みなさん情報処理技術者試験の勉強進んでいますか?今回はテクノロジ系の結構大事な部分や初学者には大変な分野であるデータベースについて紹介します.データベースは多くの開発や実務においても必ず使う技術なので資格のみでの勉強ではなく完全に会得できるといいですね!
シリーズ 情報処理技術者試験合格への道
他のシリーズ記事
TypeScriptで学ぶプログラミングの世界
プログラミング言語を根本的に理解するシリーズです.
〇〇チートシート
様々な言語,フレームワーク,ライブラリなど開発技術の使用方法,基本事項,応用事例を網羅し,手引書として記載したシリーズです.
git/gh,lazygit,docker,vim,go/gorm,typescript,SQL,プルリクエスト/マークダウン,ステータスコード,ファイル操作のチートシートがあります.以下の記事に遷移した後,各種チートシートのリンクがあります.
IAM AWS User クラウドサービスをフル活用しよう!
AWSのサービスを例にしてバックエンドとインフラ開発の手法を説明するシリーズです.
Project Gopher: Unlocking Go’s Secrets
Go言語や標準ライブラリの深掘り調査レポートです.
データベースの基本と活用例
データベースは、「データ」と「ベース」という二つの単語の合成語である。データとは単なる記号列のことで、観察や調査などの結果得られるものを指す。一方、ベースは基盤や基地を意味する。これらを組み合わせたデータベースは、データを保管・提供する基地として機能する。
データベースとは?

データベースはデータの集合そのものを指す.
データの登録(Create),参照(Read),修正(Update),削除(Delete)といったCRUD操作と呼ばれる処理をするにはデータベースソフトウェアあるいは データベース管理システムDBMS(DataBase Management System) というものを使用する.
データベースの利用例
-
銀行
ATMでの現金出入金や残高照会などで活用されており、矛盾のない口座管理が可能である。 -
コンビニ
売上データを蓄積し、売れ筋商品の分析や仕入れ予測に役立てている。 -
インターネット
SNSやオンラインショッピングなどで、データベースを活用した情報の蓄積や利用者への商品推薦が行われている。
データベースと表計算ソフトの違い

表計算ソフト(例:Microsoft Excel)は、一人利用を想定した事務計算用のツールであり、データの最大レコード数や共有機能に制限がある。一方、データベースは複数の利用者による同時操作を想定し、大量のデータを管理できる。また、データベースは矛盾が生じないように適切な管理を行う仕組みを持つ。
プログラム開発の違い
表計算ソフトではマクロやVisual Basicを使用して操作を自動化できるが、汎用性が低い。一方、データベースでは専用の言語(例:SQL)を用いるため、他のデータベースにも適用可能で汎用性が高い。
データ構造の管理
データベースでは、列の名前やデータ型(例:整数、文字列、日付)を指定し、構造化されたデータを保存する。これにより、「特定の条件に一致するデータ」を即座に取得できる。
データベースとWebページの違い

Webページとデータベースはどちらも膨大な情報を蓄積し管理するが、データベースは構造化されており、管理者が存在する点が異なる。将来的にはセマンティックWebにより、Webページもデータベースのような操作が可能になると期待されている。
MySQLとデータベース、テーブルの違いについて
MySQLとは

MySQLはオープンソースのリレーショナルデータベース管理システム(RDBMS)である.
データベースを作成・管理し、テーブルにデータを格納したり、データを検索・操作するための環境を提供する.
MySQL自体は「データベースを扱うためのソフトウェア」であり、複数のデータベースを管理できる.
データベースとテーブルの違い
| 項目 | データベース | テーブル |
|---|---|---|
| 役割 | データを管理するための大枠(入れ物) | 実際にデータを格納するための具体的な構造 |
| 作成方法 |
CREATE DATABASE を使用 |
CREATE TABLE を使用 |
| 格納するもの | テーブル | 行データ(レコード) |
| 用途 | データのカテゴリ分けや、アプリケーションごとのデータ分離に使用 | 特定のデータセットを保存・操作するために使用 |
| 関連性 | テーブルを格納するコンテナとして機能 | データベース内に存在し、データを操作する際の主要な対象 |

データベースの役割
データベースの概要
- データベースは、データを構造的に保存するための「入れ物」である.
- 1つのMySQLインスタンス内で複数のデータベースを作成できる.
- データベースには、複数のテーブルを格納できる.
主な役割
- 異なる種類のデータを分けて管理するための単位を提供する.
- 例: ユーザー情報を管理するデータベース「UserDB」と、商品情報を管理するデータベース「ProductDB」を別々に作成する.
- データベース間でデータが混ざらないようにする.
CREATE DATABASE ExampleDB;
USE ExampleDB;
上記の例では、新しいデータベース「ExampleDB」を作成し、以降の操作対象をこのデータベースに設定している.
テーブルの役割
テーブルの概要
- テーブルは、データベース内にデータを格納する「具体的な構造」である.
- 1つのデータベース内には複数のテーブルを作成できる.
- テーブルは列(カラム)と行(レコード)で構成される.
主な役割
- 実際にデータを保存する単位を提供する.
- 例: 「顧客情報」を格納するテーブル「customers」と「注文情報」を格納するテーブル「orders」を作成する.
- テーブルの構造(列名やデータ型)を定義し、それに基づいてデータを格納する.
CREATE TABLE books (
book_id INT,
title CHAR(20),
author CHAR(40),
publication_year INT
);
上記の例では、データベース内に「books」というテーブルを作成している. このテーブルは書籍情報を格納する構造を定義している.
MySQLにおけるデータ型一覧
MySQLでは、テーブルを定義する際に、各列(カラム)に保存するデータの種類を指定する.
データ型には以下のように大きく分けて「数値型」「文字列型」「日付と時刻型」がある.
数値型
数値を格納するためのデータ型で、整数型と小数型に分かれる.
整数型
| データ型 | 説明 | 格納可能な範囲(符号付き) | ストレージサイズ |
|---|---|---|---|
| TINYINT | 非常に小さな整数 | -128 ~ 127 | 1バイト |
| SMALLINT | 小さな整数 | -32,768 ~ 32,767 | 2バイト |
| MEDIUMINT | 中程度の整数 | -8,388,608 ~ 8,388,607 | 3バイト |
| INT | 標準的な整数 | -2,147,483,648 ~ 2,147,483,647 | 4バイト |
| BIGINT | 大きな整数 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | 8バイト |
小数型(実数型)
| データ型 | 説明 | 格納可能な値の範囲(例) | ストレージサイズ |
|---|---|---|---|
| FLOAT | 小数を含む数値 | -3.402823466E+38 ~ 3.402823466E+38 | 4バイト |
| DOUBLE | 高精度の小数 | -1.7976931348623157E+308 ~ 1.7976931348623157E+308 | 8バイト |
| DECIMAL | 固定小数点数(精度を指定可能) | ユーザー指定の精度とスケールに基づく | 可変(定義により異なる) |
文字列型
文字列データやバイナリデータを格納するデータ型.
固定長文字列型
| データ型 | 説明 | 最大長 | ストレージサイズ |
|---|---|---|---|
| CHAR | 固定長文字列(不足分はスペースで埋められる) | 0 ~ 255文字 | 定義した長さ |
可変長文字列型
| データ型 | 説明 | 最大長 | ストレージサイズ |
|---|---|---|---|
| VARCHAR | 可変長文字列(文字数に応じたサイズ) | 0 ~ 65,535文字 | 実際の文字数 + 1バイト |
テキスト型
| データ型 | 説明 | 最大長 | ストレージサイズ |
|---|---|---|---|
| TINYTEXT | 非常に短いテキスト | 255文字 | 実際の文字数 + 1バイト |
| TEXT | 短いテキスト | 65,535文字 | 実際の文字数 + 2バイト |
| MEDIUMTEXT | 中程度の長さのテキスト | 16,777,215文字 | 実際の文字数 + 3バイト |
| LONGTEXT | 非常に長いテキスト | 4,294,967,295文字 | 実際の文字数 + 4バイト |
バイナリデータ型
| データ型 | 説明 | 最大長 |
|---|---|---|
| BINARY | 固定長バイナリデータ | 0 ~ 255バイト |
| VARBINARY | 可変長バイナリデータ | 0 ~ 65,535バイト |
| BLOB | バイナリデータ用の型 | 0 ~ 65,535バイト |
日付と時刻型
日付や時刻を格納するためのデータ型.
| データ型 | 説明 | 格納例 | ストレージサイズ |
|---|---|---|---|
| DATE | 年月日(YYYY-MM-DD)を格納 | 2025-01-08 |
3バイト |
| DATETIME | 年月日と時刻(YYYY-MM-DD HH:MM:SS)を格納 | 2025-01-08 14:30:00 |
8バイト |
| TIMESTAMP | タイムスタンプ(1970年1月1日からの秒数で内部的に保存) | 2025-01-08 14:30:00 |
4バイト |
| TIME | 時刻(HH:MM:SS)を格納 | 14:30:00 |
3バイト |
| YEAR | 年(YYYY)を格納 | 2025 |
1バイト |
その他のデータ型
| データ型 | 説明 |
|---|---|
| ENUM | 設定可能な値を指定し、その中から1つを選択可能 |
| SET | 設定可能な値を指定し、その中から複数を選択可能 |
MySQLのセットアップ方法
MySQLを利用すれば、多様なデータ操作が可能である. データベースの基本操作を理解し、実践に活かしてほしい.
WindowsでのMySQLセットアップ
- MySQL公式サイトからWindows用のインストーラをダウンロードする.
URL: https://dev.mysql.com/downloads/ - ダウンロードしたインストーラを実行し、セットアップウィザードに従う.
- 必要なコンポーネントを選択し、MySQL Serverをインストールする.
- 設定画面で、ルートユーザーのパスワードを設定する.
- セットアップ完了後、MySQL Workbenchまたはコマンドラインツールで接続を確認する.
macOSでのMySQLセットアップ
- Homebrewを使用してMySQLをインストールする.
ターミナルで以下のコマンドを実行する:brew install mysql - インストールが完了したら、MySQLサービスを開始する.
-
brew services start mysql - 初回ログイン時のパスワードを確認し、以下のコマンドでログインする:
mysql -u root -p - 必要に応じて、ルートユーザーのパスワードを変更する.
SQLとは?
SQLは、データベースを操作するための言語であり、その機能や特徴を理解することで効率的にデータベースを扱うことができる. 以下では、SQLの基本的な概念や用語について説明する.
SQLとは?
SQLはStructured Query Languageの略であり、日本語では「構造化問合せ言語」と呼ばれる.
データベースへの問合せを簡単に記述できるだけでなく、データベースの作成、データの登録・削除・更新など、さまざまな操作の機能を提供する.
- 「表」形式という単純で理解しやすい関係データモデルを基本としている.
- 厳密に形式化されているため曖昧さがなく正確に処理できる.
- 英語的に表現されるため、問合せ内容を容易に理解できる.
SQLの使用形態
対話的DB操作
利用者が直接データベースを操作する方法であり、開発者やDB管理者が利用する.
静的SQL
アプリケーションプログラム内に直接SQL文を記述する形態である.
動的SQL
プログラム内で実行時にSQL文を生成し実行する形態であり、柔軟性が高い.
SQLの基本形式
-
SQLの文は、文の機能を示すキーワードが先頭に記述される
例:CREATE, INSERT, SELECTなど. -
キーワードは大文字と小文字を区別しない
例:SELECT * FROM student;はselect * from student;と同じ意味である. -
文の最後にはセミコロン(;)を付ける
文の中で改行しても問題はないが、セミコロンが必要である.
主な用語
表(テーブル)
データはすべて表形式で格納され、行と列で構成される.
列(属性)
表を構成する要素で、各行に共通する項目を定義する.
例:「氏名」「性別」など.
行(タプル)
表の各データを格納する部分で、1行が1件のデータに対応する.

主キー
各行を一意に特定するための列または列の組み合わせである.

スキーマ
データベースの構造を定義するもので、列の属性やデータ型を含む.
スキーマは以下のような三層の構造で成り立つ

わかりにくいと思うので店舗管理システムの例でスキーマを考えるとこうなる.

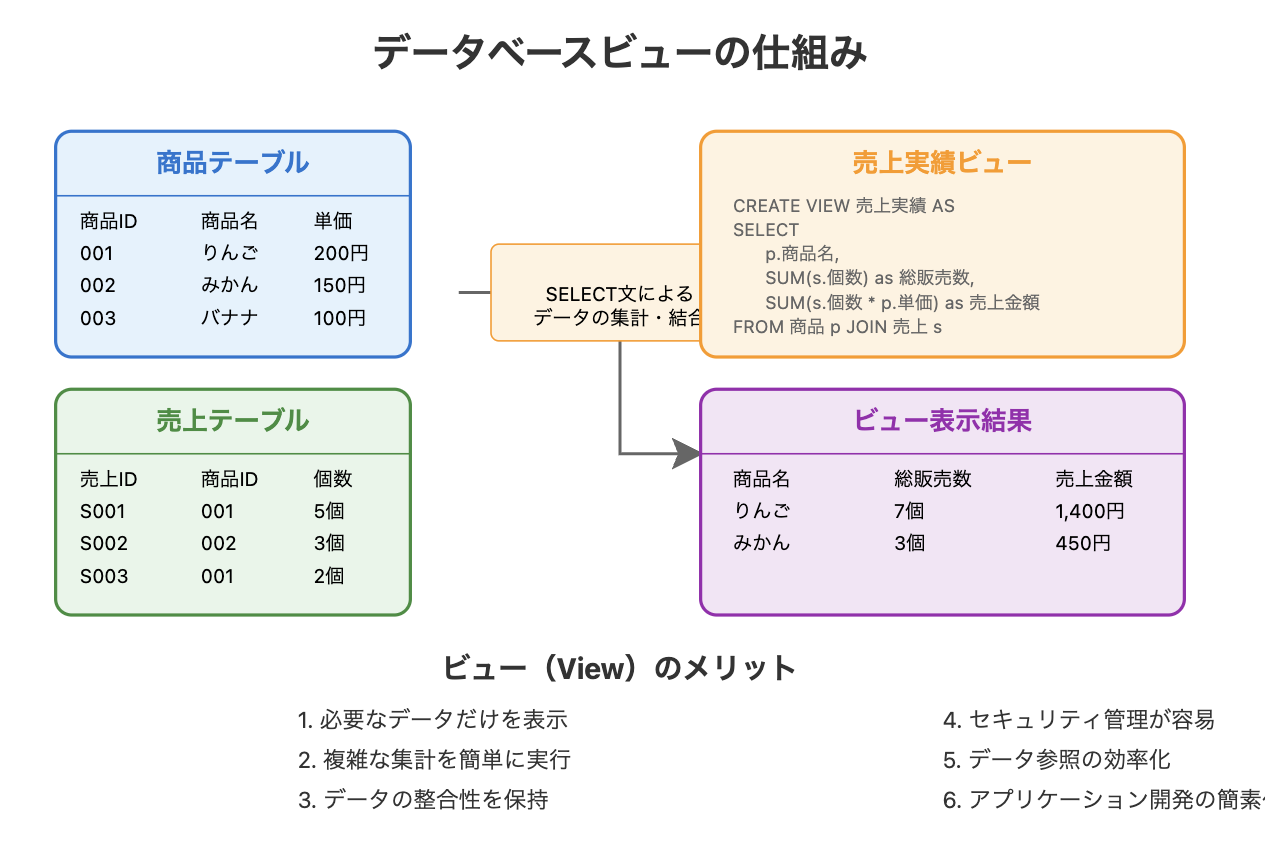
ビュー
基本表からデータを抽出して構成される仮想的な表であり、実際にデータは保存されない.
トランザクション
意味のあるSQL文の集合であり、一連の操作をひとまとめにして管理する.トランザクションを全体的に表すとこうなる.

ACID特性とは?
ACID特性は、データベースにおけるトランザクション処理の信頼性を確保するための重要な概念である. ACIDは、以下の4つの特性を示している.
1. 原子性(Atomicity)
トランザクション内のすべての操作が完全に実行されるか、全く実行されないかのいずれかであることを保証する.
例: 銀行口座間の送金では、送金元の引き落としと送金先の入金が両方成功するか、どちらも実行されないようにする.
2. 一貫性(Consistency)
トランザクションの実行後もデータベースが整合性のある状態を保つことを保証する.
例: 送金処理後、全体の合計金額がトランザクション前と一致するようにする.
3. 独立性(Isolation)
同時に実行される複数のトランザクションが互いに干渉せず、独立して実行されることを保証する.
例: 在庫管理システムで同時に在庫を更新しても不整合が生じないようにする.
4. 耐久性(Durability)
トランザクションが完了したら、その結果が永続的に保存され、システム障害が発生しても失われないことを保証する.
例: 送金処理が完了した後にシステムが停止しても、送金結果が保持される.
トランザクションのみをフローで表すとこのようになる

SQLの機能
DB定義機能(SQL-DDL(Data Definition Language))
データベース、表、スキーマ、ユーザを定義し、必要に応じて削除・更新する.
DB操作機能(SQL-DML(Data Manipulation Language))
データの登録、検索、削除、変更を行う.
DB制御機能(SQL-DCL(Data Control Language))
- トランザクションの開始や終了を管理し、異常時には操作をキャンセルする
- アクセス権の設定や索引の設定など、データベースの効率的な利用を可能にする.
データベースの基本操作
データベースの作成
新しいデータベース「MyLibrary」を作成し、それを使用する手順である.
create database MyLibrary;
use MyLibrary;
テーブルの作成
MyLibraryデータベース内に「books」という名前のテーブルを作成する.
このテーブルは、以下の列で構成されている:
- book_id: 書籍ID(整数型)
- title: 書籍タイトル(20文字以内の文字列)
- author: 著者名(40文字以内の文字列)
- publication_year: 出版年(整数型)
create table books(book_id int, title char(20), author char(40), publication_year int);
制約について
データベースでは、データの一貫性や正確性を保つために制約(Constraints)を使用する.
1.PRIMARY KEY
主キーを指定するための制約で、以下の特徴がある:
- 主キーは表中で一意でなければならない.
-
NOT NULLとUNIQUEの両方を満たす. - 一つの表に一つしか設定できない.
- 主キーが複数列で構成される場合、列定義の最後に記述する.
記述例:
-- 単一列の主キー
CREATE TABLE Student (
StudentID INT PRIMARY KEY,
Name VARCHAR(50),
Age INT
);
-- 複数列の主キー
CREATE TABLE Enrollment (
StudentID INT,
CourseID INT,
PRIMARY KEY(StudentID, CourseID)
);
2.NOT NULL
指定した列には必ず値が設定される必要があることを示す.
記述例:
-- 列にNULL値を許可しない
CREATE TABLE Employee (
EmployeeID INT NOT NULL,
Name VARCHAR(50) NOT NULL,
DepartmentID INT
);
3.UNIQUE
指定した列の値はすべて異なる必要がある.
記述例:
-- 列の値をユニークにする
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100) UNIQUE,
Price DECIMAL(10, 2)
);
4.FOREIGN KEY
他の表の列を参照する外部キーを定義する制約で、参照整合性制約とも呼ばれる.
- 外部キーが参照する表に存在しない値を設定できない.
- MySQLでは、列の定義中に外部キーを直接記述することは推奨されない. 列定義の後に記述するのが一般的である.
記述例:
-- 外部キーを定義
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
FOREIGN KEY(CustomerID) REFERENCES Customers(CustomerID)
);
MySQLでの注意例:
-- MySQLで外部キーを記述する正しい方法
CREATE TABLE Membership (
MemberID INT,
ClubID INT,
FOREIGN KEY(MemberID) REFERENCES Members(MemberID),
FOREIGN KEY(ClubID) REFERENCES Clubs(ClubID)
);
参照整合性制約がある際のデータの削除の例
外部キー制約により、不整合な操作を防ぐことができる.
例:
- 表「student」に
stuno=100111の学生がいる場合、表「所属」にそのstunoを参照する行が存在する. - この学生のデータを削除するには、まず表「所属」から該当行を削除する必要がある.
記述例:
-- 表「student」と「所属」の定義
CREATE TABLE Student (
stuno INT PRIMARY KEY,
Name VARCHAR(50)
);
CREATE TABLE ClubMembership (
stuno INT,
ClubID INT,
FOREIGN KEY(stuno) REFERENCES Student(stuno)
);
-- 関連データ削除の手順
DELETE FROM ClubMembership WHERE stuno = 100111;
DELETE FROM Student WHERE stuno = 100111;
表の構造変更(ALTER TABLE)
表の構造を変更する際には、ALTER TABLE文を使用する.
テーブル名の変更
既存のテーブル名を変更する.
-- テーブル名を変更
ALTER TABLE Users RENAME TO Customers;
列名の変更
特定の列名を変更する.
-- 列名を変更(旧列名:username、新列名:user_name)
ALTER TABLE Customers RENAME COLUMN username TO user_name;
列名と定義の変更
列名だけでなく、データ型やその他の定義も変更する.
-- 列名を変更しつつ、データ型を変更
ALTER TABLE Customers CHANGE COLUMN age user_age INT NOT NULL;
列定義の変更
列名はそのままに、列のデータ型や属性を変更する.
-- 列のデータ型を変更(例:VARCHAR(50)に拡張)
ALTER TABLE Customers MODIFY COLUMN email VARCHAR(50);
列の追加
新しい列をテーブルに追加する.
-- 新しい列を末尾に追加
ALTER TABLE Customers ADD COLUMN phone_number VARCHAR(15);
-- 列を特定の位置に追加(例:一番最初に追加)
ALTER TABLE Customers ADD COLUMN registration_date DATE FIRST;
-- 列を特定の列の後に追加
ALTER TABLE Customers ADD COLUMN membership_status VARCHAR(10) AFTER email;
列の削除
不要な列を削除する.
-- 特定の列を削除
ALTER TABLE Customers DROP COLUMN membership_status;
表の削除(DROP TABLE 文)
DROP TABLE文は、指定した表をデータベースから完全に削除するSQL文だ.
基本構文
DROP TABLE 表名;
-
表そのものを削除する.
- 表の構造(列の定義など)とともに、表に含まれるすべてのデータ(行)も削除される.
-
DELETE文との違い:
-
DELETEはデータ(行)を削除するだけで、表の構造は保持される. -
DROP TABLEは表そのものを削除するため、復元が困難である.
-
- 使用する際には、対象となる表が不要であることを確認する必要がある.
注意事項
-
依存関係:
- 外部キーなどで他の表に依存関係がある場合、エラーが発生する可能性がある.
- このような場合、依存先の外部キーを解除してから削除する必要がある.
-
バックアップ:
- 必要なデータが含まれる場合は、削除前にバックアップを取得することが推奨される.
データの登録(INSERT文)
INSERT文は、新しいデータを表に登録するためのSQL文だ.
基本構文
INSERT INTO 表名 VALUES(値の並び);
使用例
以下は、employeeという表に新しい従業員のデータを追加する例だ.
-- 従業員データの追加
INSERT INTO employee VALUES(101, '山田太郎', '営業部', 3500000, '2025-01-01');
注意事項
- 値の並びは、表を定義したときの列の並びと一致させる必要がある.
- 文字列はシングルクォーテーション(
')で囲む. - 数値はシングルクォーテーションで囲む必要はない.
- 値が存在しない場合は
NULLを指定できる. - 日付時刻はシングルクォーテーションで囲む.
データの削除(DELETE文)
DELETE文は、条件に一致する行を表から削除するためのSQL文だ.
基本構文
DELETE FROM 表名 WHERE 条件;
使用例
以下は、employeeという表から特定の従業員データを削除する例だ.
-- 従業員IDが101のデータを削除
DELETE FROM employee WHERE emp_id = 101;
-- 年収が300万円未満の従業員データを削除
DELETE FROM employee WHERE salary < 3000000;
注意事項
-
WHERE句で条件を指定しない場合、表のすべての行が削除されるので注意が必要だ. - 表そのものを削除するには
DROP TABLE文を使用する.
UPDATE文
UPDATE文は、表内のデータを更新するためのSQL文だ.
基本構文
UPDATE 表名 SET 属性名 = 値 WHERE 条件;
使用例
以下は、employeeという表で従業員データを更新する例だ.
-- 従業員IDが101の年収を400万円に変更
UPDATE employee SET salary = 4000000 WHERE emp_id = 101;
-- 営業部のすべての従業員の年収を10%増加
UPDATE employee SET salary = salary * 1.10 WHERE department = '営業部';
注意事項
-
WHERE句で条件を満たす行に対してのみ値を更新する. - 複数の列を同時に更新する場合は、
SET句で属性と値をカンマで区切る. -
NULLを指定して属性値を空にすることも可能だ.
権限設定(GRANT文とREVOKE文)
GRANT文は、指定したユーザに対して表のアクセス権限を付与するSQL文だ.
一方、REVOKE文は、GRANT文で付与した権限を取り消すためのSQL文である.
基本構文
GRANT 権限 ON 表名の並び TO ユーザ名;
REVOKE 権限 ON 表名の並び FROM ユーザ名;
使用例
以下は、studentという表に対する権限を付与または取り消す例だ.
-- ユーザkawagoeにSELECT, INSERT, DELETE, UPDATEの権限を付与
GRANT SELECT, INSERT, DELETE, UPDATE ON student TO kawagoe;
-- managerにすべての権限を付与
GRANT ALL ON student TO manager;
-- ユーザkawagoeに付与した権限を取り消す
REVOKE SELECT, INSERT ON student FROM kawagoe;
注意事項
-
ALLまたはALL PRIVILEGESを使うと、すべての権限を一括で付与できる. -
WITH GRANT OPTIONを付けると、付与されたユーザが他のユーザに権限を付与できる. - MySQLでは
PUBLICという全ユーザに権限を付与するオプションは無効だ.
ビューの作成と削除(CREATE VIEW文とDROP VIEW文)
ビューは、SQLの検索結果を仮想的な表として登録するために使用する.
CREATE VIEW文の基本構文
CREATE VIEW ビュー名 AS SELECT文;
DROP VIEW文の基本構文
DROP VIEW ビュー名;
使用例
以下は、student表を元に仮想表を作成および削除する例だ.
-- 男子学生のみの仮想表を作成
CREATE VIEW 男子学生 AS SELECT * FROM student WHERE gender = '男';
-- 学生名リストのみの仮想表を作成
CREATE VIEW 学生名リスト表 AS SELECT stu_name FROM student;
-- 男子学生の仮想表を削除
DROP VIEW 男子学生;
注意事項
- ビューは特定の条件に基づいた仮想表であり、実データを持たない.
- ビューは利用者に必要な情報のみを公開するセキュリティ対策として有効だ.
- ビュー経由でのデータの更新や削除は、整合性を損なう可能性があるため推奨されない.
データの取得(SELECT文)
SQLのSELECT文は、データベースから必要な情報を取得するために使用する基本的な文法である.
SELECT文の基本構文
SELECT文は、以下の構文で記述する。
SELECT 列名 FROM 表名 WHERE 条件 ORDER BY 列名 [ASC | DESC];
- SELECT:取得したい列を指定する。
- FROM:データを取得する表を指定する。
- WHERE:データを絞り込む条件を指定する。
- ORDER BY:取得したデータを並び替える。
例1: 表のすべてのデータを取得
以下のクエリは、student表のすべてのデータを取得する。
SELECT * FROM student;
この例では、すべての列と行が出力される。「*」は全列を意味する。
例2: 特定の列を取得
以下のクエリは、student表からstu_name(学生名)とgender(性別)のデータを取得する。
SELECT stu_name, gender FROM student;
複数の列を指定する場合、カンマで区切る。
例3: 条件を指定してデータを取得
以下のクエリは、男性学生のstu_name(学生名)を取得する。
SELECT stu_name FROM student WHERE gender = '男';
文字列の条件指定にはシングルクォートで囲む。
例4: 比較条件を指定
以下のクエリは、GPAが3.5以上の学生のstu_name(学生名)とbirthdate(生年月日)を取得する。
SELECT stu_name, birthdate FROM student WHERE GPA >= 3.5;
比較演算子として>=, <, <>(等しくない)などが使用できる。
例5: 部分一致でデータを取得
以下のクエリは、氏名が「谷」で始まる学生のstu_name(学生名)とgender(性別)を取得する。
SELECT stu_name, gender FROM student WHERE stu_name LIKE '谷%';
LIKE述語と%(任意の文字列)を使って部分一致の条件を指定する。
例6: NULL値の判定
以下のクエリは、GPAが空値である学生のstu_name(学生名)を取得する。
SELECT stu_name FROM student WHERE GPA IS NULL;
IS NULLでNULL値を判定する。空値でないことを判定するにはIS NOT NULLを使用する。
例7: 複数の条件を組み合わせる
以下のクエリは、氏名に「川」を含み、性別が女性である学生のstu_name(学生名)を取得する。
SELECT stu_name FROM student WHERE stu_name LIKE '%川%' AND gender = '女';
条件を組み合わせる際にはAND, ORを使用する。
例8: 値の範囲を指定
以下のクエリは、GPAが3.1以上4.5以下の学生のstu_name(学生名)とGPAを取得する。
SELECT stu_name, GPA FROM student WHERE GPA BETWEEN 3.1 AND 4.5;
BETWEENを使用して範囲を指定できる。
例9: 指定した値のいずれかに一致
以下のクエリは、学科番号が1または3の学生のstu_name(学生名)とdeptno(学科番号)を取得する。
SELECT stu_name, deptno FROM student WHERE deptno IN (1, 3);
INは複数の値を簡潔に列挙できる。
例10: 並び替え
以下のクエリは、男性学生のstuno(学生番号)とstu_name(学生名)を学生番号の昇順で取得する。
SELECT stuno, stu_name FROM student WHERE gender = '男' ORDER BY stuno;
降順の場合はORDER BY stuno DESCと指定する。
例11: 重複を排除
以下のクエリは、男性学生のGPA(成績)を重複を排除して取得する。
SELECT DISTINCT GPA FROM student WHERE gender = '男';
DISTINCTを使用すると、重複する値を排除できる。
例12: 集約関数
以下のクエリは、学生数、GPAの平均、合計、最大値、最小値を取得する。
SELECT COUNT(*), AVG(GPA), SUM(GPA), MAX(GPA), MIN(GPA) FROM student;
集約関数としてCOUNT, AVG, SUM, MAX, MINが使用できる。
例13: グループ化
以下のクエリは、学科ごとの平均GPAを取得する。
SELECT deptno, AVG(GPA) FROM student GROUP BY deptno;
GROUP BY句を使用して列ごとにグループ化する。
例14: グループ化と条件指定
以下のクエリは、男子学生の中で、平均GPAが3.0以上の学科ごとの平均GPAを取得する。
SELECT deptno, AVG(GPA) FROM student WHERE gender = '男' GROUP BY deptno HAVING AVG(GPA) >= 3.0;
HAVING句は、グループ化後の条件指定に使用する。
グループ化を使うタイミングと例
データベースでグループ化を使うのは、データを特定のカテゴリや属性ごとに集計する必要がある場合だ。
1. 特定の属性ごとの集計
特定の列を基準にしてデータをグループ化し、それぞれのグループに対して集計を行う場合だ。たとえば、学生の学科ごとの平均GPAを計算する場合は以下のようになる。
SELECT 学科番号, AVG(GPA) FROM 学生表 GROUP BY 学科番号;
このクエリでは、学科番号ごとに学生をグループ化し、各グループのGPAの平均を計算して出力する。
2. カテゴリごとのデータ比較
異なるカテゴリのデータを比較するためにグループ化を用いることができる。たとえば、各店舗の総売上を計算して比較する場合は以下の通りだ。
SELECT 店舗ID, SUM(売上) FROM 売上表 GROUP BY 店舗ID;
このクエリでは、店舗ごとに売上をグループ化し、各店舗の売上合計を計算する。
3. 特定の条件を先に絞り込んでグループ化
WHERE句でデータを絞り込み、その後でグループ化を行う場合もある。たとえば、性別が男性の学生のみを対象にして、学科ごとの平均GPAを計算する場合は以下のようになる。
SELECT 学科番号, AVG(GPA) FROM 学生表 WHERE 性別 = '男' GROUP BY 学科番号;
ここでは、WHERE句で男性のみを対象にデータを絞り込み、その後GROUP BYで学科ごとにデータをグループ化している。
グループ化はデータの集計や比較を行う際に非常に有用である。利用する際は、以下のポイントを押さえておくと良い。
-
GROUP BYはデータを特定の列でグループ化する。 - グループ化後に条件を適用する場合は
HAVING句を利用する。 -
WHERE句で絞り込んだデータに対してグループ化を行うことができる。 - 基本的にSQLの集約関数(COUNT, SUM, AVG, MAX, MINなど)を使った際にグループ化する例が多い
結合演算
1. 基本的な結合
2000年以降に入学した学生の名前と、その学生が所属するサークル番号を取得する例である。
SELECT stu_name, サークル番号
FROM student, 所属
WHERE 入学年 >= 2000
AND student.stuno = 所属.stuno;
studentテーブルと所属テーブルを結合している。WHERE句で、入学年が2000年以降である条件を指定し、さらにstudentテーブルのstunoと所属テーブルのstunoが一致する学生を選択する。このように、複数のテーブルを結合する際は、FROM句でテーブルを指定し、WHERE句で結合条件を明示的に指定する必要がある。
2: 相関名を使った複雑な結合
「鈴木健太」と同じ学科に所属する学生がどのサークルに入っているかを調べる例である。
SELECT Y.stu_name, サークル名, 所属日
FROM student X, student Y, 所属, サークル
WHERE X.stu_name = '鈴木健太'
AND X.deptno = Y.deptno
AND Y.stuno = 所属.stuno
AND 所属.サークル番号 = サークル.サークル番号;
studentテーブルを2回使用しており、XとYという相関名でそれぞれの学生を区別している。X.deptno = Y.deptnoという条件で、同じ学科に所属する学生を抽出し、所属テーブルとサークルテーブルを結合して、サークルの情報を取得する。相関名を使うことで、同じテーブルを異なる役割で参照することができる。
3: 交差結合(直積)
studentテーブルとサークルテーブルを交差結合する例である。
SELECT *
FROM student
CROSS JOIN サークル;
CROSS JOINは、2つのテーブルの直積(クロス結合)を求めるSQL文である。これにより、studentテーブルの全ての行とサークルテーブルの全ての行が組み合わさり、すべての組み合わせが出力される。例えば、studentテーブルに5行、サークルテーブルに4行があれば、出力される結果は20行になる。
顧客と所属情報の例
顧客ID 顧客名 所属
101 田中 A大学
102 渡辺 B大学
所属 住所
A大学 千葉
B大学 東京
この場合、CROSS JOINを使うと、次のような結果が得られる。
顧客ID 顧客名 所属 所属住所
101 田中 A大学 千葉
101 田中 A大学 東京
102 渡辺 B大学 千葉
102 渡辺 B大学 東京
交差結合を使用すると、すべての組み合わせが出力されるため、意図しない多くの行が返されることになる。したがって、CROSS JOINを使用する際は、その特性を理解しておくことが重要である.
4: 等結合
studentテーブルとサークルテーブルを等結合する例である。
SELECT *
FROM student
JOIN サークル ON student.stuno = サークル.サークル部長;
等結合では、2つのテーブル間で条件を満たす行のみを出力する。ON句を用いて結合条件を指定することで、student.stunoとサークル.サークル部長の値が一致する行を結合する。以下のSQL文でも同じ結果が得られる。
SELECT *
FROM student, サークル
WHERE student.stuno = サークル.サークル部長;
顧客と所属情報の例
顧客ID 顧客名 所属
001 佐藤 A
002 飯田 B
003 三井 B
所属 住所
A 千葉
B 東京
この場合、等結合の結果は次のようになる。
顧客ID 顧客名 所属 所属 住所
001 佐藤 A A 千葉
002 飯田 B B 東京
003 三井 B B 東京
5: 自然結合
studentテーブルと所属テーブルを自然結合する例である。
SELECT *
FROM student
NATURAL JOIN 所属;
自然結合では、2つのテーブルに共通する同名の列を基準に自動的に結合する。例えば、studentテーブルのstuno列と所属テーブルのstuno列が一致する行を結合し、重複する列は1つにまとめて出力する。
顧客と所属情報の例
顧客ID 顧客名 所属
001 佐藤 A
002 飯田 B
003 三井 B
所属 住所
A 千葉
B 東京
この場合、自然結合の結果は次のようになる。
自然か都合だと等結合と違って「所属」が重複していないことがわかりますね?
顧客ID 顧客名 所属 住所
001 佐藤 A 千葉
002 飯田 B 東京
003 三井 B 東京
6: 左外結合
studentテーブルとサークルテーブルを左外結合する例である。
SELECT *
FROM student
LEFT OUTER JOIN サークル ON student.stuno = サークル.サークル部長;
左外結合では、LEFT JOINの左側のテーブル(この例ではstudent)のすべての行が出力される。結合条件を満たす行は右側のテーブルの対応する値が結合されるが、満たさない行にはNULLが設定される。
顧客と所属情報の例
顧客ID 顧客名 所属
001 佐藤 A
002 飯田 B
003 三井 C
所属 住所
A 千葉
B 東京
この場合、左外結合の結果は次のようになる。
顧客ID 顧客名 所属 所属 住所
001 佐藤 A A 千葉
002 飯田 B B 東京
003 三井 C NULL NULL
7: 右外結合
studentテーブルとサークルテーブルを右外結合する例である。
SELECT *
FROM student
RIGHT OUTER JOIN サークル ON student.stuno = サークル.サークル部長;
右外結合では、RIGHT JOINの右側のテーブル(この例ではサークル)のすべての行が出力される。結合条件を満たす行は左側のテーブルの対応する値が結合されるが、満たさない行にはNULLが設定される。
顧客と所属情報の例
顧客ID 顧客名 所属
001 佐藤 A
002 飯田 B
003 三井 B
所属 住所
A 千葉
B 東京
C 神奈川
この場合、右外結合の結果は次のようになる。
顧客ID 顧客名 所属 所属 住所
001 佐藤 A A 千葉
002 飯田 B B 東京
003 三井 B B 東京
NULL NULL NULL C 神奈川
8: 完全外結合
studentテーブルとサークルテーブルを完全外結合する例である。
SELECT *
FROM student
FULL OUTER JOIN サークル ON student.stuno = サークル.サークル部長;
完全外結合では、結合条件を満たす行は1つにまとめるが、一致しない行もそれぞれのテーブルから出力される。他の表に対応する値がない場合、NULLが設定される。
顧客と所属情報の例
顧客ID 顧客名 所属
001 佐藤 A
002 飯田 B
003 三井 B
所属 住所
A 千葉
B 東京
D 神奈川
この場合、完全外結合の結果は次のようになる。
顧客ID 顧客名 所属 所属 住所
001 佐藤 A A 千葉
002 飯田 B B 東京
003 三井 C NULL NULL
NULL NULL NULL D 神奈川
9: 和結合
SELECT *
FROM サークル
UNION JOIN student;
和結合は、2つの表を連結せずに1つの表にまとめて出力する操作である。
- 学生の表に対応する行のサークルの情報には
NULLが設定される。 - サークルの表に対応する学生の情報には
NULLが設定される。
ただし、MySQLでは和結合は実装されていないため、この操作は使用できないので注意が必要である。
顧客と所在地の例
顧客情報と所在地情報の例を用いる。
顧客テーブル
顧客ID 顧客名 所属
001 佐藤 A
002 飯田 B
003 三井 B
所在地テーブル
所属 住所
A 千葉
B 東京
和結合を適用した場合の結果は以下のようになる。
結果
顧客ID 顧客名 所属 所属 住所
001 佐藤 A NULL NULL
002 飯田 B NULL NULL
003 三井 B NULL NULL
NULL NULL NULL A 千葉
NULL NULL NULL B 東京
副問合せ(サブクエリ)
副問合せとは、SELECT文内に複数の基本的なSELECT文を組み合わせた問合せのことを指す。これにより、より複雑な問合せを記述することが可能になる。
基本構文
SELECT・・・
FROM・・・
WHERE・・・属性名 = (
SELECT 属性名
FROM・・・
WHERE・・・
);
- 最初の
SELECT文を親問合せと呼ぶ。 - 入れ子になっている
SELECT文を副問合せと呼ぶ。
1.特定の学生の所属サークル番号と所属日を取得
SELECT サークル番号, 所属日
FROM 所属
WHERE stuno = (
SELECT stuno
FROM student
WHERE stu_name = '佐藤'
);
- 「佐藤」という名前の学生が所属するサークルのサークル番号と所属日を出力する。
- 同姓同名の学生がいない場合に有効。
- 同姓同名の学生がいる場合、結果が複数行になるため、この例は動作しない。その場合は
INを使用する必要がある。
2.特定学生が所属するサークルの部長情報を取得
SELECT *
FROM student
WHERE stuno = (
SELECT サークル部長
FROM サークル
WHERE サークル番号 = (
SELECT サークル番号
FROM 所属
WHERE stuno = (
SELECT stuno
FROM student
WHERE stu_name = '佐藤'
)
)
);
- 「佐藤」という名前の学生が所属するサークルの部長である学生のデータをすべて出力する。
3.特定学生のGPAより低い学生を取得
SELECT stu_name, gender
FROM student
WHERE GPA < (
SELECT GPA
FROM student
WHERE stu_name = '佐藤'
);
- 「佐藤」という名前の学生のGPAよりも低い値を持つ学生の名前と性別を出力する。
4.条件に合致する学科の平均GPAを計算
SELECT AVG(GPA)
FROM student
WHERE deptno IN (
SELECT deptno
FROM student
WHERE GPA > 4.0
);
- GPAが4.0より大きな成績を持つ学生がいる学科のすべての学生について、平均GPAを計算する。
- 副問合せの結果が複数行になる場合、
=ではなくINを使用する。
5.特定条件に含まれない学科の平均GPAを計算
SELECT AVG(GPA)
FROM student
WHERE deptno NOT IN (
SELECT deptno
FROM student
WHERE GPA > 4.0
);
- GPAが4.0より大きな成績を持つ学生がいる学科以外の学生について、平均GPAを計算する。
-
NOT INを使用することで、副問合せの結果に含まれないデータ集合を条件として設定する。
6.特定サークルに所属しGPAが高い学生を取得
SELECT stu_name, gender
FROM student
WHERE GPA > 3.0
AND stuno = ANY (
SELECT stuno
FROM 所属
WHERE サークル番号 = (
SELECT サークル番号
FROM サークル
WHERE サークル名 = '軽音楽部'
)
);
- 軽音楽部に所属している学生で、GPAが3.0より大きい学生の名前と性別を出力する。
-
ANYは副問合せの結果のうちどれか1つが条件を満たせば真となる。 -
ANYはSOMEと同じ意味であり、= ANYの部分をINにしても同じ結果が得られる。
7.特定条件を満たす学生を取得
SELECT *
FROM student
WHERE GPA > ANY (
SELECT GPA
FROM student
WHERE stu_name LIKE '%田%'
);
- 名前に「田」を含む学生の中で、GPAの最小値より大きなGPAを持つ学生の情報を出力する。
8.GPAが最大値より高い学生を取得
SELECT *
FROM student
WHERE GPA > ALL (
SELECT GPA
FROM student
WHERE stu_name LIKE '%田%'
);
解説
- 名前に「田」を含む学生の中で、GPAの最大値より大きなGPAを持つ学生の情報を出力する。
-
ALLは、副問合せのすべての結果を満たす場合に真となる。
9.GPAが高くサークル部長である学生を取得
SELECT *
FROM student
WHERE GPA > 3
AND EXISTS (
SELECT *
FROM サークル
WHERE サークル部長 = stuno
);
解説
- GPAが3より大きく、サークル部長である学生の情報を出力する。
-
EXISTSは副問合せの結果が存在する場合に真となる。
10.GPAが高くサークル部長でない学生を取得
SELECT *
FROM student
WHERE GPA > 3
AND NOT EXISTS (
SELECT *
FROM サークル
WHERE サークル部長 = stuno
);
- GPAが3より大きく、サークル部長ではない学生の情報を出力する。
-
NOT EXISTSは副問合せの結果が存在しない場合に真となる。
11.複数条件で学生の名前を取得
SELECT stu_name
FROM student
WHERE deptno = 1 AND GPA >= 3
UNION
SELECT stu_name
FROM student
WHERE deptno = 2 AND GPA > 4;
-
deptnoが1でGPAが3以上、またはdeptnoが2でGPAが4より大きい学生の名前を出力する。 - 以下のSQL文と同等:
SELECT stu_name
FROM student
WHERE (deptno = 1 AND GPA >= 3) OR (deptno = 2 AND GPA > 4);
12.複数条件を同時に満たす学生を取得
SELECT stu_name
FROM student
WHERE deptno = 1 AND GPA >= 3
INTERSECT
SELECT stu_name
FROM student
WHERE gender = '男';
-
deptnoが1でGPAが3以上、かつ男性である学生の名前を出力する。 - MySQL 8.0.31以降で
INTERSECTがサポートされている。 - 以下のSQL文と同等:
SELECT stu_name
FROM student
WHERE (deptno = 1 AND GPA >= 3) AND (gender = '男');
13.特定条件を除外した学生を取得
SELECT stu_name
FROM student
WHERE deptno = 1 AND GPA >= 3
EXCEPT
SELECT stu_name
FROM student
WHERE gender = '男';
-
deptnoが1でGPAが3以上、かつ男性ではない学生の名前を出力する。 - MySQL 8.0.31以降で
EXCEPTがサポートされている。 - 以下のSQL文と同等
SELECT stu_name
FROM student
WHERE (deptno = 1 AND GPA >= 3) AND NOT (gender = '男');
関係データモデルとは?
関係データモデルは、データを関係として構造化するためのモデルであり、データを表形式で扱うアプローチを提供する。関係データモデルでは、データは「関係」という単位で表され、その関係はタプル(行)と属性(列)から構成されている。関係データモデルは、リレーショナルデータベースの理論的な基盤となっている。
関係データモデルの主な特徴は以下の通りだ。
-
関係(Relation):
- 関係は、リレーショナルデータベースにおける「表」とほぼ同義であり、二次元のデータ構造である。関係は、タプル(行)と属性(列)の組み合わせで構成されており、各タプルはその関係におけるデータの一つの単位を表す。
-
タプル(Tuple):
- タプルは、関係の各行に対応し、データの一組を表す。例えば、社員情報を格納するタプルには、社員番号、名前、性別などが含まれる。
-
属性(Attribute):
- 属性は、関係の各列に対応し、データの特性や種類を表す。例えば、「社員番号」や「社員名」などが属性に該当する。
-
ドメイン(Domain):
- ドメインは、属性が取り得る値の範囲であり、例えば「性別」の属性のドメインは「男」「女」といった値の集合となる。
-
順序がない:
- 関係データモデルでは、行(タプル)の順序に意味はなく、データは集合として扱われる。関係は集合であるため、タプルの順序は定まっていない。
関係データモデルとデータベースの関係性
関係データモデルとは
数学的な基礎理論に基づいており、データの整合性を保ちながら効率的にデータを管理することができる。また、データの冗長性を排除するために、正規化と呼ばれる手法が用いられる。
データベースとは
関係データモデルを実際にデータ管理のために使用するシステムやソフトウェアを指す。リレーショナルデータベース管理システム(RDBMS)では、関係データモデルに基づいたデータを格納、検索、更新するための機能が提供される。具体的には、SQL(Structured Query Language)を使ってデータベースに格納された関係データを操作することができる。
関係データモデルとデータベースの違い
モデルが理論的な枠組みであるのに対し、データベースはその理論を実装したシステムである点だ。関係データモデルはデータの構造や操作の方法を定義するものであり、データベースは実際にそのモデルを使ってデータを管理するためのツールである。
SQLと関係データモデルの違い
- SQLでは同じ値を持つ行が存在できるが、関係データモデルでは存在しない。
- SQLのSELECT文で、結果の表から同じ値を持つ行(重複)を除去したい場合は、DISTINCTキーワードで明示的に除去する。
- 関係データモデルでは、そもそも同じ値を持つ行は存在し得ない。
- 関係データモデルのタプル(行)は集合の要素であるため。
用語の違い
SQLと関係データモデルでは、同じ対象を表す用語が異なる。
| SQL | 関係データモデル |
|----------|-----------------|
| 表(table) | 関係(relation) |
| 行(row) | タプル(tuple) |
| 列(column) | 属性(attribute)|
関係データモデルにおける「関係」
- 関係データモデルの「表」は、以下のように構成される。
属性(列) 社員コード 社員名 性別 生年月日
10001 田中一郎 男 1950年1月1日
10002 山田次郎 男 1954年4月4日
10003 山本花子 女 1966年6月6日
- 関係(relation)として定義され、行(タプル)は順序を持たない集合である。
「表」と関係データモデルの違い
- 私たちが考える「表」では、行の並び順に意味を持たせることがある。
- 関係データモデルでは、行の順序には意味がない(集合として扱われるため)。
- SQLでは、「ORDER BY」を用いて出力順序を指定できるが、指定しない場合の順序には決まりがない。
関係データモデルの厳密な定義
関係 R の定義
- 関係 ( R ) は以下で定義される。
R ⊆ D1 × D2 × ... × Dn
- ここで ( D_i ) は属性 ( A_i ) のドメイン(取り得る値の集合)である。
例
- ( D_1 ): 1から4までの整数, ( D_2 ): 1から5までの整数の場合
D1 × D2 = { (1,1), (1,2), ..., (4,5) }
- ある関係 ( R ) が以下のように定義されたとする。
R = { (2,3), (1,2), (4,3), (3,5) }
関係スキーマ
- 関係が属性 ( A_1, A_2, ..., A_n ) から構成されていることを示すには以下のように記述する。
R(A1, A2, ..., An)
- 例:学生(学生番号, 学生名, 生年月日, 住所)
関係代数
関係代数は、関係を数学的に扱うための手法であり、以下の演算が定義される。
集合演算
- 和集合演算:二つの関係の和集合を求める演算。
- 差集合演算:ある関係から他の関係の差集合を求める演算。
- 共通集合演算:二つの関係の両方に存在するものを抽出する演算。
- 直積演算:二つの関係のすべての組み合わせを求める演算。
関係代数に特有の演算
- 商集合演算:一方が他方のすべての要素を含んでいるタプルを抽出する演算。
- 射影演算:関係から指定属性集合のみの値を抜き出す演算。
- 選択演算:関係から指定条件を満たすタプル集合を抜き出す演算。
- 結合演算:複数の関係を指定条件によって結合する演算。
射影演算 (Projection)
射影演算は、関係データモデルにおいて指定された属性のみを抽出するための演算である。この演算は、関係の中から必要な情報だけを選択し、不要な情報を排除するのに役立つ。具体的には、射影演算 π(A,B) R は、関係 R の中から属性 A と B を含むデータを抽出する。
特徴:
- 指定された属性以外の列は削除される。
- 抽出結果では、重複したタプルは取り除かれる。
例:
関係 R:
| A | B | C | D |
|---|---|---|---|
| a | b | c | d |
| a | b | e | f |
| b | c | e | f |
| c | d | c | d |
射影 π(A,B) R の結果:
| A | B |
|---|---|
| a | b |
| b | c |
| c | d |
選択演算 (Selection)
選択演算は、関係のタプルを条件に基づいて選択する演算である。例えば、選択演算 σ(A=a) P は、関係 P の中から属性 A が値 a であるタプルを抽出する。
特徴:
- 指定された条件を満たすタプルのみが選択される。
- 関係を構成する属性は変更されない。
- 条件は比較演算子や論理演算子(AND, OR, NOT)を組み合わせて指定できる。
例:
関係 P:
| A | B | C | D |
|---|---|---|---|
| a | b | c | d |
| a | b | e | f |
| b | c | e | f |
選択 σ(A=a) P の結果:
| A | B | C | D |
|---|---|---|---|
| a | b | c | d |
| a | b | e | f |
結合演算 (Join)
結合演算は、二つの関係を特定の条件に基づいて結合する操作である。例えば、P⋈(B=C) Q は、関係 P と Q の間で属性 B と C が等しいタプルを結合する。
特徴:
- 結合結果には、結合した関係 P と Q のすべての属性が含まれる。
- 等結合の場合、条件を満たすタプルだけが結合される。
例:
関係 P:
| A | B | C |
|---|---|---|
| 1 | 2 | 3 |
| 2 | 4 | 1 |
関係 Q:
| B | C | D |
|---|---|---|
| 2 | 3 | 5 |
| 4 | 1 | 6 |
結合 P ⋈(B=C) Q の結果:
| A | B | C | D |
|---|---|---|---|
| 1 | 2 | 3 | 5 |
自然結合演算 (Natural Join)
自然結合は、等結合の結果から、結合に使用された同名の属性を一方だけ残して重複を削除する演算である。これにより、結合条件を明示する必要がなくなる。
特徴:
- 同じ名前の属性で結合を行う。
- 重複する属性が削除され、簡潔な結果が得られる。
例:
関係 P:
| A | B |
|---|---|
| a | b |
| c | d |
関係 Q:
| B | C |
|---|---|
| b | e |
| d | f |
自然結合 P⋈Q の結果:
| A | B | C |
|---|---|---|
| a | b | e |
| c | d | f |
複数属性の自然結合
複数の同名属性がある場合、これらも一つにまとめられる。
例:
関係 P:
| A | B | C |
|---|---|---|
| 1 | 2 | 3 |
| 2 | 4 | 5 |
関係 Q:
| B | C | D |
|---|---|---|
| 2 | 3 | 6 |
| 4 | 5 | 7 |
自然結合 P⋈Q の結果:
| A | B | C | D |
|---|---|---|---|
| 1 | 2 | 3 | 6 |
| 2 | 4 | 5 | 7 |
関係代数とSQLの関係性
関係代数を用いることで、SQLに対応するデータベースの問合せを記述することができる。ただし、SQLのすべての機能が関係代数で表現できるわけではない。以下に例を示す。
例1:
SQL:
SELECT stu_name, gender FROM student;
関係代数:
π(stu_name,gender)student
例2:
SQL:
SELECT * FROM student WHERE gender='男';
関係代数:
σ(gender='男')student
例3:
SQL:
SELECT stu_name, gender FROM student WHERE gender='男';
関係代数:
π(stu_name,gender)(σ(gender='男')student)
例4:
SQL:
SELECT stu_name FROM student WHERE deptno=1 AND GPA>=3 UNION SELECT stu_name FROM student WHERE deptno=2 AND GPA>4;
関係代数:
(π(stu_name)σ(deptno=1 AND GPA>=3 )student)⋈(π(stu_name)σ(deptno=2 AND GPA>4 )student)
データモデル
データモデルとは、実世界の事象や情報を記述・操作するための規約である。
データベースは、保存したデータをうまく取り出せるように適切に管理しなければならない。
どのようなデータをどのように保存するかを決めておく必要がある。
データモデルは、データベース管理システム(データベースソフトウェア)がデータベースを管理するために、データを記述・操作するための枠組み(または規約)を提供する。
データモデルの種類
関係データベースで用いられているデータモデルは、関係データモデル(表形式でデータを記述)である。
その他に以下のようなモデルがある。
- 階層型データモデル
- ネットワーク型データモデル(CODASYLモデル)
- 実体関連データモデル(ERモデル)
上記の1と2は、関係データモデルと同様、データベース管理システムで用いられるモデルである。
3は、データベースの設計に用いられる概念的なモデルである。
データモデルとスキーマ
データモデルはデータの記述方法の規約であり、それに基づいて実際に記述された情報はスキーマと呼ばれる。
関係データベースの場合:
- 「関係データモデル」がデータモデルである。
- 「表の構成情報」がスキーマである。
例:学生表では、学生番号、学生名、住所などが含まれる。 - 「実際に記述されたデータ」がインスタンスである。
例:学生表では、実際の学生のデータが該当する。
スキーマは、具体的な実世界の情報構造をデータモデルを用いて記述したものである。
階層型データモデル
階層型データモデルは、1969年にIBMから製品化されたIMS(Information Management System)というデータベース管理システムで使用されたデータモデルである。
関連するデータを、親と子の関係で表現する。
- 記述するデータのスキーマを「レコードタイプ」と呼ぶ。
- 実際のデータが記述されたインスタンス(レコード)を「セグメント」と呼ぶ。
階層型データモデルの問題点
- 親は複数の子を持てるが、子は1個の親しか持てない。
- 1対多の関係しか表現できず、ネットワーク構造を表現できない。
この制限を解決するために、「論理関係」を記述できるような拡張が行われた。
ネットワークモデル(CODASYLモデル)
プログラミング言語COBOLでデータベースを扱うために提案されたデータモデルである。
CODASYL(Conference for Data System Language)は、米国における情報システムに用いる標準言語を策定するための協議会である。
- 階層型データモデルと異なり、ネットワーク構造の表現が可能である。
- バックマン線図と呼ばれる記述方法で図式化できる。
- ポインタによってデータ間の関係が設定されているため、特定のデータから関連しているデータを効率的に取り出せる。
多対多の関係のデータレベルの表現
- 親レコードから個々の子レコードを巡回するポインタを用いる。
- ポインタには以下の3種類がある:
- NEXTポインタ:次のレコードを示す。
- PRIORポインタ:前のレコードを示す。
- OWNERポインタ:親レコードを示す。
- 図では便宜上、NEXTポインタのみを記述する。
例:
部門1 部門2
商品1 商品2 商品3
顧客1 顧客2 顧客3
社員1 社員2 社員3 社員4 社員5 社員6
受注7 受注1 受注2 受注3 受注4 受注5 受注6
ERデータモデル
1970年にCoddが関係データモデルを提案したが、この頃使われていたのはCODASYL型データモデルに基づくDBMSであった。
- 効率は良いが、スキーマの設計に多くの経験が必要。
- 設計次第で性能、信頼性、利用可能期間に影響が出る。
- データベースの対象となるデータの構造を明らかにする重要性が高まり、様々なデータモデルが開発された。
1976年にChenがERデータモデルを提案した。
-
ERデータモデルとは、Entity-Relationshipデータモデルの略である。
- Entityは「実体」、Relationshipは「関連」を意味する。
- 実体関連データモデルとも呼ばれる。
実体と関連
- 実体:データベースが対象とする実世界に存在するもので、データベースとして表現すべき対象。
- 関連:実体同士の相互関係。
- 同じ種類の実体をまとめたものを「実体型」と呼ぶ。
- 共通の性質(属性)を持つ実体の集まりであり、抽象的な概念。
- 例:社員という実体型は「社員番号」「名前」「生年月日」などの共通属性を持つ。
- 同様に、同じ種類の関連をまとめたものを「関連型」と呼ぶ。
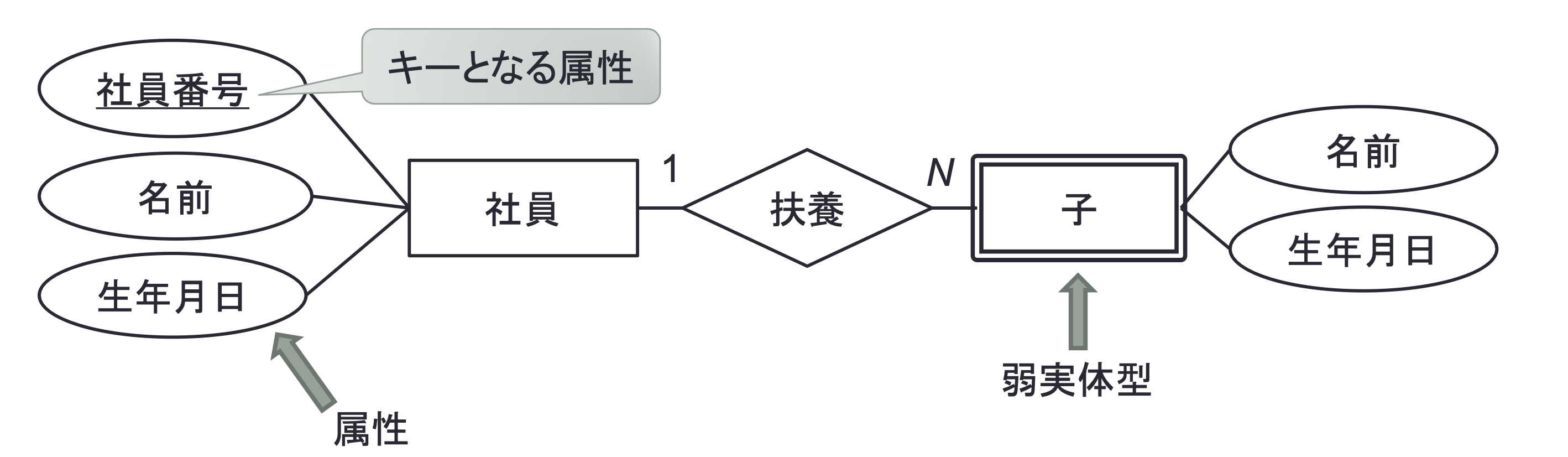
ER図
- 実体型を長方形で表現し、関連型をひし形で表現する。
- 二つの実体型間の関連型には量的関係を示す記号を併記する。
- 「1対多」、「多対多」、「1対1」のように表現する。
- 片方の実体X一件に対して関連する他方の実体Yが何件あるかを示す。
- ER図では N, M, 1 のような記号を用いる。
量的関係の記述
- 1対多:
1:N - 多対多:
N:M - 1対1:
1:1

実体型と属性
- 実体型や関連型には属性を持つことを楕円で記述する。
- 実体を識別するためのキー属性を下線で記述する。
- 自分ではキーを持たず、関連型で結ばれている他の実体型のキーと組み合わせることで識別される実体型を「弱実体型」と呼ぶ。
例:
- 実体型「社員」
- 属性:社員番号(キー)、名前、生年月日。
- 弱実体型「扶養子」
- 属性:名前、生年月日。
データベースの作り方
データベースは実際の業務で使用している情報を扱うため,実際の業務の内容を広範囲に知ることが重要。
- 様々な業務で使われている用語の知識。
- 利用者から問題点や要望などの情報を引き出すための知識。
- 実際に業務で使われている文書や帳票などを理解する知識。
- もちろんコンピュータやデータベースの専門知識も必要。
データベースの構造を設計するためには豊富な経験と知識が必要。
データベースの設計プロセス
第1段階 要件定義
- DBの目的,対象とする業務の情報,利用者からの要求事項を抽出整理。
第2段階 概念スキーマ設計
- 第1段階で定義した要件を基に,DBが持つべき情報構造を記述(ERデータモデル)。
第3段階 論理スキーマ設計
- 実際に使用するDBMSで,DBを構築するために必要な情報の論理的な構造を記述(関係データモデル,正規化)。
第4段階 物理スキーマ設計
- 実際にDBを記憶装置に格納し効率的に管理するための設計(インデックス等の設定)。
概念スキーマ設計
- ER図を使用して,必要な情報の構造を記述。
- まずは必要な実体を定義。
(方法1) ボトムアップアプローチ
- ドキュメントや伝票を調査し,そこから必要なデータ項目を洗い出し,実体を抽出。
(方法2) トップダウンアプローチ
- 実世界を分析し,実際に存在する対象物を実体として抜き出す。
- 次に,複数の実体の間の関連を定義。
- 対象とする実世界を眺めたり,さまざまなドキュメントを調査することで,実体と実体の間の関連を書き出していく。
- その結果をER図として整理し,さらに属性や,関連に対応した量的関係を記述。
論理スキーマ設計
- システムで使用するDBMSの仕様に基づいて表を定義。
- 表の名前や,その表を構成する列の名前・データ型を設計。
- ビューの定義も行う。
- 必要に応じて,意図的に重複データを付加したり,表を分割することもある。
- 概念スキーマ設計の段階で作成したER図から,関係(表)に変換することで,初期の表を作る。
- データの冗長性や不整合をなくすため,正規化を行う。
ER図から表への変換(属性なし)
- 1:Nの関連を持つ実体型。
- 例: 出発空港,フライト,到着空港,予約,顧客。
ER図から表への変換(属性を追加)
- 属性を付加し,実体型の詳細を定義。
- 例: フライト番号,フライト年月日,空港名,時刻。
ER図から関係(表)への変換のルール1(実体型の処理)
- 実体型を表に変換。
- 通常の実体型は,構成する属性によって表を作成。
- 弱実体型は,構成する属性と関連する通常の実体の主キーから構成される表を作成。
ER図から関係(表)への変換のルール2(関連型の処理)
- 関連型を表に変換。
- 多対多の関連型: 各実体型の主キーと,関連型に設定された属性を加える。
- 1対多の関連型: 「1」側の主キーと関連型の属性を「多」側の表に加える。
- 1対1の関連型: 片方の主キーと関連型の属性を他方の表に加える。
- 3種類以上の実体型が繋がっている場合: 各実体型の主キーを加えた表を作成。
正規化とは
正規化とは、実世界の事象や情報を矛盾なく管理するために、関係データベースの構造を整理・形式化することである。正規化により以下の不整合を防ぐことができる。
- 修正不整合
- 挿入不整合
- 削除不整合
第一正規形(1NF)の定義
第一正規形(1NF)とは、以下の条件を満たす関係のことである。
- 構成する属性が分解不可能な単純値のみである。
- 各属性が取り得る値は、単一値でなければならない(集合値、繰り返し値、入れ子構造を許さない)。
これにより、データの構造がより単純化され、操作が容易になる。
第一正規形でない例
以下に、第一正規形でない例を示す。
| 学生番号 | 氏名 | 所属サークル |
|---|---|---|
| 0001 | 安田 | サッカー部, 軽音楽部 |
| 0002 | 木村 | コンピュータクラブ |
この例では、「所属サークル」列に複数値(サッカー部、軽音楽部)が含まれているため、第一正規形ではない。
第一正規形に変換した例
上記の例を第一正規形に変換すると、次のようになる。
| 学生番号 | 氏名 | 所属サークル |
|---|---|---|
| 0001 | 安田 | サッカー部 |
| 0001 | 安田 | 軽音楽部 |
| 0002 | 木村 | コンピュータクラブ |
この変換により、各属性が単一値のみを含むようになり、第一正規形を満たす。
修正不整合
「修正不整合」は、データを修正する際に、同じ情報が複数の場所に存在するために起こる矛盾である。
例えば、以下のような関係を考える。
| 学生番号 | サークル番号 | 学生名 | サークル名 | サークル顧問 |
|---|---|---|---|---|
| 0001 | 2 | 学生A | サークルB | 顧問X |
| 0002 | 2 | 学生B | サークルB | 顧問X |
ここで、サークルBの顧問が変更された場合、すべての関連タプルを修正しなければならない。一部のタプルの修正を忘れると矛盾が生じる。
挿入不整合
「挿入不整合」は、主キーの制約などによって新しいデータの挿入が困難になる場合を指す。
例えば、以下のような状況がある。
- 学生3が入学したが、まだサークルに所属していない。
- 主キーが(学生番号, サークル番号)のため、「サークル番号」に値が必要である。
この場合、学生3のデータを挿入できない。
削除不整合
「削除不整合」は、データを削除する際に、関連情報も同時に失われてしまう問題である。
例えば、以下の状況を考える。
- 学生4が所属していたサークルが廃部となり、そのサークルに関するデータを削除。
- 学生4の情報も同時に削除されてしまう。
このような問題を防ぐために正規化を行う。
第2正規形とは
第2正規形(2NF)は、以下の条件を満たす関係の形である。
- 関係が第1正規形(1NF)である。
- 候補キー以外のすべての属性が、候補キーに完全関数従属している。
完全関数従属性とは、属性が候補キー全体に依存し、その一部には依存しないことを意味する。
第2正規形への正規化の例
以下に、正規化の手順を具体例で説明する。
元の関係
以下の関係 R があるとする。
| A | B | C | D |
|---|---|---|---|
| 1 | 1 | X | Z |
| 1 | 2 | Y | W |
- 関数従属性:
B → D - 候補キー:
AB
B → D により、D が B に部分関数従属している。このため、この関係は第2正規形ではない。
第2正規形への正規化手順
部分関数従属する属性を分離=
部分関数従属する属性 D を元の関係から取り除き、新たな関係を作成する。
-
関係R1:
R1(A, B, C)A B C 1 1 X 1 2 Y -
関係R2:
R2(B, D)B D 1 Z 2 W
第2正規形の効果
修正不整合の防止
例えば、D の値を変更する場合、元の関係 R(A, B, C, D) では、D の値を含むすべてのタプルを修正する必要がある。一方、正規化後の R2(B, D) では、該当する1つのタプルを修正するだけで済む。
データの独立性向上
正規化により、属性が適切な関係に分離され、データの冗長性が減少する。
第三正規形の定義
関係 R が第三正規形にあるためには,以下の条件を満たす必要がある:
- 関係 R が第二正規形である。
- すべての関数従属性 X→A が以下のいずれかを満たす:
- X が超キーである。
- A が候補キーを構成する属性である。
推移的関数従属性が存在する場合,関係は第三正規形ではない。この場合,正規化を行い推移的関数従属性を解消する必要がある。
関係と関数従属性
| 学生番号 | 学生名 | 学科名 | 学科長 |
|---|---|---|---|
| 1 | A | A学科 | X |
| 2 | B | B学科 | Y |
| 3 | C | A学科 | X |
関数従属性:
- 学生番号 → 学生名,学科名,学科長
- 学科名 → 学科長
この関係には,学生番号 → 学科名 → 学科長 という推移的関数従属性が存在するため,第三正規形ではない。
第三正規形への正規化
推移的関数従属性を解消するために,関係を分解する。
分解後の関係
- 学科(学科名,学科長)
- 学生1(学生番号,学生名,学科名)
分解後の表
学科
| 学科名 | 学科長 |
|---|---|
| A学科 | X |
| B学科 | Y |
学生1
| 学生番号 | 学生名 | 学科名 |
|---|---|---|
| 1 | A | A学科 |
| 2 | B | B学科 |
| 3 | C | A学科 |
正規化の効果
非第三正規形では,同じ学科に所属するすべての学生のタプルに学科長の情報が格納されている。そのため,学科長を更新する場合,複数のタプルを修正する必要がある。これにより修正不整合が発生する可能性がある。
第三正規形に正規化することで,学科長は「学科」関係の一つのタプルにのみ格納される。そのため,修正不整合が解消され,データの一貫性が保たれる。
ボイスコッド正規形(BCNF)の例
科目担当(科目,学科,先生)
| 科目 | 学科 | 先生 |
|---|---|---|
| DB | A学科 | X |
| OS | B学科 | Y |
関数従属性:
-
科目,学科 → 先生
-
先生 → 学科
-
先生 → 学科は超キーではないため、ボイスコッド正規形にはならない。
-
分解後の関係:
- 科目(科目,先生)
- 所属学科(先生,学科)
第四正規形(4NF)の例
関係:学生(学生名,サークル名,科目名)
| 学生名 | サークル名 | 科目名 |
|---|---|---|
| A | X | DB |
| A | X | OS |
| A | Y | DB |
| A | Y | OS |
| B | X | DB |
| B | Y | DB |
| C | Z | SE |
関数従属性
-
学生名 →→ サークル名 | 科目名
-
多値従属性があるため、第四正規形ではない。
-
分解後の関係:
- 学生-サークル(学生名,サークル名)
- 学生-科目(学生名,科目名)
分解後:
学生-サークル:
| 学生名 | サークル名 |
|---|---|
| A | X |
| A | Y |
| B | X |
| B | Y |
| C | Z |
学生-科目:
| 学生名 | 科目名 |
|---|---|
| A | DB |
| A | OS |
| B | DB |
| B | DB |
| C | SE |
トランザクション管理
「トランザクション」とは、不可分の一連の処理の単位である。例えば、銀行のATMにおける「振込」「預入」「引出」「残高照会」などが該当する。振込のトランザクションは、以下の2つの処理からなる。
- 振込元の口座からの出金
- 振込先の口座への入金
この2つの処理のどちらかが失敗すると、残高に不整合が発生してしまう。トランザクション管理機能は、一つ一つのトランザクションやデータベースの操作履歴を管理し、障害発生時に備える機能である。
同時実行制御のないトランザクションの例
以下は、銀行口座から1万円を引き出すトランザクションの処理順序を示した例である。
| 処理順序 | 処理内容 | 口座残高 |
|---|---|---|
| 1 | 利用者Aが口座の残高を取り込む | 10万円 |
| 2 | 利用者Bが口座の残高を取り込む | 10万円 |
| 3 | 利用者Aが1万円引き出し、残高更新 | 9万円 |
| 4 | 利用者Bが1万円引き出し、残高更新 | 9万円 |

利用者AとBがほぼ同時に操作を実行した場合、残高は本来8万円であるべきだが、誤って9万円となり不整合が発生する。これは処理順序3の実行結果が処理順序4の実行結果に上書きされることで生じる結果となる.
同時実行制御
同時実行制御は、複数のトランザクションが同時に処理される場合において、処理順序が適切でないと問題が発生するのを防ぐための機能である。例えば、複数の利用者が同時に一つのデータベースに対して操作を行う場合でも、データベースの整合性を保つためには、適切な順序で処理を実行することが必要だ。
同時実行制御が必要な例
例えば、2人の利用者が同じ銀行口座から各1万円を引き出す操作を、まったく独立にほぼ同時に実行する場合を考える。引き出し処理は、以下の2つの処理からなる。
- a. DBから口座の現在の残高を取り出してプログラムに取り込む
- b. 現在の金額から1万円を引いた金額を算出し、DBに書き込む
口座残高が10万円として、この処理を以下の順で実行すると、不整合が発生する。
- 利用者Aが a の処理を行う(残高「10万円」が取り込まれる)。
- 利用者Bが a の処理を行う(残高「10万円」が取り込まれる)。
- 利用者Aが b の処理を行う(「9万円」がDBに書き込まれる)。
- 利用者Bが b の処理を行う(「9万円」がDBに書き込まれる)。
結果として、残高は本来8万円であるべきだが、誤って9万円となり不整合が発生する。このような問題を防ぐために、同時実行制御が必要である。
同時実行制御の方法
-
トランザクション分離レベル: トランザクションが他のトランザクションからどれだけ隔離されるべきかを定義する。これにより、同時実行時のデータの整合性を保つことができる。具体的には、以下の分離レベルがある。
- Read Uncommitted: 他のトランザクションがコミットしていないデータも読み込む。
- Read Committed: 他のトランザクションがコミットしたデータのみを読み込む。
- Repeatable Read: 同じデータを複数回読み込む際に、その間にデータが変更されないことを保証する。
- Serializable: 最も厳格な隔離で、トランザクションが直列に実行されたかのように扱う。
-
ロック(Locking): データに対して同時にアクセスできないようにする方法。例えば、利用者Aが口座の残高を引き出す際にその口座データをロックし、利用者Bはその処理が終わるまで待機する。
-
共有ロック(Shared Lock): 他のトランザクションがデータを読み取ることはできるが、変更はできないロック。例えば、振込処理中に口座残高を確認するトランザクションが共有ロックを使用し、他のトランザクションは読み取りだけできる。
-
専有ロック(Exclusive Lock): 他のトランザクションがデータを読み取ったり、変更したりできないロック。出金処理を行う際に専有ロックをかけることで、他のトランザクションが同時に同じデータを変更できないようにする。
-

相反グラフ(Conflict Graph)
- 直列化可能な実行計画かを判定するために利用
- ノード: 各トランザクション
- アークの設定条件:
(1) Tがwrite(Q)の後にSがread(Q)
(2) Tがread(Q)の後にSがwrite(Q)
(3) Tがwrite(Q)の後にSがwrite(Q) - 作成されたグラフ内にループが存在しない場合、直列化可能
相反グラフの例
- 例1: ループが存在する(直列化可能ではない)
T1 → T2
↑ ↓
T3 ← T4
- 例2: ループが存在しない(直列化可能)
T1 → T3 → T4
T2 → T4
2相ロッキング(Two-Phase Locking)
- ロックとアンロックの操作で直列化可能性を保証
- 手順:
(1) 成長相: すべてのロック操作を行う
(2) 縮退相: アンロックを行うが、以降のロック操作は禁止 - 例:
トランザクションT1:
t1: Xをロック
t2: XをREAD
t3: X-1をWRITE
t4: Yをロック
t5: YをREAD
t6: Y+1をWRITE
t7: Xをアンロック
t8: Yをアンロック
t9: コミット
デッドロック(Deadlock)
- 複数のトランザクションがロック解除を待ち続ける状態
- 検出方法:
(1) タイマーで待ち時間を監視
(2) 待合せグラフのループを確認 - 処置:
- デッドロック関係にあるトランザクションの1つを強制終了(ロールバック)
保守的2相ロッキング(Conservative Two-Phase Locking)
- トランザクション開始時にすべてのロックを取得
- 実行途中のロック・アンロック操作は禁止
- 安全だが効率が悪い
- 例:
トランザクションT1:
t1: Xをロック
t2: Yをロック
t3: XをREAD
t4: X-1をWRITE
t5: YをREAD
t6: Y+1をWRITE
t7: Xをアンロック
t8: Yをアンロック
t9: コミット
障害回復管理
データベースに障害が発生した場合、迅速な復旧が求められる。障害発生時にデータベースを迅速に回復させるためには、障害回復管理機能を活用することが重要だ。
障害回復には主に2つのアプローチがある。
-
ジャーナリング(Logging): データベースの変更操作をログファイルに記録する方法。障害が発生した場合、このログを元に障害発生前の状態に復旧できる。例えば、銀行の振込トランザクションの場合、振込元口座から出金した操作が完了する前に障害が発生した場合、その操作をログに記録しておき、障害後に振込元口座に対する出金処理を再実行することができる。
-
バックアップとリストア(Backup and Restore): 定期的にデータベースのバックアップを取得し、障害発生時にはそのバックアップを用いてデータを復元する方法。バックアップはフルバックアップと増分バックアップに分かれ、障害が発生する前の状態にリストアできる。
障害回復の例
銀行の振込トランザクションを例に取ると、以下のシナリオを想定する。
- 振込元の口座からの出金処理: 口座Aから1万円を引き出す。
- 振込先の口座への入金処理: 口座Bに1万円を入金する。
しかし、出金処理が完了する前にシステム障害が発生したと仮定する。出金処理はログに記録されているため、障害回復後、ログを使用して出金処理を再実行し、振込先口座への入金が完了していないことが確認された場合は、入金処理を再実行する。
この処理は以下の2つの処理に大別できる.
-
ロールバック(Rollback): トランザクションが途中で失敗した場合、または不整合が発生した場合、トランザクションを開始前の状態に戻すことで整合性を保つ。たとえば、振込の出金処理が失敗した場合、その前の状態に戻して処理をやり直す。
-
ロールフォワード(Rollforward): 障害が発生した後、記録されたログを基に処理を再実行して、データベースを最新の状態に戻す。たとえば、出金処理が完了していない場合、ログを参照して再度出金処理を実行する。
以下に矢印を1つのトランザクションとした際にどの地点でコミット(処理の確定)をしたかによって障害回復方法は異なる.

また、もしデータベース全体に重大な障害が発生した場合は、定期的に取られているバックアップからデータベースを復元することができる。
障害復旧方法: シャドーページ方式
- 現在のデータ(カレントページ)を別の領域(シャドーページ)にコピー
- データ更新後、トランザクションが正常終了した段階で反映
- トランザクション異常終了時:
- カレントページを破棄し、シャドーページを利用
- 問題点:
- 2種類のページ管理に伴うオーバーヘッド
- 制御の複雑化
シャドーページ方式の概念:
ディスク上のデータページ構造
- ページ1, ページ2, ページ3, ページ4, ページ5
- 更新操作時: カレントページが新たな領域にコピー
- 更新後: カレントページとシャドーページでポインタを切り替え
- 例:
- カレントページ: 更新後の最新情報
- シャドーページ: 更新前の情報(参照されない)
障害へのその他の対応策:
二重化 (冗長化)
- 対象: コンピュータ, ネットワーク, 磁気ディスク, データベース
- 方法:
- 同時に両方のシステムを更新し、データの整合性を確保
- メリット:
- 一方が故障しても他方で継続運用可能
RAID(Redundant Arrays of Inexpensive Disks)
- 複数のHDDを1台として仮想化
- 各レベルの特徴:
- RAID 0: 分散書き込み、速度向上(冗長性なし)
- RAID 1: ミラーリング(二重化、耐障害性向上)
- RAID 10 (RAID 0+1): 高速性+耐障害性
- RAID 5: 分散パリティ記録(容量は台数-1台分)
- RAID 6: 複数パリティ記録(RAID 5より高耐障害性)
チェックポイント設定:
- メモリ上のバッファを定期的にディスクへフラッシュ
- 適切なタイミングで設定することで性能と耐障害性を両立
機密保護管理
データベースには、個人情報や機密情報が含まれることが多いため、これらの情報が流出しないように、DBへのアクセスを制限・管理する機能が必要だ。これにより、第三者による不正アクセスや改ざんからデータベースを保護することができる。
データベース管理者
データベース管理者(DBA)は、データベースの管理を担当する人物であり、スキーマの定義や変更、ユーザー管理、アクセス権の設定などを行う。
レコードとファイルの基本概念
レコード
- データの格納単位として、レコードは1件のデータを表す。フィールド(タプルの属性に対応)はレコードにおける各項目に相当する。
- 論理レコードは、人間にとって意味のあるフィールドの集まりを指す。通常、「レコード」という場合、論理レコードを意味する。
- 関係におけるタプル(表における行)に相当する。
- レコードは、固定長レコード(CHARやINT型のみから成る)と可変長レコード(TEXT型など、長さが可変のフィールドを1つでも持つ)が存在する。
- 物理レコードは、計算機が読み書きするデータの単位である。1つの物理レコードには複数の論理レコードが格納されることがある。
ファイル
- ファイルは、複数の均一なレコードから構成される。通常、1つの関係(表)が1つのファイルに対応する。
- ファイルシステムの「ファイル」とは必ずしも一致しない。複数の表をまとめて1つの「ファイル」として扱うDBMSもある。
ファイルへのアクセス方法
ファイルにアクセスする方法は基本的に以下の3種類である。
1. 順次(シーケンシャル)アクセス
- ファイルの先頭から順番に処理する方法である。この方法は、紙テープ、パンチカード、磁気テープに適している。
- アクセス先を探す時間が不要であるが、アクセスするデータが後ろにあるほど低速である。
2. 直接(ランダム)アクセス
- 特定のレコードを直接処理する方法である。ハードディスク、フラッシュメモリに向いている。
- 速度はデータの位置によらず、アクセス先の計算に一定の時間を要する。
3. 動的アクセス
- 順次アクセスと直接アクセスを組み合わせたものである。光ディスクに向いている。
- チャプタや曲の先頭まで直接アクセスして、そこから順次アクセスする。
ファイルの編成方法
(1) 順次編成(シーケンシャル)ファイル
- ディスク上にレコードが順序通りに作られる編成である(テープのイメージ)。
- 特定のレコードを読むには、現在読んでいる場所から順番に読み進める必要がある。
- 場合によっては、巻き戻しが必要である。
(2) 直接編成(ランダム)ファイル
- レコードをある単位ごとにディスクの特定の場所に格納し、格納アドレスを直接指定することで読み書きが可能になる。
- 格納アドレスは通常、レコードのキーの値から計算で求める。
(3) 索引編成ファイル
- 索引(インデックス)を付加し、キーから直接アクセスして順次アクセスする編成である。
- レコードが格納される場所のアドレスを索引に格納しておく。
ページ
関係データベースでは、タプル(レコード)単位で磁気ディスクに格納することは通常行わない。タプルサイズが小さいと大量のディスクアクセスが発生し、応答時間が増加するためである。
- データベースを磁気ディスクに格納する単位はページ単位である。
- ページは、1K、4K、8Kバイトなどに設定された固定長の物理レコードである。
- ページには、ページ番号という一意にアクセス可能な番号が設定されている。
バッファリング
- 磁気ディスクへのアクセス回数を減らすために、バッファリング(キャッシング)が行われる。
- 磁気ディスクから一度取り出されたページは、メモリ上のバッファ領域に格納される。
- 2回目以降の同じページの処理要求に対しては、バッファ領域から読み込むことで、磁気ディスクへのアクセスを不要にする。
RDBMSにおけるファイル編成
タプル(レコード)をページに割り当てる方式をファイル編成と呼び、いくつかの異なる方式が存在する。主なファイル編成の種類には以下のものがある。
- ヒープファイル(順次編成ファイル)
- ハッシュファイル(直接編成ファイル)
- 索引付きファイル(索引編成ファイル)
ヒープファイル
ヒープファイルは、ページ内にレコードを順次格納した形式である。
- 挿入処理: 空きがあればページ内に新しいレコードを追加し、空きがない場合には新しいページを作成して格納する。
- 削除処理: 該当するレコードを削除するだけで、ページ内に空きができる。
- 利点: 格納効率が良く、シンプルである。
- 欠点: キー値による検索ができず、順番にレコードを調べる必要がある。

ハッシュファイル
ハッシュファイルは、レコードのキー値をハッシュ関数を使って変換し、バケット(ページ)を決定して格納する形式である。
- 検索処理: ハッシュ関数を使用してバケットを決定し、そのバケット内のページを探索することでレコードを高速に検索することができる。
- 挿入処理: ハッシュ関数を使ってバケットを決定し、該当するバケットに格納する。バケットに空きがない場合は、オーバーフロー処理を行う。
- オーバーフロー処理: コンフリクト(同じハッシュ値を持つレコード)が発生した場合には、追加の領域を設定して処理を行う。

ハッシュ関数の例
- キーの値を素数で割った余りを使用する。
- キーを2乗して中央の何桁かを使用する。
- キーを16進数に変換し、下位何桁かを使用する。
索引付きファイル
索引付きファイルは、データページと索引ページから構成される。データページには実際のレコードが格納され、索引ページにはデータページの先頭のキー値とそのポインタが格納される。
- 検索処理: 索引ページを探索して該当するデータページを特定し、そのデータページから必要なレコードを取得する。
- 範囲検索: 索引を使うことで範囲検索を効率的に行うことができる。
- 欠点: 動的なタプルの追加への対応が困難であり、再構築が必要となる場合がある。

B木の基本構造と操作について
データベースで使用されるB木は、レコードを効率的に格納し、検索や挿入・削除の性能を向上させるためのデータ構造である。以下にB木の基本構造と操作について解説する。
B木の特徴
- バランス木: B木の高さ(根から葉までのノード数)は一定である。この性質によって効率的な検索が可能となる。
-
ノード構造:
- 葉以外のノードは
k個のレコードとk+1個の下位ノードへのポインタを持つ。 - 根以外のノードのレコード数は
d≦i≦2dの範囲、根ノードのレコード数は1≦j≦2dの範囲である。
- 葉以外のノードは
-
容量: 1ノードには最大
2d個のレコードを格納できる。dを次元として、d次のB木と呼ぶ。 -
内部構造:
- レコードはキーとデータで構成され、ノード内ではキーでソートされる。
- レコードの間に下位ノードへのポインタを配置する。
二分木との比較
- 二分木: 1つの値と2つのポインタを持つ。主にメモリ上で使用され、アクセス回数が問題にならない場合に適する。
- B木: 複数の値とポインタを持ち、1ノードが磁気ディスク上の1ページに対応するように設計されている。これにより、木の高さを抑え、ディスクアクセス回数を削減する。
B木の基本操作
参照(検索)
- 根ノードから開始し、キーを比較する。
- 一致しなければポインタを辿り、適切な下位ノードを調べる。
- 葉ノードまで辿り着いた場合、目的のキーが存在すればレコードを取得する。存在しない場合、そのB木には該当するキーがない。
22を参照する例

登録(挿入)
- 空のB木への登録: 最初のレコードは根ノードに格納する。ノードがいっぱいになった場合は分割を行い、中央値を新たな根ノードに移動させる。
- 空きのある葉への登録: 既存のノードに空きがあれば、該当ノードにレコードを追加する。
-
空きのない葉への登録:
- ノードを分割し、中央値を上位ノードに移動させる。
- 新たなノードにレコードを格納し、ポインタを更新する。
-
葉にも上位ノードにも空きがない場合:
- ノードと上位ノードを分割し、中央値をさらに上位ノードに移動する。
- 根ノードも分割が必要な場合、新しい根ノードを作成し、木の高さが増える。
B+木と二次索引の概要
データベース管理システム(DBMS)において、B+木は最もよく用いられるデータ構造の一つである。以下では、B+木の特徴とその応用である二次索引について解説する。
B+木の特徴
順次アクセスとランダムアクセス
B木はランダムアクセスに適しているが、順次アクセスには不向きである。木構造をポインタで辿りながらアクセスしなければならず、効率が悪い。一方で、B+木はB木の特性を保ちながら、順次アクセスを高速化したデータ構造である。
構造
B+木の特徴的な構造は以下の通りである。
-
葉ノード
すべてのレコードは葉ノードに格納される。隣接する葉ノード間はポインタで結合されており、範囲指定検索や順次アクセスが効率的に行える。 -
非葉ノード
非葉ノードにはキー値のみが格納される。そのため、一つのノードに多くのキーを保持でき、木の高さが低くなる。これにより、ページアクセス数が減少する。
利用例
B+木は、レコードの高速な検索や範囲クエリにおいて効果を発揮する。このため、多くのDBMSで採用されている。
二次索引
二次索引の必要性
主キー(例: 学生番号)を用いる場合、B木やB+木により効率的にレコードを検索できる。しかし、主キー以外の列(例: 年齢)に関する条件が指定された場合、主索引だけでは効率が悪い。この課題を解決するために二次索引を利用する。
構造と仕組み
二次索引は以下のように設計される。
-
ポインタの利用
二次索引では、実際のデータではなく、主索引のデータへのポインタを格納する。例えば、「20歳の学生の氏名と学生番号を取得する」といったクエリの場合、二次索引に格納されたポインタを参照して主索引のデータを取得する。 -
複数ポインタの管理
二次索引のキー(例: 年齢)に対して複数のレコードが存在する場合、ポインタの集合として管理される。
問合せ最適化と効率的なデータベース処理
データベースにおける問合せ処理方法は複数存在し、それにより実行コストが大きく異なる場合がある。特に扱うデータが大規模になるほど、効率的な問合せ処理が重要である。この記事では、問合せ最適化の考え方と技術について解説する。
問合せ最適化とは
問合せ最適化とは、与えられた問合せに対して、最も効率的な処理方法を決定するプロセスである。ただし、最適化にかかる時間が長すぎると、その効果が相殺されるため、迅速な最適化が求められる。
以下に具体的な例を示す。
問合せ最適化の例
例えば、学生データを持つ以下のテーブルがあるとする。
学生(学生番号, 学生名, 年齢, 性別, 学科名)
これに対して、以下の問合せを実行する場合を考える。
SELECT *
FROM 学生
WHERE 学生名 = '田中太郎';
方法(1):全件検索
すべてのタプルを順に取り出し、条件を満たすか調べる。1万人の学生データがある場合、最大1万回のディスクアクセスが発生する。
方法(2):二次索引の利用
学生名に二次索引がある場合、その索引を利用して対象のデータを直接取得する。この方法では、索引アクセス+条件を満たす学生数分のディスクアクセスで済むため、大幅に効率化できる。
条件が複数ある場合
以下のように条件が複数ある場合の例を考える。
SELECT *
FROM 学生
WHERE 学科名 = '情報' AND 年齢 > 20;
方法(1):全件検索
すべてのタプルを取り出して条件を評価する。
方法(2):年齢の索引を利用
年齢の索引がある場合、まず「年齢」で絞り込み、条件を満たすデータについて学科名を調べる。
方法(3):学科名の索引を利用
学科名の索引がある場合、学科名で絞り込み、その後年齢を評価する。
方法(4):複合的な利用
両方の索引が利用可能であれば、年齢と学科名の索引を並行して処理し、結果を結合する。
問合せ最適化の手順
問合せ最適化は以下の手順で行う。
- 問合せを処理方法や順序を示す内部表現に展開
- 内部表現を効率的な処理が可能なように変換
- 内部表現から処理プランを生成し、実行
問合せ木の利用
問合せを木構造で表現することで、処理手順を視覚化できる。以下はその一例である。
π学生.学生番号, 学生名, 学科名
⋈学生.学科番号 = 学科.学科番号
σ学生名 = '田中太郎'
π学科番号, 学科名
学生 学科
上記の問合せ木では、選択演算(σ)を下方で行うことで、処理対象のデータ量を削減し効率を向上させる。
結合演算の効率化
データベース処理で最も時間を要するのは結合演算である。そのため、以下のような手法が用いられる。
入れ子ループ結合
基本的な結合法で、すべてのタプルを順に比較する。
for (int i = 1; i <= N; i++) {
for (int j = 1; j <= M; j++) {
// 条件を満たす場合、結合したタプルを出力
}
}
マージ結合
結合属性でソートした後に結合を行う方法。
- 結合対象をソート
- 両方のデータを順次比較しながら結合
索引を利用した結合
索引を用いて効率的に結合条件を満たすデータを取得する方法。
for (int i = 1; i <= N; i++) {
// 索引を利用して条件を満たすタプルを取得
}
ハッシュ結合
片方のデータをハッシュテーブル化し、もう一方と突き合わせる方法。
for (int j = 1; j <= M; j++) {
// ハッシュテーブルに登録
}
for (int i = 1; i <= N; i++) {
// ハッシュテーブルから条件を満たすタプルを取得
}
従来のクライアントサーバシステムとWebアプリケーションの構造
従来のクライアントサーバシステム
従来のクライアントサーバシステムは2層構造で構成されています。この構造では、以下のような特徴があります。
- クライアントアプリケーションはデータベースサーバに直接アクセスします。
- 業務データの処理をクライアント側で行うため、処理内容が変更されると、クライアントアプリケーションの修正が必要になります。
例えば、以下のような構成です:
クライアントアプリケーション | データベースサーバ
このような構造では、クライアントがデータベースに直接アクセスして業務処理を行いますが、システムの拡張性や保守性には限界があります。
Webアプリケーションにおける3層モデル
Webアプリケーションでは、通常、3層モデルを用いてシステムを構成します。これにより、柔軟な仕様変更や負荷分散が可能となります。
1. プレゼンテーション層(Webサーバ)
- ユーザインタフェースを提供する層です。
- Webサーバは、ユーザに表示するページを生成します。
2. アプリケーション層(アプリケーションサーバ)
- 業務データの処理を担当します。
- ビジネスロジックに基づいてデータを処理し、データベースに対する操作を指示します。
3. データ層(データベースサーバ)
- データベースを管理する層です。
- アプリケーションサーバからの指示に基づいてデータベース操作を行います。
例えば、以下のような3層のアーキテクチャになります:
クライアント(Webブラウザ / スマホアプリ) | プレゼンテーション層(Webサーバ) | アプリケーション層(アプリケーションサーバ) | データ層(データベースサーバ)
このアーキテクチャでは、各層が異なる役割を担っており、各層の変更が他の層に与える影響を最小限に抑えることができます。
JDBCプログラミングによるデータベース操作
Webアプリケーションからデータベースサーバへは、**JDBC(Java Database Connectivity)**を使用してアクセスします。JDBCは、Javaプログラムからデータベースにアクセスするための標準APIであり、特定のDBMSに依存しない点が特徴です。
JDBCの基本的な流れ
-
JDBCドライバのロード
JDBCを使用するためには、まずデータベースに対応したJDBCドライバをロードします。 -
データベースへの接続
ドライバをロードした後、データベースへの接続を確立します。 -
SQLの実行
接続後、SQL文を実行して、データベースからデータを取得したり、更新したりします。 -
結果セットの操作
SQL文の実行結果として返されるデータを処理します。 -
接続の解除
データベース操作が終了したら、接続を閉じてリソースを解放します。
JDBCを用いたサーブレットの例
次に、JDBCを使ってデータベースから学生情報を取得するサーブレットのコード例を示します。
public class StudentServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/html; charset=UTF-8");
PrintWriter out = response.getWriter();
out.println("<html><head><title>結果出力</title></head><body>");
Connection con = null;
Statement st = null;
ResultSet rs = null;
String login = "root";
String passwd = "";
try {
// JDBCドライバのロード
Class.forName("com.mysql.jdbc.Driver");
// データベースへの接続
String url = "jdbc:mysql://localhost/StudentDB?useUnicode=true&characterEncoding=UTF8&autoReconnect=true";
con = DriverManager.getConnection(url, login, passwd);
st = con.createStatement();
// SQL文の実行
String sql = "SELECT * FROM student;";
rs = st.executeQuery(sql);
// リザルトセットからデータを取得して表示
while (rs.next()) {
int id = rs.getInt("stuno");
String name = rs.getString("stu_name");
String gen = rs.getString("gender");
out.println(id + ":" + name + ":" + gen + "<br/>");
}
} catch (Exception e) {
out.println("<p>" + e.toString() + "</p>");
} finally {
try {
// 接続の解除
rs.close();
st.close();
con.close();
} catch (Exception e) {
// リソースの解放エラー処理
}
}
out.println("</body></html>");
}
}
-
JDBCドライバのロード
Class.forName("com.mysql.jdbc.Driver")でMySQLのJDBCドライバをロードします。 -
データベースへの接続
DriverManager.getConnection(url, login, passwd)で、指定したURL、ユーザー名、パスワードを使ってデータベースに接続します。 -
SQLの実行
st.executeQuery(sql)でSQL文を実行し、その結果をResultSetに格納します。 -
結果セットの処理
rs.next()で1行ずつデータを読み取り、rs.getInt("stuno")などで学生番号、名前、性別を取得します。 -
リソースの解放
最後に、データベースとの接続を閉じ、リソースを解放します。
Webアプリケーションにおけるデータベースの活用
多くのWebアプリケーションはその背後でデータベースを使用しており、例えば以下のようなデータベースが存在します:
- ユーザ管理用のデータベース
- ショッピングサイトの顧客情報データベース
- 商品情報や購買履歴を管理するデータベース
3層モデルを採用することで、次のような利点があります:
-
仕様変更や負荷分散に柔軟に対応可能
サーバを増設することで、システムの処理能力を向上させることができます。 -
データベースの変更が容易
業務処理の部分とデータベースが独立しているため、DBMSの変更がシステム全体に与える影響を最小限にできます。
JDBCを使ってデータベースにアクセスするため、Javaを用いたプログラミングが多くの場合に利用されますが、他のプログラミング言語にもそれぞれDBへのアクセス手段があります。