はじめに
Aidemy Premiumにて「データ分析3ヶ月コース」を2021/09/27より受講しています。
自己紹介
新卒で5年ほど客先常駐のSEとして働いてましたが、以下のような理由から受講を決めました。
- AIの台頭や外国人労働者の増加などでいま私のしている仕事が10年後も続けられる保証はない。
- 今の自分のスキルセットで転職を希望しても結局似たようなSES企業にしか転職できないと思った。
- 以前からデータ分析分野に興味・関心があり、データ分析、機械学習、Pythonをしっかりと学びたいと思った。
環境
- OS: Windows10
- CPU : AMD Ryzen 5 5500U with Radeon Graphics 2.10 GHz
- メモリ: 8GB
- python環境:Jupyter Notebook
- Python ver : 3.8.11
ファイル構成
MyNotebook-
|-Predict_covid19.py(pythonファイル)
|-nhk_news_covid19_domestic_daily_data.csv
必要モジュール
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import itertools
import numpy as np
import datetime
import warnings
本記事の概要
- この記事に書くこと、わかること、扱わないこと
一般的なデータ分析では、以下の7つのステージで進めていきます。
1. 明らかにしたい問いや、問題の定義
2. 訓練およびテストデータの取得
3. データの整形、作成、クレンジング
4. パターンの分析、特定、また探索的にデータを分析する
5. 問題のモデル化、予測、解決
6. 問題解決のステップと最終的な解決方法を視覚化、報告
7. 結果の提出
本記事では1~5のワークフローに沿って進めていきたいと思います。
6,7は素人にできる範囲を超えているので割愛します。
作成したプログラム
1. 明らかにしたい問いや、問題の定義
新型コロナウイルスの第5波の猛威が噓のように過ぎ去り、現在は落ち着きを取り戻しています。
しかし、第6波はいつ来るのかまたどれほどの被害が想定されるのかを予測することは喫緊の課題となっております。
とはいえ、著名な学者が複雑なモデルを駆使しても当たらないほどなので、私のような素人の予測などあてになるはずがないことは最初にお断りしておきます。
また、感染者数ではなく死者数にした理由は感染者数だと検査数の多寡に左右されるため予測が困難だと判断したためです。
2. 訓練およびテストデータの取得
データは「情報:NHKまとめ」からCSVファイルを取得します。
本記事では2021/10/27時点の取得データとなっております。
3. データの整形、作成、クレンジング
まずは、CSVファイルの中身を見てみたいと思います。
pandasライブラリを使用して、CSVファイルなどのファイルを読み込むにはread_csv()関数を使用します。
読み込まれたファイルはpandasライブラリのDataFrame型のオブジェクトに変換されるので、
pandasの機能を使用して様々な加工を行うことが可能です。
# データの読み込み
df = pd.read_csv("./nhk_news_covid19_domestic_daily_data.csv")
print(df)
出力すると以下のような結果が得られます。
| 日付 | 国内の感染者数_1日ごとの発表数 | 国内の感染者数_累計 | 国内の死者数_1日ごとの発表数 | 国内の死者数_累計 | |
|---|---|---|---|---|---|
| 0 | 2020/1/16 | 1 | 1 | 0 | 0 |
| 1 | 2020/1/17 | 0 | 1 | 0 | 0 |
| 2 | 2020/1/18 | 0 | 1 | 0 | 0 |
| 3 | 2020/1/19 | 0 | 1 | 0 | 0 |
| 4 | 2020/1/20 | 0 | 1 | 0 | 0 |
| .. | ... | ... | ... | ... | ... |
| 645 | 2021/10/22 | 325 | 1716084 | 12 | 18186 |
| 646 | 2021/10/23 | 284 | 1716368 | 5 | 18191 |
| 647 | 2021/10/24 | 233 | 1716601 | 8 | 18199 |
| 648 | 2021/10/25 | 152 | 1716753 | 7 | 18206 |
| 649 | 2021/10/26 | 314 | 1717067 | 15 | 18221 |
| [650 rows x 5 columns] |
時系列データを分析する際は時間情報(上記の出力結果では日付のデータ)を
pandasのインデックス(上記の出力結果では一番左端にある0, 1, 2 ......の部分)にすることでデータを扱いやすくします。
この加工は、
1.index情報をpd.date_range("開始時", "終了時", freq="間隔")にまとめる
2.その情報をもとのデータのインデックスに代入する
3.もとのデータの"日付"を削除する
の手順で行います。
freqには、収集したい間隔の頭文字を渡します。
(Second➡S, Minute➡min, Hour➡H, Day➡D, Month➡M)
上記の出力結果から、2020/1/16~2021-10-26の期間を日にち間隔で収集したいため、
pd.date_range("2020-01-16", "2021-10-26", freq = "D")の様に引数を渡します。
また、今回は死者数の時系列分析をしたいため「国内の死者数_1日ごとの発表数」以外の列を削除します。
DataFrame型の変数がdfの場合、df.drop()にインデックスまたはカラムを指定すると該当する行または列を削除できます。
# 1.index情報をpd.date_range("開始時", "終了時", freq="間隔")にまとめる
index = pd.date_range("2020-01-16", "2021-10-26", freq = "D")
# 2.その情報をもとのデータのインデックスに代入する
df.index = index
# 3.もとのデータの"日付"を削除する
del df["日付"]
# 不必要な列を消す
df = df.drop(df.columns[0:2], axis=1)
df = df.drop(df.columns[-1], axis=1)
# 列のタイトルをつけなおす
df = df.rename(columns={'国内の死者数_1日ごとの発表数': 'Number_of_died_people_per_day'})
print(df)
出力すると以下のような結果が得られます。
| Number_of_died_people_per_day | |
|---|---|
| 2020-01-16 | 0 |
| 2020-01-17 | 0 |
| 2020-01-18 | 0 |
| 2020-01-19 | 0 |
| 2020-01-20 | 0 |
| ... | ... |
| 2021-10-22 | 12 |
| 2021-10-23 | 5 |
| 2021-10-24 | 8 |
| 2021-10-25 | 7 |
| 2021-10-26 | 15 |
| [650 rows x 1 columns] |
以上で、データの整形、作成、クレンジングは終了です。
今回は用いたデータが綺麗だったためソートも欠損値の補完も不要となります。
もし欠損値を算出する場合には、infoメソッドを利用します。
4. パターンの分析、特定、また探索的にデータを分析する
まずは、前項で整形したデータをプロットしてみます。
データ分析を行う上でデータを視覚化することはとても有効な手段の一つです。
ライブラリMatplotlib(マットプロットリブ)にはデータを視覚化するための機能が豊富に揃っています。
# データを折れ線グラフで表します
# グラフのサイズを指定
plt.figure(figsize=(16, 9))
# データのプロット
plt.plot(df)
plt.show()
出力すると以下のような結果が得られます。
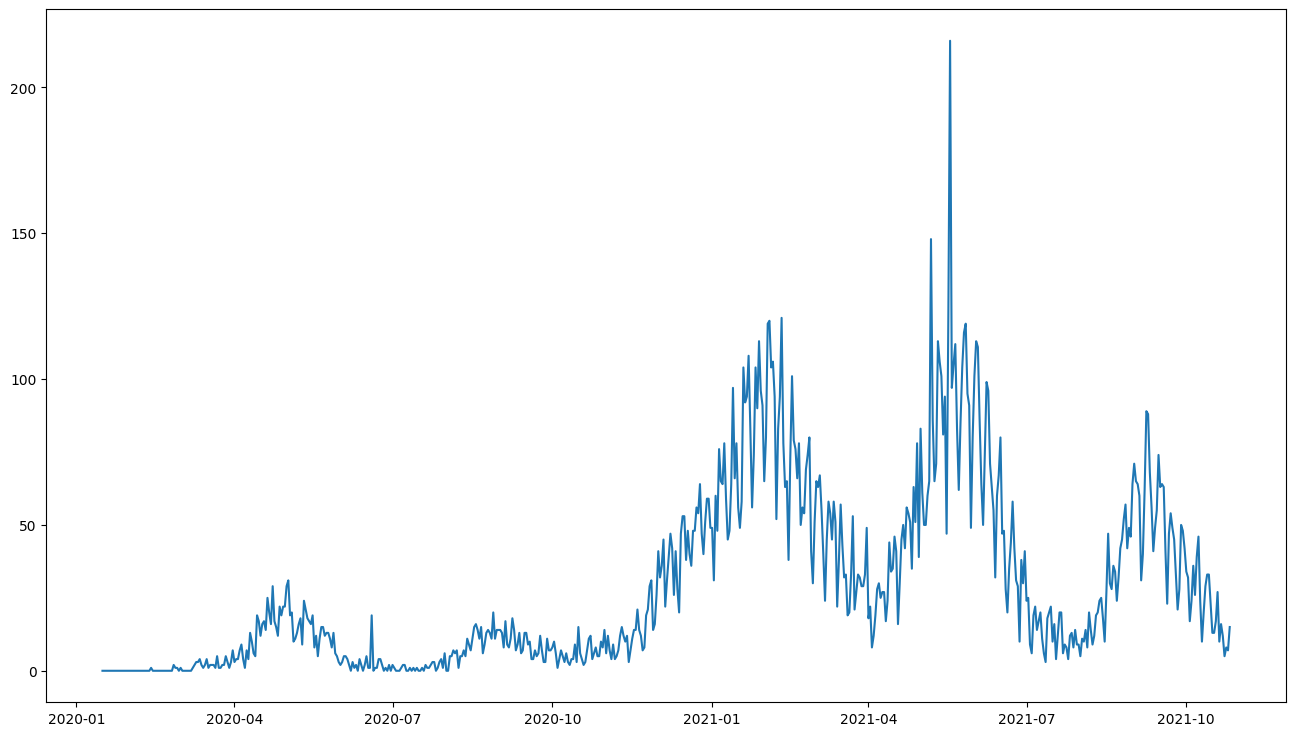
第5波での感染爆発の印象が強いですが死者数で見ると、第3波、第4波の方が被害が大きいことがわかります。
5. 問題のモデル化、予測、解決
今回使用するデータが時系列データなので、SARIMAモデルを使用して学習していきます。
SARIMAモデルとは、時系列分析の一手法です。複数の時系列モデルを複合した手法と考えることができます。
SARIMAモデルについて詳しく示してあるURLを以下に添付します。
SARIMAモデルを用いた時系列データの分析手順は以下の通りとなっています。
a. データの読み込み
b. データの整理
c. データの可視化
d. データの周期の把握 (パラメーターsの決定)
e. s以外のパラメーターの決定
f. モデルの構築
g. データとの予測とその可視化
a~cについては前項までで完了しています。
d. データの周期の把握 (パラメーターsの決定)
d. データの周期の把握 (パラメーターsの決定)についてですが、本来では偏自己相関係数を求め可視化して決定します。
しかし、本記事では新型コロナウイルスの周期は3、4か月と仮定してパラメーターsを決め打ちします。
e. s以外のパラメーターの決定
次に、e. s以外のパラメーターの決定を行います。
PythonにはSARIMAモデルのパラメーター、(p, d, q) (sp, sd, sq, s)を自動で最も適切にしてくれる機能はありません。
そのため 情報量規準 (今回の場合は [BIC(ベイズ情報量基準)] (https://www.google.com/search?q=%E3%83%99%E3%82%A4%E3%82%BA%E6%83%85%E5%A0%B1%E9%87%8F%E5%9F%BA%E6%BA%96%E3%81%A8%E3%81%AF&ei=ssZiYNezKs3R-Qag8bCIDA&oq=%E3%83%99%E3%82%A4%E3%82%BA%E6%83%85%E5%A0%B1%E9%87%8F%E5%9F%BA%E6%BA%96%E3%81%A8%E3%81%AF&gs_lcp=Cgdnd3Mtd2l6EAMyBggAEAcQHlC-Rli-RmDxSGgAcAB4AIABowGIAZkCkgEDMC4ymAEAoAECoAEBqgEHZ3dzLXdpesABAQ&sclient=gws-wiz&ved=0ahUKEwjX1JCjs9fvAhXNaN4KHaA4DMEQ4dUDCA0&uact=5))によってどの値が最も適切なのか調べるプログラムを書かなければなりません。
以下のコードで時系列データ:DATA, パラメータs(周期):sを入力すると、最も良いパラメーターとそのBICを出力します。
# 関数の定義
def selectparameter(DATA,s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs,results.bic)
except:
continue
return parameters[np.argmin(BICs)]
# 時系列データ:DATA, パラメータs(周期):sを入力
selectparameter(df,105)
以下の通り、最適な(p,d,q),(sp,sd,sq,s)が求められます。
[(1, 1, 1), (0, 1, 1, 105), 4374.967330320696]
f. モデルの構築
次に、f. モデルの構築を行います。
モデルの構築にはsm.tsa.statespace.SARIMAX(DATA,order=(p, d, q),seasonal_order=(sp, sd, sq, s)).fit()を用います。
# モデルの当てはめ
SARIMA_df = sm.tsa.statespace.SARIMAX(df,order=(1, 1, 1),seasonal_order=(0, 1, 1, 105)).fit()
print(SARIMA_df.summary())
結果は以下の通りです。
SARIMAX Results
===========================================================================================
Dep. Variable: Number_of_died_people_per_day No. Observations: 650
Model: SARIMAX(1, 1, 1)x(0, 1, 1, 105) Log Likelihood -2174.886
Date: Thu, 28 Oct 2021 AIC 4357.772
Time: 15:03:35 BIC 4374.967
Sample: 01-16-2020 HQIC 4364.495
- 10-26-2021
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.2063 0.041 5.089 0.000 0.127 0.286
ma.L1 -0.7817 0.034 -22.660 0.000 -0.849 -0.714
ma.S.L105 -0.6231 0.027 -23.202 0.000 -0.676 -0.571
sigma2 157.9994 3.744 42.199 0.000 150.661 165.338
===================================================================================
Ljung-Box (L1) (Q): 0.24 Jarque-Bera (JB): 3723.23
Prob(Q): 0.62 Prob(JB): 0.00
Heteroskedasticity (H): 17.88 Skew: 1.40
Prob(H) (two-sided): 0.00 Kurtosis: 15.51
===================================================================================
summaryの結果には、AICなどの情報量規準の一覧に加え、推定された係数も表示されています。
モデルとしてあまり良くない結果となりました。
一般的に、AIC、BICは値が小さいほうが良いモデルとされる傾向がありますが、とりあえずこのまま進めます。
g. データとの予測とその可視化
最終的に以下のコードで予測と実測値の可視化を行います。
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import datetime
# データの読み込みと整理
df = pd.read_csv("./nhk_news_covid19_domestic_daily_data.csv")
# インデックスデータの作成
index = pd.date_range("2020-01-16", "2021-10-26", freq = "D")
# インデックスデータの代入
df.index = index
# "日付"カラムの削除
del df["日付"]
# 不必要な列を消す
df = df.drop(df.columns[0:2], axis=1)
df = df.drop(df.columns[-1], axis=1)
# 列のタイトルをつけなおす
df = df.rename(columns={'国内の死者数_1日ごとの発表数': 'Number_of_died_people_per_day'})
# モデルの当てはめ
SARIMA_df = sm.tsa.statespace.SARIMAX(df,order=(1, 1, 1),seasonal_order=(0, 1, 1, 105)).fit()
# predに予測データを代入する
pred = SARIMA_df.predict("2021-1-1", "2022-1-31")
# データを折れ線グラフで表します
# グラフのサイズを指定
plt.figure(figsize=(16, 9))
# グラフのタイトルを設定
plt.title("Number_of_died_people_per_day")
# グラフのx軸とy軸の名前設定
plt.xlabel("date")
plt.ylabel("Number_of_died_people_per_day")
# x軸の表示範囲を[2020-01-01, 2022-01-31]に指定
sxmin='2020-01-01'
sxmax='2022-01-31'
xmin = datetime.datetime.strptime(sxmin, '%Y-%m-%d')
xmax = datetime.datetime.strptime(sxmax, '%Y-%m-%d')
plt.xlim([xmin,xmax])
# y軸の表示範囲を[0, 225]に指定
plt.ylim([0,225])
# グラフにグリッドを表示
plt.grid(True)
# データのプロット
plt.plot(df, color="b", label="actual")
plt.plot(pred, color="r", label="predict")
# 系列ラベルを表示
plt.legend()
plt.show()
出力すると以下のような結果が得られます。
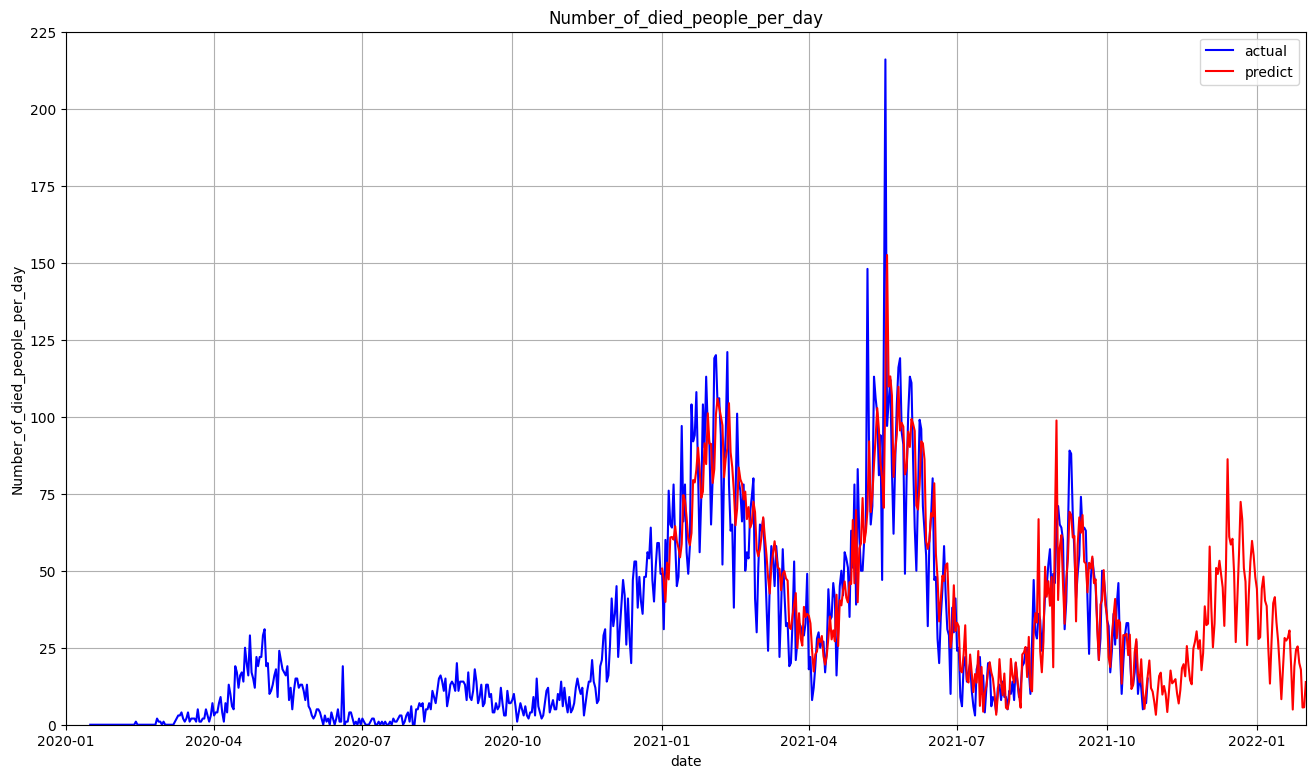
まとめ
作成したモデルで第3波、第4波、第5波の実数値と予測値がそれなりに沿っていることがわかります。
図を見ますと第6波は第3波、第4波よりは落ち着く予測となっています。
ワクチンの2回目接種率も上がっておりますので、この予測結果より低くなることを願っています。
考察・反省
今回はテストデータも整っており、最初から結論ありきでモデルも周期も決定してしまいました。
実際はこんなスムーズにいくことはないと思うので、これから機械学習エンジニアとしてレベルアップできるように、さらに精進していきたいと思います。
おわりに
まだ機械学習エンジニア転職するか出来るかは分かりませんが、
今後の活動については以下のようなことを考えています。
- 他のカリキュラムの受講
- 数学的知識の増強
- コンペに参加
- 受講後の継続的な学習