素人が投稿サイトから情報をスクレイピングし、sqlite3で保存するまでのメモです。
雑談Slack Advent Calendar 2019 18日目の関連記事でもあります。
先人の多くの記事を参考にしました。
Beautifulsoup4で他の記事を検索されると、そちらのほうが詳しいでしょう。
やりたいこと
- 投稿のサムネイルページをみて、概要情報をDBに保存する。
- 必要があれば各投稿ページをみて、詳細な投稿情報をDBに保存する。
環境
- Windows10 Pro + Python3.7.1 x64 (BeautifulSoup4 , SQLite3)
対象ページの情報調査
スクレイピング対象のページから使えそうなテキストデータをピックアップします。
-
サムネイルページ
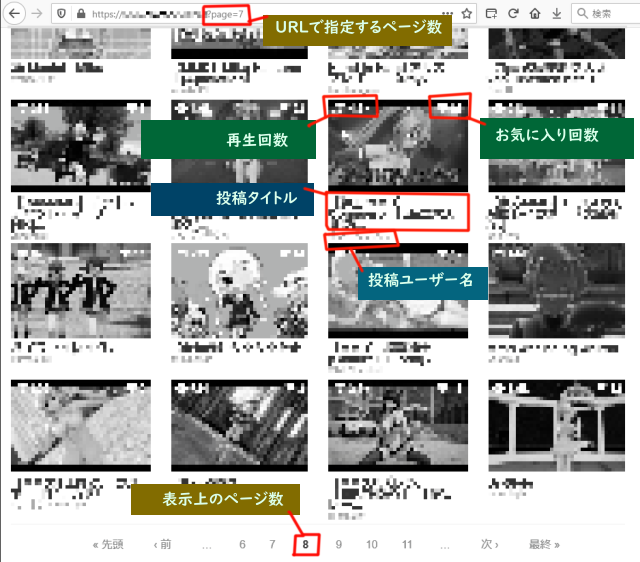
各投稿ごとに以下の情報が見えます。
- 投稿タイトル
- 投稿者名
- 再生回数
- お気に入り回数
-
投稿ページ
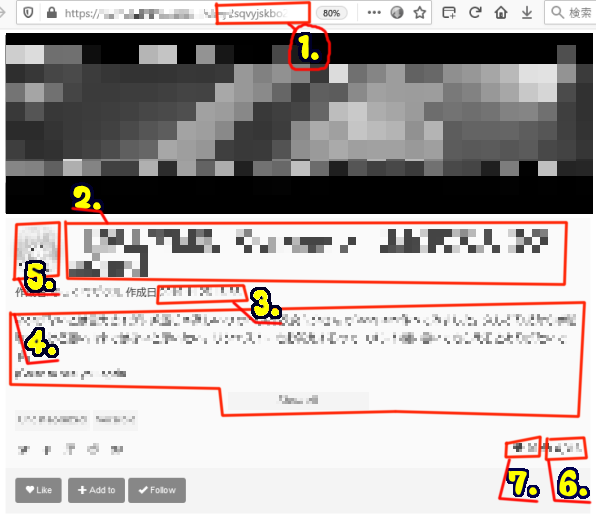
-
投稿ページURL
末尾はハッシュでしょうか。各投稿のユニークなキーとして使えそうです。 -
タイトル
サムネイルページでは15文字程度で"..."と切れていましたが、こちらではフル表示です。 -
投稿日時
新しい情報!ただ海外のサーバーなのに、最新記事から考えて日本時間で表示されています。アクセス者の時間帯を見て出力しているようです。 -
キャプション
投稿内容の説明など、投稿の主要な情報です。表示は「show all」で途中から隠れていますがHTML上では全テキストが最初から表示されていました。 -
投稿者アイコン
このアイコン画像にマウスカーソルを合わせると、_投稿者名_ のプロフィールのようにフルネームが表示されます。imgタグのALT属性ですね。下に投稿者名の欄がありますがそちらはサムネイルページと同様に10文字程度で"..."のように切れていました。 -
再生回数
サムネイルページでは、1000を超えると1.1K、100万をこえると1.1Mのように表示されていましたが、こちらでは細かい数字が読めます。 -
お気に入り回数
再生回数と同様です。
上記の他、投稿者アイコン画像のurlには__ユーザーのユニークID__が含まれていました。良く名前を変える投稿者が居るため、取得しておきます。
インストール
大体情報がみえたので、実行環境を用意します。
-
Python3.7
ライブラリurllibbeautifulsoup4sqlite3
D:\script> pip install urllib
D:\script> pip install beautifulsoup4
D:\script> pip install sqlite3
-
DBbrowser(SQLite3用)
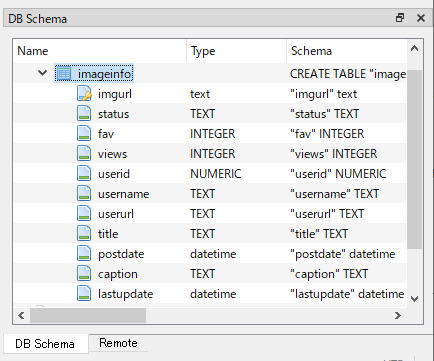
調査結果を参考にDBbrowserで次のようにテーブルを設計して"hogeimages.db"というファイル名で保存しました。
初期設定
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
import sqlite3,sys,os,json,re,datetime,time
# SQLite3のDB読み込み。
conn = sqlite3.connect("hogeimages.db")
conn.text_factory = str
csr = conn.cursor()
HTML取得
HTMLをBeautifulSoupでパースします
headers = {
"User-Agent": "Mozilla/今風のユーザーエージェント文字列をググレ",
}
# メイン処理
for page in range(0, 10):
#サムネイルURLの指定
url = "https://fushiginachikara.de/shinukotoninaru/images?page=" + str(page)
request = urllib.request.Request(url=url, headers=headers)
try:
html = urlopen(request)
except urllib.error.HTTPError:
#エラー処理などは最低限。一回待ちリトライし、だめならエラーを吐くに任せる。
print('page: '+ str(page) +' '+ url + '---HTTPERROR--- sleep 300sec...')
time.sleep(300)
html = urlopen(request)
#取得したHTMLを、BeautifulSoupでパース
bsThumbsPage = BeautifulSoup(html, "html.parser")
サムネイルページから情報抽出
BeautifulSoup4の機能を使い、HTMLタグ名・含まれるCSSのクラスやIDをターゲットとして抽出します。
ブラウザで対象ページのソース・F12のインスペクタをみて抽出タグ・クラスを考えます。
# タイトル、ユーザ名リスト取得
# サムネイルページのように、同じクラスで複数件の情報がある場合は「findAll」でリストとして取得できます。
titles = bsThumbsPage.findAll("h3", {"class":"title"})
users = bsThumbsPage.findAll("a", {"class":"username"})
#サムネの閲覧データ部取得
dat_bgs = bsThumbsPage.findAll("div", {"class":"dat-bg"})
#タイトル数とユーザID数と一致していれば各ページ取得
#壊れたデータを取得した場合を考え、エラーや個数の異常がある場合は抽出をスキップします。
if len(titles) == len(users):
for i in range(len(titles)):
usernameTb = users[i].string
viewsTb = dat_bgs[i].find("div", {"class":"left-dat views-icon"}).text
#抽出テキストからさらに詳細なデータを正規表現で抽出する場合は"re"などを利用します。
viewsTb = re.sub('[\t\n ]','',viewsTb)
favTb = dat_bgs[i].find("div", {"class":"right-dat likes-icon"})
imagehash = titles[i].a.get('href').replace('/images/', '').split('?',1)[0]
imageurl = 'https://fushiginachikara.de/shinukotoninaru/images/' + titles[i].a.get('href')
#飛び先URLは末尾に各種の引継ぎ情報を付与されている場合があり、不要なら削除します。
userUrl = 'https://fushiginachikara.de/shinukotoninaru/' + users[i].get('href').split('?',1)[0]
投稿内容詳細の取得を行うか判定
DBファイルに保存されているデータと照合します。
#取得済hashのチェック
csr.execute('select imgurl,status,fav,views,username,title from imageinfo where imgurl = ' + "'" + imghash + "'" )
dbdat = csr.fetchone()
if dbdat is not None :
#取得済の場合、投稿内容詳細ページを取得します。詳細は略。
投稿内容詳細ページから情報抽出
サムネイルページと大体同じ感じなので省略。書くのがめんどくなってきた。
取得データの保存
urllibでHTML取得した際、投稿日時はUTCでした。ここではdatetimeで決め打ち+9時間しています。
#更新時刻
lastupdate = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
#行リストROWデータ作成
#key = ('imgurl','status','userid','username','userurl','title','postdate','caption','lastupdate')
row = (imgurl,status,fav,views,userid,username,userUrl,title,postdate,caption,lastupdate)
#カラム名をキーにしてデータリストを辞書形式にする data=dict(zip(keys,row))
d=dict(zip(keys,row))
#一括更新
csr.execute('insert into videoinfo (imgurl,status,fav,views,userid,username,userurl,title,postdate,caption,lastupdate) values(:imgurl, :status, :fav, :views, :userid, :username, :userurl, :title, datetime(:postdate, "+9 hours"), :caption, :lastupdate)' , d)
conn.commit()
取得データの活用
DBに残すことで、SQLを使い様々なデータ活用が可能です。具体的には…
- 取得と同時に未チェックの投稿URLを一覧抽出、ブラウザのアドオンから開いて確認
- 削除された投稿の検知、あとから非公開解除された投稿の自動検知
- タイトル変更、ユーザー名変更の自動検知
- 再生回数、お気に入り数から人気投稿を自動抽出
- 気になるキーワードやキャプションを含む投稿を抽出
などです。
ちょっと困ったポイントと対応
- ユーザー名表示の文字数が制限で変わったりする
⇒関連ページのHTMLテキストを舐めて確実に取れそうな情報元を選ぶ - 各種項目内容NULLで投稿した場合にHTMLのタグやクラスが生成されない
⇒常に取得文字列is NULL判定を入れよう
まとめ
このスクリプトを書いたおかげで毎日1時間の作業がなくなり、
見たくない投稿者の投稿を間違えて開くこともなくなり、
無駄なタブ開きによる投稿サイトへのアクセス負荷も減りました。
(個人の感想です)
後にRaspbian busterのlinux上に移植しましたが
sqliteのファイル読込パスの書き方を修正するだけで動作しました。pythonすごーい。
参考になれば幸いです。