今回はよく使うDatabaseコンポーネント(ソース)について紹介します。

Table/Queryの選択
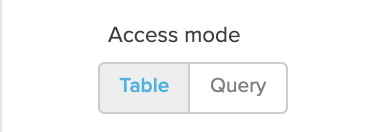
Tableを選択した場合:1つのテーブルを変換なしでシンプルに取り込みたい場合に使用します。
Queryを選択した場合:SQLクエリを自身で書き、取り込みと同時に結合処理やデータ変換をSQLで行いたい場合に使用します。
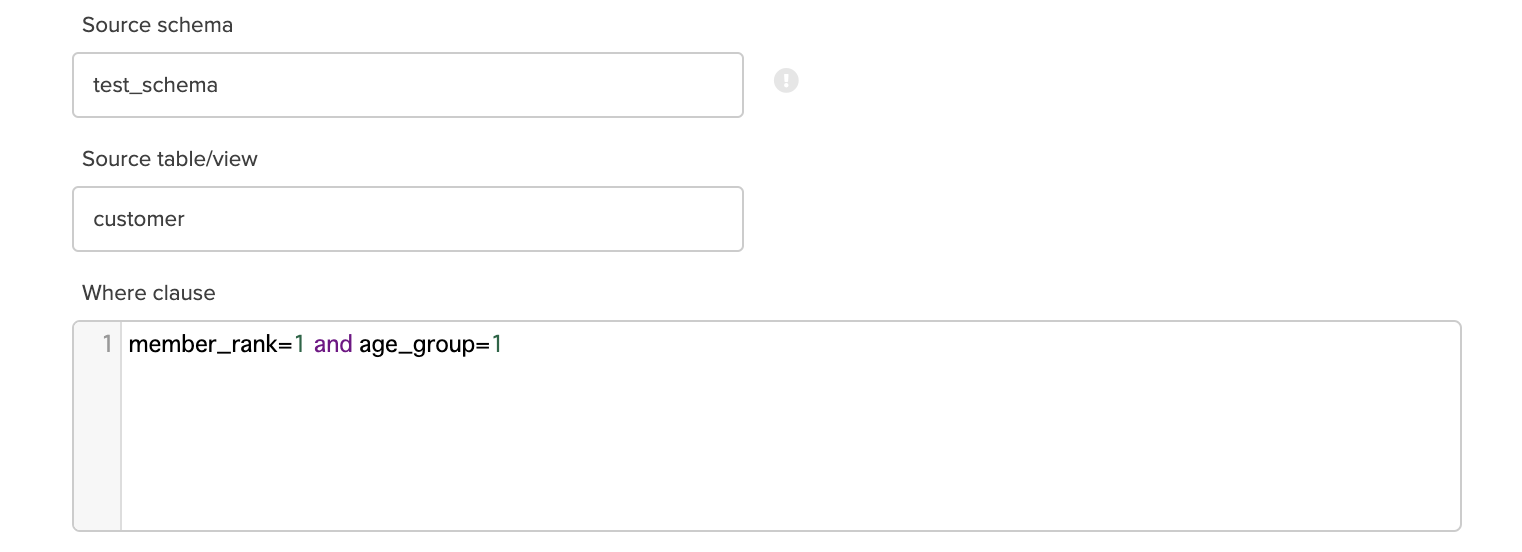
Tableを選択した場合の各オプションについて
Souce shema:ソースのスキーマ名を設定します。
Souce table/view:ソースのテーブルもしくはViewの名前を設定します。
Where clause:SQLのWhere句を設定します。(Whereは不要です。Where以降を入力ください。)
クエリ並列化オプション
データをクエリの並列実行で取得することで取り込み処理部分の高速化が期待できます。
クエリを並列化するには、クエリを分割するキーと並列接続の最大数を設定します。クエリを並列化する場合、最初に列の最小値と最大値を取得し、データを範囲に分割するためのwhere句を使用し、複数の接続からクエリを実行します。例:pk> = 1 AND pk <1000、pk> = 1001 AND pk <2000。
Split query by key column:クエリの分割に使用するプライマリキーを指定します。
Max parallel connections:クエリを並列実行するための接続数を設定します。クラスターの処理パワー(ノード数)に対して「Node数x5」の値を目安に設定ください。

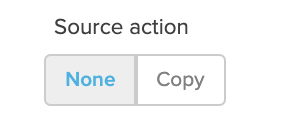
データ取得方法の指定
Noneを選択した場合:データベースからデータが読み取られ、変換がすぐに適用されます。
Copyを選択した場合:データを処理する前に、データベースソースから中間ストレージにデータをコピーします。これにより、データベースコネクションを開いている時間を短縮することが出来ますが、通常ジョブ全体の時間はNoneのほうが短くなります。
Databaseコンポーネント(Destination)の設定はこちら
送信先(Destination)がDBの場合、「Xplenty中級編 Part4: DB周りの設定(Destination編)」を参考ください。