どんなもの?
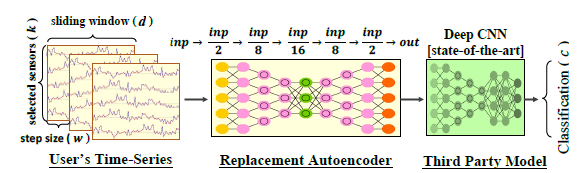
多次元のデータを匿名化することに着目している。主に時系列のデータを窓枠を定めて匿名化したい。
まず、データが匿名したいものから順にblack, gray, whiteの3種類に分けられることに触れ、blackは匿名化され、grayとして表現されるべきだとしている。ただし、時系列のデータの場合、窓を定めてしまうとblack、gray、whiteが混ざって存在するため、その場合は一番割合の多いラベルを採用している。
その際、単にgrayなデータでblackを置換するのではなく、置換したデータを教師としてAutoEncoderに学習させれば良い置換ができる学習器が出来上がるとしている。実際、MNISTのデータに対して偶数をblack、奇数をwhite、0をgrayなデータして与えたとき偶数の画像を与えると0の画像を返すReplacement AE (RAE)が生成できた。
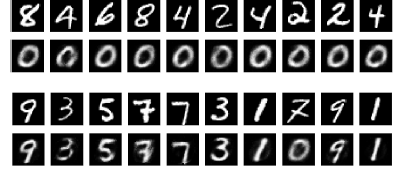
先行研究と比べてどこがすごい?
置換によって匿名化している点?
正直よくわからない
技術や手法のキモはどこ?
AutoEncoderで匿名化している点。denoising autoencoder1にヒントを得たとしている。
どうやって有効だと検証した?
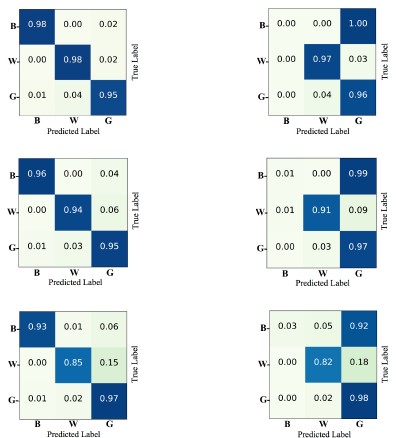
第三者の識別機であるHARを用いて、RAEで置換したデータを食わせ、blackがgrayとしかほとんど識別されないことを確かめた。
議論はある?
検証の一つとして、偽のgrayを識別する識別器をGANによってつくったところ、ほぼ100%識別できてしまうことが分かった。置換しても解析者に偽であることが明らかになるとWhiteなデータがあったことは露見してしまう。しかし、作者はこのGANの作成に生のデータが必要なため問題にならないとしているが、GANをほかの経路で得た同様な内容のデータで学習すればよいから問題だと思う。
次に読むべき論文は?
denoising aeは読んでもいいかもしれない。
感想
AEで匿名化するという発想は自分にもあったので読んだ。が、自分はAEで得た隠れ層の値にこそ意味があると思っているのだが、筆者はそこではなくAEの出力に着目している。これでは結局、教師に与えた関数の模写であり、なら教師として与えた関数である、blackをgrayにする関数を最初から匿名化に使えばよいのにと思う。現状ではただ単に時系列のデータのラベル付けをするN.N.を作成したに過ぎない結果だ。
また、第一に匿名化するときにblackなデータかどうかが分かっているというのも前提に疑問がある。そこまでわかっているなら消せばよいと思うのは駄目なんだろうか?少しでもデータを残したいんだとしても、「じゃそれblackじゃなくない?」と意味が分からない。
-
P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, “Extracting and composing robust features with denoising autoencoders,” in Proceedings of the 25th ICDM. ACM, 2008, pp. 1096–1103 ↩