Gemfile
gem 'capybara'
gem 'selenium-webdriver'
gem 'webdrivers'
rails_helper.rbかどっかに書く
Capybara.register_driver :headless_chrome do |app|
options = Selenium::WebDriver::Chrome::Options.new
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--window-size=800,600')
Capybara::Selenium::Driver.new(app, browser: :chrome, options: options)
end
Capybara.configure do |config|
config.default_max_wait_time = 15
config.default_driver = :headless_chrome
end
CircleCIのArtifactsを活用する
以下のArtifactsの収集を行うセクションを.config/circleci.ymlの中に用意しておくと、任意のディレクトリ内のファイルをビルド結果の画面から直接ブラウザで見ることができる。
# collect reports
- store_test_results:
path: /tmp/test-results
- store_artifacts:
path: /tmp/test-results
destination: test-result
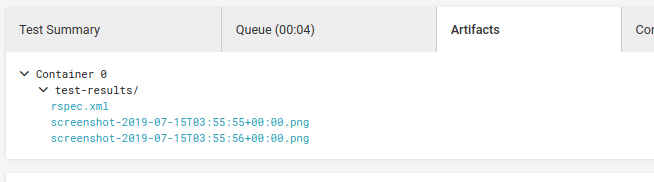
なのでCircleCI上でfeature specがコケた際のブラウザの画面をArtifactsとして収集するディレクトリへスクショとして放り込んでおくと、サクッとデバッグできてよい。わざわざSSHでコンテナに入る必要もない。
以下のような関数を用意しておくと便利
def take_screenshot
page.save_screenshot "/tmp/test-results/screenshot-#{DateTime.now}.png"
end
テスト例
RSpec.feature "User", type: :feature do
background do
create(:activated_user)
end
scenario 'can get logged in if activated' do
visit root_path
take_screenshot # 遷移直後にスクショをとる
click_on 'Log in'
expect(page).to have_content 'Login to Slip.it'
fill_in 'session_email', with: 'activated_user@example.com'
fill_in 'session_password', with: 'password'
click_on 'Login'
expect(page).to have_content 'Add a new bookmark'
end
end