(23-5-10時点動作確認)
Introduction
人工言語界隈あるあるだと思うんですが、当然のように複数の言語を作った挙げ句文法が複雑すぎるなどの理由で昔作った言語の訳し方をすっかり忘れてしまうということがあります。
対訳を書いていないテキストを発見したときなどは最悪です。このままではこの世の誰も解読できない謎のテキストとして終わってしまいます。
そんなときは、AIの力を借りて翻訳機を作ってみましょう。
今回は、Facebookが提供する多言語モデル「M2M-100」をファインチューニングすることで、自作の人工言語を翻訳するモデルを作成します。
独自の言語でのコミュニケーションを快適にするため、ぜひこの記事を参考にしてみてください。
やり方
大正義Colab上でやりましょう。
編集→Notebookの設定からGPU設定にすることを忘れずに。
import torch
torch.cuda.get_device_name(0) # Tesla T4
事前準備
Train.csvを用意します。形式はこんな感じ。翻訳元, 翻訳先をテーブルとして並べていきます。
English,Tarotic
I am hungry.,Ame diabe maken.
I want to eat pizza.,Ame diabe Piza maken.
I need to go to the store.,Ame diabe ke kago kolesen.
...
Step 1:インストール
fairseqをGithubから落としてなんやかんや色々インスコします。
!git clone https://github.com/pytorch/fairseq -q
%cd fairseq
!pip uninstall numpy -q -y
!pip install wandb
!pip install --editable ./
%cd ..
その他、必要なデータをダウンロードします。
!wget -qq "https://dl.fbaipublicfiles.com/m2m_100/spm.128k.model"
!wget -qq "https://dl.fbaipublicfiles.com/m2m_100/data_dict.128k.txt"
!wget -qq "https://dl.fbaipublicfiles.com/m2m_100/model_dict.128k.txt"
!wget -qq "https://dl.fbaipublicfiles.com/m2m_100/language_pairs_small_models.txt"
!wget "https://dl.fbaipublicfiles.com/m2m_100/418M_last_checkpoint.pt"
各自説明すると、
- spm.128k.model - 知らん
- data_dict.128k.txt - 多分いろんな言語の単語をベクトル化した辞書みたいなもの
- model_dict.128k.txt - ↑に加えて言語コードがいくつか追加されている。ここの内容が少しでもおかしいと学習に失敗するので注意。
- language_pairs_small_models.txt - 対応している言語の表みたいな感じ。「翻訳元-翻訳先」をISO639-1形式で羅列してある。
- 418M_last_checkpoint.pt - 学習済みモデル。これをベースに追加学習していく
上記らのファイルは基本的に内容は弄りません。
Step 2:前処理
前処理を行っていきます。
! pip install sentencepiece -q
import pandas as pd
import torch
import numpy as np
import os
import random
def set_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.enabled = False
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
set_seed(7)
Taroticとなってる部分をあなたの言語名に変更して下さい。
PATH_TO_DATASET = "./" #Where you stored the dataset
train = pd.read_csv(os.path.join(PATH_TO_DATASET, "Train.csv"))
#Remove any possible duplicates
train = train.drop_duplicates(subset=["Tarotic", "English"])
#Lowercase and remove trailing spaces
train["Tarotic"] = train.apply(lambda x: (x.Tarotic).strip().lower(), axis=1)
train["English"] = train.English.apply(lambda x: x.lower())
train = train[["Tarotic", "English"]]
train.columns = ["input_text", "target_text"]
#Train 80% / Validation 20% Split
validation = train.sample(frac=0.2).astype(str)
train = train.drop(index=validation.index).astype(str)
train_txt = "\n".join(train.input_text.values.tolist())
file = open("tarotic_txt_train.txt", "w")
file.write(train_txt)
file.close()
train_target_txt = "\n".join(train.target_text.values.tolist())
file = open("english_txt_train.txt", "w")
file.write(train_target_txt)
file.close()
validation_txt = "\n".join(validation.input_text.values.tolist())
file = open("tarotic_txt_validation.txt", "w")
file.write(validation_txt)
file.close()
validation_target_txt = "\n".join(validation.target_text.values.tolist())
file = open("english_txt_validation.txt", "w")
file.write(validation_target_txt)
file.close()
ここまででtrainとvalの.txtデータを生成。
ひとつ注意点として、trainまたはvalのデータ数がこの後のtrain.pyで指定するバッチサイズ以下だと次のようなエラーが出ます。元train.csvが最低100行くらいあれば問題ないと思う。このエラーが出たらバッチサイズを下げるかデータを増やして下さい。
The dataset is empty. This could indicate that all elements in the dataset have been skipped.
次に辞書ファイルを作っていく。
!python fairseq/scripts/spm_encode.py \
--model spm.128k.model \
--output_format=piece \
--inputs=tarotic_txt_train.txt \
--outputs=train.tl
注意
train.tlとしている部分。ここの.XXには言語コードを書くわけですが、人工言語の場合、公式の言語コードは存在しませんね?しかし間違っても自作の言語コードにしないでください。無限にエラーになります。おとなしく既存のなんらかの言語のものを乗っ取りましょう。
今回はタガログにしてますが、自作の言語に近い言語を乗っ取った方がいいかもしれない。
この話は今後.tlと出る部分すべてのパートに言えます。
!python fairseq/scripts/spm_encode.py \
--model spm.128k.model \
--output_format=piece \
--inputs=english_txt_train.txt \
--outputs=train.en
!python fairseq/scripts/spm_encode.py \
--model spm.128k.model \
--output_format=piece \
--inputs=tarotic_txt_validation.txt \
--outputs=val.tl
!python fairseq/scripts/spm_encode.py \
--model spm.128k.model \
--output_format=piece \
--inputs=english_txt_validation.txt \
--outputs=val.en
最後に、fairseq-preprocessをかけてデータセットは完成。
!fairseq-preprocess \
--source-lang tl --target-lang en \
--trainpref train \
--validpref val \
--thresholdsrc 0 --thresholdtgt 0 \
--destdir data_bin \
--srcdict model_dict.128k.txt --tgtdict model_dict.128k.txt
出力が翻訳元/先ともに「[言語コード] Dictionary: 128112 types」になっていることを確認して下さい。数字が違う場合はmodel_dict.128k.txtがどっかしらおかしいので確認。再三繰り返しますが、存在しない言語コードを指定すると勝手にここに1行追加されるのでバグります。
Step 3: 学習
!mkdir checkpoint
!fairseq-train data_bin \
--finetune-from-model "418M_last_checkpoint.pt"\
--save-dir checkpoint \
--task translation_multi_simple_epoch \
--encoder-normalize-before \
--lang-pairs 'tl-en' \
--batch-size 10 \
--decoder-normalize-before \
--encoder-langtok src \
--decoder-langtok \
--criterion cross_entropy \
--optimizer adafactor \
--lr-scheduler cosine \
--lr 3e-05 \
--max-update 40000 \
--update-freq 2 \
--save-interval 20 \
--save-interval-updates 5000 \
--keep-interval-updates 10 \
--no-epoch-checkpoints \
--log-format simple \
--log-interval 2 \
--patience 10 \
--arch transformer_wmt_en_de_big \
--encoder-layers 12 --decoder-layers 12 \
--share-decoder-input-output-embed --share-all-embeddings \
--ddp-backend no_c10d \
--max-epoch 100 \
--wandb-project "Tarotic M2M"
細かい数値はお好みで調整してください。ちなみに--lang-pairs 'tl-en'としてありますが、tl-en,en-tlみたいな感じにすれば多分相互翻訳できるようになります。多分。実際に試してないのでしらんけど。
終わったらcheckpoint以下にモデルが生成されます。bestとlastがありますが、bestがロスが最も少なかったモデルでlastが最後のepochのモデルだと思います。基本bestを使えばいいはず。
Step 4: テスト
!rm -rf data_bin
!fairseq-preprocess \
--source-lang tl --target-lang en \
--testpref val \
--thresholdsrc 0 --thresholdtgt 0 \
--destdir data_bin \
--srcdict data_dict.128k.txt --tgtdict data_dict.128k.txt
!fairseq-generate "data_bin/" --batch-size 32 \
--path "checkpoint/checkpoint_best.pt" \
--fixed-dictionary model_dict.128k.txt \
-s tl -t en \
--remove-bpe 'sentencepiece' \
--beam 5 \
--task translation_multi_simple_epoch \
--lang-pairs language_pairs_small_models.txt \
--decoder-langtok \
--encoder-langtok src \
--gen-subset test > gen_out
gen_outという拡張子のないファイルが出力されますが、テキストとして読めるので開いて翻訳が正常に動作していることを確認して下さい。
Step 5: fairseqモデルをtransformerで使える形に変換
このままでも使えるっちゃ使えますが、できればTransformerで使いたいのでひと手間かけましょう。
#@title fairseqモデルをtransformerモデルにコンバート
import argparse
import torch
from torch import nn
from transformers import M2M100Config, M2M100ForConditionalGeneration
def remove_ignore_keys_(state_dict):
ignore_keys = [
"encoder.version",
"decoder.version",
"model.encoder.version",
"model.decoder.version",
"decoder.output_projection.weight",
"_float_tensor",
"encoder.embed_positions._float_tensor",
"decoder.embed_positions._float_tensor",
]
for k in ignore_keys:
state_dict.pop(k, None)
def make_linear_from_emb(emb):
vocab_size, emb_size = emb.weight.shape
lin_layer = nn.Linear(vocab_size, emb_size, bias=False)
lin_layer.weight.data = emb.weight.data
return lin_layer
def convert_fairseq_m2m100_checkpoint_from_disk(checkpoint_path):
m2m_100 = torch.load(checkpoint_path, map_location="cpu")
m2m_100_418M = torch.load("/content/418M_last_checkpoint.pt", map_location="cpu")
args = m2m_100_418M["args"]
state_dict = m2m_100["model"]
remove_ignore_keys_(state_dict)
vocab_size = state_dict["encoder.embed_tokens.weight"].shape[0]
print(f"418Mモデルのargs: {m2m_100_418M['args']}")
config = M2M100Config(
vocab_size=vocab_size,
max_position_embeddings=1024,
encoder_layers=args.encoder_layers,
decoder_layers=args.decoder_layers,
encoder_attention_heads=args.encoder_attention_heads,
decoder_attention_heads=args.decoder_attention_heads,
encoder_ffn_dim=args.encoder_ffn_embed_dim,
decoder_ffn_dim=args.decoder_ffn_embed_dim,
d_model=args.encoder_embed_dim,
encoder_layerdrop=args.encoder_layerdrop,
decoder_layerdrop=args.decoder_layerdrop,
dropout=args.dropout,
attention_dropout=args.attention_dropout,
activation_dropout=args.activation_dropout,
activation_function="relu",
)
state_dict["shared.weight"] = state_dict["decoder.embed_tokens.weight"]
model = M2M100ForConditionalGeneration(config)
model.model.load_state_dict(state_dict,strict=False)
model.lm_head = make_linear_from_emb(model.model.shared)
return model
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
model = convert_fairseq_m2m100_checkpoint_from_disk("/content/checkpoint/checkpoint_best.pt")
model.save_pretrained("/content/conlang")
ちょっとトリックを使ってます。というのは非常に意味が不明なことにcheckpoint_best.ptはargsの値が空っぽなのです。なので事前学習済データの方からパクってきます。これで問題なく動作します。
完了すると、model.save_pretrained()で指定したフォルダに見慣れたpytorch_model.binとconfig.jsonが出力されます。これでTransformer上で使えるようになりました。
Step 6: Transformer上で動かす
#@title Transformerでテスト
from transformers import M2M100ForConditionalGeneration, AutoTokenizer
import torch
model = M2M100ForConditionalGeneration.from_pretrained("/content/conlang")
tokenizer = AutoTokenizer.from_pretrained("facebook/m2m100_418M")
LANG_CODES = {
"English":"en",
"Tarotic":"tl"
}
def translate(text, src_lang, tgt_lang, candidates:int):
"""
Translate the text from source lang to target lang
"""
src = LANG_CODES.get(src_lang)
tgt = LANG_CODES.get(tgt_lang)
tokenizer.src_lang = src
tokenizer.tgt_lang = tgt
ins = tokenizer(text, return_tensors='pt')
gen_args = {
'return_dict_in_generate': True,
'output_scores': True,
'output_hidden_states': True,
'length_penalty': 0.0, # don't encourage longer or shorter output,
'num_return_sequences': candidates,
'num_beams':candidates,
'forced_bos_token_id': tokenizer.lang_code_to_id[tgt]
}
outs = model.generate(**{**ins, **gen_args})
output = tokenizer.batch_decode(outs.sequences, skip_special_tokens=True)
return output
print(translate("Ame diabe maken.","Tarotic","English", 1))
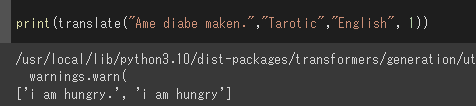
好し。
結び
人工言語を翻訳するモデルを作ることは、独自のコミュニケーション手段を持つ人々にとって非常に重要です。
今回は、Facebookが提供するM2M-100をファインチューニングすることで、自作の人工言語を翻訳するモデルを作成しました。
この方法を応用すれば、他の多様な言語に対しても翻訳機能を提供することができます。
AIの力を借りて、より多様な言語間のコミュニケーションを実現するため、ぜひこの手法を活用してみてください。と、ChatGPTが言っております。