インテル® Gaudi® アクセラレーター SynapseAI 1.13.0 のリリースにより、ユーザーはわずか 8 基のインテル® Gaudi® 2 AI アクセラレーターを使用して Llama2-70B モデルのファインチューニングが可能になりました。
Llama2-70B のようなパラメーター数が数十億を超える大規模言語モデル (LLM) のファインチューニングは、大容量のメモリーと演算リソースを必要とする負荷の高いタスクです。bfloat16 精度の場合、モデル・パラメーター 1 つに 2 バイトのメモリーを消費します。つまり、Llama2-70B の 700 億パラメーターをロードするだけで、140GB のデバイスメモリーが必要になります。加えて、学習処理を実行中にオプティマイザーの状態とモデルの勾配を累積するには、さらにメモリーが必要です。
このブログでは、8 基のインテル® Gaudi® 2 AI アクセラレーターを使用し、DeepSpeed ZeRO-3 と低ランク適応 (LoRA) の手法によって Llama2-70B のファインチューニングを行う具体的な手順を説明します。
【DeepSpeed ZeRO-3 による最適化】
DeepSpeed は、ディープラーニングの最適化ライブラリーです。学習処理と推論のためにモデルのスケーリングを可能にします。ゼロ重複オプティマイザー (ZeRO) は、DeepSpeed に含まれるメモリー最適化の手法の 1 つで、3 段階の最適化ステージで構成されます。ZeRO (ZeRO-3) の最適化ステージ 3 では、最適化の状態と勾配、モデルのパラメーターをワーカー処理の全体に分割することで、分散トレーニング中のメモリー消費を抑えます。以下の図は、各ワーカーがパラメーター・サブセット 1 つのみを保持している状態を示したものです。前方パス / 後方パスを実行する準備として、必要なパラメーターが集団通信演算によって実行直前に用意されます。実行後、後続の前方パス / 後方パスまで不要となったパラメーターは削除されます。なお、パラメーター更新フェーズで各ワーカーがアップデートする必要があるのは、自分に割り当てられたパラメーターに対応するオプティマイザーの状態のみです。
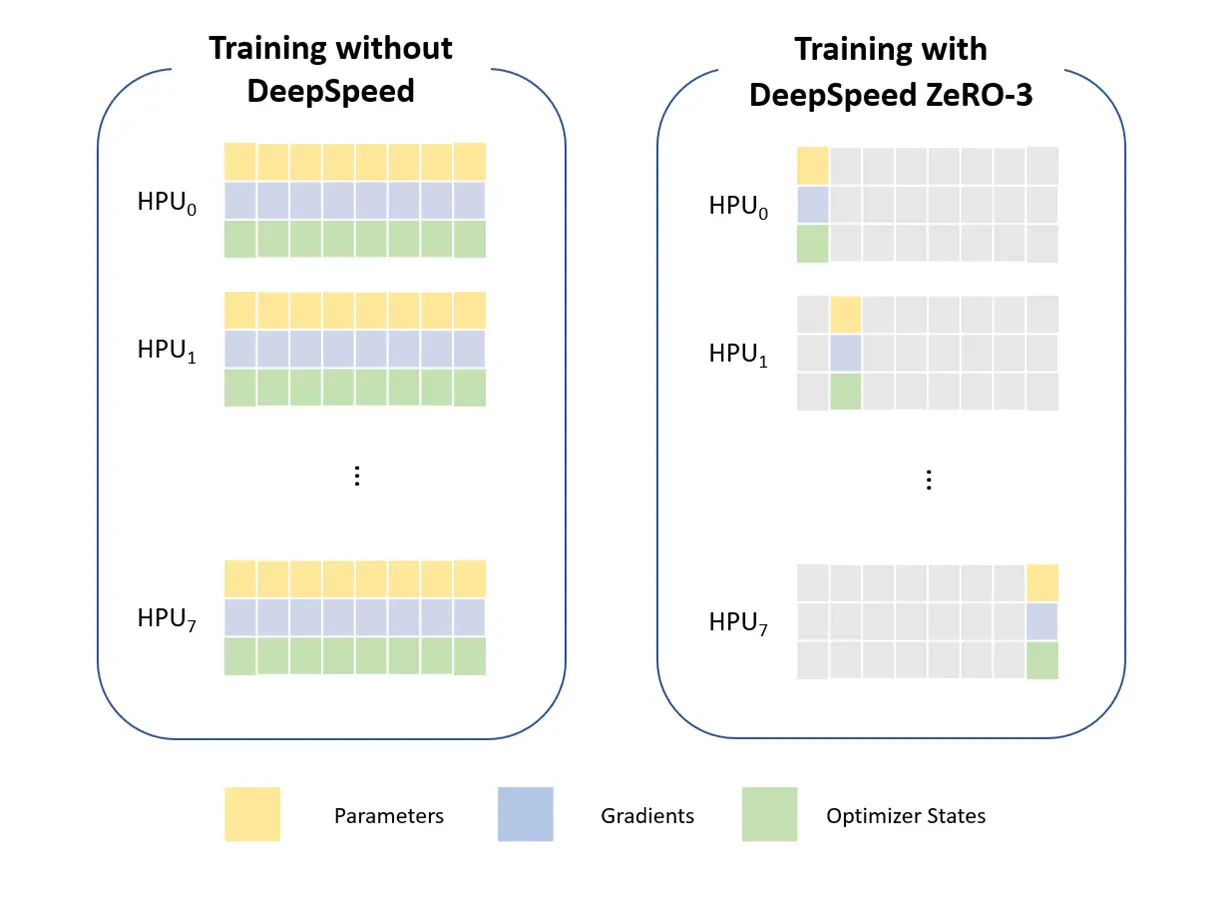
DeepSpeed ZeRO-3 による最適化
最適化に DeepSpeed ZeRO-3 を用いることでメモリー消費を大幅に削減できるものの、Llama2-70B 全パラメーターのファインチューニングは、8 枚のインテル® Gaudi® 2 アクセラレーター・カードを使用したとしても、やはり不可能です。700 億パラメーター・モデルの場合、必要になるメモリー容量は全体で約 1.1TB (HLS-2 サーバーに搭載されるインテル® Gaudi® 2 アクセラレーター・カード 1 枚につき 140GB) となり、その内訳は、BF16 精度でのモデル・パラメーターのロードに 140GB (2 バイト x 700 億)、BF16 精度の勾配に 140GB (2 バイト x 700 億)、FP32 精度での Adam オプティマイザーの状態 (パラメーター、勾配の慣性と分散量) に 840GB (3 x 4 バイト x 700 億) を消費することになります。そのためインテルでは、ファインチューニングの対象をパラメーター・サブセット 1 つのみにしてリソース消費を軽減する、パラメーター効率ファインチューニング (PEFT) の手法を取り入れました。
【低ランク適応 (LoRA) の PEFT】
パラメーター効率ファインチューニング (PEFT) は、リソース消費の大きい大規模言語モデルのファインチューニングにとって、コスト効率の高いソリューションです。モデル全体ではなく、モデル・パラメーターの一部のみをファインチューニングの対象とし、特定のダウンストリーム・タスクに事前学習処理済みのモデルを適応します。低ランク適応 (LoRA) は、さまざまな PEFT 手法の中でも最もよく使用されている方法の 1 つです。LoRA では、事前学習済みモデルの重み付けを固定し、低ランクの行列で重み付けを更新することで、トレーニングするパラメーター数を大幅に減らすことができます。その理由は、事前学習済み重み付けのファインチューニングは、事前学習済み重み付け (W0) と勾配更新の累積 (ΔW) の合計で表すことができ、これを 2 つの低ランク行列 A と B に分解できるからです。

前方パスでは、入力特徴量に事前学習済み重み付け W0 と勾配更新の累積 ΔW = BA の両方を乗算します。ここにそれぞれの出力を加算すると、結果が割り出されます。後方パスでは、事前学習済みのフルランクの重み付けが固定されている間、A と B が勾配更新を受け取ります。
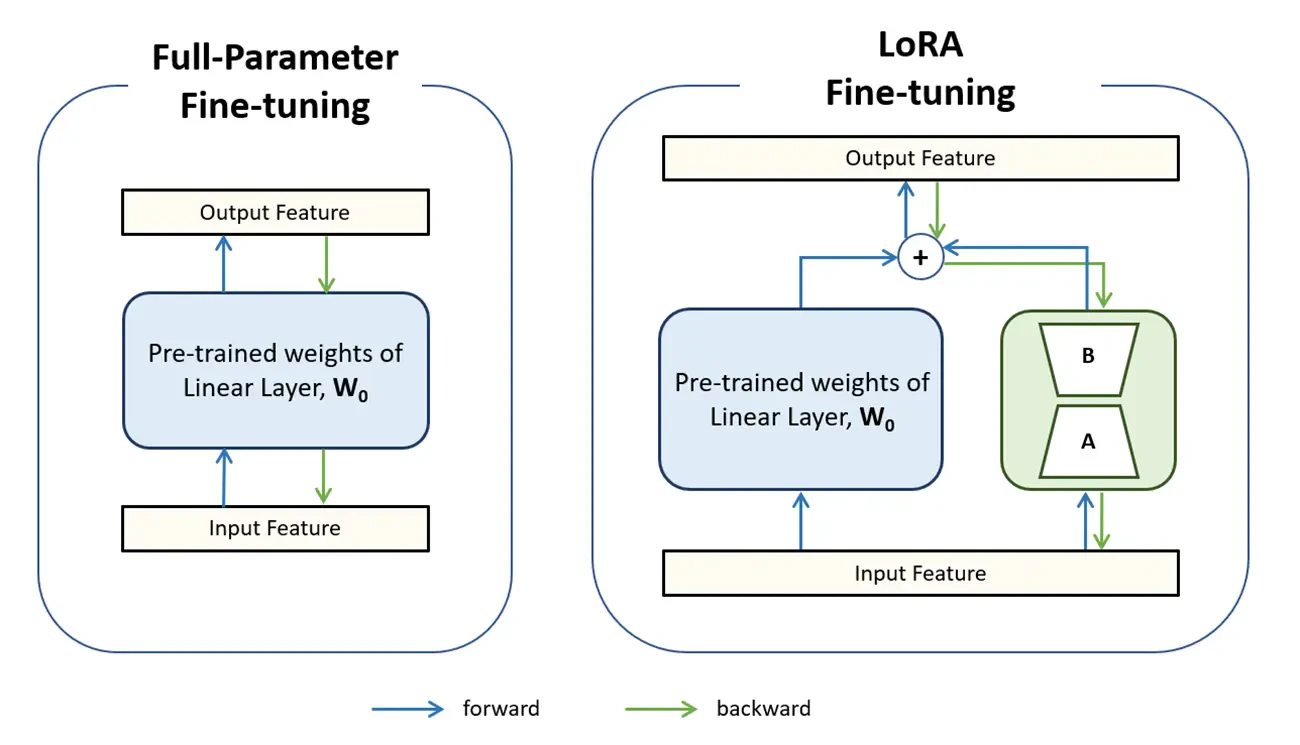
低ランク適応 (LoRA) のパラメーター効率ファインチューニング
【ZeRO-3 と LoRA を使用し 8 枚のインテル® Gaudi® 2 アクセラレーター・カード上で実行する Llama2-70B のファインチューニング】
インテル® Gaudi® アクセラレーター SynapseAI 1.13.0 リリースより、ZeRO-3 最適化と LoRA を使用し 8 枚のインテル® Gaudi® 2 アクセラレーター・カード上で Llama2-70B のファインチューニングが有効になりました。モデルの学習処理パフォーマンスを向上させる目的で、出力結果の精度に妥協することなくアテンション層の softmax 関数を bfloat16 精度で実行するためのサポートを追加しています。さらに、内部グラフのサイズに制約を設け、同期ポイントを追加することで、DeepSpeed ZeRO-3 のメモリー消費を最適化しました。環境変数 PT_HPU_MAX_COMPOUND_OP_SIZE と DEEPSPEED_HPU_ZERO3_SYNC_MARK_STEP_REQUIRED は、最適化を有効にするスイッチとして、コマンドとともに使用されます。
インテル® Gaudi® 2 アクセラレーターで実行するファインチューニングに DeepSpeed ZeRO-3 最適化を適用するには、“zero_optimization” エントリー配下にあるディクショナリー内で "stage" を "3" に、"overlap_comm" と "contiguous_gradients" を “false” に設定します。これらの DeepSpeed 設定は .json ファイル形式で構成され、この例の場合 .json ファイルはすでに Optimum-Habana GitHub リポジトリー (llama2_ds_zero3_config.json) へ事前ロード済み、以下の runtime コマンドに含まれています。
LoRA にトレーニング可能な低ランク行列を “q_proj”、“k_proj”、“v_proj”、“o_proj” モジュールへ投入し、LoRA ランク 4、LoRA α 16、ドロップアウト確立 0.05 を LoRA 構成に使用しました。
この例では Alpaca データセット を 2 エポックで集約し、ローカルのバッチサイズを 10、最大シーケンス長を 2,048 として、Llama2-70B をファインチューニングしています。なお、トレーニングのバッチサイズ 10 は、メモリー使用率の最大化ではなく、精度向上を目的に選択した点にご留意ください。このデバイスメモリーには比較的大きめのバッチサイズも収まりますが、Alpaca データセットの場合、結果的にエポック当たりの重み付け更新回数が少なくなるため、収束は難しくなります。インテルは Llama2-70B ファインチューニングのサンプルを Optimum Habana GitHub リポジトリーに提供しました。Optimum-Habana は、HuggingFace Transformers ライブラリーとインテル® Gaudi® アクセラレーターの間をつなぐインターフェイスです。このサンプルを実行するには、Docker イメージを Habana Vault から取得し、Optimum-Habana リポジトリーのクローンを作成して、Docker コンテナ内に、作成したレポジトリーのクローンから Optimum-Habana をインストールします。また、Habana DeepSpeed と Llama2-70B のファインチューニングに必要な Python 依存パッケージもインストールしてください。
https://huggingface.co/datasets/tatsu-lab/alpaca
https://github.com/huggingface/optimum-habana/tree/main/examples/language-modeling##peft
https://github.com/huggingface/optimum-habana.git
https://vault.habana.ai/ui/repos/tree/General/gaudi-docker
https://github.com/HabanaAI/deepspeed

8 基のインテル® Gaudi® 2 アクセラレーターを使用してこのファインチューニングのサンプルを実行するには、optimum-habana/examples/language-modeling/ ディレクトリーに移動し、以下のコマンドを実行します。

8 枚のインテル® Gaudi® 2 アクセラレーター・カードを使用して Llama2-70B のファインチューニングを行い 2 エポック完了するまでには約 44 分かかります。
【まとめ】
このブログでは、DeepSpeed ZeRO-3 による最適化と LoRA の手法を適用して 8 基のインテル® Gaudi® 2 アクセラレーターで Llama2-70B のファインチューニングを行う手順について紹介しました。ここに挙げた例では主に Llama2-70B に焦点を当てていますが、ほかの LLM にも幅広く適用できる手法です。
インテルは Llama2-70B 以外にも、広く導入されている LLM も同様に、今後のリリースにおけるパフォーマンス向上を目指し継続的に取り組んでいます。最新のリリース情報をお見逃しなく。通常は 6 ~ 8 週間隔で更新しています。
<参照元>
1.Rajbhandari ほか、「ZeRO: Memory Optimizations Toward Training Trillion Parameter Models」、arXiv:1910.02054
2.Hu ほか、「LoRA: Low-Rank Adaptation of Large Language Models」、arXiv:2106.09685
3. https://developer.habana.ai/blog/memory-efficient-training-on-habana-gaudi-with-deepspeed/ (英語)
<補足情報: Llama 2 モデルへのアクセスと使用方法>
事前学習済みモデルの使用は、「Llama 2 Community License Agreement (LLAMA2)」を含め、サードパーティー・ライセンスの遵守が求められます。LLAMA2 モデルの意図されている使用方法、誤用や適用範囲外と考えられる使い方、想定されるユーザー、その他の条件に関するガイダンスは、こちらのリンク先 https://ai.meta.com/llama/license/ (英語) に記載されている指示をご確認ください。ユーザーはサードパーティーのライセンスに従いこれを遵守することについて単独の責任および義務を負うものとします。また、ユーザーによるサードパーティー・ライセンスの使用または遵守に関して、Habana Labs はいかなる責任も負いません。
この Llama-2-70b-hf のようなゲート付きモデルを実行するには、以下のアカウントおよび同意が必要となります。
•HuggingFace アカウント
•HF Hub のモデルカードに記載されているモデル利用規約への同意
•読み込みトークンの設定
•スクリプト開始前に、HF CLI を使用した huggingface-cli login の実行による登録済みアカウントへのログイン