はじめに
災害が発生した場合、ビジネスを継続するために、必要になるサービス
『AWS Elastic Disaster Recovery (DRS)』についてAWSがブログを投稿されていたので
このブログでさらに読みやすくなるように解説していきたいと思います。
想定される考慮事項
- 定期的なデータバックアップ以上のことが必要
- ビジネスの目標復旧時間 (RTO) を満たす完全なリカバリ
- データの処理に使用されるインフラストラクチャ、オペレーティングシステム、アプリケーション、および構成も含める
- ランサムウェアの脅威の増大に伴い、完全なポイントインタイムリカバリを実行できる環境の必要性
ランサムウェア攻撃の影響を受けた企業では、手動のバックアップからデータを復元するだけでは不十分です。
過去の対策での問題点
これまで、企業は物理的災害対策 (DR) インフラストラクチャを個別にプロビジョニングすることを選択していました。
- 要求されるまで、アイドル状態のままであるハードウェアや設備への投資
- スペースとコストの両方が法外になる可能性がある
- インフラストラクチャは、要求があった場合、現在のビジネス負荷は最初のプロビジョニング以降に大幅に増加している可能性がある
- これに対応できる状態にあることを確認するため、通常手動で行われる定期的な検査とメンテナンスに関するオーバーヘッドも発生
- テストが困難になり、コストも高い
AWS Elastic Disaster Recovery (DRS) について
AWS災害対策に基づく、物理的サーバー、仮想サーバー、およびクラウドサーバー向けの、完全にスケーラブルで費用対効果に優れたサービス
- 必要になるまでアイドル状態で、オンプレミスの DR インフラストラクチャに投資する必要がない
- AWS で弾力性のあるリカバリサイトとして使用
- オペレーティングシステム、アプリケーション、データベースのレプリケーションを常時維持
- 企業は、災害発生後、数秒の目標復旧時点 (RPO)、数分の RTO を達成
- 例えば、ランサムウェア攻撃の場合、DRS は以前の時点へのリカバリも可能にします
- 現在のセットアップに合わせて必要に応じて拡張できるリカバリを提供
- 準備状態を維持するために時間のかかる手動プロセスがいらない
- 災害対策読み取り演習を実施する機能
サービス機能について
- 物理的サーバー、仮想サーバー、またはクラウドベースのサーバーからブロックストレージボリュームを継続的に複製
- 数秒で測定されるビジネス RPO をサポートできる
- リカバリには、物理的インフラストラクチャ、VMware vSphere、Microsoft Hyper-V、および AWS へのクラウドインフラストラクチャで実行されているアプリケーションが含まれる
- サポートされている Windows および Linux オペレーティングシステムで実行される、すべてのアプリケーションとデータベースをリカバリ
- AWS 上のサーバーのリカバリプロセスを調整し、数分で測定される RTO をサポートします
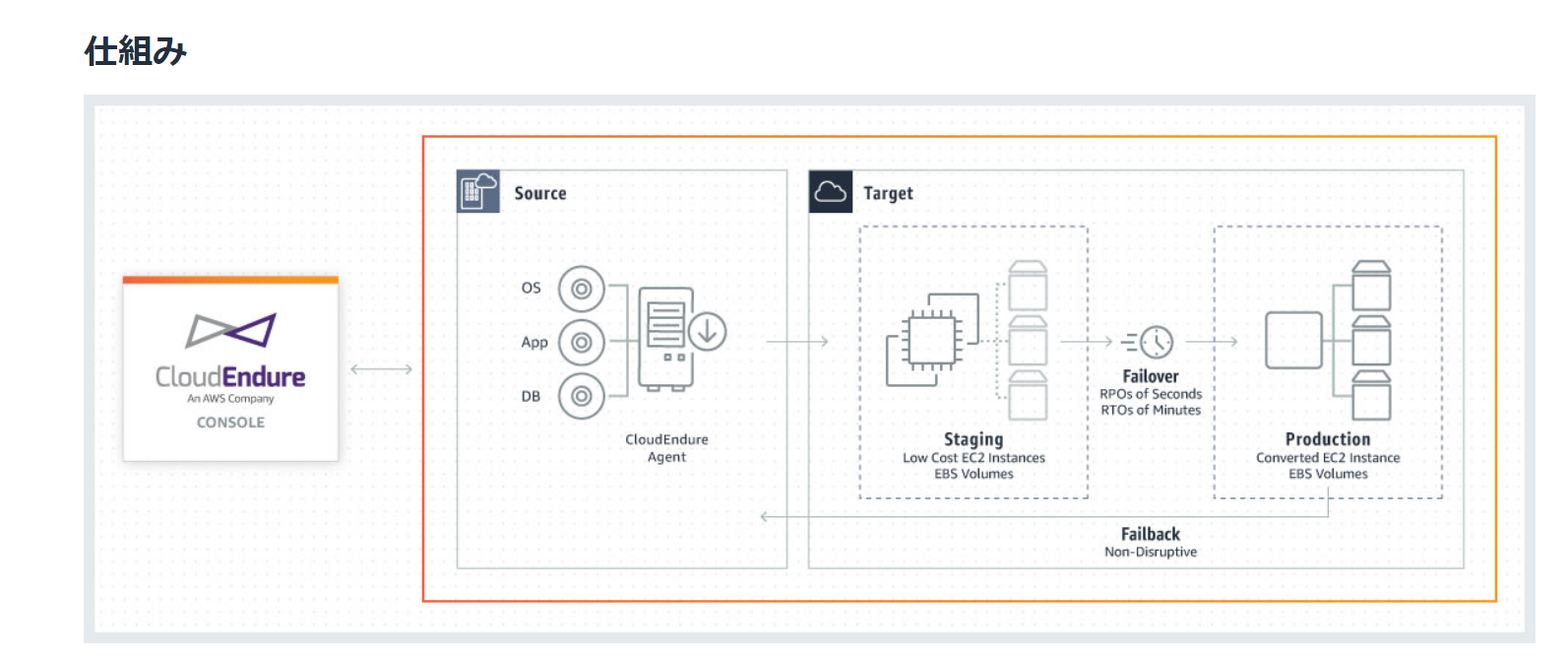
仕組みについて
- サーバーにインストールしたエージェントを使用
- AWS アカウント内の選択したリージョンのステージングエリアサブネットに、データを安全にレプリケート
- ステージングエリアサブネットは、手頃な価格のストレージと最小限のコンピューティングリソースを使用、コストを削減
- DRS コンソール内では、必要に応じて、別のAWS リージョンにある Amazon EC2 インスタンスをリカバリ
- DRS のレプリケーションとリカバリの手順を自動化してくれる
- 特別なスキルセットを必要とせずに、1 つのプロセスで災害対策機能をセットアップ、テスト、運用できます
コストについて
- 長期契約や一定数のサーバーを契約する必要がない
- オンプレミスまたはデータセンターのリカバリソリューションよりもメリットがある
- 従量制料金制で時間単位で課金されます。
さいごに
バックアップからの、データのリストアをテストすることが重要であるのと同様に、
継続的な複製やお客様のサービス利用に影響を与えることなく、コストパフォーマンスに優れた方法でリカバリ演習を実施できると
リカバリを依頼する必要がある場合に、目標とお客様の期待に応えることができますので積極的に使うべきサービスだと思います。
次回は軽くチュートリアルを実践していきますので、合わせてお読みいただければ幸いです。