この記事は SoftBank AI部 Advent Calendar 2019 の1日目の記事です。トップバッター頑張ります👀
※ SoftBank AI部 Advent Calendar 2019 第二弾 も出ました!
スーパー内定者のコミさん!素敵な企画有難うございます。
はじめに
エレキギターの種類
エレキギターには結構いろんな種類があるんですが、ざっくりと「シングルコイル勢」「ハムバッカー勢」の2派閥に分けることができます。
シングルコイル・ハムバッカーというのは「ピックアップ」の種類のことです。
エレキギターの弦の振動を電気信号に変えるマイクのような装置で、具体的には


左のようなピックアップがシングルコイル
右のようなピックアップがハムバッカーです。
どこかで見たことがあるのではないでしょうか。
ピックアップによる音の違い
見た目の違いももちろんですがこれらを二大派閥とした理由として**「音の違い」があります。
よく言われる表現としては「シングルコイルはシャキッとして明るい」「ハムバッカーはウォームで滑らか」**みたいな感じでしょうか。
適切な例かは分かりませんが、Eric Claptonやギターの神様Jimi Hendrixのメインギターはシングルコイルで

B'zのTAK MATSUMOTOやVelvet Revolver(ex. Guns 'N Roses)のSlashのメインギターはハムバッカーです。

音の違いが気になる方は上記のギタリスト達の楽曲を是非聴き比べてみてください!
本記事ではこれらのギターのうち
シングルコイルギターの代表格「Storatocaster」とハムバッカーギターの代表格「Les Paul」を音によって分類するAIモデルを作ってみました!!
データの準備
録音
AIモデルを作るにあたりデータの準備はめちゃめちゃ重要です。
今回は以下のような環境でギター音声を録音しました。
・PC: MaxBook Pro (13-inch, 2017) / macOS 10.14 Mojave
・Interface: Steinberg UR22mkII
・DAW: Garageband / wav 44100Hz/24bitで出力
まずStratocaster、LesPaulそれぞれのギターで60秒分の2種類のフレーズ「backing」と「lead」を録音します。
backingは伴奏のフレーズで、leadはソロのフレーズというイメージです。
データの多様性を持たせるためbackingフレーズでは前半30秒はストロークの多い16ビート、後半30秒はゆったりとした8ビートを弾いています。
leadは好きだしいろんな弦のいろんなポジションを弾いているのでCreamの名曲「crossroads」を弾きました。
また、ピックアップ自体に出力の差分があるのでDAW入力時には音声のレンジを揃えるようにします。
弦のテンションも多少違うのでギターによってプレイスタイルが変わらないように注意します。

最初の10sずつだけですが音の違いを確認してみましょう。
(音声や動画の埋め込み方がわからずTwitterの埋め込みです)
ブログ用 pic.twitter.com/Rp10gXrsmM
— johannyjm (@johannyjm1) November 29, 2019
並べて聞いてみると随分違うように聞こえたのではないでしょうか。
なんのエフェクトもかけていない「生音」なので違いが分かりやすいのかもしれません。
モデルに学習させたい「ストラトっぽさ・レスポールっぽさ」もこういった音の特徴です。
エフェクト
録音した音声は何もエフェクトがかかっていない言わば「すっぴん」の状態です。
なので一般的にギターの生音に対して「エフェクト」がかけられることが多いです。
今回はそのエフェクトの中でも代表格である「歪み系」を3段階「clean」「crunch」「distort」と名付け、
それぞれの生音に重畳しました。(使ったエフェクターは・・忘れました)

以下はStratocaster・LesPaulそれぞれの「distorted」音源です
ブログ用2 pic.twitter.com/hszWmlkLX6
— johannyjm (@johannyjm1) November 29, 2019
歪み系って何?という方もいるかもしれませんが、いわゆるこういう音です。ロック系のギターの音って感じですね。
両者の違いが分かりにくくなってきたのではないでしょうか?
この工程は「一般に使われる音に近いものをデータにしたい」というモチベーションですが、Data Augmentationの思惑もあります(すぐ録れるのでそれぞれのエフェクトをかけて弾いてもよかったんですが。)
leadはちょっと、伴奏がなくて寂しいので勘弁してください😂
現時点で以下のwavデータが出来上がりました。
・ST_backing_raw.wav
・ST_backing_clean.wav
・ST_backing_crunch.wav
・ST_backing_distorted.wav
・ST_lead_raw.wav
・ST_lead_clean.wav
・ST_lead_crunch.wav
・ST_lead_distorted.wav
・LP_backing_raw.wav
・LP_backing_clean.wav
・LP_backing_crunch.wav
・LP_backing_distorted.wav
・LP_lead_raw.wav
・LP_lead_clean.wav
・LP_lead_crunch.wav
・LP_lead_distorted.wav
ギター2種類[Stratocaster/LesPaul] × 奏法2種類[backing/lead] × 音色4種類[raw/clean/crunch/distorted]
で16ファイルです。それぞれが60sのサイズです。
Google ColaboratoryでAIモデル作成
ここからはいよいよデータ分析→学習を行っていきます!
最近つよつよのGPUリソースが導入された庶民の味方でお馴染みのGoogle Colaboratoryを活用します。
ランタイムタイプをGPUに変えることを忘れずに!
データの読み込みと音声分析
データの読み込み
用意した16ファイルを一旦全てGoogle Storageにアップロードし、Colabから読めるようにします。
Colabで案外詰まってしまうのがこの工程です。
※余談ですがフォルダ名を30measuresとしているのはBPM=120で30小節録音すればちょうど60秒になるからです。
%mkdir ../data
%mkdir ../data/30measures
%pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
表示されるリンク先で認証キーを取得、テキスト欄に入力すると認証が完了します。
上記実行後、以下のようにするとColab上でStorage上のデータを読めるようになります。(もっといい方法はあるかもしれません)
dir_id = "ディレクトリid(データが保存されているGstorageのurl、folders/以下の文字列)"
file_list = drive.ListFile({'q': "'%s' in parents and trashed=false" % dir_id}).GetList()
for f in file_list:
file_id = f['id']
drive_file = drive.CreateFile({'id': file_id})
drive_file.GetContentFile(f['title'])
%mv *.wav ../data/30measures/
notebook上でwavファイルが見えていたら成功です。
%ls ../data/30measures/
LP_backing_clean.wav LP_lead_distorted.wav ST_lead_clean.wav
LP_backing_crunch.wav LP_lead_raw.wav ST_lead_crunch.wav
LP_backing_distorted.wav ST_backing_clean.wav ST_lead_distorted.wav
LP_backing_raw.wav ST_backing_crunch.wav ST_lead_raw.wav
LP_lead_clean.wav ST_backing_distorted.wav
LP_lead_crunch.wav ST_backing_raw.wav
ギター音声ファイルの読み込み
Pydubを用いてwavファイルを処理していきます。Pydubはデフォルトで入っていないためpip installします。
%pip install pydub
Collecting pydub
Downloading https://files.pythonhosted.org/packages/79/db/eaf620b73a1eec3c8c6f8f5b0b236a50f9da88ad57802154b7ba7664d0b8/pydub-0.23.1-py2.py3-none-any.whl
Installing collected packages: pydub
Successfully installed pydub-0.23.1
PydubのモジュールAudioSegmentを用います。
AudioSegmentのメソッドfrom_file()の引数にファイルのパスとファイル形式(今回はwav)を指定すると音声ファイルを読み込むことができます。(notebook内で埋め込み再生も可能です)
得られたAudioSegmentに.get_array_of_samples()メソッドを使うとarray.arrayという筆者があまり詳しくない型で音のデータが返ってくるので大人しくndarrayにします。
from pydub import AudioSegment
import matplotlib.pyplot as plt
import numpy as np
ST_backing_raw = AudioSegment.from_file('../data/30measures/ST_backing_raw.wav', 'wav')
LP_backing_raw = AudioSegment.from_file('../data/30measures/LP_backing_raw.wav', 'wav')
ST_backing_raw_sample = np.array(ST_backing_raw.get_array_of_samples())
LP_backing_raw_sample = np.array(LP_backing_raw.get_array_of_samples())
plt.plot(ST_backing_raw_sample)
plt.show()
plt.plot(LP_backing_raw_sample)
plt.show()
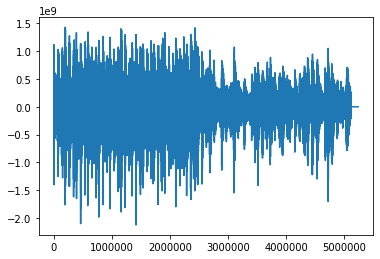
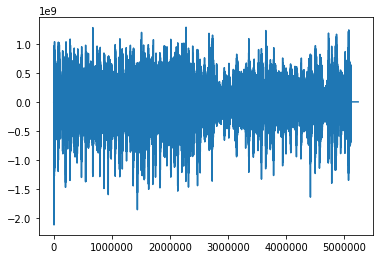
無事音声を読み込むことができました!上がストラト・下がレスポールです。
半分くらいで波の振幅が小さくなってるのは後半をゆったりと弾いているからです。
もちろん波の形から両者の区別はできません。
スペクトログラムを作ってみる
波形では分かりませんでしたが周波数もみてみるとどうでしょうか。
拾いものですが以下のようにハミング窓+FFTでスペクトログラムを作成します。
sampling_rate = 44100
NFFT = 1024
OVERLAP = NFFT / 2
frame_length = LP_backing_raw_sample.shape[0]
split_number = len(np.arange((NFFT / 2), frame_length, (NFFT - OVERLAP)))
window = np.hamming(NFFT)
for data in [ST_backing_raw_sample, LP_backing_raw_sample]:
spec = np.zeros([split_number, NFFT // 4])
pos = 0
for fft_index in range(split_number):
frame = data[int(pos): int(pos + NFFT)]
if len(frame) == NFFT:
windowed = window * frame
fft_result = np.fft.rfft(windowed)
fft_data2 = np.real(fft_result[: int(len(fft_result) / 2)])
fft_data2 = np.log(fft_data2 ** 2)
for i in range(len(spec[fft_index])):
spec[fft_index][-i - 1] = fft_data2[i]
pos += (NFFT - OVERLAP)
plt.imshow(spec.T, extent=[0, frame_length, 0, sampling_rate / 2], aspect="auto")
plt.show()
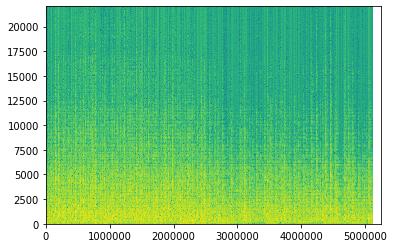
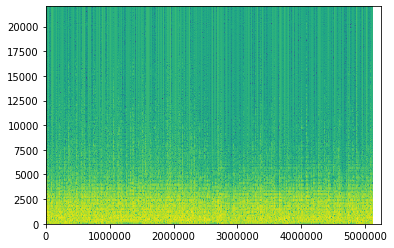
上がストラト、下がレスポールです。
横軸が時間(サンプル数)縦軸が周波数、色が明るければ明るいほど「その時間においてその周波数成分を多く含む」というイメージです。
ストラトの方が5000Hzより高い成分も多く「シャキッとした明るい音」と説明した通りですね、
一方レスポールの方は音の成分が5000Hz以下に集中し、「まるい滑らかな音」つまり「尖った音じゃない=高周波成分が弱い」という特徴が表現されているのではないでしょうか。
モデルの紹介
今回の音声分類にあたっていろんなモデルを試してみたのですが、最も精度が高くなったのは2017年に出た以下の論文で提案されている「LSTM FCN」だったのでこちらを少し紹介します。
LSTM Fully Convolutional Networks for Time Series Classification

この論文では上のような比較的シンプルなモデルで有名な時系列データセット128種類の学習をし、相互のfine-tuningをおこなった結果43のタスクにおいては最高の性能が出たという内容になっています。
論文ではLSTMの隠れ層セル数を8→64→128と変えていきそれぞれのモデルで予測しています今回はセル数8のみで実装します。
Attention LSTMは実装が大変だったので今回は使いません。
・・実を言うとこのモデルを選んだのには他に理由があって、kerasで実装してくれているからです・・本当に有難うございます。
Codebase for the paper LSTM Fully Convolutional Networks for Time Series Classification
データセットの作成
シーケンス長の設計
今回はデータを時系列として入力します。
60sの音声データを決まったシーケンス長に分割して訓練データを作成します。
このシーケンス長ですが録音はモノラルで行ったので入力データのshapeは(<シーケンス長>, 1)と入力することにすれば、
データ数 = 全てのデータ / シーケンス長 となるため、結構重要なポイントです。
イメージとしては
訓練データのシーケンス長を長くすれば「一つ一つのデータの特徴は増えるが、データ数が少なくなる」
訓練データのシーケンス長を短くすれば「データ数は多くなるが、一つ一つのデータの特徴は減る。」
という感じです。
具体的には、
シーケンス長1000→データ数83881
シーケンス長2500→データ数33552
シーケンス長8000→データ数10485
になります。
今回はシーケンス長:8000samplesを選択しました。
理由としては色々試して精度が良かったと言うのももちろんありますが、1000サンプル≒22.7msだけ聴いて分かってたまるか!と言う感情的要因もあります。
最低限1万データは確保したいのでシーケンス長:8000samplesに落ち着きました。
※あともう一つ、筆者が途中までサンプリングレートを48kHzと勘違いしていたため8000ええやん、となったからというのもあります。
テストデータについて
リークを防ぐため一番最初に事前に決めたランダムな時間から2s分の不可侵なデータを16ファイルそれぞれに作っておきます。
開始時間をファイル間で共有する理由は、同じ音声に別のエフェクトをかけて別ファイルとしているので、そこから発生しうるリーク対策です。
最終的にこの2sをモデルに聴かせてStratocaster/LesPaulを予測→最終的なモデルの精度を評価します!
 ※図では48kHzの計算になってしまっているため実際は2s、1/6sより少し長いです。
※図では48kHzの計算になってしまっているため実際は2s、1/6sより少し長いです。
データセット作成のコードは以下です。
とても単純で8000サンプルごとにdataとラベルをappendしていき、test対象の部分だけpassします。
これを16ファイル分繰り返すだけです。
import pathlib
import random
SEQUENCE_LENGTH = 8000
file_names = []
d_wave = []
d_wave_class = []
TEST_LENGTH = 96000 # 48000: 1s, 96000: 2s
frag_num = TEST_LENGTH // SEQUENCE_LENGTH
test_wave = []
test_class = []
ridx = random.randint(0, ST_backing_raw_sample.shape[0] // SEQUENCE_LENGTH - frag_num)
for f_name in pathlib.Path('../data/30measures/').iterdir():
print(str(f_name.name.split('/')[-1]) + ' ... now processing')
file_names.append(f_name.name.split('/')[-1])
wave_data = np.array(AudioSegment.from_file('../data/30measures/' + f_name.name, 'wav').get_array_of_samples())
# wave_data = wave_data / wave_data.max() # normalizarion
d_mean = wave_data.mean()
d_std = wave_data.std()
wave_data = (wave_data - d_mean) / d_std # standardization
g_class = int('LP_' in f_name.name) # 0: Stratocaster, 1: Les Paul
for j in range(wave_data.shape[0] // SEQUENCE_LENGTH):
if(j in range(ridx, ridx + frag_num)): # TEST data generate
if(j in range(ridx + 1, ridx + frag_num)): pass
else:
test_wave.append(wave_data[j*SEQUENCE_LENGTH: j*SEQUENCE_LENGTH + TEST_LENGTH])
test_class.append(g_class)
else: # TRAIN data generate
d_wave.append(wave_data[j*SEQUENCE_LENGTH: j*SEQUENCE_LENGTH + SEQUENCE_LENGTH])
d_wave_class.append(g_class)
d_wave = np.array(d_wave)
d_wave_class = np.array(d_wave_class)
test_wave = np.array(test_wave)
test_class = np.array(test_class)
d_wave.shape, d_wave_class.shape, test_wave.shape, test_class.shape
ST_backing_raw.wav ... now processing
LP_backing_distorted.wav ... now processing
LP_backing_crunch.wav ... now processing
ST_lead_distorted.wav ... now processing
ST_lead_clean.wav ... now processing
ST_backing_distorted.wav ... now processing
ST_backing_clean.wav ... now processing
ST_backing_crunch.wav ... now processing
LP_lead_distorted.wav ... now processing
LP_backing_clean.wav ... now processing
LP_lead_clean.wav ... now processing
LP_lead_crunch.wav ... now processing
LP_lead_raw.wav ... now processing
ST_lead_raw.wav ... now processing
LP_backing_raw.wav ... now processing
ST_lead_crunch.wav ... now processing
((10288, 8000), (10288,), (16, 96000), (16,))
LSTM FCNでデータを学習
データセットも無事にできあがったのでモデルに学習させていきましょう!
シードの固定
GPU、Kerasを使うのでseed固定できない説ありますが惰性で固定します。
import os
import random
def seed_everything(seed=1234):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
seed_everything()
各ツールのインポートとvalidation split
論文では無印LSTMでの実装でしたが、GPUで爆速のCuDNNLSTMを使いましょう。
本当は交差検証すべきなんでしょうがひとまずホールドアウトで行います。
from keras import backend as K
from keras.layers import Conv1D, BatchNormalization, GlobalAveragePooling1D, Permute, Dropout
from keras.layers import Input, Dense, CuDNNLSTM, concatenate, Activation
from keras.optimizers import Adam
from keras.models import Model
from sklearn.model_selection import train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(d_wave, d_wave_class, test_size = 0.2, random_state = 42)
x_train = x_train.reshape(-1, SEQUENCE_LENGTH, 1)
x_valid = x_valid.reshape(-1, SEQUENCE_LENGTH, 1)
Model Generate
Codebase for the paper LSTM Fully Convolutional Networks for Time Series Classification の実装では他のデータセットに対応するためNB_CLASSを引数として持っており、出力層はSoftmaxでしたが、今回はStratocaster/LesPaulの2者分類なので出力層はDense(1, activation='sigmoid')としています。
def generate_lstmfcn(SEQUENCE_LENGTH, NUM_CELLS=8):
ip = Input(shape=(SEQUENCE_LENGTH, 1))
x = CuDNNLSTM(NUM_CELLS)(ip)
x = Dropout(0.8)(x)
y = Permute((2, 1))(ip)
y = Conv1D(128, 8, padding='same', kernel_initializer='he_uniform')(y)
y = BatchNormalization()(y)
y = Activation('relu')(y)
y = Conv1D(256, 5, padding='same', kernel_initializer='he_uniform')(y)
y = BatchNormalization()(y)
y = Activation('relu')(y)
y = Conv1D(128, 3, padding='same', kernel_initializer='he_uniform')(y)
y = BatchNormalization()(y)
y = Activation('relu')(y)
y = GlobalAveragePooling1D()(y)
x = concatenate([x, y])
out = Dense(1, activation='sigmoid')(x)
model = Model(ip, out)
return model
学習!
上述通り論文では8→64→128とLSTMcellの値を変えていき、それぞれの予測を行なっていますが今回はcell=8のみで学習しました。
またAdam()はcallbackで学習率減衰すれば良かったのですが、バグった思い出しかないのでこちらの方法で・・
学習の進み具合に応じてさらに学習率を減衰させた学習を追加します。
K.clear_session() # release GPU Memory
model = generate_lstmfcn(SEQUENCE_LENGTH)
model.compile(Adam(lr = 0.001), loss = 'binary_crossentropy', metrics = ['accuracy'])
history = model.fit(x_train, y_train, batch_size = 32, epochs = 10, verbose = 1, validation_data = (x_valid, y_valid))
model.compile(Adam(lr = 0.0001), loss = 'binary_crossentropy', metrics = ['accuracy'])
history = model.fit(x_train, y_train, batch_size = 32, epochs = 5, verbose = 1, validation_data = (x_valid, y_valid))
Epoch 5/5 8230/8230 [==============================] - 65s 8ms/step - loss: 0.0634 - acc: 0.9719 - val_loss: 0.6223 - val_acc: 0.8192
1epochに大体1分強かかるので、15epochだと20分弱かかります。
最終的にval_accが0.8あたりまで行きます。
モデルの評価
評価は以下のように行います。
・Test data 96000samples を 8000samples × 12 に分割します
・それぞれをモデルに入力し、12の予測値を得ます(出力がsigmoidなので0~1の確信度と捉えます)
・その予測値の平均値が0.5より大きければLesPaul、以下であればStratocasterをモデルの最終予測とします。
・16ファイルに対して上記の操作を行い、その正解率を最終的なモデルの精度とします。
以下のように実装しました。キレイな実装ではないですが・・
iscorrect = []
for i in range(16):
preds = 0
print('\n' + file_names[i])
print('label: ' + ['Stratocaster', 'LesPaul'][test_class[i]]) # Stratocaster: 0, Les Paul: 1
for j in range(12): # prediction for 12 fragments
pred = model.predict(test_wave[i][j * SEQUENCE_LENGTH: j * SEQUENCE_LENGTH + SEQUENCE_LENGTH].reshape(1, SEQUENCE_LENGTH, 1))[0][0]
preds += pred
print('pred: ' + ['Stratocaster-> ', 'LesPaul-> '][int(preds / 12 > 0.5)] + str(preds / 12))
iscorrect.append(test_class[i] == int(preds / 12 > 0.5))
print('\naccuracy: ' + str(sum(iscorrect) / 16))
ST_backing_raw.wav
label: Stratocaster
pred: Stratocaster-> 0.384837884271595
LP_backing_distorted.wav
label: LesPaul
pred: LesPaul-> 0.8223973872760931
LP_backing_crunch.wav
label: LesPaul
pred: LesPaul-> 0.8515597583415607
ST_lead_distorted.wav
label: Stratocaster
pred: Stratocaster-> 0.33414264490905526
ST_lead_clean.wav
label: Stratocaster
pred: Stratocaster-> 0.06880748727058857
ST_backing_distorted.wav
label: Stratocaster
pred: Stratocaster-> 0.07151546456528497
ST_backing_clean.wav
label: Stratocaster
pred: Stratocaster-> 0.15246008742496997
ST_backing_crunch.wav
label: Stratocaster
pred: Stratocaster-> 0.046076005835099444
LP_lead_distorted.wav
label: LesPaul
pred: LesPaul-> 0.5751855125029882
LP_backing_clean.wav
label: LesPaul
pred: LesPaul-> 0.9819872577985128
LP_lead_clean.wav
label: LesPaul
pred: LesPaul-> 0.6855922320391983
LP_lead_crunch.wav
label: LesPaul
pred: Stratocaster-> 0.2915394731486837
LP_lead_raw.wav
label: LesPaul
pred: LesPaul-> 0.6964348847977817
ST_lead_raw.wav
label: Stratocaster
pred: Stratocaster-> 0.4482770240865648
LP_backing_raw.wav
label: LesPaul
pred: LesPaul-> 0.8605776695961443
ST_lead_crunch.wav
label: Stratocaster
pred: Stratocaster-> 0.33251506977831014
accuracy: 0.9375
意外とDistortedの分類も成功していて嬉しいです。
15/16正解で精度93.75%!が最終的な精度になります。
おわりに
長文になってしまいましたが最後まで読んで頂き有難うございました。
コードも汚く、ロジックがイケてない部分や改善点も多々あるかと思いますのでご指摘頂けると嬉しいです!!
今後検証したい事リスト
・実は初期モデルとして「スペクトログラムを画像認識」という手法を使っていました。上述の通り視覚的にも両者の判別が可能だと考えたため、そして音声分析法としてスペクトログラムの画像認識はわりと使われている手法っぽかったからです。結果としては上手く学習が進まず今回のモデルにピボットしました。→上手くいかない理由の解明はやる事リストであり、上手くいったら今回のモデルとアンサンブルしたいです。
・そもそも1分ずつ4回弾いただけ、というのが今回のデータの全てなので「データはもっと要る」と思いました。普通に10分ずつくらい弾けばもっと精度上がりそう👀同時に音の多様性も失われていくので「別のエフェクターを使う→ディレイやコンプレッサーなど」「別のギターを使う」「別のDAWソフトを使う」「別の人に弾いてもらう」といった方法を試したいです。
・さらに発展形として「楽曲からギターパートを抽出し、訓練データとする」「ラベルを細分化し、細かいギターの種類も推定できるようにする」など、いつか挑戦してみたいです!