Eugenie_Wirz
所属: インテル
2025年4月30日
著者:YeHur Cheong、Rahul Unnikrishnan Nair
https://community.intel.com/t5/user/viewprofilepage/user-id/245396
インテル® Liftoff プログラムのメンバーである Embedded LLM は JamAI Base の開発元です。JamAI Base は AI ネイティブな共同作業型の表計算シートで、各セルがインテリジェント・エージェントとして働くため、ユーザーは複雑な AI パイプラインをシンプルかつ素早く構築できます。
https://embeddedllm.com/
Embedded LLM は知識経済 (ナレッジエコノミー) にとって基盤となる “電力網” のようなソフトウェアの提供を使命として掲げており、高度なモデル・オーケストレーションのためのツール、TokenVisor の開発にも携わっています。
こうした取り組みの一環として、インテル® Gaudi® 2 アクセラレーターと NVIDIA A100 のベンチマーク比較を実施。これにより、企業の AI 導入において大きな意味を持つ、パフォーマンスと効率性の大幅な向上が明らかになりました。
<インテル® Tiber™ AI クラウドでの実装とスタートアップ企業への招待>
インテル® Gaudi® 2 ソフトウェア・スタックと大規模言語モデル (LLM) 向けパフォーマンス最適化について詳しく見ていく前に、前提を共有しておきましょう。この記事で紹介するベンチマーク、テスト、開発作業は、インテル® Tiber™ AI クラウドを用いて行われました。
インテル® Tiber™ AI クラウドは、開発者と AI スタートアップ企業が、スケーラブルでコスト効率の高いインテルの先進的な AI ハードウェア・ポートフォリオを利用できるように設計された、クラウド・プラットフォームです。
ここには、インテル® Gaudi® 2 アクセラレーター (およびインテル® Gaudi® 3 アクセラレーター)、インテル® データセンター GPU マックス・シリーズ、インテル® Xeon® スケーラブル・プロセッサーが含まれます。
演算負荷の高い AI モデルの構築と実装を目指すスタートアップ企業にとって、インテル® Tiber™ AI クラウドはハードウェアへの初期投資という大きな障壁をなくしつつ、パフォーマンスに最適化された環境を提供するプラットフォームです。
AI を取り巻く環境は大規模言語モデル (LLM) の驚くべき可能性によって、常にその姿を変えています。LLM は高度な推論を必要とするアプリケーションに次々と実装され、AI ができることの限界を押し広げているのです。
しかし、このような高度な LLM に求められる膨大な演算処理能力は、大量の入力シーケンスを処理する複雑な推論の場合は特に、LLM の幅広い採用が進む中、効率的に導入していくうえで大きな課題となっています。[1]
スタートアップ企業も大規模企業も同様に、このようなパフォーマンスと効率のハードルを乗り越えるための革新的なソリューションを求めています。
こうした状況を背景に、魅力的な選択肢として登場したインテル® Gaudi® 2 AI アクセラレーターは、要求の厳しい推論型 LLM をはじめ、最新の AI ワークロードにおける複雑な演算処理に対応するために設計されました。
Intel® Liftoff プログラムに参加しているスタートアップ企業にとって、高性能の追求とコスト効率の両立は極めて重要です。インテル® Gaudi® 2 アクセラレーターはディープラーニング・タスクの高速化を目的にゼロから設計されており、そこに備わる独自の機能は、最先端の AI モデルを導入しようとする企業に強力な競争優位性をもたらします。
高効率の演算処理と広帯域幅メモリーを軸とする設計理念は、LLM での複雑な推論処理に不可欠な要素です。
<エンジンの最適化: インテル® Gaudi® 2 アクセラレーターの LLM パフォーマンスを支えるハードウェアとソフトウェア>
インテル® Gaudi® 2 アクセラレーターで LLM に最高水準のパフォーマンスを発揮させるとき、特に vLLM のようなフレームワークでベンチマーク評価される負荷の高い長文シーケンスのシナリオでは、強力なシリコンだけでは不十分です。
SynapseAI のソフトウェア・スタックと専用のハードウェア・アーキテクチャーの間で、シームレスな相互作用が実現されていなければなりません。この 2 つのレイヤーがどのように連動しているのかを理解することが、インテル® Gaudi® 2 アクセラレーターの潜在能力を発揮させるためのカギとなります。
SynapseAI ソフトウェア・スタック: 処理の変換と最適化
インテル® Gaudi® 2 ソフトウェアのエコシステムの中心にあるのは、ディープラーニング向けに設計されている Habana の SDK、SynapseAI です。これは、vLLM に使用される PyTorch などの主要なフレームワークと、基盤となるインテル® Gaudi® 2 プラットフォームを橋渡しする重要な役割を担います。SynapseAI は単に処理を変換するだけではなく、演算グラフを有効にコンパイル / 最適化し、HPU 上で最大の効率を引き出します。主な最適化手法は以下のとおりです。
https://docs.habana.ai/en/latest/Gaudi_Overview/Intel_Gaudi_Software_Suite.html
グラフコンパイルとレシピのキャッシング: SynapseAI には PyTorch モデルで定義された演算シーケンスを解析するグラフ・コンパイラーが搭載されています [出典: Habana ドキュメント]。このコンパイラーは、グラフを最適化し、HPU に合うように演算カーネルをコンパイルします。その後の実行と初期化時間を高速化するために、SynapseAI は "レシピのキャッシング" を適用します。コンパイルされたグラフセグメントやカーネル (つまり "レシピ") を保存 (PT_HPU_RECIPE_CACHE_CONFIG などの環境変数により設定可能) することで、その後のロードが素早くなり、冗長なコンパイル作業を回避できます [出典: Habana ドキュメント]。
https://docs.habana.ai/en/latest/PyTorch/Reference/Runtime_Flags.html
オーバーヘッドを抑える HPU グラフ: HPU グラフは推論を行うホスト CPU のオーバーヘッドを最小限に抑える、SynapseAI の強力な機能です [出典: Habana ドキュメント]。PyTorch の @hpu.graphs.capture デコレーターなどのメカニズムを使用することで、1 回または複数回繰り返される演算グラフをキャプチャーでき、デバイス上で直接再現できます。これにより、キャプチャーされたグラフ内の各演算における Python インタープリターのオーバーヘッドが回避され、実行を大きくデバイス依存にできるため、特に LLM のトークン生成が持つ反復性に対して、スループットが向上します。
https://docs.habana.ai/en/latest/PyTorch/Inference_on_PyTorch/Inference_Using_HPU_Graphs.html
重要なウォームアップ段階: インテル® Gaudi® 2 アクセラレーターの初期推論イテレーションでは、レイテンシーが高くなることが多く、この "ウォームアップ" 期間は、SynapseAI が先行して最適化を行うときに欠かせません。
https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/index.html
ウォームアップ中には、初期のグラフコンパイルが行われ、レシピキャッシュが構築されます。HPU グラフが使用されている場合はキャプチャーされます。LLM で多用される重要な KV キャッシュ用の領域を含むメモリーバッファーが割り当てられ、最適化されます [出典: Habana チュートリアル]。こうしたウォームアップへの投資は、その後の推論ワークロードにおける安定した低レイテンシーと持続的な高スループットに直結します。これは実際のデプロイメントに不可欠です。
https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Optimization_Getting_Started.html
インテル® Gaudi® 2 アクセラレーターで実行する vLLM などのフレームワークは、このような SynapseAI による最適化のメリットを直接受けます。vLLM が高レベルのスケジューリングやメモリー管理 (KV キャッシュなど) を行うのに対し、その根幹を成す PyTorch は SynapseAI によるグラフコンパイルや HPU グラフの活用、キャッシングなどのおかげで、HPU 上で効率的に演算を実行します。
https://github.com/HabanaAI/vllm-fork/blob/habana_main/README_GAUDI.md
<インテル® Gaudi® 2 プラットフォームのハードウェア基盤: AI のために構築されたハードウェア>
これらの高度なソフトウェア最適化は、大規模なディープラーニングの要件に応えるために設計されたハードウェア・アーキテクチャー上で実行されます。
https://docs.habana.ai/en/latest/Gaudi_Overview/Gaudi_Architecture.html
コンピューティング・エンジン: 柔軟性と高速化
Tensor プロセッサー・コア (TPC): 高度にプログラマブルな VLIW SIMD プロセッサーが、最新の LLM で見られる幅広い演算を実行し、行列演算だけに限らず、柔軟な処理を可能にします。このプログラマビリティーは、複雑なアテンション機構やカスタムの演算を効率的に実行するカギです。
行列演算エンジン (MME): この専用アクセラレーターは、LLM の演算の中心である密な行列乗算に特化しており、こうした負荷の高い演算を大幅に高速化します。
メモリー階層: 容量、帯域幅、局所性
広帯域幅メモリー (HBM2E): 96GB という大容量が大規模なモデルや長文シーケンスにつきものの膨大な KV キャッシュに対応する一方、最大 2.4 ~ 2.45 TB/s の帯域幅により、コンピューティング・エンジンへのデータ供給が滞ることはありません。
オンチップ SRAM: 高速かつ低レイテンシーの 48MB SRAM が、アクセス頻繁の高いデータを TPC と MME の近くに保持することで、レイテンシーを最小限に抑え、データ局所性を向上させます。
統合型ネットワーキングによる拡張性
RDMA over Converged Ethernet (RoCE v2): 内蔵の高速ネットワーキング (100Gbps x24 ポート) により、標準イーサネット経由で複数インテル® Gaudi® 2 アクセラレーター間の効率的な拡張が可能になります。これは非常に大規模なモデルや高スループットが求められる場合に不可欠です。
<ハイパフォーマンスを実現するシナジー効果>
結論として、インテル® Gaudi® 2 アクセラレーターが実現する LLM パフォーマンスの要因は、特に vLLM などのフレームワークを活用した場合のベンチマーク評価からも分かるとおり、SynapseAI ソフトウェア・スタックと根幹を成すハードウェアの間にある強力なシナジー効果です。
SynapseAI はウォームアップ段階で準備されるグラフコンパイル、HPU グラフ、インテリジェントなキャッシングによって、演算を最適化しています。
このソフトウェアは、柔軟な TPC、高速な MME、大容量 / 広帯域幅のメモリーシステム、内蔵のスケーリング機能を備えたアーキテクチャー上で効率的に動き、これらが強力に連携することで、現在の極めて負荷の高い AI の推論ワークロードに対応しています。
Embedded LLM は自社のインフラストラクチャーを検証するために、長文コンテキストの LLM 推論に焦点をあてた厳格なベンチマーク測定を実施しました。この領域では、ハードウェアの効率性とアーキテクチャーの微妙な違いが深く影響します。検証の結果、ソフトウェアとハードウェア共通の最適化が、AI インフラを決定するうえでいかにパワーバランスを変えうるかが示唆されました。
ここでは、ディープラーニングのワークロード向けに設計されたインテル® Gaudi® 2 AI アクセラレーターが、NVIDIA A100 など従来の GPU に置き換わる、魅力的でコスト優位性の高いソリューションとなっている理由を詳しく見ていきましょう。ファームウェアの強化、高度な量子化手法、最新の vLLM 最適化、インテル® Gaudi® 2 アクセラレーター専用のウォームアップ手順を組み合わせることで、顕著なパフォーマンス向上が達成されていることを実証します。最後に、実環境に即した長文コンテキストの推論シナリオを実行してインテル® Gaudi® 2 アクセラレーターと NVIDIA A100 を比較した結果、LLM 推論の勢力図を塗り替えるインテル® Gaudi® 2 アクセラレーターの可能性が明らかになります。
評価項目は以下のとおりです。
• インテル® Gaudi® ソフトウェア・スイート v1.18 から v1.19 へのアップデートによるパフォーマンスの向上
• FP8 量子化が推論の高速化に及ぼした影響
• 新バージョンの vLLM フレームワークにより可能になった最適化
• 長文シーケンスにおけるインテル® Gaudi® 2 アクセラレーターの可能性を広げるカスタム・ウォームアップ技術
• 長文コンテキストにおける NVIDIA A100 との直接的なパフォーマンス比較
ソフトウェアと最適化の力: v1.18 vs. v1.19
インテル® Gaudi® ソフトウェア・スイート のバージョンが v1.18 から v1.19 へ移行したことで、インテル® Gaudi® 2 アクセラレーターのパフォーマンスが大幅に向上し、さらに高速かつ効率的な LLM 推論が可能になりました。Embedded LLM は Llama3.3-70B-Instruct と ShareGPT データセットを使用してベンチマークを行い、主要な指標すべてが向上していることを示しています。結果は図 1 のとおりです。
検証は、スループットの向上 (リクエストレートで測定) と生成レイテンシーの低減 (出力トークン当たりの時間 TPOT の中央値で測定) に注目して行われました。
• リクエスト・スループット (Req/s): ソフトウェア・スイート v1.19 では、リクエスト・スループットが大幅に向上。リクエストレートが 8 のとき、ソフトウェア・スイート v1.19 ではスループットが 20.62% 高く、1 秒当たりのリクエスト数が 3.54 から 4.27 に増加しています。つまり、インテル® Gaudi® 2 アクセラレーターが同時に処理できるリクエスト数が増え、システム全体の使用率向上を意味しています。
• 出力トークン当たりの時間 (TPOT 中央値): TPOT 中央値も向上。各後続トークンの生成にかかる時間の中央値は 85.06ms から 44.87ms と最大 47% 短縮しました。これは、生成時間の全体的な高速化につながります。
これらの向上すべてを総合して、インテル® Gaudi® 2 アクセラレーターを負荷の高い LLM 推論ワークロードに最適化するうえで、インテル® Gaudi® ソフトウェア・スイート v1.19 が効果的であると言えます。
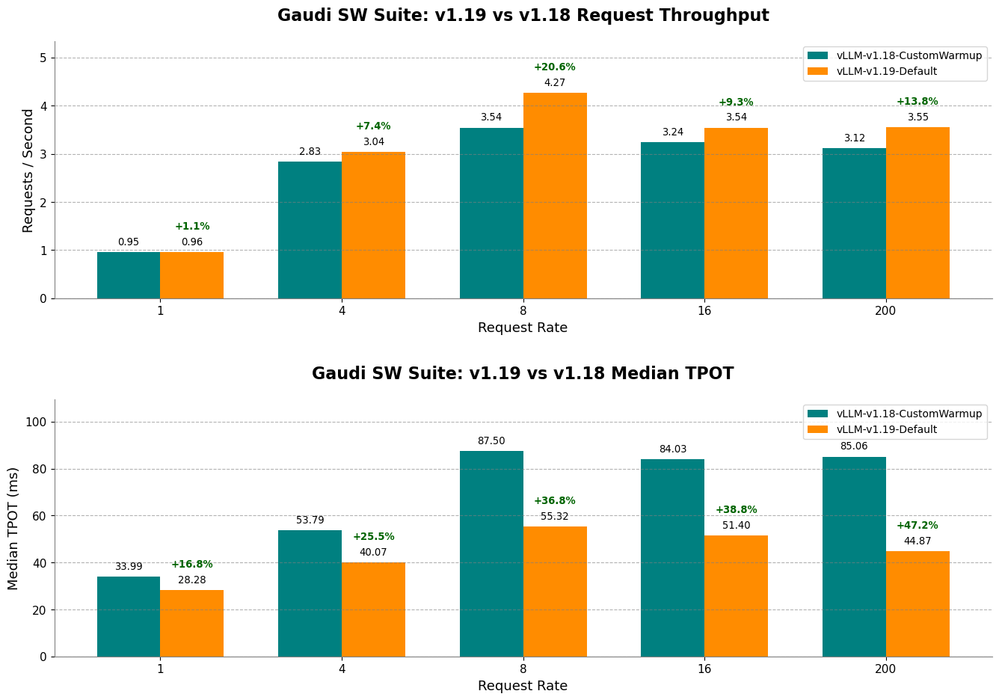
図 1: v1.19 ファームウェア・アップデートにより、リクエスト・スループット (1 秒当たりのリクエスト数) が大幅に向上、各リクエストレートの出力トークン当たりの時間が大幅に短縮。ソフトウェア最適化によるパフォーマンス向上を強調する結果が示されました。
量子化: インテル® Gaudi® 2 アクセラレーターのさらなる可能性を引き出す FP8
LLM ではこれまで BF16 のような高精度フォーマットで保存や処理を実行してきました。量子化は、これよりもさらに低精度数値のフォーマットで処理する強力な技術であり、演算が高速化し、メモリー効率も向上します。中でも FP8 (8 ビット浮動小数点) は新たな標準となっていくと見られ、モデル精度とシステム性能のバランスを実現するのに有効です。
重要なのは、インテル® Gaudi® 2 アクセラレーターは FP8 の演算をネイティブにサポートするハードウェアであるという点で、Tensor プロセシング・コア (TPC) と行列乗算エンジン (MME) 内で E4M3 と E5M2 の両フォーマットを直接処理できます。このネイティブ性こそソフトウェア・エミュレーションとの明確な違いであり、パフォーマンス優位性の根本的な要因です。このハードウェアの可能性を引き出し、最適化する Habana SynapseAI ソフトウェア・スタックには、グラフ・コンパイラーが含まれ、このコンパイラーがモデルの演算を FP8 で効率的に実行するために変換と調整を行います (特定のベンチマーク手法に該当する場合のオプションとして、 FP8 実装用にモデルを準備するには、インテル® ニューラル・コンプレッサーのようなツールと SynapseAI を統合して高精度のキャリブレーションと量子化を実行します)。さらに、このような低精度の演算処理中に高い数値精度を維持するために、インテル® Gaudi® 2 アクセラレーターでは通常、MME 内部の FP32 累積演算を使用します。
インテル® Gaudi® 2 アクセラレーターで FP8 量子化に内蔵のハードウェアとソフトウェア機能を活用することで、レイテンシーの大幅な低減が可能になり、応答性の高いインタラクティブなユーザー体験を提供できます。図 2 に示すとおり、ソフトウェア・スイート v1.19 で Llama3-70B-Instruct を FP8 に量子化することで、最初のトークンまでにかかる時間 (TTFT) と出力トークン当たりの時間の中央値 (TPOT 中央値) の両方が大幅に短縮されます。具体的には以下のとおりです。
• 最初のトークンまでにかかる時間 (TTFT) の短縮: 最初のトークンまでにかかる時間は初期応答を測定するもので、FP8 ではリクエストレート 16 のときに最大 67% 短縮。
• 出力トークン当たりの時間の中央値 (TPOT 中央値) の短縮: 各後続トークンが生成されるまでの時間の中央値も、FP8 量子化により短縮。リクエストレート 4 のとき、各後続トークン生成までの時間の中央値は、BF16 と比較すると FP8 では30% 以上短縮しています。
これらのパフォーマンス向上は、FP8 実装に最適化されたインテル® Gaudi® 2 アクセラレーターが推論のレイテンシー低減とユーザー・インタラクションの向上において重要な役割を果たすことを示しています。
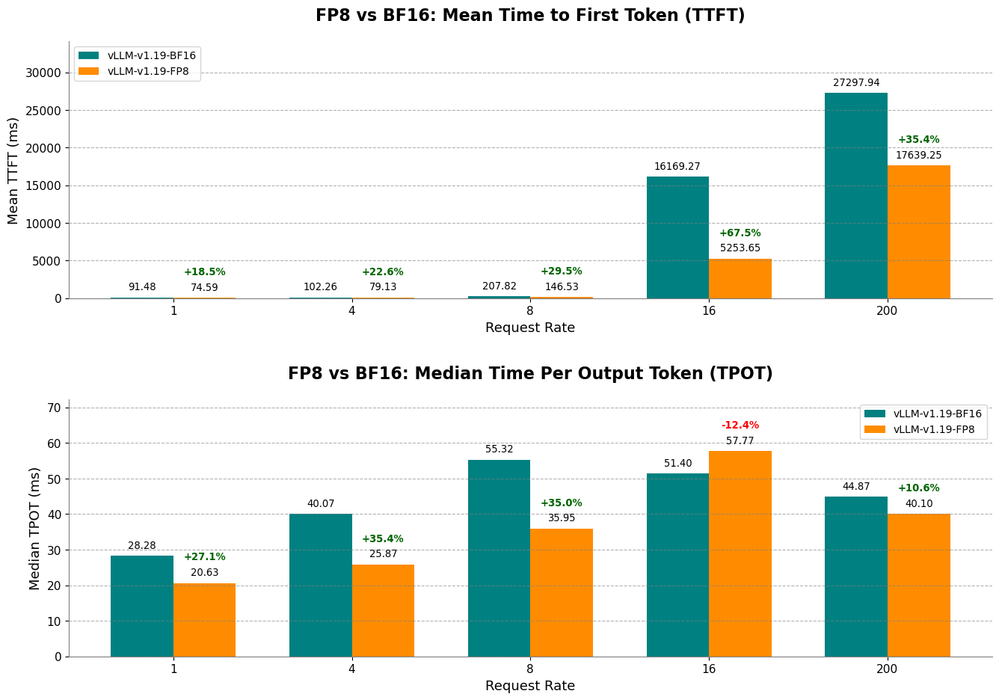
図 2: FP8 量子化 により最初のトークンまでにかかる時間 (TTFT) と出力トークン当たりの時間の中央値 (TPOT 中央値) の両方が短縮。インテル® Gaudi® 2 アクセラレーターで実行する LLM 推論の応答性向上につながっています。
vLLM のデプロイメント引数をファインチューニングすることで、さらなる最適化が可能です。例えば、デコーディング・ステージを対象にマルチステップ・スケジューリングを有効にすることで、TPOT 中央値がさらに最大 19% 短縮され、テキスト生成時間も同様に短縮されることになります。次の図では、この最適化を行った結果、インテル® Gaudi® 2 アクセラレーターで TPOT 中央値のさらなる短縮が可能になったことを示しています。
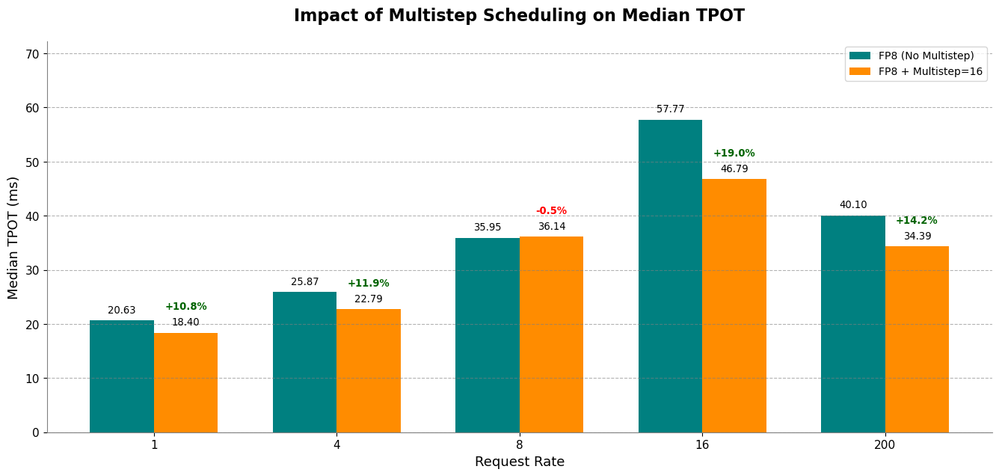
図 3: インテル® Gaudi® 2 アクセラレーターで FP8 量子化を適用した場合の、マルチステップ・スケジューリングが TPOT 中央値に及ぼす影響。このデータから、マルチステップ・スケジューリングの有効化により、FP8 単独の場合と比較して生成レイテンシーがさらに低減していることが分かります。
これらの最適化の複合的な影響を深く理解するために、ベストな最適化設定 (v1.19 で FP8 とマルチステップ・スケジューリングを使用) と、カスタム・ウォームアップを適用した基準となる v1.18 の構成を比較してみましょう。エンドツーエンドの生成パフォーマンスの指標として、出力トークン当たりの時間の中央値 (TPOT 中央値) に注目します。これらの異なる設定を比較することで、プロセス全体でどのくらいのパフォーマンス向上が見られたかを確認できます。今回のパフォーマンス向上は、インテルが前進していることを示しており、さらに進歩していくことが期待されます。図 4 にその結果を示します。
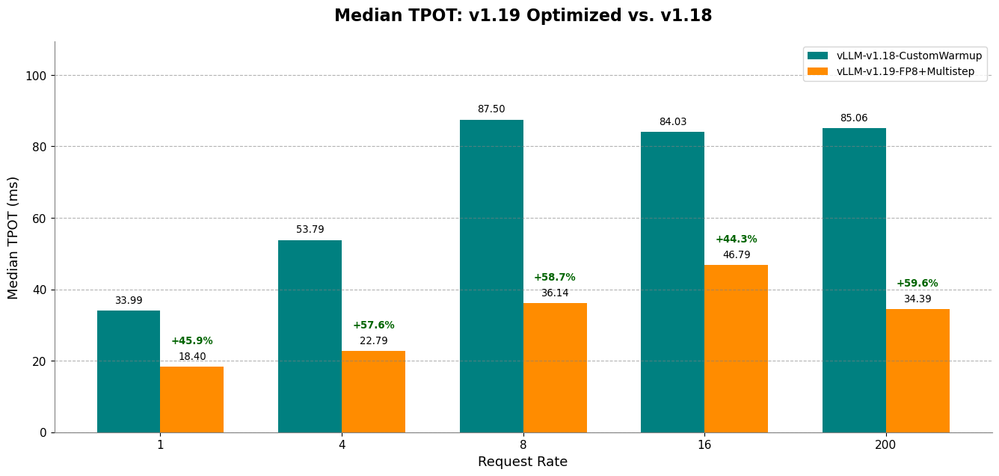
図 4: 基準となる vLLM-v1.18 構成を、FP8 とマルチステップ・スケジューリングにより最適化された vLLM-v1.19 の TPOT 中央値と比較。ソフトウェア、量子化、vLLM 最適化による累積的なパフォーマンス向上が明らかになりました。
インテル® Gaudi® 2 アクセラレーターの秘策: 長文コンテキストの推論をカスタム・ウォームアップ (最高水準の推論モデルに有効)
インテル® Gaudi® 2 アクセラレーターは、専用のウォームアップ手順によるメリットが大きく、メモリー割り当てとカーネルのロードが最適化されるため、ハイパフォーマンスが継続します。これは LLM の推論実装において非常に重要となり、長文シーケンスの推論に特に有効です。このような推論型 LLMは、事実上の最高水準モデルとなっています。
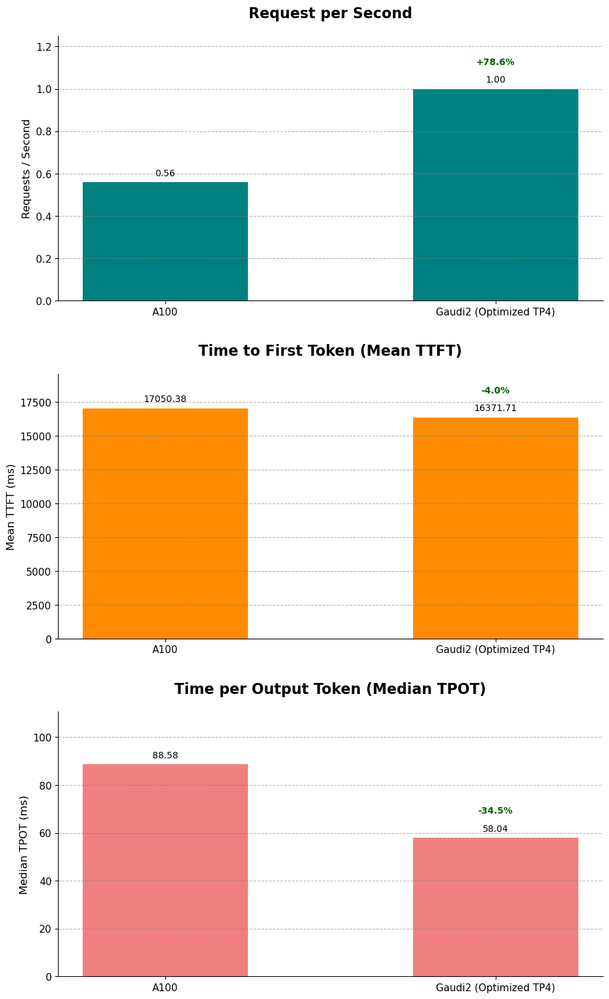
図 5: インテル® Gaudi® 2 アクセラレーターは、長文コンテキスト推論に最適化されたウォームアップ手順により、NVIDIA A100 と比較してリクエスト・スループットが高く、低レイテンシー (TTFT および TPOT 中央値)。
インテル® Gaudi® 2 アクセラレーターは LLM 推論の現実的な選択肢か?
これはデータから明らかです。ファームウェアの強化、FP8 量子化、vLLM 構成の最適化、カスタム・ウォームアップ手順のすべてが組み合わされたインテル® Gaudi® 2 アクセラレーターは、LLM 推論において素晴らしいパフォーマンスを示しており、NVIDIA A100 に匹敵するだけでなく、特に長文コンテキストの処理では大きく上回っています。
長文コンテキストのベンチマークでは、ウォームアップ構成の最適化により、インテル® Gaudi® 2 アクセラレーターは次のようなパフォーマンスを示しました。
• 高スループット: 長文シーケンス (1,000 入力 / 3,000 出力)、リクエストレート 16 の場合、1 秒当たりの出力トークン数が多い。
• レイテンシーは同程度: リクエストレート 16 の場合、最初のトークンまでにかかる時間 (TTFT) は A100 と同程度でした。
• 生成レイテンシー: 出力トークン当たりの時間 (TPOT) を測定すると、インテル® Gaudi® 2 アクセラレーターの生成速度は 34% 高速。
ここで示したデータから、インテル® Gaudi® 2 アクセラレーターは LLM 推論において NVIDIA A100 に置き換わる強力な代替ソリューションと言えます。FP8 量子化の効果的な活用と目的に合ったソフトウェアの機能拡張が、競合製品よりも競争優位なスループットとレイテンシーを実現しており、高性能 LLM の実装に魅力的でコスト効率の高い選択肢となるでしょう。
AI スタートアップ企業のメンバーとして、インテル® Gaudi® アクセラレーターの可能性を探求し、インテル® Tiber™ AI クラウドの最適化された環境をプロジェクトに活かしたいなら、ぜひ AI スタートアップ企業向けの Intel® Liftoff プログラムにご参加ください。
これはスタートアップ企業のサポートのために構築されたプログラムで、リソース、技術的な専門知識、インテル® Tiber™ AI クラウドなどのプラットフォームへのアクセスを提供しています。
• AI スタートアップ企業向け Intel® Liftoff プログラムの詳細
• インテル® Tiber™ AI クラウド
https://www.intel.com/content/www/us/en/developer/tools/oneapi/liftoff.html
https://ai.cloud.intel.com/
AI パフォーマンスを最大化するには、適切なハードウェアも必要ですが、適切なエコシステムを通じた機会の拡大も重要です。AI スタートアップ企業がすべてを単独で解決する必要はありません。Intel® Liftoff プログラムでは、メンターのサポートを受けながら、最先端の技術リソースを利用し、同じ志を持つ仲間とともに AI の手ごわい課題に取り組むことができます。
AI で次のイノベーションを起こしたい皆さんに最適な環境です。現在、参加企業を募集しています。ぜひご応募ください。
https://www.intel.com/content/www/us/en/developer/tools/oneapi/liftoff.html
<関連リソース>
インテル® Tiber™ AI クラウド - AI の開発 / 実装のためのクラウド・プラットフォーム
https://ai.cloud.intel.com/
インテル® Gaudi® 2 AI アクセラレーター - ディープラーニングのワークロード向けに設計されたハイパフォーマンスの AI トレーニング・プロセッサー
https://www.intel.co.jp/content/www/jp/ja/products/details/processors/ai-accelerators/gaudi2.html
Embedded LLM がインテル® CPU を評価:
https://community.intel.com/t5/Blogs/Tech-Innovation/Artificial-Intelligence-AI/Beyond-GPUs-Why-JamAI-Base-Moved-Embedding-Models-to-Intel-Xeon/post/1650850