はじめに
2022/6/15(木)~2022/6/17(金)に開催されたMicrosoft OpenHackというイベントに参加する機会があったので、その振り返りとかを書きます。
今回参加したテーマは「AI-Powered Knowledge Mining」というもので、主にAzure Coginitive Searchを使い、AIパワーなどを借りてドキュメント検索を強化し、ユーザの使い勝手を上げていこうというものでした。
参加してどうだったか
先にこれを書きます。
楽しかったです。
数人のチームになって時間内にできるだけ多くのチャレンジを解いていくのですが、そのチャレンジ内容が実際の仕事でありそうな内容だったり、Microsoft公式のとっつきにくいドキュメントを解読しながらチームメンバーと試行錯誤して勧めていくのは日頃の業務とは全く違って新鮮でした。
チームでの作業の進め方もチームメンバーと決めていいのでやり方は自由です。
私のチームの場合は、チャレンジごとに画面共有担当を決めてAzureのリソース操作が必要な場合はその人に行ってもらい、他メンバーは個別に必要な情報を調べたり、コーチにチェックしてもらう用のPythonコードの準備を進めるようなスタイルでした。
行き詰まりそうになるとチームコーチがヒントをくれるので(「答え」はもらえません)、それをもとにまたネットで情報を調べてリトライするといった感じなので、どうしようもなくお手上げになることはありませんでした。
OpenHackについて
OpenHackはMicrosoftが主催しているハッカソンイベントです。(ハッカソンなるものにこれまで参加したことないので多分ですが)
テーマは8個くらいあるみたいで、多分テーマごとに開催されるみたいです。
はじめにでも書いた通り、今回は「AI-Powered Knowledge Mining」というテーマでした。
学んだことの備忘録
ここでは、このイベントでずっと触り続けたAzure Cognitive Searchについて理解したことを書いておきます。
Azure Cognitive Search
Azure Cognitive Searchは、Apache Luceneという全文検索エンジンをMicrosoftが独自にカスタマイズして、いろんなファイルを効率よく検索できるようにしてくれるサービスと理解しました。
検索対象のファイルは、Azure上のサービス(Azure BLOBストレージやCosmos DB)に格納されている必要があります。
このサービスを利用するにあたっては、以下の3要素の理解が重要です。
-
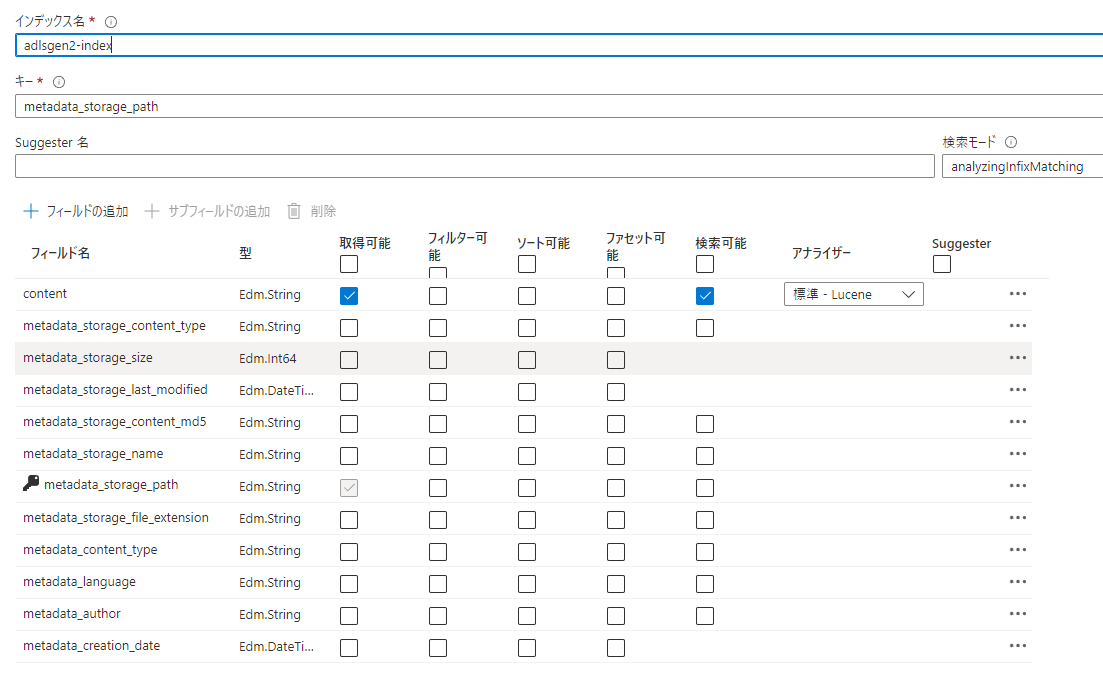
インデックス
情報を見つけやすくするための索引情報です。
ドキュメント本文や、ファイル名やファイルサイズなどのメタデータ、後述するスキルセットによってAIが特定のエンティティとしてラベル付けした単語などをインデックスとして利用できます。
インデックスは、事前にインデックスフィールドを定義しておきます。
このときに意識しておきたいことは、インデックスの型をどうするかということと、そのフィールドをどのように使うかということです。
フィールドの型については、インデクサーが取ってきたデータの型が一致していないと入れれないし、入れれても検索時に扱いずらかったりします。
フィールドをどのように使うかというのは、フィールドに取得可能や検索可能といったオプションがあり、これが入っていないと検索条件として使えなくて困ったりします。かと言って全フィールドのオプションを有効にすると不要なデータを開示することになり、また検索性能にも影響がでるので要件に合わせてちゃんと設定する必要があります。
-
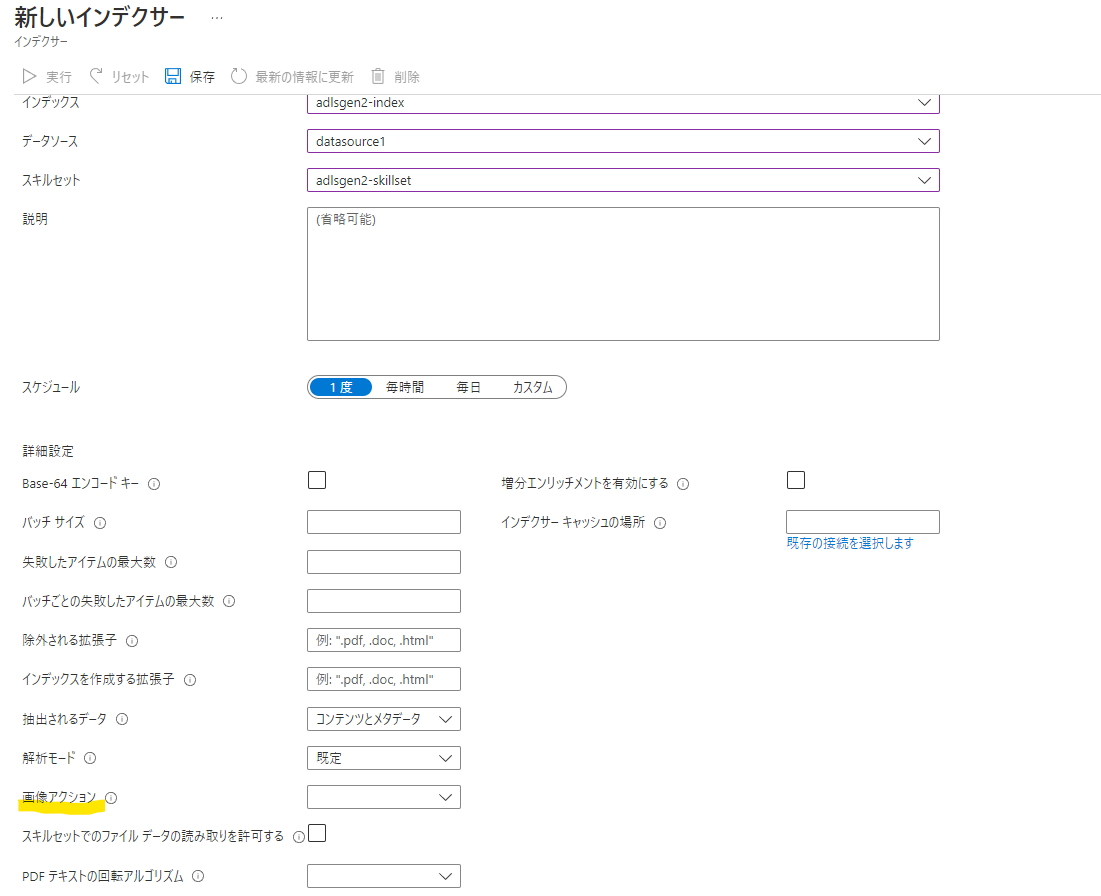
インデクサー
インデックスを作っていくクローラです。
インデクサーは、事前に設定した定義(対象のファイルが保存されたストレージや、解析された情報をどのインデックスフィールドに設定するかなど)に従いファイルを解析してインデックスを作っていきます。
1回だけ実行や、毎時、毎日実行など、実行頻度を設定することができます。なので、毎晩実行してインデックスを最新にしていくことなどもできます。
その他にも設定はあるのですが、画像アクションというものは、AIの力を借りてファイル中の画像から情報を抽出する場合は有効にしておく必要があります。
-
スキルセット
スキルセットを使用すると、インデクサーがファイルを解析して情報を抽出する際に、AIの力を借りて感情分析やエンティティラベル付け、ファイル内の画像から抽出された情報も抽出できるようになります。
スキルセットは、事前に用意された組み込みスキルと、独自に作成したカスタムスキルを利用することができます。
カスタムスキルは、REST APIが利用できるので、Azure Functionsで作った関数はもちろん、AWSのLambdaとAPI Gatewayで作成したAPIも呼ぶことができます。他にもAzure MLで作成した独自AIモデルの推論エンドポイントを呼んだりできます。
スキルセットはテンプレートが用意されているので、そこから必要なものを選び追加していくことができます。
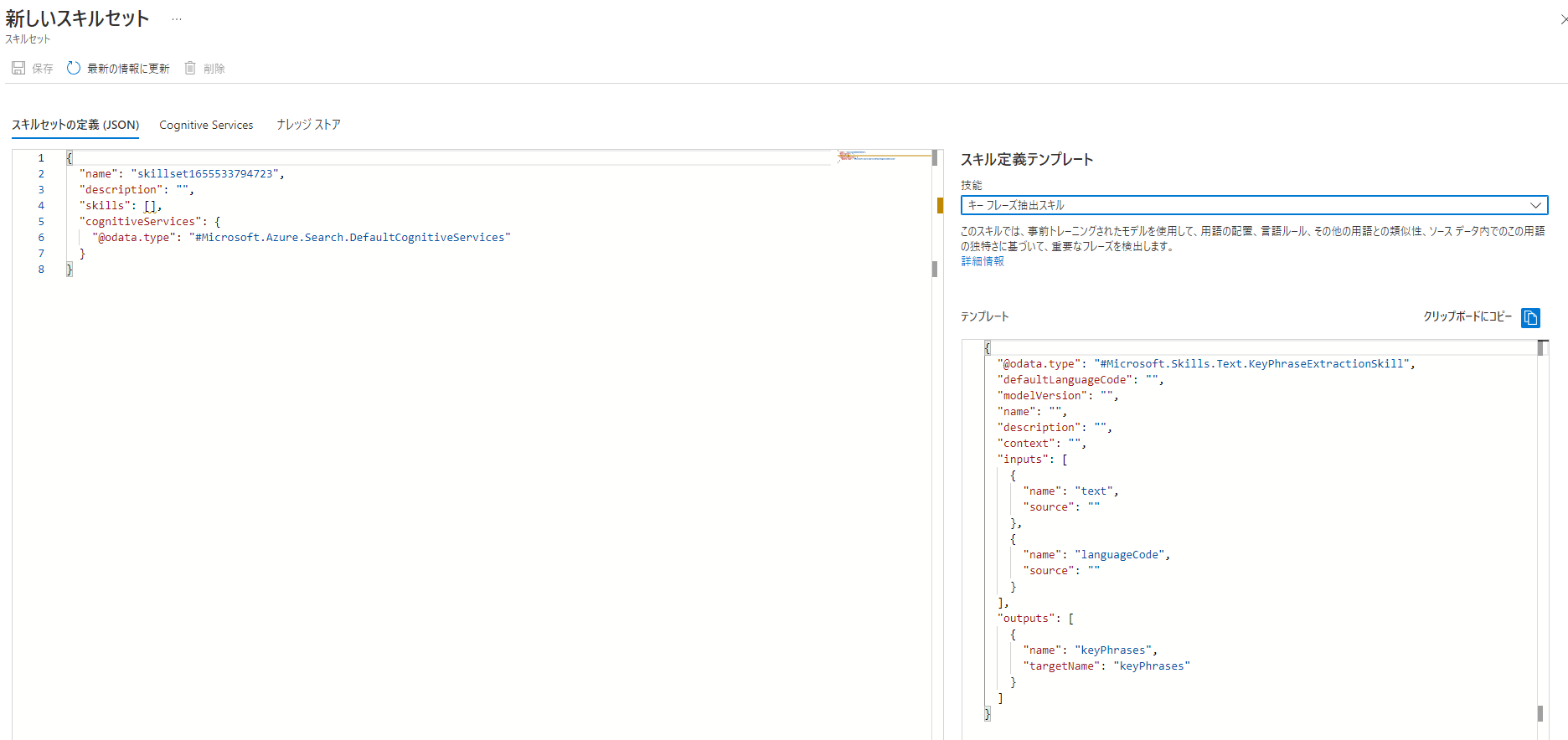
インデクサーやスキルセットを定義するなかで、contextというパラメータがあるのですが、これが最初は理解しづらいかもしれません。
インデクサーが実行されたときに抽出した情報をメモリ上に確保しておくときのツリー構造のパスがコンテキストです。
以下の記事が参考になります。
作成したインデックスを利用した検索
作成したインデックスに対する検索は、独自にクエリを組み立ててHTTPリクエストをGETかPOSTで投げるか、Azureが提供するSDKを利用する方法があります。
Pythonを利用していたのですが、最初にSDKを利用しようとしたのですが、サンプルに記載された情報が少なく諦めました。
以下の記事を参考に、RequestsモジュールでGETリクエストを書いて実行していました。
GETやPOSTでクエリを書く方法は公式ドキュメントに色々書いてるのでそれを参考にしました。
queryType=fullを指定することで、高度な検索ができるようになります。
また、フィルター機能を利用することで、searchで検索した結果を更に絞り込むことができます。
書き方が特殊で慣れていないと難しいです。また、コレクションタイプに対しては少し書き方に注意する必要があります。
いくつか例を書きます。queryType=fullでないと効かない書き方もあるので注意が必要です。
-
metadata_authorというファイル作成者のメタデータに'Jhon'というワードが含まれているというフィルタは
$filter=search.ismatch('John', 'metadata_author')
となります。
これは、SQLのlike句のようなもので、John、John Smith、Alexander Boris de Pfeffel Johnsonなどのインデックスがあれば引っ掛かります。 -
コレクションの空判定については、Roomフィールドが空(データが存在しない)というフィルタは
not rooms/any()
となります。
notを外せば、データが空でない(データが存在する)になります。
感想
Azure Cognitive Searchは、日々増えていく情報を整理するにあたりとても有用なサービスだと思いました。
機能もどんどん増えていっているようなので、より使いやすく細かいところまで手が届くサービスになっていくと思います。
チャレンジの中でPythonコードを書く場面もありましたが、プログラムのスキルはあまり必要ないです。
必要なのはチームメンバーとのコミュニケーション能力と、公式ドキュメントを理解する柔らかい頭です。
ハッカソン系のイベントとして最初に参加するにはちょうどいいレベルかと思いますので、気になる方はぜひ参加してみてはどうでしょうか?
最初に書きましたが、私はハッカソンというものに参加したことがなかったので、他がどうかは知りません😎
一緒のチームになった方とコーチに感謝!
小言
チャレンジを進めていて思ったことは、Azureの情報をインターネットで調べても公式ドキュメントばっかり引っかかって(公式ドキュメントが正なので検索結果としては正しいのですが)、Qiitaなどの技術記事が少なく詰みポイントの回避策を探すのが大変なことです。
AWSはいくつかサービスを触ったことはあるのですが、わからないことがあり調べると、大体先駆者の記事があり参考にすることができます。
これは利用しているユーザ層の違いがあるのかもしれません。
以下は、勝手な個人的なイメージです。
- AWSは、個人やスタートアップなどがMVPを作り、そこからサービスアウトしていくスタイルが多い。こういうフットワークが軽いユーザは、技術系記事も結構書く人が多い。
- Azureは、Microsoftが提供しているということもあり、もとからWindows製品やAD、Office365を導入している大きめの企業が、既存の資産を使ってDXを実現するために利用することが多い。こういう企業のユーザはフットワークが重い。そう私です🙄
頑張れマイクロソフト!