本記事は Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation(論文, リポジトリ)のサーベイ記事です。
日鉄ソリューションズ(NSSOL)様での研究開発インターンの一環として執筆しました。
今回紹介するのは、ざっくり言えば、自然言語で記述された質問からSQLクエリを生成するタスク(Text-to-SQL)において、文脈自由な中間表現を導入して性能を上げた研究で、提案モデルはIRNetと呼ばれています。
この研究ではSpider (論文, サイト) というデータセットを用いています。Spiderは従来のText-to-SQLデータセットよりも複雑な事例を多く含んでいます。
Spiderの公式サイトで挙げられている難易度が中くらい(Meidum)の例がこちらです:

複数テーブルを見たうえでJOINとGROUP BYを適切に使わないといけないので、初級者だと苦戦しそうです。これを機械にやらせるのがText-to-SQLタスク、Spiderデータセットです。
このIRNetは論文公開時点で以前のSpiderのSoTA (27.2%) を大きく上回る46.7%という性能を出しました。さらにEncoding手法にBERTを用いた場合は、54.7%まで性能向上しました。
2020年2月現在ではIRNetはSpiderのSoTA手法ではなくなっているものの、タスク特有の中間表現を導入した点で面白く、読む価値があります。
データセット
Spiderはjson形式で、各事例を辞書型オブジェクトとして提供しています。
格納されている主な情報はデータベースのID(db_id)、SQLクエリ(query)、自然言語の質問(question)です。
これに加えて前処理としてクエリをトークナイズしたもの(query_toks)、トークナイズされたクエリに含まれる値を別の記号表現に置換したもの(query_toks_no_value)、質問をトークナイズしたもの(question_toks)、さらにSQLクエリを前処理したもの(sql)があります。
データベースの中身はここに含まれておらず、別ファイル(sql形式とsqlite形式)で提供されています。
下に訓練データの例を示します(長くなるので適当に省略しています)。
[
{
"db_id": "department_management",
"query": "SELECT count(*) FROM head WHERE age > 56",
"query_toks": [
"SELECT",
"count",
...
"56"
],
"query_toks_no_value": [
"select",
"count",
...
"value"
],
"question": "How many heads of the departments are older than 56 ?",
"question_toks": [
"How",
"many",
...
"?"
],
"sql": {
...
}
}, ...
]
この事例では、department_managementデータベースに対する質問How many heads of the departments are older than 56 ?から、SQLクエリSELECT count(*) FROM head WHERE age > 56が生成できればよいわけです。
department_managementの中には、department、head、managementの3つのテーブルが格納されています。Spiderでは、まず適切なテーブルをこれらの中から選んだうえで、SQLクエリを生成する必要があります。
Spiderの特徴
Spiderは、未知の複雑なSQLクエリを生成できるか、複数のテーブルを考慮して性能を出せるか、という点を検証するために作られたデータセットです。Spiderにはnested query(GROUPBYやHAVINGを含むSQLクエリ)、質問中で明示されないカラム・複数のテーブルを扱う必要のあるクエリが含まれています。
Spider論文では、既存のSemantic Parsingタスク(自然言語を論理式に変換するタスク)のためのデータセットの欠点2つをSpiderは改善したと述べられています。
まず欠点の1つめは、複雑なプログラムを含むようなデータセットでも、訓練データとテストデータで重複する要素が多いことです。具体的には、訓練データとテストデータで共通するデータベース、論理式/SQLクエリが出現するのです。
2つめの欠点は、WikiSQLのような大規模なデータセットは、SQLクエリを生成する際は単一テーブルしか考慮しないで済むうえ、単純なSQLクエリばかりだということです。
未知の複雑なプログラムを生成するモデルの能力を検証したいなら、これらの欠点は改善しなければなりません。このような考えに基づいてSpiderは構築されています。
なお、Spiderはモデルの頑健性を評価したいので、開発データにはOOV; Out Of Vocabulary(訓練データ中に含まれない語彙、未知語)が多いです。開発データにおけるDBスキーマ中の単語のOOV率はWikiSQL: 22%、Spider: 35%です。
NLPシステムはOOVに対して頑健であることが求められます。特に比較的規模の小さいデータセットでは、訓練データで十分な語彙をまかないきれません。そのため、たとえば wikipedia などに出現する語彙の埋め込みを事前学習しておき、その埋め込みの重みを固定させたうえで、特定タスク(ここではText-to-SQL)の学習に利用することが多いです。
以上のような特徴があるので、Spiderはかなり難しいデータセットです。先発のデータセットでは完全一致で80%以上の性能を出せるモデルが提案されていますが、Spiderでは現状そこまで高い性能を出せるモデルは登場していません。ここで紹介しているIRNetでも50%前後ですし、それ以前のSoTA手法は27.2%しか出せていませんでした。ただ、難しいとは言っても、過度に曖昧な質問文、答えるのにテーブル外の知識が必要な質問文は含まれないような配慮はきちんとされています。
関連研究
IRNetの重要な関連手法について概要を述べます。
Spiderの以前のSoTAであったSyntaxSQLNetは、自然言語文をエンコードし、well-formedな文を得るための統語木構造ベースのデコーダーからSQLクエリを得る手法です。
統語木構造ベースのデコーダーTRANXは、実行可能なプログラムを生成するために考案された汎用的な手法です。このモデルは自然言語文から抽象構文木(Abstract Structure Tree; AST)を生成、次にそのASTからプログラムを生成します。提案論文ではプログラム生成のためのデータセット複数種で検証されており、汎用性が高いことが分かります。
WikiSQLで高い性能を出した手法としてcoarse-to-fine modelがあり、これは文の大雑把な骨格をまずデコードした後、その骨格に対して詳細を補完するデコーダーです。
提案手法
自然言語文からSQLクエリへの変換は、ある種の翻訳だと見なせます。ニューラルネットを用いて自然言語文を潜在表現にエンコードし、その情報をSQLクエリにデコードするseq2seqな手法が、すぐ思いつく(いまどきの?)解き方です。
しかし、SQLクエリは統語的にwell-formed、実行可能でなければいけません。単純なseq2seq手法はその点を考慮できないので、Text-to-SQLタスクには必ずしも適しません。
IRNet論文で汎用的なseq2seqはベースラインとして採用されていますが、やはりText-to-SQLのために作られたモデルではないため、テストデータで完全一致する事例の割合は高くとも5.3%です。
IRNetでは、end-to-endに自然言語文から直接SQLクエリを生成するのではなく、明示的な中間表現SemQLを導入しています。SQLクエリを潜在表現から直接デコードするのは難しいため、代わりにSQLを簡略化した中間表現をデコードし、その中間表現から確定的にSQLを確定的に導出する方針です。
SemQL
SemQLはIRNetで提案された文脈自由な言語で、自然言語とSQLの橋渡しをする中間表現です。SemQLとは、大雑把に言うと、SQLを簡略化した言語かつ確定的にもとのSQLを復元できるような言語です。
論文のAppendixからの図の抜粋を次に示します。
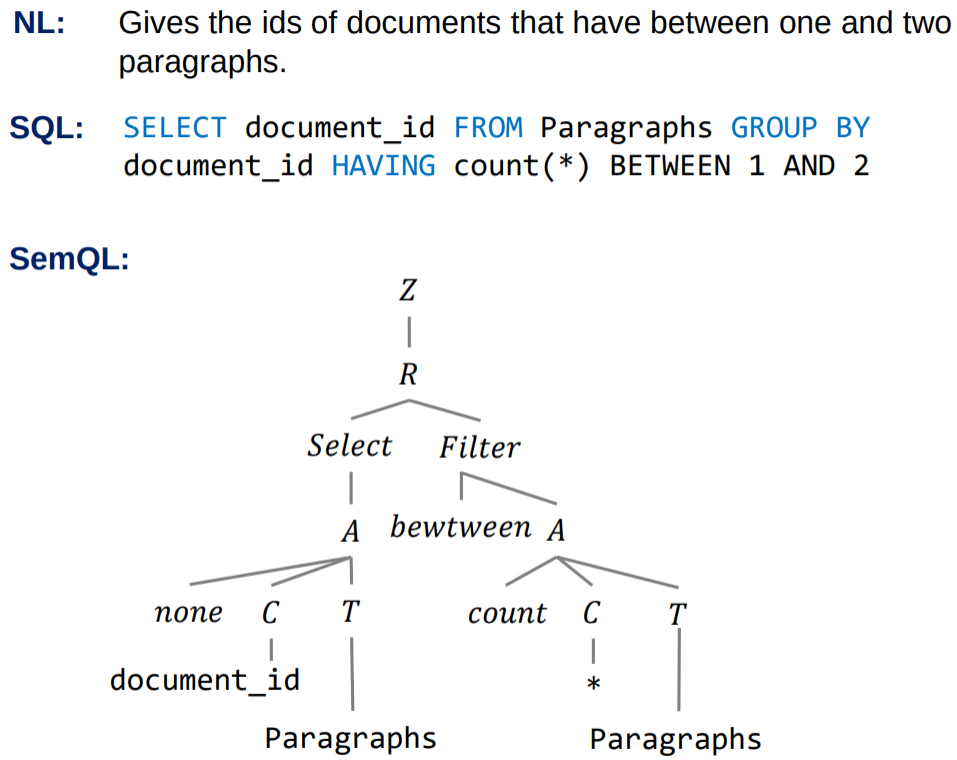
たとえばSemQLでは、HAVING句やWHERE句はまとめてFilterノードとして表現されます。そしてFilterノード以下Aノードの集計関数を示す値がnoneであればWHERE句、そうでなければHAVING句が復元されます。上の例だとAノード以下の集合関数としてcountが入っているので、FilterノードはHAVING句に復元できます。
つまり、デコードすべき語彙を削って、最終的に本来のSQLの語彙は文脈から一意に復元しようという発想です。こうすることでニューラルネットの担う仕事が簡単になって、限られた訓練データでも高い性能を出せるようになると期待できます。
Schema Linking
質問中で言及されている、table、column、valueの3種類の実体を、質問中の単語と紐付けます。論文中ではこれをschema linkingと呼んでおり、Text-to-SQLでのentity-linking(テキスト中の単語を一意な実体と紐付けるタスク)だと説明しています。
以下は論文中のモデル概略図に、単語・スキーマ間のリンクを分かりやすく矢印で表現したものです(モデル自体の説明はこの後のセクションでします)。schema-linkingは、例えば、質問中に"books"という単語があって、かつ"book"テーブルがあるとき、質問文中の"books"をテーブル"book"と紐付けるような処理です。
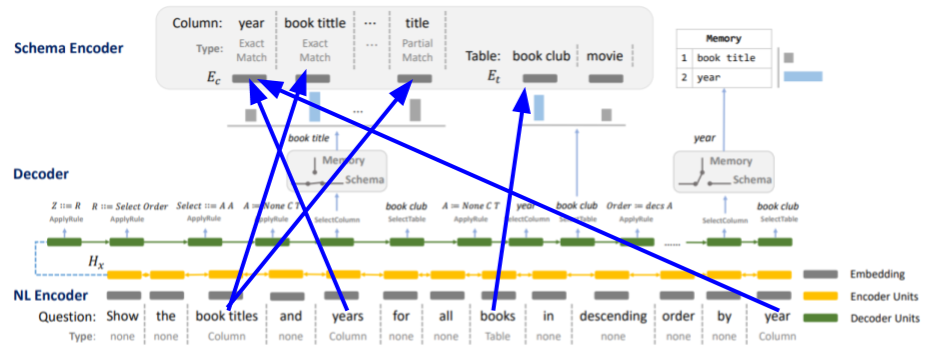
実際の処理では、質問中の各単語のn-gramをループで回し、それと一致するカラム名・テーブル名をもつ実体をその単語に紐付けます。単純な文字列マッチではありますが、効果的な手法です。さらにそれだけではなく、シソーラス(ここではConceptNet)からis a type of関係かrelated terms関係にある単語まで見て、単語とスキーマとの紐付けを行います。またクォーテーションで囲われているトークンはvalueだとみなします。
Model
IRNetモデル概略図を再掲します。
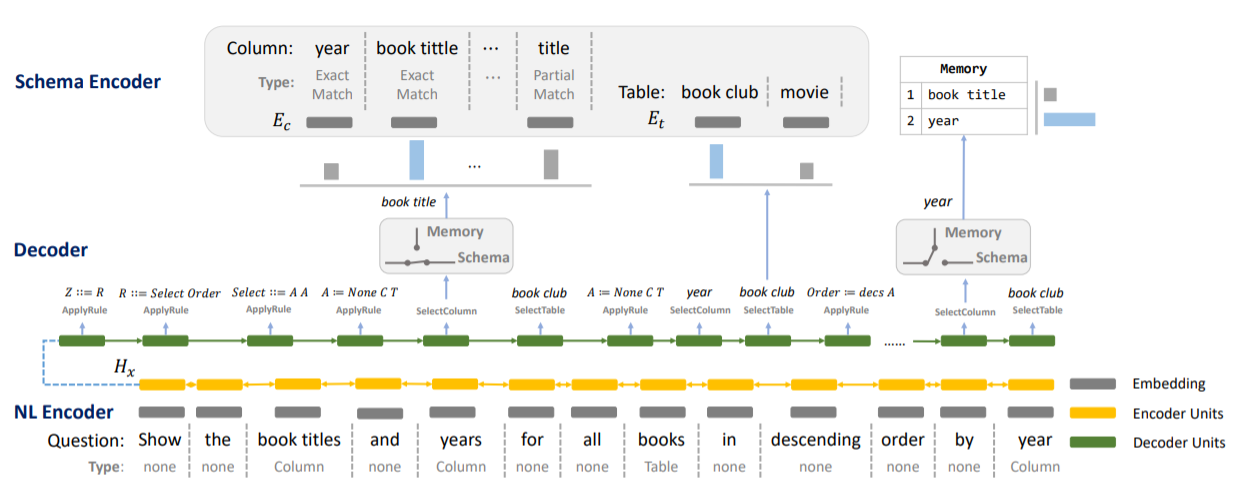
IRNetは主にNL Encoder、Schema Encoder、そして Decoderで構成されています。
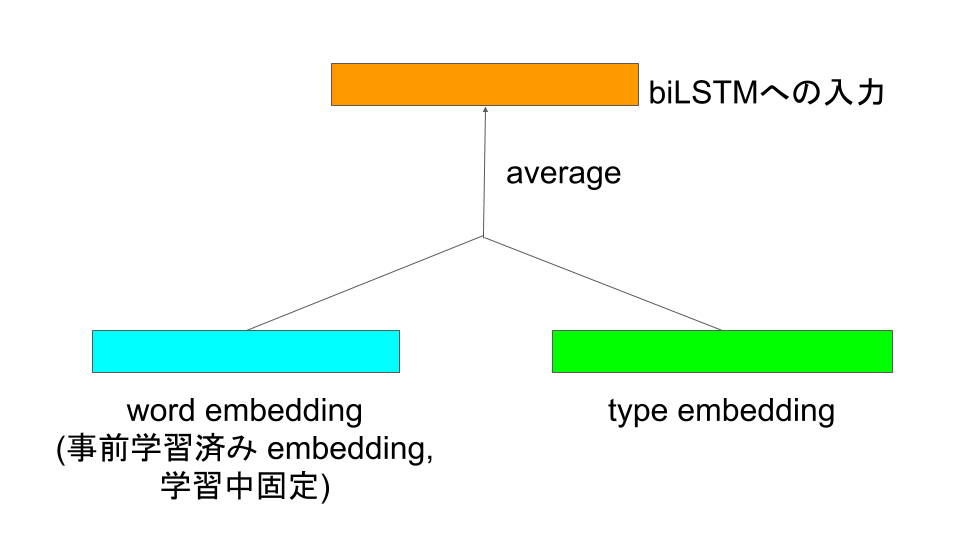
NL Encoderでは質問(Question)と先ほどのschema-linkingでどの種類のスキーマと紐付けられたかを表現するType (none/table/column/value) の埋め込みを平均して、それをbiLSTMでエンコードします。
Schema Encoderではスキーマ(テーブル名、カラム名)の単語、その単語が質問中の単語と完全一致してるか部分一致してるか(exact match/partial match)の情報を、事前学習済みの単語埋め込みを使ってエンコードします。
Decoderでは、エンコードされた情報から中間表現SemQLをデコードします。このSemQL生成にはgrammar-based decoderとcoarse-to-fine frameworkが活用されています。先行手法の章でも言及しましたが、grammar-based decoderはwell-formedな文を生成するためのデコーダー、coarse-to-fine frameworkはまず非常に大雑把な文の骨格だけを生成し、それに対して詳細を補完していくデコーダーです。このデコーダーによってSemQLはあらかじめ決められた文法に従い、次のように出力されます。

最終的なSQLクエリは、あらかじめ定義したSemQLとSQLの対応にしたがってSemQLの木構造を走査することで、SemQLから確定的に導出できます。
Results
各モデルの完全一致での正解率を以下に示します。
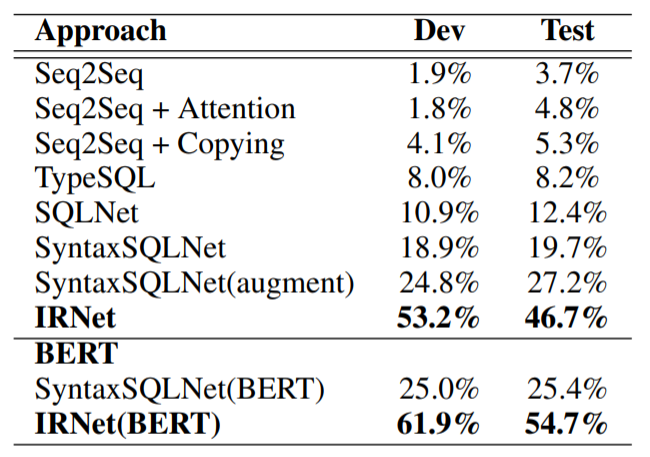
単純なSeq2Seqではほとんど正解できないことが分かります。Spiderに対して提案されたSyntaxSQLNetでも正解率は27.2%です。IRNetはテストデータに対して46.7%の性能を発揮しています。さらにIRNetのEncoderにBERTを用いた場合、8ポイントほども性能が上がっています(詳細は付録にて解説します)。
Pretrained Model
著者提供のpretrained modelがあります。
これをロードして開発データに対して実行させたところ、性能は
sketch acc: 0.777237
acc: 0.499027
となりました。
corse-to-fine modelを使っているため、評価項目が sketch acc(簡単な骨格の正解率)と acc(詳細まできちんと埋めたときの正解率)の2つになっています。
acc がちょうど半分ほどなので、それなりに良いと言えそうです。論文で報告されているよりなぜか低いですが。
エラー分析
論文中のエラー分析で報告されている主な問題は以下の3つです。
- カラムの予測
- 複雑なネスト
- 一般常識が必要なオペレーター
これらに該当しない残りは簡単に分類できないと報告しています。BERTを用いればカラム予測、オペレーターの問題の3割が改善されましたが、複雑なネストはほとんど改善できなかったようです。
また実際に、自分でも著者提供IRNetが生成したSQLクエリを(簡単にですが)分析しました。
全体的な傾向として、やはり誤った事例は正解した事例よりも文字列長が長い傾向があると分かりました。つまり、誤り事例中には、ネストが深いものが多そうだと言えます。
さらに、誤り事例の中でも正解のSQLクエリが短い例に注目しました。正解のSQLクエリが長くなる/ネストが深くなると難しいというのはある意味当然で、それ以外で論文で言及されている課題が具体的にどういうものか、あるいは言及されていないような種類の課題があるかどうかを知るためです。
正解と予測をざっと眺める限り、簡単に考えるべきところで難しい処理をしすぎているような印象を受けました。
原因として考えられるのは、常識に基づく推論がうまくできず、本来は必要ない余計なカラムを使うべきだと判断してしまうからかもしれません。
常識に基づく推論に失敗している例:
質問 Tell me the age of the oldest dog.
正解 SELECT max(age) FROM Dogs
予測 SELECT T1.age FROM Dogs AS T1 ORDER BY T1.date_of_birth DESC LIMIT 1
予測クエリでは、最も若い犬の情報を出力してしまいます。
「maxを取るのだから降順ソート」と短絡的に処理したのかもしれません。
意図とは異なる情報を補った例:
質問 List each charge type and its amount.
正解 SELECT charge_type, charge_amount FROM Charges
予測 SELECT T1.charge_type, sum(T1.charge_amount) FROM Charges AS T1 GROUP BY T1.charge_type
each の意味を取り違えてしまったようです。これは自然言語文の方にも非がある気もします。本来の意図は「各行におけるcharge_typeとcharge_amountをリストせよ」なのですが、単に”each”としか言っていないせいで、IRNetは「各行の」ではなく「各charge_typeの」と解釈したのでしょう。そしてその解釈だと集計関数を使わないと行数が合わなくなって実行できないため、とりあえずよく用いられるsumが集計関数として選ばれたのだと思います。
スキーマを誤った例:
質問 How many flight numbers of flights depart from ‘APG’?
正解 SELECT count(*) FROM FLIGHTS WHERE SourceAirpot = “APG”
予測 SELECT count(*) FROM flights AS T1 JOIN airlines AS T2 WHERE T2.Airline = 1
depart from XXX が WHERE SourceAirport=”XXX” になると予測できていません。
質問 How much does the youngest dog weight?
正解 SELECT weight FROM pets ORDER BY pet_age LIMIT 1
予測 SELECT T1.Age FROM Student AS T1 ORDER BY T1.Age ASC LIMIT 1
petsテーブルを見るべきところでStudentテーブルを見ています。
質問 What is the average number of injuries caused each time?
正解 SELECT avg(injured) FROM death
予測 SELECT T1.date, avg(T2.injured) FROM battle AS T1 JOIN ship AS T3 JOIN death AS T2 GROUP BY T1.date
質問とは関係のないshipテーブル中のdateカラムが入り込んでいます。質問文中の“each time”の意図は「各行で」なのですが、これをカラムだと思って ship テーブル中の date に反応してしまったと推測できます。
それとエラー分析ではないのですが、正しく予測できた事例をいくつかピックアップします。
質問 What is the average and maximum capacities for all stations?
正解 SELECT avg(capacity), max(capacity) FROM stadium
予測 SELECT avg(T1.Capacity), max(T1.Capacity) FROM stadium AS T1
構造的に簡単な例です。
質問 How many cities in each district have a population that is above the average population across all cities?
正解 SELECT count(*), District FROM city WHERE Population > (SELECT avg(Population) FROM city) GROUP BY District
予測 SELECT count(*), T1.District FROM city AS T1 WHERE T1.Population > (SELECT avg(T2.Population) FROM city AS T2) GROUP BY T1.District
ネストがあり、複雑な例です。
質問 How many flights depart from City 'Aberdeen' and have destination City 'Ashley'?
正解 SELECT count(*) FROM FLIGHTS AS T1 JOIN AIRPORTS AS T2 ON T1.DestAirport = T2.AirportCode JOIN AIRPORTS AS T3 ON T1.SourceAirport = T3.AirportCode WHERE T2.City = "Ashley" AND T3.City = "Aberdeen"
予測 SELECT count(*) FROM flights AS T1 JOIN airports AS T2 WHERE T2.City = 1 INTERSECT SELECT count(*) FROM flights AS T3 JOIN airports AS T4 WHERE T4.City = 1
クエリの構造は正解とはかなり違っており、ややこしいことをしていますが、合ってはいるようです。ここまで長い出力を要求されると、正解と構造が大きく異なることが多いです。
まとめ
自然言語からプログラムを生成するSemantic Parsingタスクは、一見よくあるseq2seqなタスクですが、自然言語どうしを変換する手法をそのまま流用しても効果的ではありません。出力のプログラムは実行可能である必要があるからです。
今回紹介したIRNetは、自然言語とSQLの中間表現を導入して、従来よりも正確にSQLを生成しています。ただ、それでも人間にとっては簡単に見える言語理解でもまだ難がありますし、ネストが深い・構造的に複雑なクエリを生成することはさらに困難です。このタスクで解決すべき問題はまだ多く、今後の動向に期待できそうです。
参考文献
- Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation
- microsoft/IRNet: An algorithm for cross-domain NL2SQL
- Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task
- Spider: Yale Semantic Parsing and Text-to-SQL Challenge
- salesforce/WikiSQL: A large annotated semantic parsing corpus for developing natural language interfaces.
- Semantic parsing - Wikipedia
- SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-DomainText-to-SQL Task
- TRANX: A Transition-based Neural Abstract Syntax Parser for Semantic Parsing and Code Generation
- Coarse-to-Fine Decoding for Neural Semantic Parsing
- Entity linking - Wikipedia
- ConceptNet
付録
SQLからSemQLの生成
IRNetは質問からSemQLをニューラルネットで予測し、その予測したSemQLからSQLクエリを確定的に導出する手法です。そのため訓練データとして質問とSemQLのペアを作っておく必要があります。
- Zノードを初期化
- UNION, EXCEPT, INTERSECT を SQLクエリが持っていれば、Z以下に2つのRとその間に(Union, Except, Intersept)を配置する
- Rノード以下にSelectノードを配置する
- SELECT句のカラム数は、Selectノード以下のAノードの数を決める
- ORDERBY句がLIMITキーワードを含んでいればSuperlativeノードに変換する
- LIMITがないORDERBYならOderに変換
- Filter以下の部分木はWHERE/HAVING句の条件によって決まる
- WHERE/HAVING句の中にnested queryを持っている場合、そのサブクエリを再帰的に処理する
- SQLクエリの各カラムのために、A以下に集計関数/C/Tノードをつける
- Cノードはカラム名をつける
- Tノードはそのカラムのテーブル名をつける
- 特殊カラム * (star) のために、どのカラムにも属していないFROM句中の唯一のテーブルがあったとき、カラム名 star を入れて、複数テーブルあれば star のテーブルは人手でラベルする(ここだけ機械的には定まらないので人手で処理している)
- もしFROM句中のテーブルがどのカラムにもアサインされなければ、in条件を伴うFilterノード以下の部分木へ変形される
BERTの利用
IRNetでは、BERTにNL EncoderとSchema Encoderの両方の役割を担わせることにより、テストデータで8ポイントも性能改善が見られました。かなり無理矢理に質問とスキーマを入力しているように見えますが、それでも性能向上できるようです。
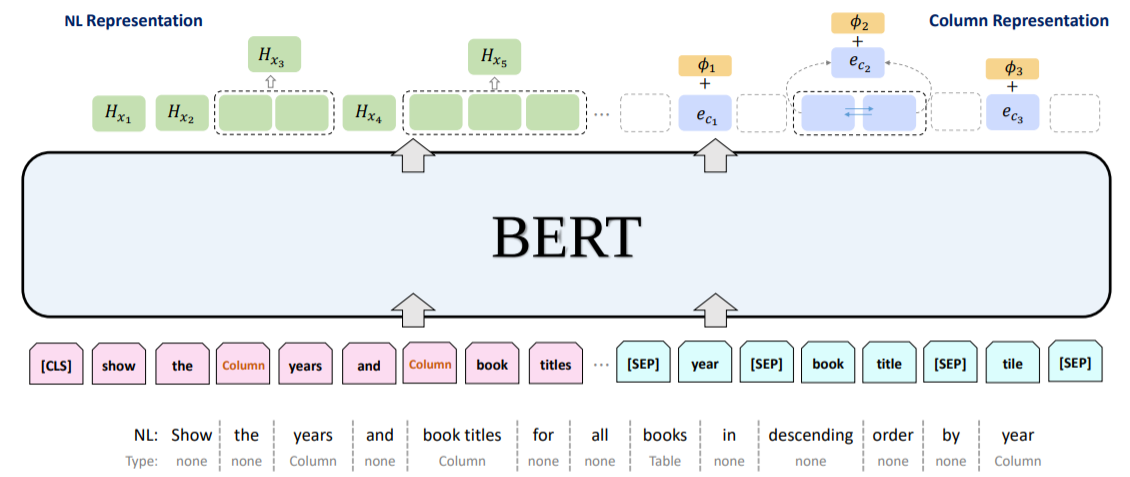
どのような点で改善されたかというと、やはり言語理解の部分です。エラー分析で取り上げられたカラムの予測や常識に基づく操作でエラーが3割ほど減ったようです。ただし、ネストの深い複雑なクエリを上手く出力できないという問題に対してはBERTでもほとんど改善できなかったと報告されています。