スパースなデータ表現とは、データを表現するための辞書を用意し、その要素のできるだけ少ない組み合わせでデータを表現することをいいます。
文章で説明されてもいまいちピンとこないと思うので図で表すとこんな感じです。
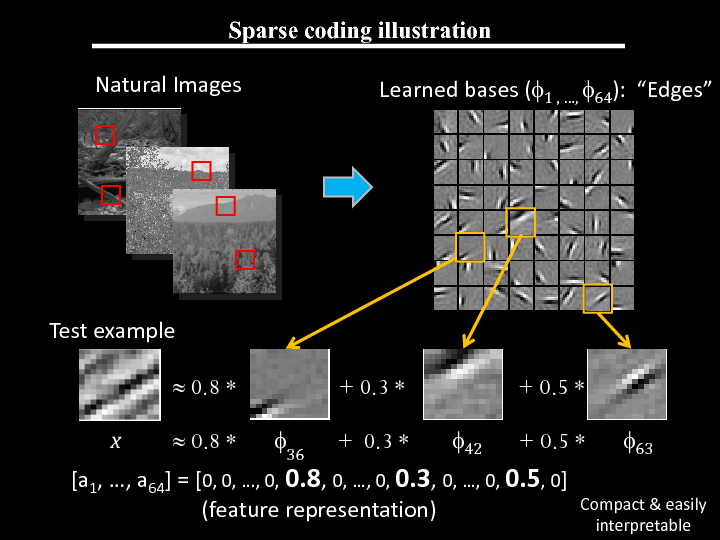
引用元: Andrew Ng, Unsupervised Feature Learning and Deep Learning, 2015
右側のLearned basesと書いてある部分が辞書を表しています。
スパースコーディングは入力画像の一部または全体を、辞書に含まれる要素の組み合わせで表現しようというものです。
例えば下の例では表現したい画像$x$を$\phi_{36}$、$\phi_{42}$、$\phi_{63}$という3つの要素を
0.8\phi_{36} + 0.3\phi_{42} + 0.5\phi_{63}
というふうに組み合わせて$x$を近似しています。
もっとたくさんの要素を使って
0.8\phi_{36} + 0.002\phi_{40} + 0.3\phi_{42} + 0.02\phi_{58} + 0.5\phi_{63}
などとすれば近似精度は上がるかもしれませんが、スパースコーディングにおいてはあえてこれを行いません。
少数の要素を用いることで、意味のある表現を取り出すことができる__からです。
スパースな表現を用いると、データを表現するにはどの要素がどの程度有用なのかをはっきりさせることができます。
例えば上の例では、$x$を表現するには$\phi{36}$が最も有用で、次に$\phi{63}$、$\phi_{42}$と並ぶ、といった具合です。