はじめに
皆さん、こんにちは!こちらは、2024年のAdvent Calendarで完走賞を目指す筆者による24記事目の記事です。記事数が増える中で、「自分がどんなテーマで書いているか」を体系的に振り返りたくなりました。そこで、本記事の前半では、LLMを用いた記事タイトルのクラスタリング手法を紹介し、後半では実際にクラスタリングした記事をテーマごとに紹介します。
使用する技術
- LLMによるテキスト埋め込み: タイトルをLlamaモデルでエンコードし、高次元の意味空間へマッピング。
- UMAP次元削減: 高次元ベクトルを2次元空間へ射影。類似するタイトルが近くにプロットされ、テーマ別の分布が視覚的に把握。
- HDBSCANクラスタリング: 自動的に適切なクラスタ数を決定し、密度ベースで類似タイトルをグルーピング。
- Plotly可視化: インタラクティブな可視化。マーカー上にタイトルテキスト表示し、クラスタ分布を直感的に確認。
ソースコード
以下は、記事タイトルをLLMで埋め込み、UMAPで次元削減、HDBSCANでクラスタリング、そしてPlotlyで可視化するソースコードです。モデルのパスや環境はKaggle Notebook上での動作を想定していますが、適宜環境に合わせて変更してください。
全体のソースコードはこちらから入手可能です。
pip install hdbscan
import numpy as np
import pandas as pd
import torch
from transformers import AutoTokenizer, LlamaModel
import umap.umap_ as umap
import hdbscan
import plotly.graph_objs as go
article_titles = [
"2年連続1人アドカレを完走した挫折0で記事を書く方法",
"一人アドカレ総括!25記事のタイトルをLLMとUMAPでクラスタリング",
"機械学習のためのソフトウェアテスト入門",
"5分でできるGitHub Actionsを用いた自動テスト",
"AI系の人がソフトウェア開発に挑戦するならこのUdemy講座がオススメ!",
"Soraで架空の生き物の動画を生成してみた!【2024年12月10日】",
"Twitter投稿とQiitaの記事、いいね数に相関はあるのか?──検証の結果、ほぼナシ",
"LLM(+UMAP)を用いたテキストデータ教師なし異常検知の実践ガイド",
"Kaggleに特化したChatGPTのカスタムインストラクションの紹介",
"人類サンタ化計画🎅🤶(アプリ公開中)",
"X (Twitter) API を使って Qiita 投稿ポスト(ツイート)を収集する",
"クラウドセキュリティのヒヤリ体験:Streamlitアプリの公開ミス",
"Qiita APIを使って記事の「タイトル」「いいね数」「ストック数」を取得してCSVに書き出す",
"OpenAI APIキーをKaggle Notebook上で安全に使う方法",
"モジュール依存関係をNetworkXとPlotlyで可視化する",
"【アドカレ駆動学習】新しい技術を学ぶ方法の備忘録",
"FastAPIの学習を迷わず進めるための事前知識",
"FastAPIで機械学習モデルをAPI化!簡単クイックスタートガイド",
"ポケポケに登場する確率分布",
"LLMコンペの取り組み方",
"Optunaを用いたプロンプトエンジニアリング",
"架空のコンペ『LLM Prompt Reverse』を考えたのでトイプロブレムに使ってください!",
"GitHubでたまに見るColabやKaggleのアイコンの出し方",
"Kaggleと名のつく本を全て読んだので紹介していく",
"5分でできるRuffによる高速Pythonコードリント"
]
# ================ LLMモデルの準備 ================
# モデルとトークナイザの読み込み
tokenizer = AutoTokenizer.from_pretrained("/kaggle/input/llama-3-1-8b-instruct-fix-json/fixed-llama-3.1-8b-instruct/")
model = LlamaModel.from_pretrained("/kaggle/input/llama-3-1-8b-instruct-fix-json/fixed-llama-3.1-8b-instruct/")
def get_embedding(text: str) -> np.ndarray:
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# 平均プーリング
embedding = outputs.last_hidden_state.mean(dim=1).squeeze().numpy()
return embedding
# 埋め込み取得
X = np.array([get_embedding(title) for title in article_titles])
# ================ UMAPによる次元削減 ================
umap_reducer = umap.UMAP(n_neighbors=5, min_dist=0.1, n_components=2, random_state=42)
X_2d = umap_reducer.fit_transform(X)
# ================ クラスタリング ================
# HDBSCANでクラスタリング(自動で適切なクラスタ数を抽出)
clusterer = hdbscan.HDBSCAN(min_cluster_size=2, metric='euclidean', cluster_selection_epsilon=0.1)
labels = clusterer.fit_predict(X_2d)
# ノイズ(-1)はクラスタ外として扱われる
# ================ 可視化 ================
def visualize_2d_data(points, labels, texts, title="UMAP + HDBSCAN Clustering"):
unique_labels = np.unique(labels)
color_map = {}
for lbl in unique_labels:
if lbl == -1:
color_map[lbl] = "rgba(128,128,128,0.8)"
else:
color_map[lbl] = f"hsl({(lbl * 60) % 360}, 70%, 50%)"
data_traces = []
for lbl in unique_labels:
mask = (labels == lbl)
data_traces.append(go.Scatter(
x=points[mask, 0],
y=points[mask, 1],
mode='markers+text', # テキストを常時表示
text=[texts[i] for i in np.where(mask)[0]],
textposition='top center', # テキスト位置
textfont=dict(size=8), # テキストサイズ
marker=dict(color=color_map[lbl], size=10),
name=f"Cluster {lbl}" if lbl != -1 else "Noise"
))
fig = go.Figure(data=data_traces)
fig.update_layout(
title=title,
xaxis_title='UMAP Component 1',
yaxis_title='UMAP Component 2',
showlegend=True,
hovermode='closest'
)
fig.show()
visualize_2d_data(X_2d, labels, article_titles, title="Article Titles Clustering")
クラスタリング可視化結果
タイトルの2次元可視化(テキスト表示なし)
タイトルの2次元可視化(テキスト表示あり)
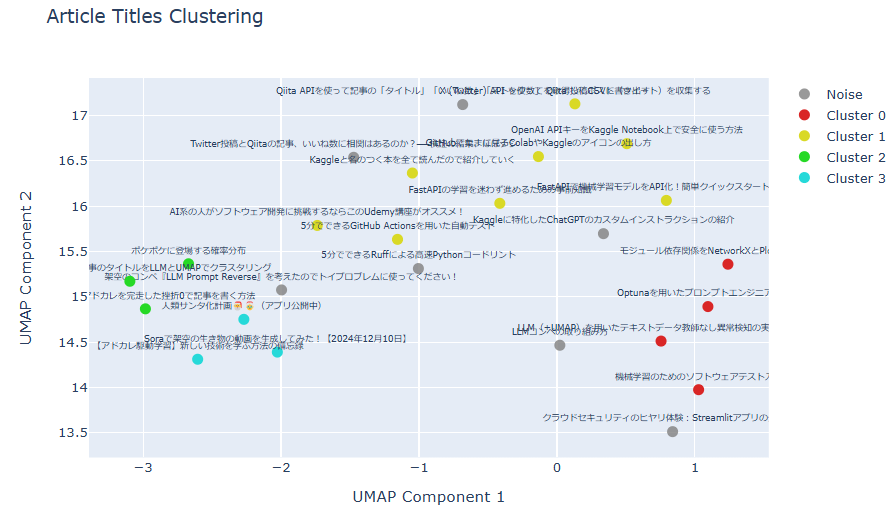
クラスタごとに記事の紹介
LLMによるクラスタリング結果を参考にしながら、グルーピングした記事を一挙紹介します。
1. Kaggle
今年はKaggle Masterの称号を獲得でき、非常に印象深い年となりました。Kaggle参加を通じて、テストコードを書くことの有用性を改めて実感しています。
2. LLM
今年はLLMコンペが数多く開催され、私自身も3つのLLMコンペに挑戦しました。一人アドカレ完走後にはもう一つのLLMコンペに参戦予定です。対戦よろしくお願いします!
3. ソフトウェア開発
機械学習だけでなく、ソフトウェア開発にも強い関心があります。いくつか温めているアプリ開発のアイデアがあるので、それを実現するための技術習得に努めていきます。
4. Python
機械学習界隈ではPythonが事実上の標準言語となっています。Pythonでできないことはないくらい手広い言語だと思っています。
5. アドカレスペシャル
プロフィールをサンタ化するアプリはとてもおすすめです!ぜひ皆さんも使ってみてください。また、「ポケポケ」の記事は想定以上の反響があり、リアル知人からも多くの反響が届くほどでした。最後の一人アドカレ完走振り返り記事も、近々公開予定ですのでお楽しみに。
おわりに
本記事では、LLM埋め込み+UMAP次元削減+HDBSCANクラスタリング+Plotly可視化という流れを用いて、25本の記事タイトルをクラスタリングしました。これにより、記事全体を俯瞰することができました。
今年も2年連続で一人アドカレに挑戦し、多彩なトピックに挑みました。今後も機械学習・LLM・ソフトウェア開発・Pythonなどのさらなるスキルアップを目指します。
最後の記事(一人アドカレ完走記事)も近日中に執筆し、二年連続完走賞を目指します。それでは、引き続き応援よろしくお願いします!
2024年12月19日追記:2024年も一人アドベントカレンダーを無事に完走することができました。見守ってくださった皆様、本当にありがとうございました!