
Zabbix Template
ここからはZabbixテンプレートのお話です。
Triggers
ざっくり機能だけってことで、
- Average Latencyが_一定_msを超えていないか
- Maximum Latencyが_一定_msを超えていないか
- Backend側とELB側のHTTP StatusCodeの4XXが_一定_数以上出ていないか
- Backend側とELB側のHTTP StatusCodeの5XXが_一定_数以上出ていないか
- SpilloverCountが_一定_数以上出ていないか
- BackendConnectionErrorsが_一定_数以上出ていないか
こんな感じのアラートを投げてくれます。それぞれ_一定_になっているところはTemplateのMacroにしておきましたので、サービスのTrafficの特性に応じて編集してくださいまし。また、それぞれのトリガーは三段階のSerbilityをもたせているので、Infoならchat、Averageならメール、Highならケータイみたいなことも可能です。
Graphs
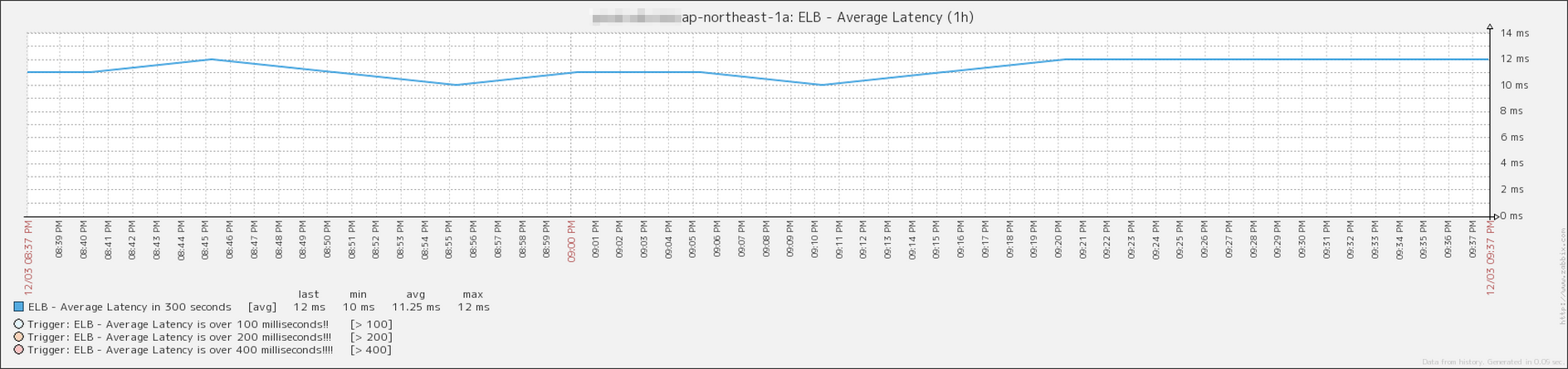
レスポンスタイムの平均
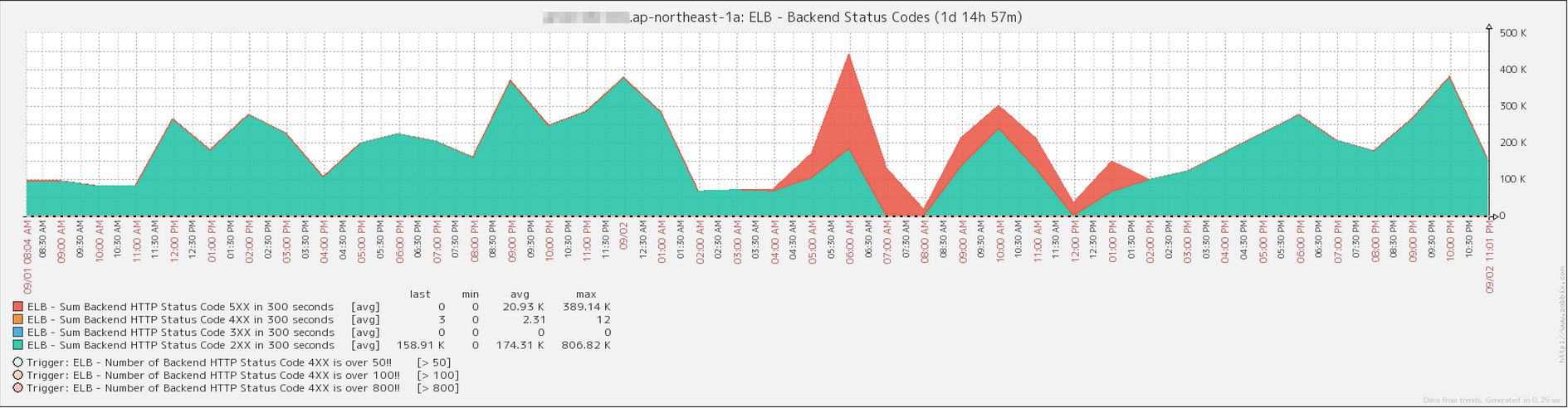
Backendのステータスコードの積算グラフ
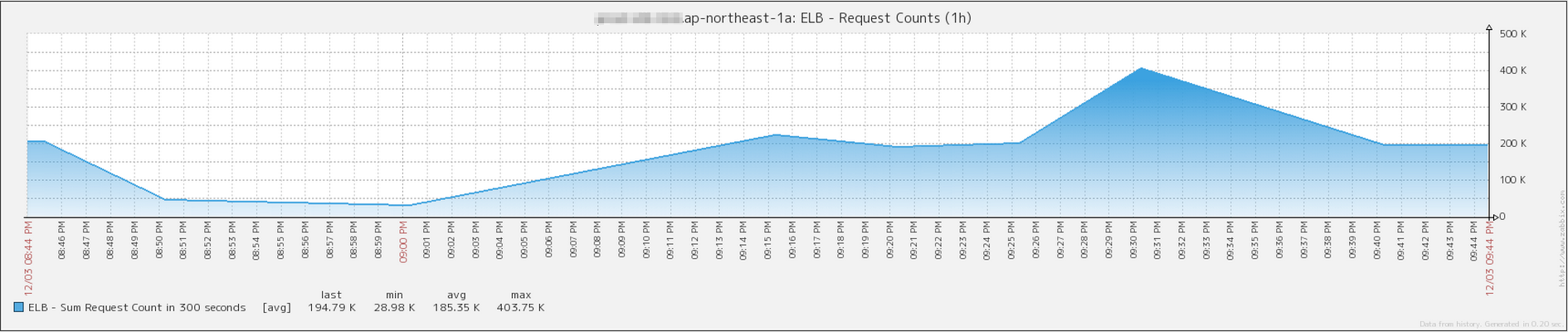
RequestCount
レスポンスタイムの最大値
普通の棒グラフのため割愛
ELBのステータスコード(4XX,5XXのみ)の積算グラフ
普通の棒グラフのためry
How to Install
Case of Using pip
pip install blackbird-elb
PyPiに登録してあるので、pipでさくっと入れちゃってください。
Case of Using yum
まずはrepoファイルを作成しましょう。(もちろん最終的にはhttp://blackbird.example.com/blackbird_install.sh | sh的なことをしたいとは考えてるんですが、もう少々お待ちをば。)
[blackbird]
name=blackbird package repository
baseurl=https://vagrants.github.io/blackbird/repo/yum/6/x86_64
enabled=0
gpgcheck=0
yum install blackbird --enablerepo=blackbird
How to Use
Configure your blackbird
# iniファイル形式で言うセクション名はなんでもおkです
# ただ内部的にはこの名前でthreadを生成するので、ほかとかぶらない方が無難です
[ANYTHING_OK]
# 取得間隔です。1秒とかも設定できますが、CloudWatch側が対応してないので、最低値は60秒です
interval = 300
# region名です。defaultはus-east-1。
region_name = ap-northeast-1
# AWSのcredentailです
# EC2 InstanceのIAM Roleからstsでっていう認証をしたいとは考えているので、しばしお待ちを。ぼくもここにcredentialを書きたくないんです
aws_access_key_id = ACCESS_KEY_ID
aws_secret_access_key = SECRET_ACCESS_KEY
# ELBの名前
load_balancer_name = YOUR_ELB_NAME
# ELBのCloudWatchのMetricsはAZごとに値を取れるのでavailability_zoneを指定します(どっちのAZによってるとかもわかるので、ちょっとうれしいこともあります)
availability_zone = ap-northeast-1a
# Zabbix Web(普段みなさんがつかってるZabbixの画面ですね)上でのHostを指定します。送り先わかんないので。。。なので先にZabbix側でHostを作るのを忘れないようにしてくだしあ。
hostname = YOUR_ELB_NAME_ON_ZABBIX
# moduleはどのpluginを使うかの指定ですが、ここはelb固定です
module = elb
んでもって、この設定ファイルをblackbird本体のdefaults.cfgにしていたinclude_dir(blackbirdはNginxとかでいう/etc/blackbird/conf.d/*.conf的なことができます)の配下に置くか、defaults.cfgの下に追記しちゃってください。
では、Let's run your blackbird!
Case of Install by pip
blackbird --config YOUR_DEFAULT_CONFIG
Case of Install by yum
sudo service blackbird start
これでintervalに指定した時間が経過すれば値が入ってくる!はずです。