はじめに
デモです。
input=>ちょっと、何!? びっくりすんじゃん……。
category: tsundere
input=>君が大好きで。すっごく大好きでね。
category: not_tsundere
input=>……気安く触んないでよ、バカ。
category: tsundere
input=>人ラブ!俺は人間が好きだ!愛してる!
category: not_tsundere
よい...。
やったこと
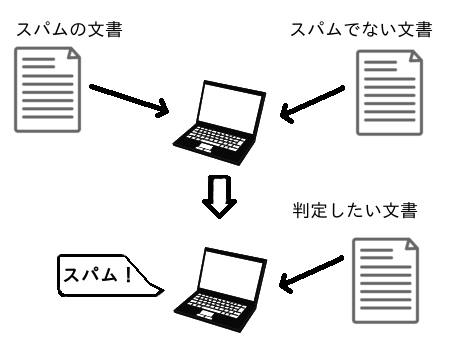
ふつうのスパム判定の場合
スパムのテキストとそうでないテキストをそれぞれコンピュータに学習させて、新しく入力されたテキストがスパムかどうかを判定します。
...つまらん
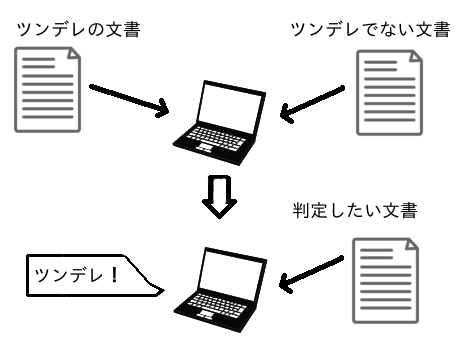
ツンデレ判定の場合
ツンデレのテキストとそうでないテキストをそれぞれコンピュータに学習させて、新しく入力されたテキストがツンデレかどうかを判定します。
楽しい!!
データの用意
学習を行うためには当然学習データが必要です。ツンデレがいっぱい詰まったテキストをどうにかして用意しなければなりません。
今回はデータを集めるのにtwitterを使いました。「ツンデレbot」みたいなアカウントのツイートを取得して学習データとしています。
コード
コードはGitHubにあります。詳しいつかいかたはREADMEを見てください。
ナイーブベイズのコードはkatryoさんの記事のものを使用しました。
動作させるにはpython-twitter(pipでインストールできる)が必要です。
また、twitterのアプリケーション用のキーとyahooの形態素解析のアプリケーションIDを発行する必要があります。
それぞれ以下で取得できます。
https://dev.twitter.com/
https://e.developer.yahoo.co.jp/register
なおYahooのアプリケーションIDを発行する際には「クライアントサイド」を選択してください。
発行した各IDをsettings.cfgに貼り付け、適当なアカウントをtrue_accountsとfalse_accountsに設定するとつかえます。
アカウント1つあたり200ツイート取得して学習させているため、たくさんアカウントを指定するとそれだけ学習に時間がかかります。指定するアカウントの数は時間と精度のトレードオフを見て適切に決めてください。
最後に
別のデータを学習させれば自分のオリジナルの学習器を作ることができます。
ツンデレ判定以外にも、ヤンデレ判定やイケメン判定などもやってみると面白いかもしれません。