現在、AIや機械学習界隈で最も有名なスタンフォード大学のAndrew Ng教授が、「Machine Learning Yearning」という書籍を執筆中です。2018年4月18日に、そのドラフト版(1-14章)が公開されました。
この投稿では、いち早く本書籍を翻訳しました。

この本は、機械学習プロジェクトの構築方法を提供します。また、機械学習アルゴリズムを教えるのではなく、機械学習アルゴリズムが機能する方法に焦点を当てています。
本投稿は、1-5章の翻訳になります。少しづつ翻訳していきます。(教授は、来週も送ってくると言っている。) ※翻訳違っていたらご指摘ください。
本書籍は、とても読みやすく、かつ各章短めに記載されています。
6章の翻訳
【Draft版公開】Machine Learning Yearning 6章 by stanford大学Andrew Ng教授
7-8章の翻訳
【Draft版公開】Machine Learning Yearning 7~8章 by stanford大学Andrew Ng教授
9-10章の翻訳
【Draft版公開】Machine Learning Yearning 9~10章 by stanford大学Andrew Ng教授
11-12章の翻訳
[【Draft版公開】Machine Learning Yearning 11~12章 by stanford大学Andrew Ng教授]
(https://qiita.com/Ishio/items/35c756e073a1f2f1d244)
1. Why Machine Learning Strategy(なぜ、機械学習戦略が必要か?)
機械学習は、ウェブ検索、電子メールにおけるスパム対策、音声認識、製品レコメンドなど、無数の重要なアプリケーションの基盤です。あなたやあなたのチームは、機械学習アプリケーションに取組んでおり、急速に進歩したいと考えているとします。この本は、そんなあなたを支援します。
例:猫の絵を配信するスタートアッププロジェクト
あなたが猫の愛好家に対して、エンドレスにストリーム配信される猫の写真を提供するスタートアップを構築しているとします。

ニューラルネットワークを使用して、ネコの写真を検出するコンピュータビジョンシステム(ロボットの目)を構築します。しかし残念なことに、あなたの学習アルゴリズムの精度はまだ十分ではありません。あなたには、猫検知器を改善するための驚異的なプレッシャーがあるとします。あなたはどうしますか?
あなたのチームには以下のようなアイデアがいくつかあります。
- さらに多くのデータを獲得する:猫の写真をもっと集める
- より多様なデータを収集する:EX) 珍しい位置にいる猫、珍しい配色の猫、様々な角度からの猫
- 勾配降下法の反復により、より長くアルゴリズムを訓練する
- よりレイヤーの数や隠れ層の数を増やした大規模ニューラルネットワークを試す
- より小規模なニューラルネットワークを試す
- 正則化を追加してみる(たとえばL2正則化)
- ニューラルネットワークのアーキテクチャを変更する(活性化関数、隠れユニットの数、など)
- ...
これらの中で可能性のある選択をすると、優れた猫写真のプラットフォームを構築できるでしょう。そしてあなたの会社を成功に導くでしょう。逆にもし、誤った判断をすると、何カ月も浪費するかもしれません。
どのように進めますか?
この本は、それをお伝えします。多くの機械学習の問題は、試してみると有用なこと、逆に有用ではないことの手がかりを残します。これらの手がかりを読み学ぶことで、数カ月もしくは数年の開発期間を節約できます。
2. How to use this book to help your team(この書籍をチームの手助けにどう使うか)
この本を読み終えたら、機械学習プロジェクトのために技術的な指針をどう設定するべきか深い理解が得られるでしょう。
しかし、あなたのチームメンバーが、あなたがなぜ特定の方針を推奨しているか理解できないかもしれません。おそらく、チームに単一の評価尺度を定義したいかもしれませんが、確信が持てません。どうやって彼らを説得しますか?
だから私は章を短くしました。あなたはそれを印刷して、あなたが知るべき1~2ページだけを読むことができます。
いくつかの優先順位付けの変更は、チームの生産性に大きな影響を与える可能性があります。
あなたのチームにこのような変更を加えることで、チームのスーパーヒーローになれることを願っています!

3. Prerequisites and Notation(前提条件および記法について)
Courseraで私の機械学習講座を受講した場合、または教師あり学習の経験がある場合は、このテキストを理解することができます。
私はあなたが教師あり学習に精通していると想定します。教師あり学習のアルゴリズムには、線形回帰、ロジスティック回帰、およびニューラルネットワークが含まれます。機械学習には多くの形式がありますが、今日の機械学習における実用的価値の大半は、教師あり学習からもたらされます。
私は頻繁にニューラルネットワーク(「深層学習」とも呼ばれます)について言及するでしょう。このテキストを読み進めるには、それらの基本理解が必要です。ここに記載した概念に精通していない場合には、Couseraの機械学習コースのビデオの最初の3週間分をご覧ください(http://ml-class.org)。
4. Scale drives machine learning progress(スケールは機械学習のパフォーマンス改善を促進する)
深層学習(ニューラルネットワーク)の多くのアイデアは、数十年前から存在しています。何故、今日までこれらのアイデアは実用化されなかったのか。
最近の発展には以下の2つの大きな要因があります。
-
データの可用性(Data Availability)の向上
- 今日、人々はデジタルデバイス上で多くの時間を費やします(デスクトップ、モバイルデバイス)。彼らのデジタル上での活動は巨大なデータを生成し、私たちの学習アルゴリズムに利用することができます。
-
計算規模(Computational Scale)
- まさに数年前から、私たちが持つ巨大なデータセットを利用するに資する十分な大きさのニューラルネットワークを訓練することができるようになった。
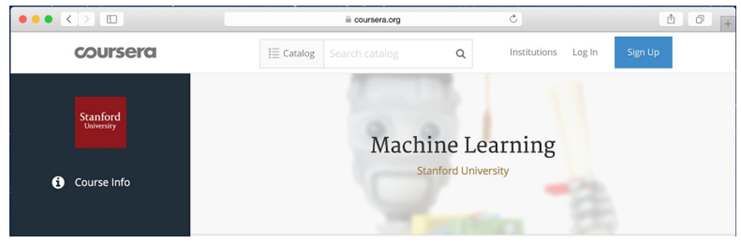
具体的には、より多くのデータを蓄積しても、ロジスティック回帰のように古い伝統的なアルゴリズムのパフォーマンスは横ばいです。これはLearing Curveを描いたときに、平坦な状況で、アルゴリズムがデータを追加してもパフォーマンス改善が止まっていることを意味します。
これは、あたかも古いアルゴリズムが、私たちが現在持つ「全データ」を使ってで何をすべきかを知らなかったかのようです。
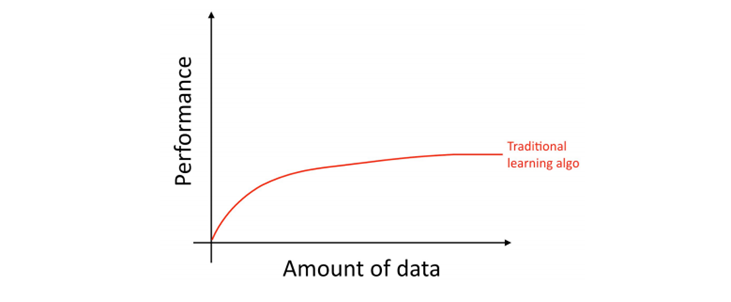
同じく教師あり学習の小規模なニューラルネットワーク(NN)で訓練すれば、パフォーマンスは幾分良くなるかもしれません。
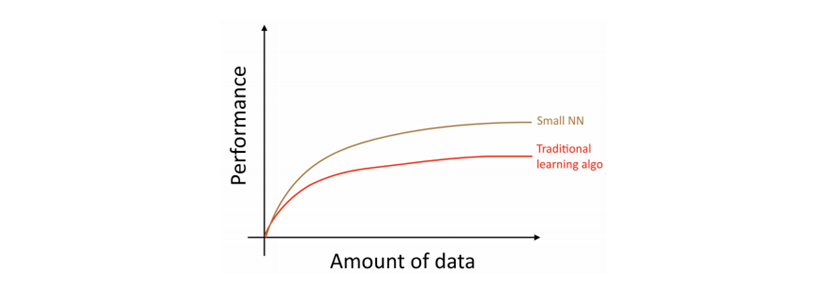
ここで、「小規模ニューラルネットワーク」とは、少ない数の隠れユニット/ 層/パラメータしか持たないニューラルネットワークを意味します。 最後に、より大きなデータと大規模ニューラルネットワークを訓練すれば、さらに優れたパフォーマンスを得ることができます。
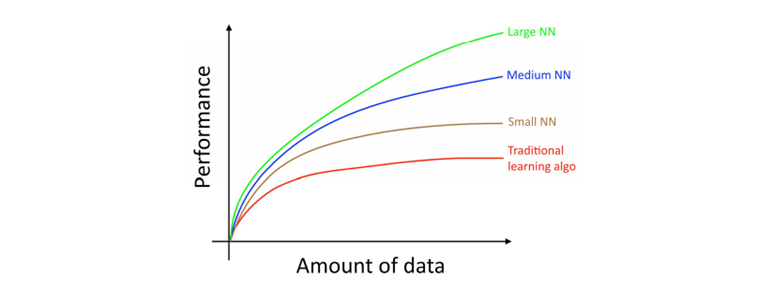
したがって、(1)大規模なニューラルネットワークを訓練して上記図の緑色の曲線上にいるとき、最高のパフォーマンスを得ることができます。ただし、そのためには(2)巨大な量のデータが必要です。
他のニューラルネットワークのアーキテクチャのような細かいチューニングもまたとても重要であり、今日たくさんのイノベーションが存在します。しかし、アルゴリズムのパフォーマンスを改善するためにより信じられる方法は、いまだに(1)の訓練であり、(2)巨大なデータを得ることです。
どのように(1)と(2)を達成するかのプロセスは、驚くほど複雑です。 この本では詳細に説明します。従来の学習アルゴリズムとニューラルネットワークの両方に役立つ一般的な戦略から始め、現代の最新の深層学習システムを構築するための戦略まで学んでいきます。
5. Your development and test sets(学習/テストセットについて)
以前の猫の写真の例に戻りましょう。あなたはモバイルアプリを運営しており、ユーザーはアプリに様々な写真をアップロードする中で、あなたは自動的に猫の写真を探したいと考えます。
あなたのチームは、異なるウェブサイトから猫の写真(肯定的な例)と猫以外の写真(否定的な例)をダウンロードすることにより、大規模なデータセットを取得します。
データセットを70%対30%でトレーニングセットとテストセットに分割しました。このデータを使用して、訓練セットとテストセットからうまく機能する猫検出器を構築します。
しかし、この分類器をモバイルアプリにデプロイすると、パフォーマンスが悪いことがわかります。

いったい、何が起こっているのでしょう。
ユーザがアップロードしている写真は、訓練データのために準備したウェブサイトの画像と比較して、見た目が違うことが判明しました。ユーザは携帯電話で撮影した写真をアップロードしていますが、解像度は低く、ぼかしがあり、写真が明るくない傾向があります。
あなたの訓練/テストデータは、ウェブサイトの画像で作られているので、あなたのアルゴリズムは、あなたが気にかけていた携帯画像の実分布に対して、うまく汎化しなかったのです。
私たちは通常、以下を定義します。
-
トレーニングセット
- トレーニングセット上で、学習アルゴリズムを実行します。
-
開発セット(Dev (development) set)
- パラメータの調整、特徴量の選択、学習アルゴリズムに関するその他の決定を行うために使用します。「ホールドアウトクロスバリデーションセット(hold-out cross validation set)」と呼ばれることもあります。
-
テストセット
- アルゴリズムのパフォーマンスを評価するために使用しますが、どの学習アルゴリズムやパラメータを利用するかに関しては関与しません。
開発セットとテストセットを定義すると、あなたのチームは異なる学習アルゴリズムのパラメータなど、多くのアイデアを試して、何が最も効果的かを確認します。 開発/テストセットによって、あなたのアルゴリズムがどれほどうまく機能するかを素早く確認することができます。
言い換えれば、開発/テストセットの目的は、あなたのチームを機械学習システムにとって最も重要な変化の方向に向けることです。
したがって、あなたは次のことをするべきです。
あなたが将来的にうまくいくと予想できるデータを反映するように、開発/テストセットを選ぶ必要がある
つまり、将来のデータ(携帯電話の画像)がトレーニングセット(ウェブサイトの画像)と性質が異なることが予想される場合は、テストセットは単に利用可能な30%のデータにすべきではありません。
あなたのモバイルアプリがまだローンチしていなければ、まだユーザがいないかもしれません。そのため、将来的にうまくいくものを正確に反映したデータを取得できない可能性があります。しかし、あなたはまだこの方法に近づこうと頑張るかもしれません。例えば、お友達にネコの携帯電話の写真を撮って、あなたに送信してもらうように訪ねてください。あなたのアプリが一旦ローンチすると、実際のユーザデータを利用した開発/テストセットに更新することができます。
将来的に得られるデータに近づく方法がない場合は、ウェブサイトのイメージを使用して開始することができます。しかし、これが汎化しにくいシステムにつながるリスクを認識しておくべきです。
それは、素晴らしい開発/テストセットの準備にどれだけ投資するかを決める判断が必要になります。 しかし、あなたのトレーニングデータの分布が、テストデータの分布と同じであると仮定しないでください。あなたがトレーニング用に持っているどんなデータよりもむしろ、最終的に成果をあげたいと考えるデータを反映するテストのサンプルデータを選んでみてください。