はじめに
今回は、MarkLogic社配布の並列分散ロードAPIContentPumpを使って、データロードと同時にちょっとしたデータ加工もできることを紹介します。
なお、ContentPumpについてある程度理解している前提でお話を進めますので、ご存知の無い方は公式ページなどを一読してからお願いします。
背景
ContentPumpは、MarkLogic Serverに対してXML / JSON / CSV / TSVなどのインポートやXML/JSONのエクスポート行うことができます。しかしXMLデータはAs-Isで取り込むと、いくつかの問題が起きます。
・日付型が不揃いだったり、数値型にカンマが入っていると、クエリ実行時に変換作業を噛ませなければいけなくなる。
・同じ意味なのに別々の要素名となっているとrange索引をそれぞれで設定しなければいけなくなる。
・インポートするドキュメント内に任意の付加情報を記述できない。
もちろん一旦MarkLogic Serverに取り込んで、これらをバッチ処理などで綺麗にするのも手ですが、その場合は以下の問題が起きます。
・一旦索引付けしたデータを再度加工して挿入する処理時間
・バッチ処理によって新たに挿入する分、DBサイズが肥大化する。
そこで今回はContentPumpによる挿入時点で加工を行うサンプルを示します。
加工内容
変換項目すべてをカバーするクエリを書くのは大変なので、今回はContentPumpを使ったCSV→MLDBという流れを前提に以下の項目のみを確かめることにしましょう。
| 対象項目 | 加工内容 |
|---|---|
| 日付型の変換 | 日付をyyyyMMddからyyyy-MM-ddに変換する |
| 数値型の変換 | 正整数内のカンマを削除する |
| 要素名の変換 | 要素名を別のモノに変更する |
| CSVファイル情報の付加 | CSVファイル名や行数を付加する |
| 外部変数の設定 | その他任意の情報を付加する |
実機検証環境・検証条件
☆検証環境
| Content Pumpのバージョン | MarkLogicのバージョン | OS | CPU | メモリ |
|---|---|---|---|---|
| 8.04 | 8.0-3.3 | Windows7 Professional |
Intel(R)Core(TM)i7-3740QM CPU2.70GHz 2.70GHz (4core8スレッド) |
16GB |
☆サンプルデータ
挿入データは以下のCSVです。必ず1行目に要素名があること、要素名がXML文法として許されること、要素列数と各行の列数(この場合は3)があっていることを確認しておきましょう。CSVファイルをC:\work\transformに置きます。
if001.csvの内容:
"SHOP_ID","SAMPLE_DATE","SALE_SUM"
"SHOP001","20170101","11,111"
"SHOP001","20170202","22,222"
"SHOP001","20170303","333"
"SHOP001","20170404","4,444,444"
"SHOP001","20170505","5,555,555"
"SHOP002","20170606","34,567"
"SHOP002","20170707","22,111"
"SHOP002","20170808","88,999"
"SHOP002","20170909","31,234"
"SHOP002","20171010","45,678"
このまま挿入するとこんな感じです。
<?xml version="1.0" encoding="UTF-8"?>
<root>
<SHOP_ID>SHOP002</SHOP_ID>
<SAMPLE_DATE>20171010</SAMPLE_DATE>
<SALE_SUM>45,678</SALE_SUM>
</root>
これに対して目指すべき挿入後データはこんな感じです。
<?xml version="1.0" encoding="UTF-8"?>
<ENVELOPE>
<METADATA>
<CSV_FILE_NAME>if0001.csv</CSV_FILE_NAME>
<SRC_LINE_NUM>10</SRC_LINE_NUM>
<INTERFACE_ID>IF0001</INTERFACE_ID>
</METADATA>
<CONTENT>
<SHOP_ID>SHOP002</SHOP_ID>
<SALE_DATE>2017-10-10</SALE_DATE>
<SALE_SUM>45678</SALE_SUM>
</CONTENT>
</ENVELOPE>
☆ContentPumpの実行バッチファイルのサンプル
コマンドプロンプトでmlcp.batがあるディレクトリに移動して、以下のコマンドを実行します。
mlcp.bat import -host localhost -input_file_path C:\work\transform -host localhost ^
-port 8062 -username admin -password admin ^
-output_uri_replace "/C:/work/transform, '/transformed'" ^
-transform_module /transform/transform_if0001.xqy ^
-transform_namespace "http://marklogic.com/example" ^
-transform_param "IF0001" -input_file_type delimited_text -delimiter "," ^
-generate_uri true -thread_count 16
今回、紹介する機能に関連するパラメータは以下の通りです。
| パラメータ | 説明 |
|---|---|
| transform_module | 変換内容を記述したXQueryのURI |
| transform_namespace | XQueryの名前空間 |
| transform_param | 外部変数設定。XQuery内ではmap:map型変数$contextに"transform_param"をキーとして格納されます。 |
☆変換クエリ
/transform/transform_if0001.xqyの中身を示します。CSVファイルに関する情報は挿入URI名に含まれるため文字列関数から取り出すことにしました。その他は、要素名をみてそれぞれのデータに変換を適用しています。
xquery version "1.0-ml";
(: モジュール名前空間 :)
module namespace example = "http://marklogic.com/example";
(: 変換関数 :)
declare function example:transform(
$content as map:map, (: 変換対象のドキュメント内容・URI :)
$context as map:map (: transform_paramで指定した外部パラメータ :)
) as map:map* {
(: 現在の挿入内容の取得 :)
let $the-doc := map:get($content, "value") (: 現在設定の挿入ドキュメント内容 :)
let $the-uri := map:get($content, "uri") (: 現在設定の挿入ドキュメントURI :)
(: 外部変数の取得 :)
let $ifId := map:get($context, "transform_param")
(: URIよりCSVファイルに関する情報(ファイル名と行数)を取り出す。 :)
let $temp-value := fn:tokenize($the-uri, "/")[fn:last()]
let $fileName-seq := fn:tokenize($temp-value, "-")
let $sourceFileName := $fileName-seq[fn:last() - 2]
let $sourceFileLine := $fileName-seq[fn:last()]
(: DBアクセスできるかの確認(ここは不要ですが、後述します) :)
let $a := fn:doc("/rule/if0001_cp.xml")
let $_ := xdmp:log(fn:concat("Let's Get ", $a/ROOT/SAMPLE/text()))
(: 戻り値の設定 :)
return
if (fn:empty($the-doc/element())) then ($content)
else (
(: 要素の中身を変換 :)
let $changedData-seq :=
for $ele in $the-doc/root/*
let $name := fn:name($ele)
let $data := $ele/text()
return
if($name = "SHOP_ID") then $ele
else if($name = "SAMPLE_DATE") then (
let $new_name := "SALE_DATE"
let $new_data := fn:concat(
fn:substring($data, 1, 4), "-",
fn:substring($data, 5, 2), "-",
fn:substring($data, 7, 2)
)
return element{$new_name}{$new_data}
)
else if($name = "SALE_SUM") then (
let $new_data := fn:replace($data, ",", "")
return element{$name}{$new_data}
)
else ()
(: 挿入内容の作成 :)
let $updated-content :=
element {"ENVELOPE"}{
element {"METADATA"} {
element {"CSV_FILE_NAME"}{$sourceFileName},
element {"SRC_LINE_NUM"}{$sourceFileLine},
element {"INTERFACE_ID"}{$ifId}
},
element {"CONTENT"}{$changedData-seq}
}
return (
map:put($content, "value", document {$updated-content}), $content
)
)
};
試験実施
では、実際にインポートしてみましょう。ContentPumpを実行して標準出力の中のINPUT_RECORDS、OUTPUT_RECORDS、OUTPUT_RECORDS_COMMITTEDが全て10、OUTPUT_RECORDS_FAILEDが0となっていることを確認します。
挿入後のファイルの確認はクエリコンソールで行いました。
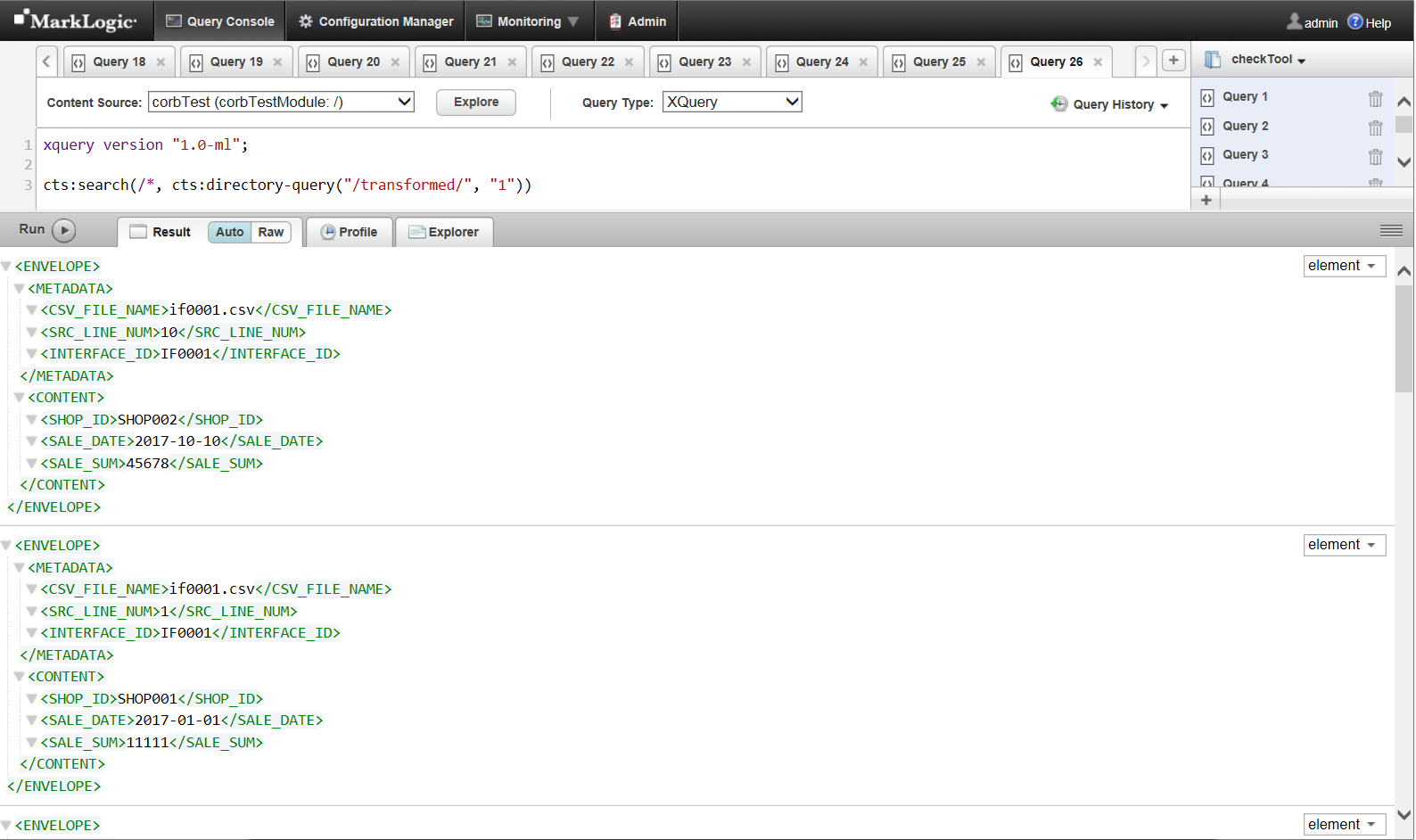
スクロールして10ファイル一通り確認しましたが問題なさそうです。
[補足]変換ルールをMarkLogic内に置くことは可能か?
今回の検証を行うにあたり変換内容をXQueryに直書きしましたが、変換ルールをMarkLogic内の別ファイルに置くことはできないかと考えました。XQuery中の以下の記述は/rule/if0001_cp.xmlのSAMPLE要素の内容"rule"を取り出してErrorLog.txtに出力するものです。
※ver9以降では、ErrorLog.txtではなく[APPサーバのポート番号]_ErrorLog.txtとなります。
(: DBアクセスできるかの確認(ここは不要ですが、後述します) :)
let $a := fn:doc("/rule/if0001_cp.xml")
let $_ := xdmp:log(fn:concat("Let's Get ", $a/ROOT/SAMPLE/text()))
ErrorLog.txtには実際に"rule"というテキストを取り出すことができました。
2018-02-13 16:09:51.268 Info: corbTest_XDBC: Let's Get rule
2018-02-13 16:09:51.268 Info: corbTest_XDBC: Let's Get rule
・・・
2018-02-13 16:09:51.330 Info: corbTest_XDBC: Let's Get rule
このことから、変換ルールファイルを作成して変換XQueryで参照させることは可能です。しかし個人的にはお勧めできません。というのも挿入するXMLファイルごとにfn:docのような参照関数を実行することになるからです。このため変換ルールをMarkLogicに格納するのならば、変換ルールへの参照はContentPump実行前に行い、その結果を外部変数としてContentPumpのパラメータtransform_paramで渡すことをお勧めします。
考察
ContentPumpは単にデータのインポートを行うだけでなく、XQueryの範囲で任意のデータ加工が行えることが分かりました。他にも以下のようなことに使えそうです。
・空の要素は、要素を設定しない。
・同一ファイル内での導出計算
他方で、こういった煩わしい加工を担ってくれる一般のデータ変換ツールを手放せるかというとそうではありません。例えば、
・ロードデータの文字コードや改行コードの変換や制御文字の排除
・XMLが整形式になっていない、CSVの項目数があっていない、CSVに項目行がない、場合などの補正
・CSV要素名がXML文法に違反している etc
と、いったことはContentPumpだけではどうしようもないようです。
一方で、XQuery内でDBに参照クエリを実行できることから、DB内に既に存在するデータとの結合検索が効率よくできそうな点は大きな特徴といえます。
おわりに
今回はContentPumpのインポート時における付加機能を説明したに過ぎません。今後は変換ルール設計案の考案やこの方法で出来ること出来ないことの整理、性能の劣化度合いの測定などを行っていこうと思います。
\def\textsmall#1{%
{\rm\scriptsize #1}
}
免責事項
$\textsmall{当ユーザ会は本文書及びその内容に関して、いかなる保証もするものではありません。}$
$\textsmall{万一、本文書の内容に誤りがあった場合でも当ユーザ会は一切責任を負いかねます。}$
$\textsmall{また、本文書に記載されている事項は予告なしに変更または削除されることがありますので、予めご了承ください。}$