Hugging Face を活用してインテル® Gaudi® アクセラレーターに検索拡張生成を実装する方法
GitHub でソースを表示する
https://github.com/HabanaAI/Gaudi-tutorials/blob/main/PyTorch/RAG_Application/RAG-on-Intel-Gaudi.ipynb
【検索拡張生成 (RAG) をインテル® Gaudi® 2 アクセラレーターに実装】
Hugging Face ツールを活用して、インテル® Gaudi® 2 AI アクセラレーターに最適化済みのスケーラブルな検索拡張生成 (RAG) アプリケーションを実装します。
このチュートリアルでは、インテル® Gaudi® 2 アクセラレーターを使用した RAG アプリケーションの構築手順を説明します。アプリケーションの構築には、テキスト生成推論 (TGI) やテキスト埋め込み推論 (TEI) など、アクセスしやすい Hugging Face のツールを活用し、コードを理解しやすくするために Langchain フレームワークを選択しました。チュートリアルの最後では、Gradio をユーザー・インターフェイスとしてクエリーをサブミットします。ここではアプリケーションを Docker 環境に導入しますが、Kubernetes クラスターへ手間なく実装することが可能です。
検索拡張生成 (RAG) は、外部ソースから事実情報を取り込むことで、生成 AI モデルの精度と信頼性を向上させる手法の 1 つです。汎用プロンプトに対して瞬時に応答を生成できるものの、詳細で具体的な情報を出力しない可能性もある、大規模言語モデル (LLM) の限界を補完する手法と言えます。外部ナレッジソースへのアクセスを可能にすることで、事実に基づく一貫性を確保し、生成する応答の信頼性を向上させ、複雑でナレッジ依存の高いタスクにおける「ハルシネーション」の問題を軽減します。
このチュートリアルでは、インテル® Gaudi® 2 アクセラレーター上に RAG パイプライン全体を構築する手順について説明します。まず初めに、テキスト生成、テキスト埋め込み、ベクトル型の格納インデックスとデータベース生成ツールを構築。次に、外部ドキュメントから情報を抽出して外部データセットを準備し、ドキュメントの「チャンク」と、このデータチャンクの数値埋め込みを作成します。これらの埋め込みは、この後ベクトル型データベースにロードされます。これでクエリー実行を開始する準備が整い、再度クエリー上で埋め込みモデルを実行して、データベースの内容と一致しているかマッチングを試行し、プロンプト全体とクエリーへの応答を Llama 2 大規模言語モデルに送信して、フル形式の応答を生成します。
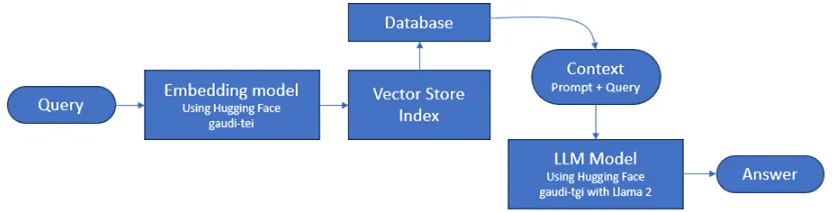
図 1. RAG モデルの詳細
<初期セットアップ>
以下の初期セットアップ手順に従い、ビルド環境が間違いなく設定されていることを確認します。
1.インテル® Gaudi® 2 アクセラレーター搭載ノードに ssh でアクセスする適切なポートを設定。以下のポートを開放しておく必要があります。
ポート 8888 (Jupyter Notebook の実行)
ポート 7680 (Gradio サーバーの実行)
2.このため、インテル® Gaudi® アクセラレーター搭載ノードに接続する際の ssh コマンド全体で、以下とおりポートを追加してください。
3.この Notebook をロードする前に、インテル® Gaudi® アクセラレーターの標準的な Docker イメージを実行しますが、/var/run/docker.sock ファイルを含める必要があります。これらの exec コマンドを実行し、Docker を開始します。

<Notebook 内に Docker 環境を設定:>
この時点で、インテル® Gaudi® アクセラレーターのチュートリアル用 Notebook のクローンを Docker イメージ内に作成してオープンできました。ここから次の手順に進みます。RAG ツールの実行を管理するために、インテル® Gaudi® アクセラレーターのコンテナへ Docker を再びインストールする必要がある点に注意してください。

<RAG 用のツールをロード>
RAG 環境の構築には、テキスト生成、テキスト埋め込み、ベクトル化の 3 つのステップがあります。
<テキスト生成インターフェイス (TGI)>
アプリケーションの 1 つ目のビルディング・ブロックとなるテキスト生成推論には、コンテキストに基づいた問い合わせに返答する LLM モデルとしての役割があります。これを実行するために、Docker イメージのビルドが必要です。
注意: Hugging Face のテキスト生成インターフェイスはソフトウェアに依存するため、オープンソース・ライセンスではないこともあります。このソフトウェアを使用または再配布する場合、ライセンスへの準拠はご自身の責任となりますのでご注意ください。

イメージをビルドした後は、以下のとおり実行します。
【Llama 2 モデルへのアクセスと使用方法】
Llama 2 モデルを使用するには、Hugging Face アカウントが必要です。HF Hub のモデルカードに記載されているモデル利用規約へ同意のうえ、読み込みトークンを作成します。次に、このトークンを以下の HUGGING_FACE_HUB_TOKEN 変数にコピーします。
事前学習済みモデルの使用は、「Llama 2 Community License Agreement (LLAMA2)」を含め、サードパーティー・ライセンスの遵守が求められます。LLAMA2 モデルの意図されている使用方法、誤用や適用範囲外と考えられる使い方、想定されるユーザー、その他の条件に関するガイダンスは、こちらのリンク先 https://ai.meta.com/llama/license/ に記載されている指示をご確認ください。ユーザーはサードパーティーのライセンスに従いこれを遵守することについて単独の責任および義務を負うものとします。また、ユーザーによるサードパーティー・ライセンスの使用または遵守に関して、Habana Labs はいかなる責任も負いません。

Docker サーバーの起動後、モデルのダウンロードとデバイスへのロードが完了するまでにしばらく時間がかかります。ステータスを確認するには、docker logs gaudi-tgi を実行してください。以下のように表示されます。

セットアップが完了すると、リクエストを送信することでテキスト生成が機能していることを確認できます (最初のリクエストはグラフコンパイルの影響から時間がかかる場合があります)。

【テキスト埋め込みインターフェイス (TEI)】
2 つ目のビルディング・ブロックはテキスト埋め込み推論です。ベクトル型データベース用の埋め込みを生成する埋め込みモデルとしての役割があります。これを実行するために、Docker イメージのビルドが必要です。
注意: Hugging Face のテキスト埋め込みインターフェイスはソフトウェアに依存するため、オープンソース・ライセンスではないこともあります。このソフトウェアを使用または再配布する場合、ライセンスへの準拠はご自身の責任となりますのでご注意ください。

イメージをビルドした後は、以下のとおり実行が可能になります。

【PGVector データベース】
3 つ目のビルディング・ブロックは、ベクトル型データベースです。このチュートリアルでは PGVector を選択しました。以下のとおり Docker を設定します。

【アプリケーション・フロントエンド】
最後 (4 つ目) のビルディング・ブロックは、http サーバーとして稼働するフロントエンドです。フロントエンドは Gradio インターフェイスを使用して Python で実装します。環境セットアップは以下のとおりです。

【データの準備】
質の高い RAG アプリケーションを構築するには、データの準備が必要です。ベクトル型データベースのデータ処理は、(例えば PDF や CSV といった) ドキュメントからテキスト情報を抽出し、(ファイル名やファイル作成日など) 追加のメタデータとともに、最大長を超えないように複数チャンクへ分割します。次に、事前処理したデータをベクトル型データベースへアップロードします。
データ処理のプロセスで重要な役割を担うのがテキスト分割です。テキストをセマンティクス的に意味のある小サイズの複数チャンクに細分化することで、さらに詳細な処理と分析を可能にします。ここでは広く用いられているテキスト分割のメソッドをいくつか紹介します。
•文字単位: テキストを個々の文字ごとに分割するメソッド。単純明快なアプローチですが、単語やフレーズのつながりなどセマンティクス的な意味は考慮されないため、常に効率的とは限りません。
•再帰的分割: ある条件が満たされるまでテキストを小パーツへ繰り返し細分化するメソッド。細かいレベルでの分割が可能になるため、複雑な構造のテキストを扱う場合に特に有効です。
•HTML 専用: HTML コンテンツを扱う場合、特定の HTML タグまたはエレメントに基づいてテキスト分割を実行。ウェブページなどの HTML ドキュメントから意味のある情報を抽出する際に有効なメソッドです。
•コード専用: プログラミング・コードのコンテキスト内で、特定のコード構文や構造に基づいてテキストを分割。このメソッドはコード分析やコードと連動するビルディング・ブロックで特に有効です。
•トークン単位: トークン化は自然言語処理 (NLP) のテキスト分割に広く用いられるメソッド。テキストを個々の単語やトークンに細分化します。個々の単語とそこから構成されるコンテキストを分析できるため、テキストのセマンティクス的な意味の理解に有効です。
結論を言うと、テキスト分割のどのメソッドを選択するかは、テキストの性質と手元にあるタスクに求められる具体的な要件によるところが大きく、テキストのセマンティクス的な意味を効果的に捉えて、後に続く処理と分析をスムーズに進める手法を選択することが重要となります。
このチュートリアルでは、再帰的分割メソッドを選択しました。このトピックについてさらに理解を深めるには、https://langchain-text-splitter.streamlit.app/ を参照してください。
【データベースへの入力】
データベースへの入力は、ドキュメントのロードと埋め込みの後、データベースにロードする工程です。
【データのロード】
使いやすさを考え、LangChain のヘルパー関数を使用します。なお、langchain_community も必要になりますので、ご注意ください。
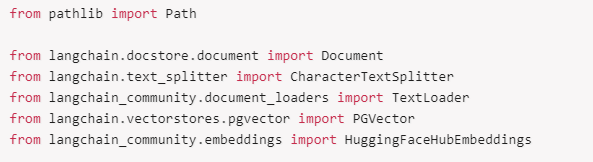
【埋め込みとともにドキュメントをロード】
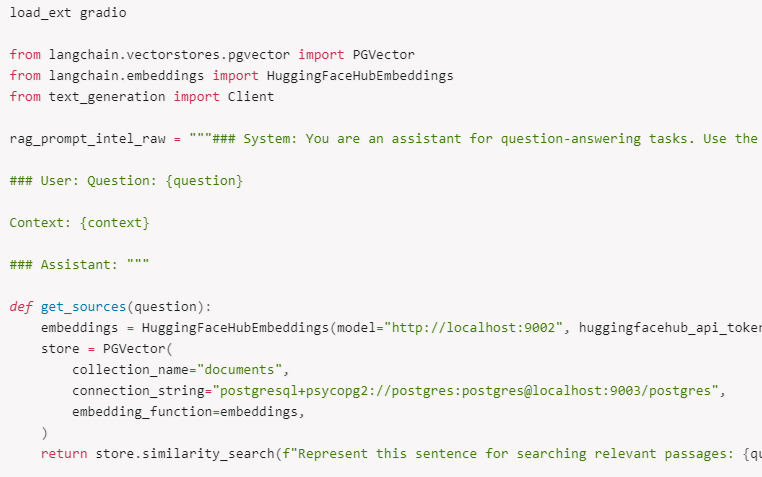
ここから、Hugging Face の TEI クライアントと PGVector クライアントを作成します。PGVector の場合、コレクション名 (collection_name) はテーブル名に相当し、接続文字列 (connection_string) 内に接続プロトコル postgresql+psycopg2、ユーザー、パスワード、ホスト、ポート、データベース名が続きます。使いやすさを考え、pre_delete_collection を True に設定し、データベース内の重複を防いでいます。

【データのロードと分割】
データは data/ のテキストファイルからロード、ドキュメントは 512 文字サイズのチャンクに分割、最終的にデータベースへロードされます。ドキュメントにはメタデータが含まれ、ベクトル型データベースに格納することも可能です。
新しいテキストファイルを data/ フォルダーにロードし、以下のセルを新しいデータで再び実行することで、RAG パイプラインを新コンテンツ上で実行します。このセルによって新しいデータベースが作成され、独自のクエリーを実行できるようになります。
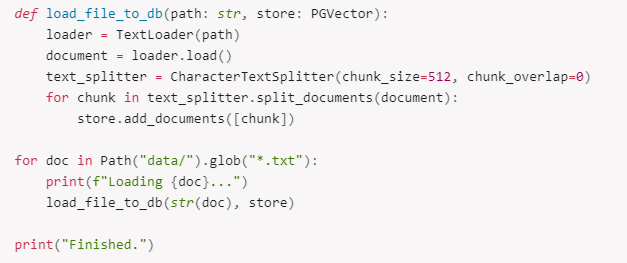
【アプリケーションの実行】
アプリケーションを開始するには、以下のコマンドを実行して Gradio インターフェイスを設定します。
データフォルダーにテキストファイルをロードし上記のセルを実行すると、アプリケーションが取り込みとチャットを開始して、ドキュメントに対し問い合わせを行います。
TGI ライブラリーと TEI ライブラリーに直接アクセスすることで取り込みを行い、埋め込みとベクトル型データベースを作成し、データベース経由でクエリーを実行して、LLM によってクエリーへの回答を生成していることが分かるでしょう。
最後に Gradio アプリケーションを実行すると、以下のように出力されます。
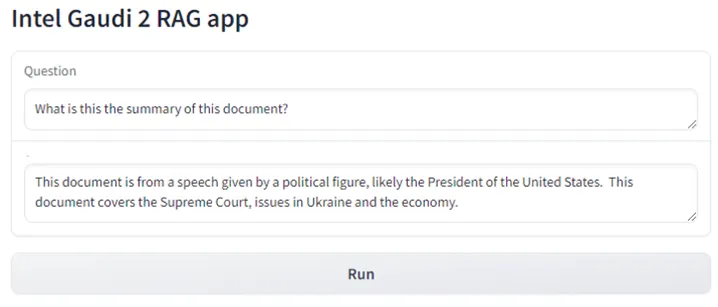
<次のステップ>
の他の .txt ドキュメントを ./data フォルダーに追加し、「データの準備」の手順を再び繰り返すことで、新しいドキュメントを使用してベクトル型データベースを更新できます。
また、LocalGPT チュートリアル: https://developer.habana.ai/tutorials/pytorch/using-localgpt-with-llama2/ を試してみることも可能です。こちらも RAG と LocalGPT スクリプトによって Chroma データベースを使用し、回答を生成します。
ほかのモデルを使用するには、https://huggingface.co/docs/optimum/habana/index にアクセスし、インテル® Gaudi® アクセラレーターに最適化済みの全モデルをまとめたリストを確認してください。
Copyright© 2024 Habana Labs, Ltd. an Intel Company.
<Apache License Version 2.0 (以下「ライセンス」) の下に使用許諾条件が適用されます。>
本ライセンスを遵守しない限り、このファイルを使用することはできません。本ライセンスのコピーは、https://www.apache.org/licenses/LICENSE-2.0 から入手できます。該当する法律で義務付けられている場合または書面で合意した場合を除いて、本ライセンスの下で頒布されるソフトウェアは、明示されているか否かにかかわらず、いかなる種類の保証あるいは条件なしに「現状のまま」提供されるものとします。本ライセンスの下での許可および制限を規定する特定の文言については、本ライセンスを参照してください。