
Jade-Worrall
所属: インテル
2025年4月28日
著者: Intel® Liftoff プログラム、シニア・ソリューション・エンジニア Sri Raj Aryan、エンジニアリング担当主任 Rahul Unnikrishnan Nair
https://community.intel.com/t5/user/viewprofilepage/user-id/178146
理論的なスペックなど忘れてください。Intel® Liftoff プログラムのメンターや AI エンジニアたちは、インテル® データセンター GPU マックス・シリーズ 1100 とインテル® Tiber™ AI クラウドを徹底的に活用し、得られたインサイトを、スリムでありながら高スループットの LLM パイプラインを追求するスタートアップ企業のためのフィールドガイドへと転換しました。
詳しく見ていく前に、まずは前提条件を確認しておきましょう。ここで説明するベンチマーク、テスト、開発などの作業はすべて、インテル® Tiber™ AI クラウドを通じて実施しました。
インテル® Tiber™ AI クラウドは、開発者や AI スタートアップ企業がインテルの AI ハードウェア・ポートフォリオを高い拡張性とコスト効率で利用できるように設計された、マネージド・クラウド・プラットフォームです。このプラットフォームにはインテル® Gaudi® 2 アクセラレーター (およびインテル® Gaudi® 3 アクセラレーター)、インテル® データセンター GPU マックス・シリーズ、最新のインテル® Xeon® スケーラブル・プロセッサーも含まれます。演算負荷の高い AI モデルの構築と実装を目指すスタートアップ企業に、インテル® Tiber™ AI クラウドはハードウェアへの初期投資という大きな障壁をなくしつつ、パフォーマンスに最適化された環境を提供します。
AI スタートアップ企業のメンバーとして、インテル® データセンター GPU マックス・シリーズやインテル® Gaudi® アクセラレーターの可能性を探求し、インテル® Tiber™ AI クラウドの最適化された環境を独自のプロジェクトに活かしたいのなら、AI スタートアップ企業向けの Intel® Liftoff プログラムへの参加を強くおすすめします。
https://www.intel.com/content/www/us/en/developer/tools/oneapi/liftoff.html
このプログラムは、皆さんのようなスタートアップ企業をサポートする、リソース、技術的な専門知識、インテル® Tiber™ AI クラウドといったプラットフォームへのアクセスを提供するために設計されました。

AI 駆動のアプリケーションは、画像、テキスト、音声など、マルチモーダル・データにますます依存するようになっています。このブログでは、ベクトル型データベースの Chroma と埋め込みを生成する OpenCLIP を用いて、画像とテキストの両方を格納 / 検索できるマルチモーダル・データベースの構築とクエリー実行の手順を紹介します。
ここで生成される埋め込みによって、異なる形式のデータを効率的に比較 / 検索できるようになります。このプロジェクトの目的は、画像データを処理してテキストベースの検索クエリーを実行するシステムの構築だけではなく、同時に GPU や xPU のアクセラレーションによりパフォーマンスを拡大することです。
<最先端の AI を動かすインテル® データセンター GPU マックス・シリーズ 1100>
によるアクセラレーションは、インテル® データセンター GPU マックス・シリーズなどの強力なハードウェアによって実現するものです。インテル® データセンター GPU マックス・シリーズ 1100 は、無償のインテル® Tiber™ AI クラウド JupyterLab 環境で次のような専用インスタンスとして利用できます。
https://intel.github.io/intel-extension-for-pytorch/xpu/latest/
• 演算アーキテクチャー (Xe-HPC):
o Xe-core: GPU 演算タスクの基盤を形成する 56 個の専用コア
o インテル® Xe マトリクス・エクステンション (インテル® XMX) エンジン: 448 個のエンジンにディープラーニング用シストリック・アレイを実装、AI/DL モデルで広く実行される高密度の行列 / ベクトル演算のアクセラレーションに最適化
o ベクトル演算エンジン: 448 個のエンジンがインテル® XMX ユニットを補完して幅広い並列タスクを処理
o レイ・トレーシング・ユニット: ハードウェア・アクセラレーションによる 56 ユニットのレイ・トレーシング、視覚化機能を拡張
• メモリーの階層構造:
o 広帯域幅メモリー (HBM2e): 48GB の HBM2e メモリーが 1.23TB/s の帯域幅を実現、マルチモーダルの埋め込みに用いられる大規模データセットの複雑なモデルに不可欠
o キャッシュ: 28MB の L1 キャッシュと 108MB の L2 キャッシュを備え、演算ユニットの近くにデータを保持してレイテンシーを最小化
• 接続:
o PCIe Gen 5: 高速 PCIe Gen 5 x16 ホスト・インターフェイスを経由した CPU と GPU 間の高速データ転送
• ソフトウェア・エコシステム (oneAPI): インテル® データセンター GPU マックス・シリーズは、インテル® oneAPI ベース・ツールキットを活用して構築された標準ベースのプログラミング・モデルとのシームレスな連動を目的に設計されました。そのため、開発者は HuggingFace の Transformers、Pytorch、インテル® PyTorch 拡張パッケージなどのフレームワークや、ほかにもインテルのアーキテクチャー (CPU と GPU) に最適化済みの多様なライブラリーを利用して、ベンダー独自のフォーマットにとらわれることなく、AI パイプラインを高速化できます。
<コードの解説>
このコードでは、画像とテキストの埋め込みを格納するベクトル型データベースとして Chroma を使用したマルチモーダル・データベースのセットアップ手順を詳しく解説します。次に、データベースにテキスト形式のクエリーを実行し、類似する画像やメタデータを検索します。また、インテル® PyTorch 拡張パッケージを使用した PyTorch 用のハードウェア・アクセラレーション手法により、CPU や xPU (アクセラレーション・プロセシング・ユニット) などインテルのデバイス上で実行する演算処理を高速化する方法についても説明しています。
コードの主な構成コンポーネントは以下のとおりです。
- 画像とテキストの埋め込み: OpenCLIP (CLIP ベースのモデル) を使用して画像とテキストの埋め込みを生成し、簡単に検索できるようにデータベースへ格納。幅広いベンチマークで実証済みの強力なパフォーマンスと、事前学習済みモデルをすぐに利用できることから、OpenCLIP を選びました。
- Chroma データベース: 埋め込みを格納する持続性データベースの構築。テキスト形式のクエリーにより、最も類似性の高い結果を効率的に検索可能。Python ネイティブの API であること、持続性マルチモーダル集合のセットアップしやすさ、開発者体験を重視している点から、ChromaDB を選択しました。
- ハードウェア・アクセラレーション: ハードウェア・アクセラレーションが可能な xPU かどうかをコードが確認。インテル® PyTorch 拡張パッケージによりインテルのハードウェア・アクセラレーションを追加することで、埋め込み生成といったタスクを最適化し、データ処理を高速化するため、高性能アプリケーションに最適です。
ユースケースとアプリケーション
例えば次のような用途を含め、どのようなシナリオにも有効なコードです。
• マルチモーダル・データの格納: 画像やテキスト、または両方を格納して検索する、高速かつ拡張可能な方法が必要。
• 画像検索: 例えば、“黒のベンツ” のようなテキスト形式の記述をもとに類似する車の画像を検索するクエリーの実行など、eコマースのプラットフォーム、画像検索エンジン、レコメンデーション・システム。
• クロスモーダル検索: テキストをもとに類似画像を検索 (またはその逆) のような、1 種類のデータ形式 (画像) を対象に別のデータ形式 (テキスト) で検索をかける場合。視覚的 Q&A (VQA) や字幕 / タイトルから画像を検索するシステムでよく見られます。
• レコメンデーション・システム: 類似度に基づきクエリーを実行し、ユーザーの検索内容とセマンティックな類似性が高い、おすすめの製品、映画、コンテンツを表示。
• AI ベースのアプリケーション: 学習用データの生成、特徴の抽出、マルチモーダル・モデルに使用するデータの前処理など、マシンラーニングのパイプラインに最適。
必須要件:
• ディープラーニング操作用の torch
• intel_extension_for_pytorch (インテル® PyTorch 拡張パッケージ) により、パフォーマンスを PyTorch に最適化
• ベクトル型の持続性マルチモーダル・データベースを構築してクエリーを実行する chromaDB
• 画像表示の matplotlib
• OpenCLIPEmbeddingFunction (埋め込みの抽出) と ImageLoader (画像のロード)
<コードの詳細>
ステップ 1: 必要ライブラリーのインポート、ディレクトリー設定、デバイスの選択
このコードは、必要な Python パッケージをインポートして、画像と持続性ベクトル型データベースの格納ディレクトリーを定義するところから始まります。
get_device() 関数: xPU (インテル® Tiber™AI クラウドで利用可能なインテル® データセンター GPU マックス・シリーズのようなディスクリート型 GPU を指します) が有効かどうかを確認し、デバイスとして選択。利用できなければデフォルトの CPU を選択。有効な場合は、xPU を活用することで演算処理が高速化し、負荷の高いワークロードでは特にメリットがあります。
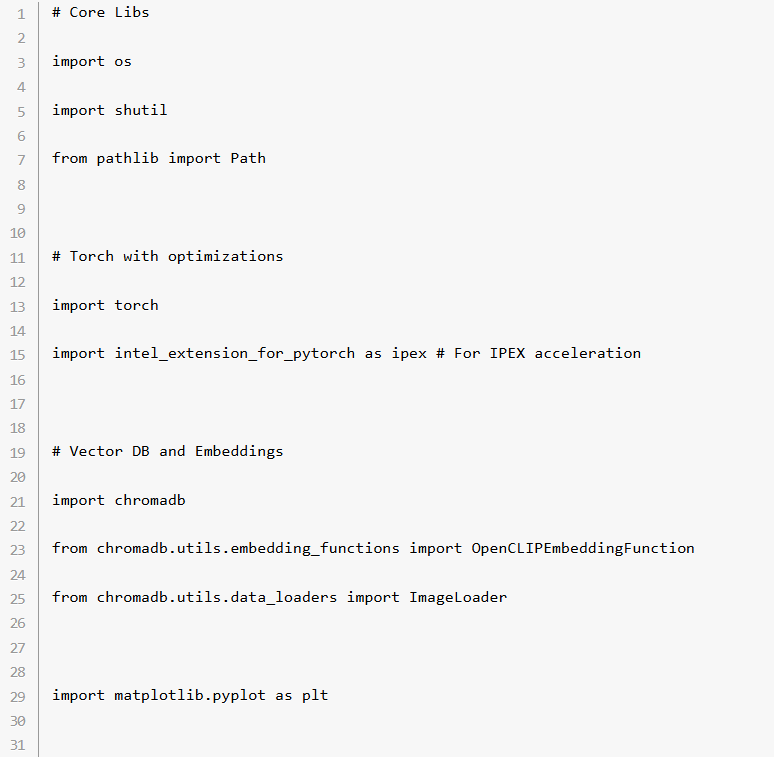

ステップ 2: Chroma データベースの初期化
initialize_chroma() 関数を実行すると、Chroma クライアントが初期化され、ベクトル型データベースとのインタラクションが開始。すでにデータベースのディレクトリーが存在する場合は削除後に新しく作成されます。

ステップ 3: データベース集合のセットアップ
次に、Chroma にマルチモーダル・データベースを構築。このデータベースに画像とテキストの両方の埋め込みを格納してクエリーを実行します。

• ImageLoader() 関数: ファイルシステムから画像データを読み込み
• OpenCLIPEmbeddingFunction() 関数: 画像とテキストの両方の埋め込みを生成して、類似度ベースのクエリーを実行
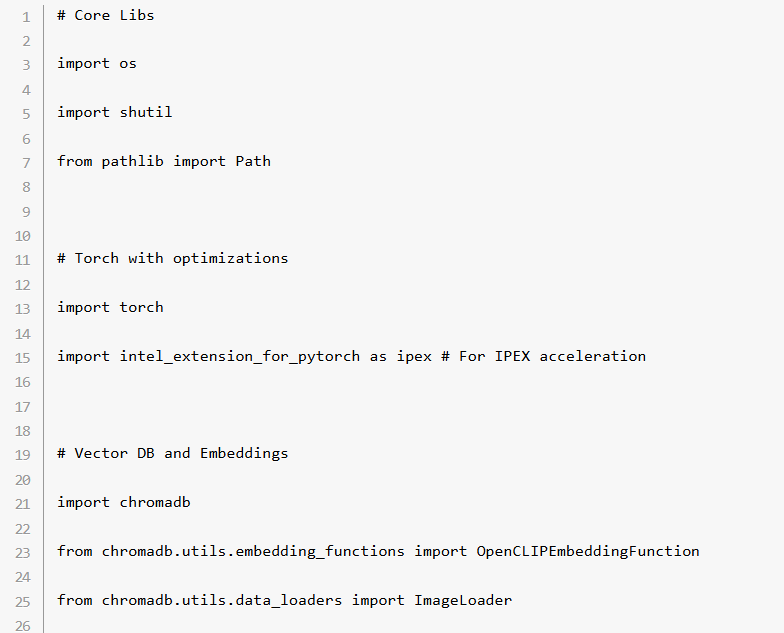
ステップ 4: データベースに画像を追加
add_images_to_db() 関数は、あらかじめ指定したディレクトリーからの画像を処理して Chroma データベースに追加。画像は個別の ID でインデックス付けされます。

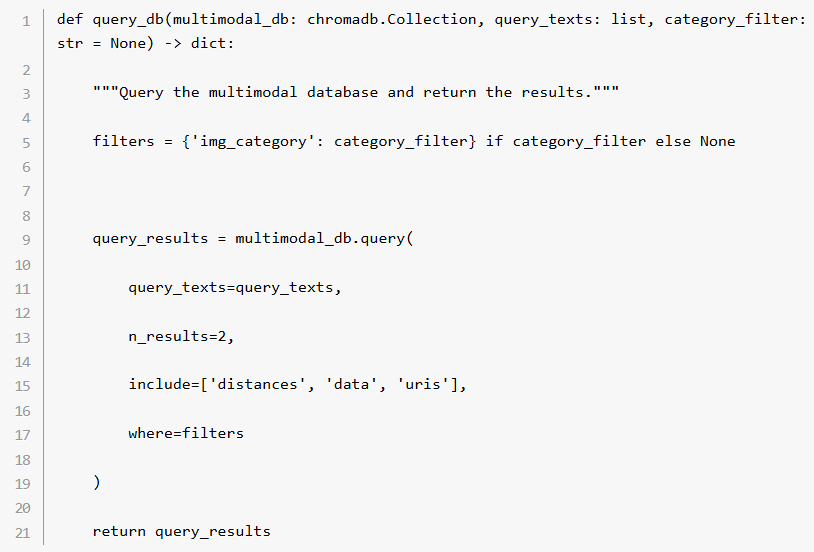
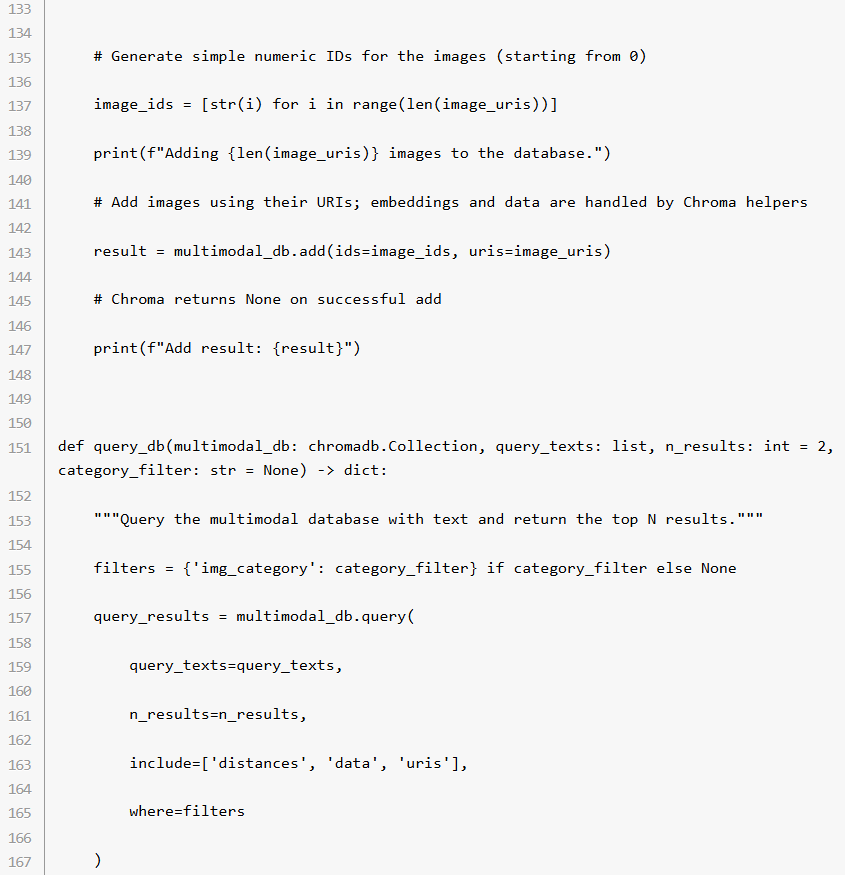
ステップ 5: データベースにクエリーを実行
query_db() 関数によって、テキストをもとにデータベースにクエリーを実行。入力されたテキスト形式クエリーとの類似性に基づき、上位 N 個の結果が抽出されます。
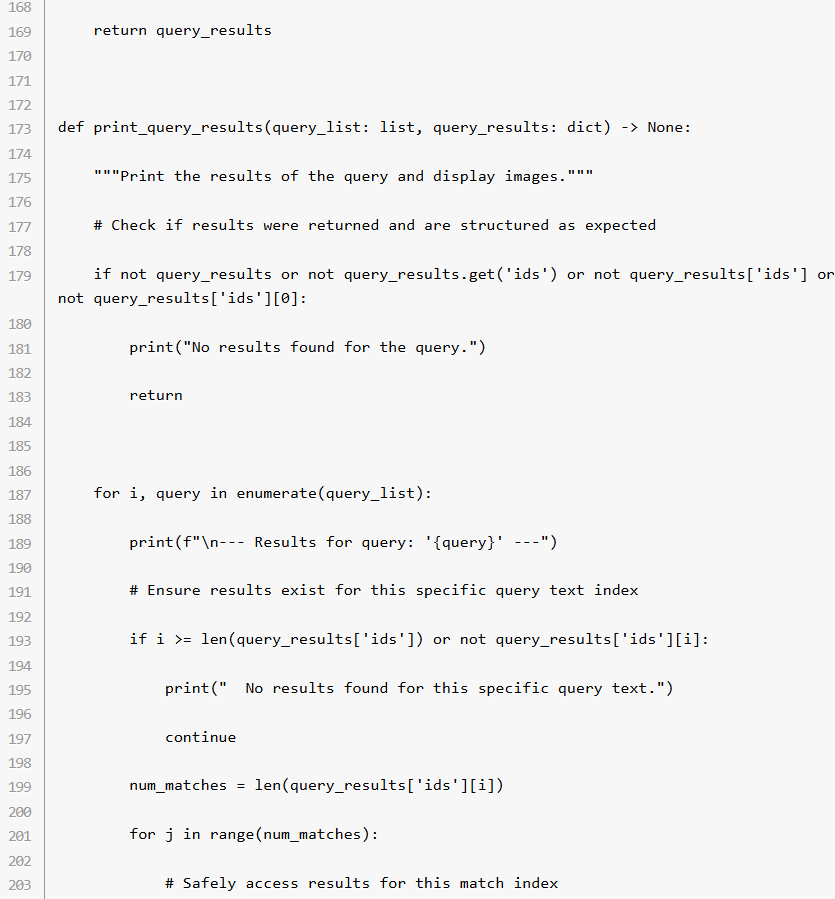
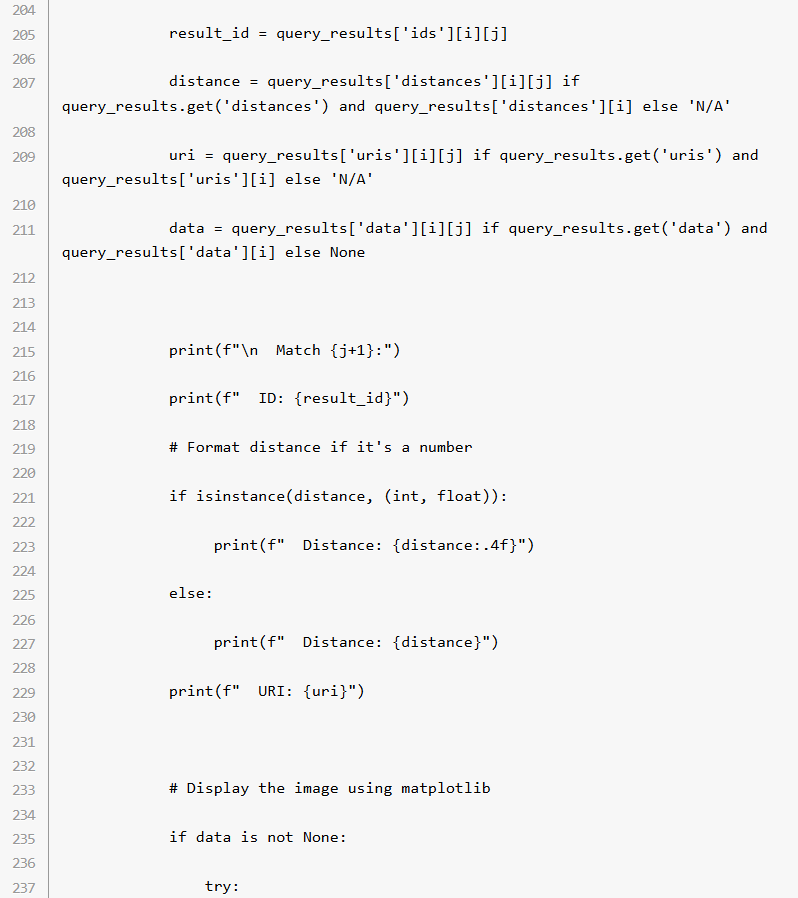
ステップ 6: クエリーの検索結果を表示
データベースへのクエリー後、print_query_results() 関数はマッチ度が最も近い画像を含めた検索結果を出力。
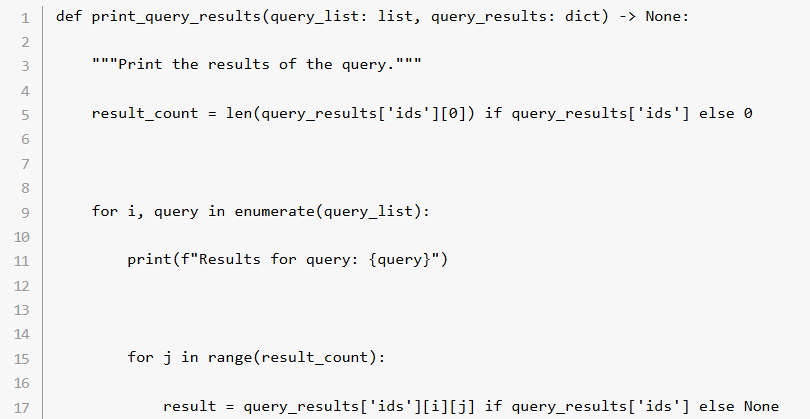

ステップ 7: メインのワークフロー
最後は main() 関数によってプログラムの実行を調整。デバイス、Chroma クライアント、マルチモーダル・データベースの初期化から、画像の追加、サンプルクエリーの実行までを一括で行います。

出力:
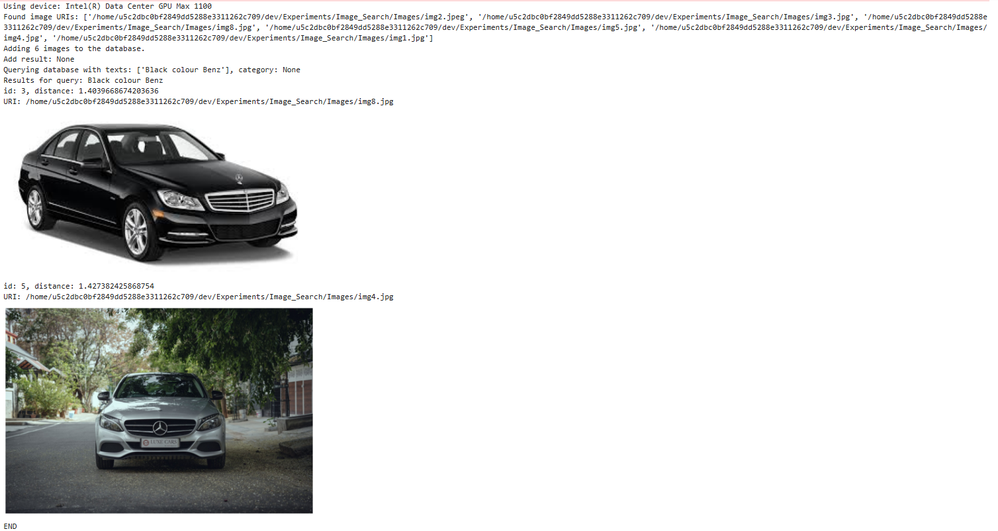
入力したクエリー: "黒のベンツ"
出力結果:


<実行コードの全体>
この下に、ここまで説明してきた Python スクリプトの全体を載せています。インテル® データセンター GPU マックス・シリーズ 1100 など、インテル® Tiber™ AI クラウドで利用可能なインテルのハードウェア上でインテル® PyTorch 拡張パッケージを活用し、ChromaDB を使用した持続性マルチモーダル・データベースのセットアップ、OpenCLIP によるローカル画像の埋め込み生成、テキスト形式の画像検索を実行する手順をデモ用コードでまとめています。
前提条件:
必要なライブラリー (torch、intel-extension-for-pytorch、chromadb、matplotlib、open_clip_torch) がインストールされているか確認してください。通常は以下のように pip コマンドでインストールします。
https://intel.github.io/intel-extension-for-pytorch/
pip list torch intel-extension-for-pytorch chromadb matplotlib open_clip_torch Pillow
# if not available install (ensure ipex for xpu is used)
# pip install torch intel-extension-for-pytorch chromadb matplotlib open_clip_torch Pillow
(注: インテル® Tiber™ AI クラウド経由ではない場合は、実際のハードウェア環境に合わせて intel-extension-for-pytorch のインストールを調整してください。)
このスクリプトを保存したディレクトリーに、サブディレクトリー "Images" を作成し、
このサブディレクトリー "Images" 内に画像ファイル (.jpg、.jpeg、.png) を配置します。
以下のコードブロック全体をコピーして Python ファイル (multimodal_search.py など) として保存し、実際にマルチモーダル検索が動くか確認することも可能です。





本番環境用コードに関する注意:
この例では分かりやすさを優先してデモ用のコードを紹介していますが、(initialize_chroma でのディレクトリーの削除 / 作成など) ファイルシステムの操作を行う本番環境の実装では、try...except ブロックで示しているようなエラー処理が必ず発生します。
認証エラーやファイルシステムの例外といった起こりうる問題にスムーズに対処して、予期せぬクラッシュを回避し、信頼性の向上につながるようにしてください。
<まとめ>
このスクリプトでは、画像とテキストを効率的に格納してクエリー検索を実行できる、Chroma と OpenCLIP によるマルチモーダル・データベースの構築方法を説明しました。PyTorch、インテル® PyTorch 拡張パッケージ、Chroma のパワーを組み合わせた、画像検索やレコメンデーション・システムなど、クロスモーダルのデータ検索を実行する幅広いユースケースに適応可能なワークフローです。
インテルのハードウェア・アクセラレーションを追加することでデータ処理が高速化されるため、高性能アプリケーションに最適な設定となっています。
ぜひインテル® Tiber™ AI クラウドを自分で試してみてください
ここで紹介したコードを実行して、インテル® データセンター GPU マックス・シリーズ 1100 のパフォーマンスを直接体験してみることが可能です。例えばインテル® Tiber™ AI クラウドでは、次のようなリソースを提供しています。
• 無償の JupyterLab 環境: インテル® データセンター GPU マックス・シリーズ 1100 を実際に操作して学習処理や評価を実行。cloud.intel.com にアクセスしてアカウントを登録し、"Training" セクションから GPU アクセラレーション対応の Jupyter Notebook を起動できます。
• 仮想マシン & ベアメタル: インテル® データセンター GPU マックス・シリーズ 1100 搭載 VM 1 台 (カード当たり 1 時間 0.39 ドル~)、または、高速ブリッジ経由のパワフルなマルチ GPU 搭載システムへのアクセス。対象の AI スタートアップ企業は、Intel® Liftoff プログラムを通じた PoC クレジットを利用できます。詳細については、インテル® Tiber™ AI クラウドの利用料リストを参照してください。
https://ai.cloud.intel.com/
<関連リソース>
インテル® Tiber™ AI クラウド - AI 開発 / 実装のためのクラウド・プラットフォーム
https://ai.cloud.intel.com/
インテル® データセンター GPU マックス・シリーズ - データセンターの高負荷アプリケーション向けにカスタマイズされ、AI や HPC ワークロードの高速化を目的に設計されたハイパフォーマンス GPU
https://www.intel.co.jp/content/www/jp/ja/products/details/discrete-gpus/data-center-gpu/max-series.html