1. 少量データの処理を高速化する
Xplentyはデータ処理プラットフォームとしてHadoopを利用しており、通常のジョブはMapReduceで実行されます。もともとMapReduceはビッグデータ処理基盤として設計されているため、データの処理量にかかわらず開始と終了後のクリーンナップにオーバーヘッド時間がかかります。
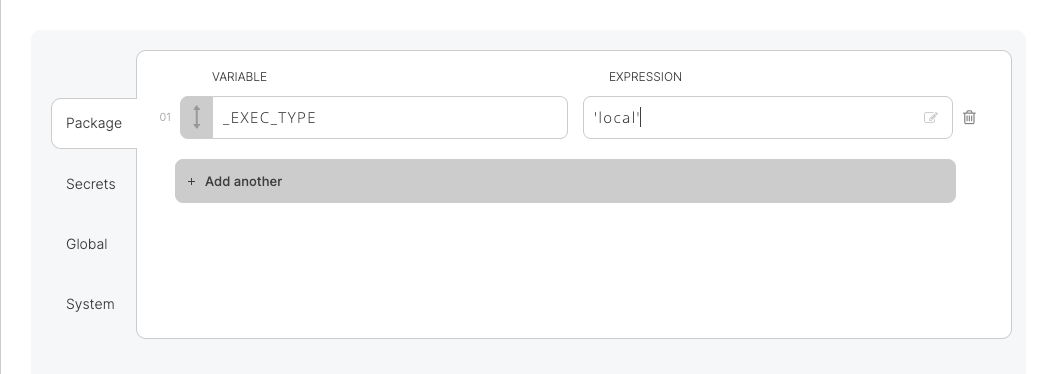
そこで、Xplentyでは小さいデータ量を扱うジョブの場合は、MapReduceを使用せずにマスターノード上で処理を実行するオプションが用意されています。パッケージの変数画面で以下のように変数を設定することでMapReduceを介さずにスクリプトベース(Pig)でジョブが実行され、ジョブ実行時間の高速化を図ることが可能です。
_EXEC_TYPE = 'local'
2. Salesforceからのデータ読み込み処理の高速化
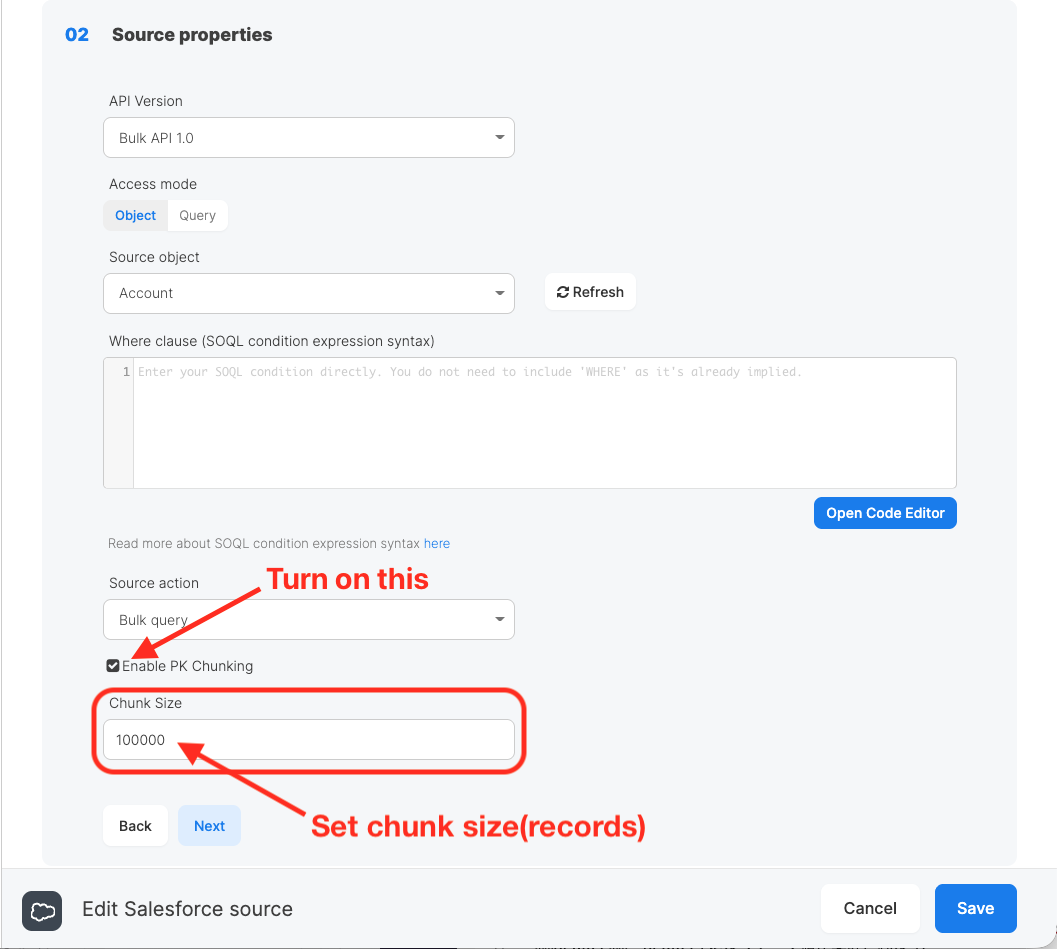
Xplentyでは、Salesforceオブジェクトから大量のデータを抽出する場合、「PK Chunking」の設定を有効にすることでPrimary Keyに基づき指定したチャンクサイズに分割して並列で読み込み処理を行うことで、読み込みにかかる処理時間の高速化を図ることが可能です。チャンクサイズは、Saleforce Bulk API Guideによると性能上の理由で100,000(デフォルト)から250,000(最大値)が推奨されています。
3. Rest APIでのデータ書込処理の並列化
ユースケースによっては、サードパーティのREST APIに膨大な量のデータをスピーディに書き込まなければならない場合があります。APIをシングルスレッドで実行するのは非常に時間がかかります。理想的には、データスループットを高速化するために、APIを並列で実行するのがベストです。
XplentyはHadoop MapReduceを使用してサーバーのクラスタ上にコンピューティングタスクを分散させるため、(メモリやディスクの制約により)単一のサーバーでは処理できない大規模なデータセットに理想的な製品です。これにより、ペタバイト級のデータの並列処理が可能になります。
MapReduceの処理は、4つの主要なフェーズに分けられます。
- Map キーによってグループ化されたキー・バリューペアです。
- Shuffle 同じキーを持つすべての値が、Reducerによって一緒に束ねられます。
- Sort すべてのレコードはReducerによりキーごとにソートされます。
- Reduce Reducerによりデータ値が集計されます、
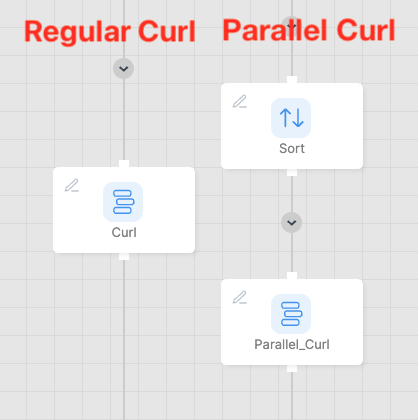
サードパーティAPIへのデータ書き込みを高速化するために、Curリクエストを並列で実行することができます。以下の図のようにCurl()を実行するSelectコンポーネントの直前にSortコンポーネントを追加することで、タスクが複数のクラスタノードに渡り分散されるようになります(タスクはMapperではなくReducerによって処理されるため)。
デフォルトでは、Xplentyは単一のHadoop Reducerを使用します(Xplentyのシステム変数「_DEFAULT_PARALLELISM」は0に設定されています)が、「_DEFAULT_PARALLELISM」はシングルノード(1 node)のHadoopクラスタあたり最大「5」まで設定することができ、5つの並列スレッドを処理できるようになります。
<パッケージ変数画面>

Xplentyの変数「_DEFAULT_PARALLELISM」を「6」以上に増やすには、Hadoopクラスタが複数のノードを持っている場合にのみ有効です。
例えば、15の並列スレッドであれば、「_DEFAULT_PARALLELISM」は3ノードのクラスタが必要となります。
4. システム変数
システム変数の中には、「_MAX_COMBINED_SPLIT_SIZE」(注)のように特定のシナリオにおいて、ファイル処理にかかるオーバーヘッドを少なくし、パフォーマンスを最適化する変数があります。
- 注 - 1つのタスクで処理するデータ量をバイト単位で指定します。設定値より小さいファイルは、このサイズに達するまで結合されます。それより大きなファイル(圧縮されていない、またはBzip2 を使用して圧縮されている場合)は設定されたサイズに基づき分割されます。