この記事はNew Relic Advent Calendar 2022の18日目のエントリーです。
TL; DR
New Relicと「はじめまして」したらあまりの機能の多さにビビって
どこから手を付けたらいいのかわからなかった方🐣は
まずこんなことから始めたらいいんじゃないかなというファーストステップの具体例
導入のきっかけ
現在のツールへの不満① インシデント発生時のアクションの取りづらさ
弊チームではメトリクス監視、ログ監視、死活監視、外形監視などの監視をZABBIXで行ってきました。
一方でZABBIXではアクセス数を計測していないため、
CPU使用率やメモリ使用率のスパイクによってサービスが不安定になった際には、
分散したサーバにSSHでログインし grep や wc などのコマンドでアクセスログからアクセス数を出しつつエクセルで作成したグラフをZABBIXのグラフと突合していました。
非効率ですし、対応は常に後手に回ってしまっていました。
現在のツールへの不満② インフラモダナイズの障壁
現在絶賛リアーキテクチャの真っ最中なのですが、Amazon EC2からECSへの移行も含まれています。
静的IPアドレスを設定できる EC2に対してECSのコンテナはIPアドレスが起動のたびに変わります。
IPアドレスベースでホストを管理しているZABBIXとは相容れません。
また、モノリスなEC2上のアプリケーションからイベントドリブンなサーバレスへの移行をしていく上で、
様々な分散したサービスを一貫して監視できるツールが必要になりました。
などなど、他にもあるのですがこれだけでもオブザーバビリティへの移行には十分な理由でした。
導入戦略
New Relicは非常にできることが多く、どこから手を付けるべきかでかなり悩みました。
そこでNew Relic実践入門 監視からオブザーバビリティへの変革を教本として読んでいく上でオブザーバビリティ成熟モデルに出会いました。
詳細については上記の書籍、またはオブザーバビリティの成熟度を表す4つのステップについて解説 - ログミーTechを参照していただければと思いますが、軽く触れておきますと、
0. Getting Started
1. Reactive
2. Proactive
3. Data Driven
※記事のほうではProactiveとData Drivenの間にPredictiveが入りますが
書籍ベースで導入戦略を立てていったためPredictiveは入れていません
という ステップに沿って一歩ずつレベルアップをしていきましょう、
という指針になります。
また、監視全体を一度にレベルアップさせる必要はまったくなく、
監視の部分ごとにレベルがバラバラでも問題ない とのことです。
やったこと
ステップに従って、まずはシステムの大半を 1. Reactive のレベルに持っていくことを考えます。
そのために必要なステップを以下のように定めました。
- 何を監視するのかを決める
- 現在の監視項目を整理する
- これから監視する項目を決める
- 監視を始める =
0. Getting Started- エージェントの導入
- AWSとの連携
- ダッシュボードの作成
- 異常を検知する
- 異常を定義する
- 異常を通知する =
1. Reactive- Slackへ通知をする
何を監視するのかを決める
現在の監視項目を整理する
現在の監視項目を整理したところ、ザックリ以下のような項目に分けられました。
- メトリクス監視
- ログ監視
- ミドルウェア監視
- 死活監視(ping, SSH)
- 外形監視(HTTPS)
またメトリクス監視もCPU関連だけで
- CPU idle
- CPU nice
- CPU ratio
- CPU system
- CPU user
などのグラフが用意されていましたが
実際には使用率(ratio)だけがしきい値とアラートの設定がされているなど、
注視している項目(ratio)ととりあえず取得できている項目(それ以外)とに分けられます。
これから監視する項目を決める
すべてを書くと量が大変になってしまうのでメトリクス監視について監視していく項目を書き出すと以下のようになります。
- Amazon EC2
- CPU使用率
host.cpuPercent - inode使用率
host.disk.inodesUsedPercent - disk使用率
host.disk.usedPercent - メモリ使用率
host.memoryUsedPercent - Load average
host.loadAverageOneMinute
- CPU使用率
- Amazon RDS
- CPU使用率
aws.rds.CPUUtilization - Failover
- SlowQuery
- CPU使用率
- ElastiCache
- CPU使用率
aws.elasticache.CPUUtilization - メモリ使用率
aws.elasticache.DatabaseMemoryUsagePercentage
- CPU使用率
RDSのフェールオーバーなどのイベントについては直接はとれませんのでAWS RDSのイベントをNew Relicで監視してみるなどを参考に構築していくことにします。
監視を始める
具体的な手順はNew Relic公式が出しているものが非常に詳細に書かれていますので、
本エントリではリンクを貼るのみにとどめます。
インフラエージェントの導入
Linux向けInfrastructureモニタリングエージェントをインストールする
AWSとの連携
ダッシュボードの作成
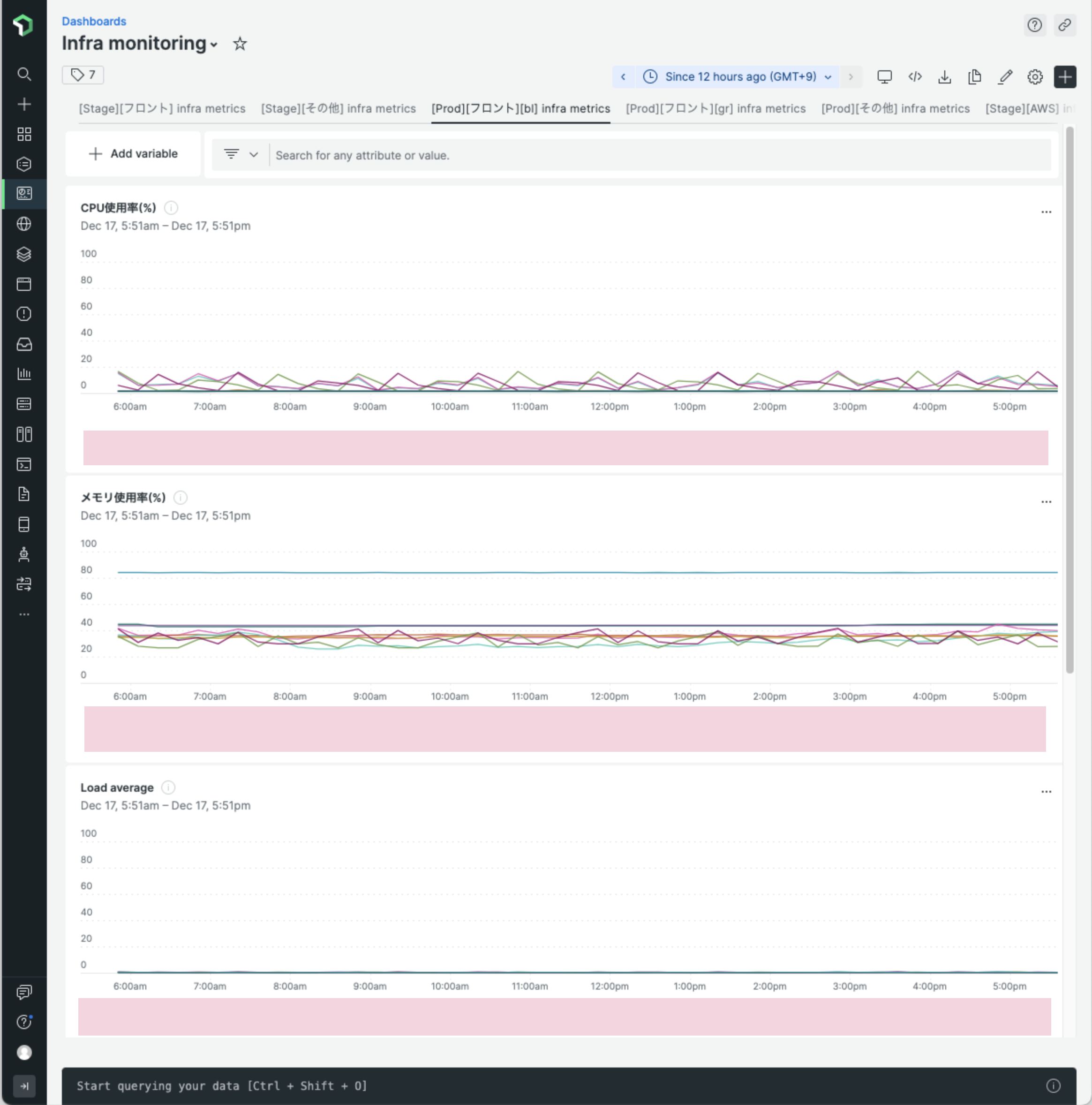
この段階で以下のようなシンプルなダッシュボードができているかと思います。
これでようやく 0. Getting Started に到達できました!!やったね!!
異常を検知する
次は異常検知の仕組みづくりです。
まずは「異常」を定義します。
今回は現在のZABBIXのアラートに倣って以下のようにCriticalを指定しました。
- Amazon EC2
- CPU使用率
host.cpuPercent> 99% - inode使用率
host.disk.inodesUsedPercent> 90% - disk使用率
host.disk.usedPercent> 99% - メモリ使用率
host.memoryUsedPercent> 99% - Load average
host.loadAverageOneMinute> 0
- CPU使用率
ただし、この「異常」が定義されたのは弊チームではすでに7年以上前ですので、
今後は実際に運用を進めながらしきい値は適宜変更していく想定です。
異常を通知する
この段階で以下のようなアラートを受け取ることができるようになりました!!
これで異常を検知しアクションを取る体制がとれる = 1. Reactive に到達できました!!
いままでZABBIXで行っていた監視のうち、メトリクスに関してはこれで移行完了です!!
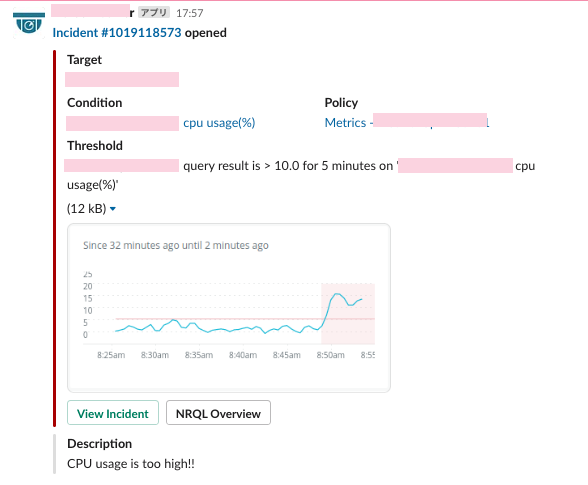
※このスクリーンショットではアラートを受け取れるかのテストのために
CPU使用率が10%を超える時間が5分を超えたときに受け取るようにしています
さいごに
以上が弊チームでのNew Relic導入のファーストステップでした。
右も左も分からない段階から現在と同等の監視と通知のシステムが構築できました。
やはり何事も自分が処理できるレベルにまでステップを小さく分割することが大事ですね。
とはいえ、まだまだNew Relicのごく一部の機能を使いはじめた段階ですので、
ツールの研究と運用をこれからがんばっていきます!!