はじめに
リモートワークが中心になってきましたが、事務処理をしたりするために会社にいかなければならないこともありますよね。
私も、会社に届いた郵便物の処理を行うために出社したりすることがあります。
出社が当たり前だった頃は、文書箱に郵便物が届けられていましたが、リモートワークになると届いたのか分かりません。
また、リモートワーク中心になってフリーアドレス席が増えたのですが、社員の固定席が無くなり郵便物の届け先がないということになってしまいました。
そこで、総務の方が会社宛ての郵便物を受け取ったら、宛先人を自動で判別して本人に通知を送るシステムを開発します。
今回は、郵便物をOCRにかけ、宛名を抽出するところまでを行いましたので紹介します。
OCRには、Google Cloud Vision API、テキストから宛名を抽出するのにはGiNZAを使用しました。
本記事では、パワポで作成した郵便物サンプルをカメラで撮影した画像を使って試してみます。
※毛利探偵事務所の住所は都庁の住所にしています。

Google Cloud Vision APIを使ってOCRを行う
Vision APIは、画像を入力してオブジェクト検出や、文字検出を行うことができるAPIです。
今回使用するテキスト検出であれば、月1000ユニットまでは無料で使用できます。
Vision APIを使用できるようにする
Vision APIを使用するには、Google Cloudコンソール上でサービスアカウントとプロジェクトを作成する必要があります。
公式リファレンスの手順を参考に、サービスアカウントキーの作成までを行います。
PythonからVision APIを呼び出す
では、PythonからVision APIを呼び出してみます。
まずは、google-cloud-visionをインストールします。
$ pip install google-cloud-vision
先ほどダウンロードしたサービスアカウントキー(JSONファイル)のパスを環境変数に設定します。
# Linux or macOS
$ export GOOGLE_APPLICATION_CREDENTIALS="path/to/JSONファイル"
# Windows コマンドプロンプト
> set GOOGLE_APPLICATION_CREDENTIALS="path/to/JSONファイル"
リクエストは以下のように行います。
import io
import os
from google.cloud import vision
client = vision.ImageAnnotatorClient()
file_name = os.path.abspath('image.jpg')
with io.open(file_name, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.document_text_detection(
image=image,
image_context={'language_hints': ['ja']}
)
今回はテキスト検出を行いため、document_text_detectionを使用しています。例えば、顔検出を行いたいのであればface_detectionにします。
いくつかチュートリアルも用意されているので、自分にあったものを探してみてください。
実行するとresponseの中身は以下のようになっています。
フィールドがたくさんありますが、検出したテキストだけを使いたいのであれば、wordsの部分を使用します。
各フィールドについては公式ドキュメントを参照してください。
text_annotations {
locale: "ja"
description: "\343\200\222154-0004\n\346\235\261\344\272\254\351\203\275\344\270\226\347\224\260\350\260\267\345\214\272\345\244\252\345\255\220\345\240\2024-1-1\n\343\202\255\343\203\243\343\203\255\343\203\203\343\203\210\343\202\277\343\203\257\343\203\27424F\n\346\227\245\346\234\254\343\202\242\343\203\253\343\202\264\343\203\252\343\202\272\343\203\240\346\240\252\345\274\217\344\274\232\347\244\276\n\351\226\213\347\231\272\351\203\250 \344\274\212\350\227\244\351\226\213\345\217\270 \346\247\230\n\343\201\273\343\201\222\343\201\273\343\201\222\343\203\241\343\203\274\343\203\253\344\276\277\343\201\253\343\201\246\343\201\212\345\261\212\343\201\221\343\201\204\343\201\237\343\201\227\343\201\276\343\201\227\343\201\237\n(\351\203\265\344\276\277\343\203\235\343\202\271\343\203\210\343\201\253\346\212\225\345\207\275\343\201\227\343\201\252\343\201\204\343\201\247\344\270\213\343\201\225\343\201\204)\n-\343\201\212\345\261\212\343\201\221\343\201\253\351\226\242\343\201\231\343\202\213\345\225\217\343\201\204\345\220\210\343\202\217\343\201\233\345\205\210\344\270\200\n\343\201\273\343\201\222\343\201\273\343\201\222\343\203\241\343\203\274\343\203\253\344\276\277 0120-00-ABCD\n\345\217\227\344\273\230:9:00~18:00\nP1-07\n\350\253\213\346\261\202\346\233\270\345\234\250\344\270\255\n\345\270\235\346\204\233\343\202\260\343\203\253\343\203\274\343\203\227\346\240\252\345\274\217\344\274\232\347\244\276\n\343\200\222163-8001\n\346\235\261\344\272\254\351\203\275\346\226\260\345\256\277\345\214\272\350\245\277\346\226\260\345\256\2772\344\270\201\347\233\2568-1\nTEL: AB-CDEF-GHIJ"
bounding_poly {
vertices {
x: 179
y: 380
}
・・・
}
}
・・・
full_text_annotation {
pages {
property {
・・・
}
width: 4080
height: 3072
blocks {
bounding_box {
・・・
}
paragraphs {
bounding_box {
・・・
}
words {
bounding_box {
・・・
}
symbols {
bounding_box {
・・・
}
text: "5"
confidence: 0.9941741824150085
}
・・・
confidence: 0.9797465205192566
}
以下のようにして、wordsから検出テキストを取得します。
text = ''
for page in response.full_text_annotation.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
text += ''.join([
symbol.text for symbol in word.symbols
])
text += '\n'
textの中身
〒154-0004
東京都世田谷区太子堂4-1-1キャロットタワー24F
日本アルゴリズム株式会社
開発部工藤新一様
ほげほげメール便にてお届けいたしました
(郵便ポストに投函しないで下さい)
お届けに関する問い合わせ先一
ほげほげメール便0120-00-ABCD受付:9:00~18:00
P1-07
請求書在中
毛利探偵事務所
〒163-8001
東京都新宿区西新宿2丁目8-1
TEL:AB-CDEF-GHIJ
これで郵便物のOCRはできました。
spaCyとGiNZAを使用して宛名と差出人住所を抽出する
spaCyとGiNZAは自然言語処理を行うためのライブラリです。
OCRしたテキストに対してエンティティ抽出を行い、宛名と差出人住所を取得してみます。
GiNZAと日本語モデルをインストールしておきます。
$ pip install ginza ja-ginza
先ほど手に入れたOCRの結果を分析してみます。
エンティティ分析の結果は、doc.entsに入っているようです。
import spacy
nlp = spacy.load('ja_ginza')
text = <Vision APIで手に入れたテキスト>
doc = nlp(text)
for ent in doc.ents:
# エンティティ毎のテキストとエンティティ種別を出力
print(ent.text, ent.label_)
出力
〒154-0004
東京都世田谷区太子堂4-1- Postal_Address
キャロットタワー Flora
24F
ID_Number
日本アルゴリズム株式会社
Corporation_Other
工藤新一 Person
0120-00 Time
9:00 Time
18:00 Time
毛利探偵事務所 Company
〒163-8001
Postal_Address
東京都新宿区西新宿2丁目8-1
Time
AB-CDEF Sport
GHIJ Show_Organization
Jupyter Notebookであれば
from spacy import displacy
displacy.render(doc, style="ent", jupyter=Trus)
とすることで、可視化してくれます。
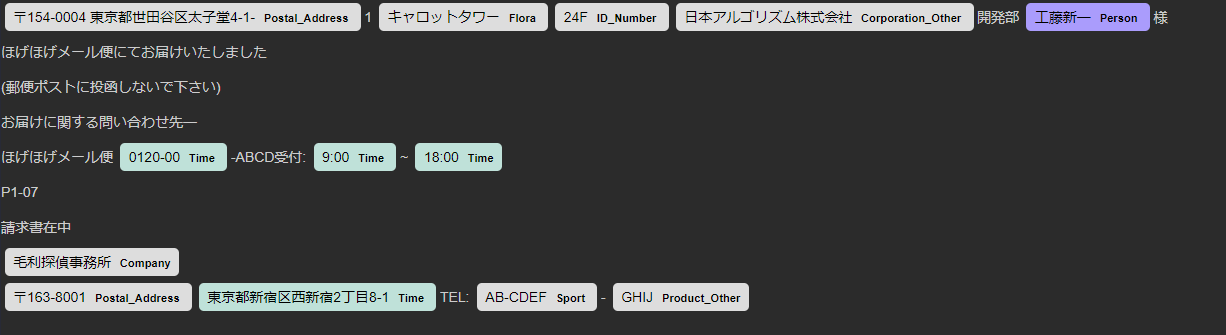
人名(工藤新一)のところにPersonというラベルがついていますね。これを抽出すれば宛名が取れそうです。
また、住所にはPostal_Addressというラベルがついていて、これも抽出できそうです。
ということで、宛名と住所を抽出してみます。
persons = [ent.text for ent in doc.ents if ent.label_ == "Person"]
addresses = [ent.text for ent in doc.ents if ent.label_ == "Postal_Address"]
print('persons', persons)
print('address', addresses)
# persons ['工藤新一']
# address ['〒154-0004\n東京都世田谷区太子堂4-1-', '〒163-8001\n']
と簡単に宛名と差出人住所を取得できました。ただし、宛先住所が切れてしまっているのと、複数抽出できてしまっているため、改善の必要があります。
おわりに
今回はGoogle Cloud Vision APIとGiNZAを使って、郵便物の宛名と差出人を抽出する方法を紹介しました。
次回は、宛先人に通知するまでをアプリケーションにしましたので紹介します。