トライ木とは
トライ(Trie)木というデータ構造をご存知でしょうか?
トライ木は高速な辞書の実装に使えるデータ構造です。LOUDSというデータ構造を使って実装すると,非常に少ないメモリで木を表現できるという利点があります。トライ木は例えばかな漢字変換(Google日本語入力など)において,国語辞典をメモリに保持するために用いられています。
トライ木はこんなカタチをしています。
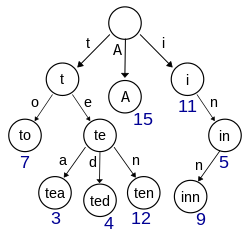
(図はWikipediaより引用)
他の木と違うところは、木の"枝"にあたる部分にラベルが付いていることです。
これを辞書として使うにはどうすればいいでしょうか。
"in"を検索してみましょう。簡単です。i -> n とたどればいいだけです。「5」が検索結果として取り出せますね。
"inn"を検索してみましょう。今いる「5」の位置から下に動けばいいだけです。「9」が結果として取り出せます。
トライ木の特徴
高速に検索できる
このトライ木、何がすごいかというと、検索がすごく高速にできるんです。トライ木では検索速度は検索するキーの大きさに比例します。そして、木の大きさには比例しません!
例えば、トライ木で国語辞典を実装したとします。
その国語辞典で12文字の「わらうかどにはふくきたる」を検索するには、3文字の「わらう」を検索する場合のだいたい4(=12/3)倍の時間がかかります。
しかし、辞書に100単語入っていようが100万単語入っていようが、同じ単語を調べる場合、理論上検索速度は変わりません。すごいですね。
ムダな検索を減らせる
また、共通する部分がある文字列を検索する場合、検索を途中から再開させることでムダな検索を減らすことができます。
例えば先ほど"inn"を検索したときは、"in"を検索した結果の「5」のノードから検索を再開することで、素早く"inn"の検索結果を見つけることができました。
LOUDSによる実装
トライ木を構造体やポインタを使って何も考えずに実装するとものすごくメモリを食います。メモリ確保が忙しすぎてヘタするとマシンがフリーズします。
そこでLOUDSというデータの表現方法を使います。
LOUDSを使うとノード1つをたった2ビット程度で表現できます。
最初に示した図のようなノードが11個ある木でもたった23ビットで表現でき、なんとlong型の変数1つに収まってしまいます。
ここでLOUDSの説明といきたいところですが、簡潔データ構造 LOUDS の解説が非常にわかりやすかったのでそちらに譲ります。
コード
コードは以下です。D言語とPythonそれぞれで実装しました。
github.com/IshitaTakeshi/Louds-Trie
コメントはたくさん書いたつもりなので、上記リンクのLOUDSの解説を読んでからコードを読めば理解できると思います。
疑問点やおかしいと思った点があればコメントするかtwitterで言っていただければ対応します。