日々のビジネスの中でデータを扱っていると、企業名・顧客名・顧客の属性情報などの文字列型のデータを扱うことは避けられません。多くの場合、そういったテキスト型のデータは、グループごとの集計に利用されたり、より深い分析のをするために、他のデータと結合することになりますが、このときに問題になるのが「表記揺れ」です。
例えば、「株式会社」といったテキストの有無や位置、会社名に空白が入っていることで、同じ企業や顧客を同一の存在として認識することは難しくなり、正しい集計や分析結果は得られなくなってしまいます。そこで、そういった問題を解決するために行うのが「名寄せ」などのテキストのデータを適切な形に加工するための処理です。

多くの場合、こういったテキストデータの加工処理は手作業で進めることになりますが、何から始めていいかわからない、といった話を聞くことも少なくありません。
そこで、こちらの記事では名寄せなどを始めとするテキストデータを加工するときに役立つ5つのテクニックを紹介いたします。
1. 変換: 全角/半角
例えば、以下のような「顧客ID」に全角と半角のものが混在しているデータを例に考えてみます。
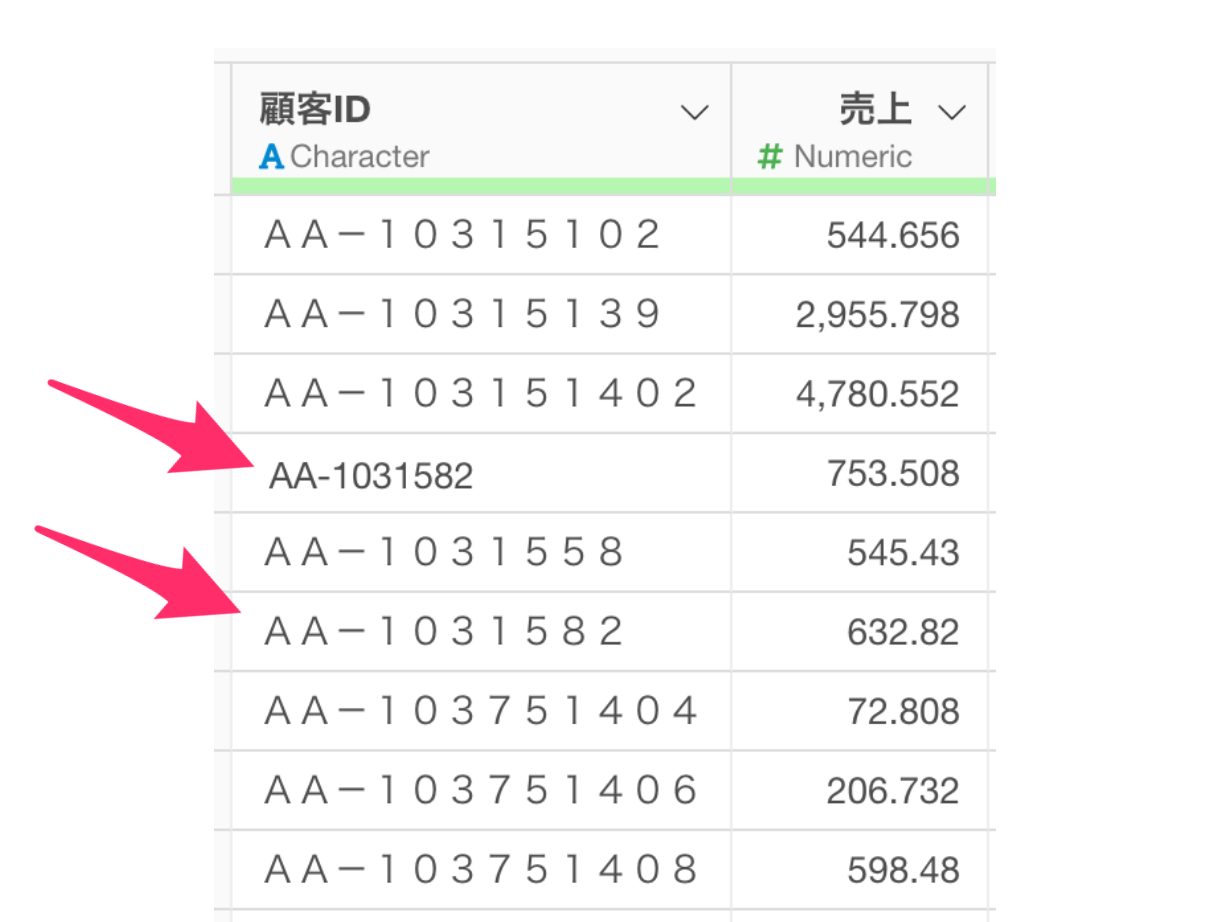
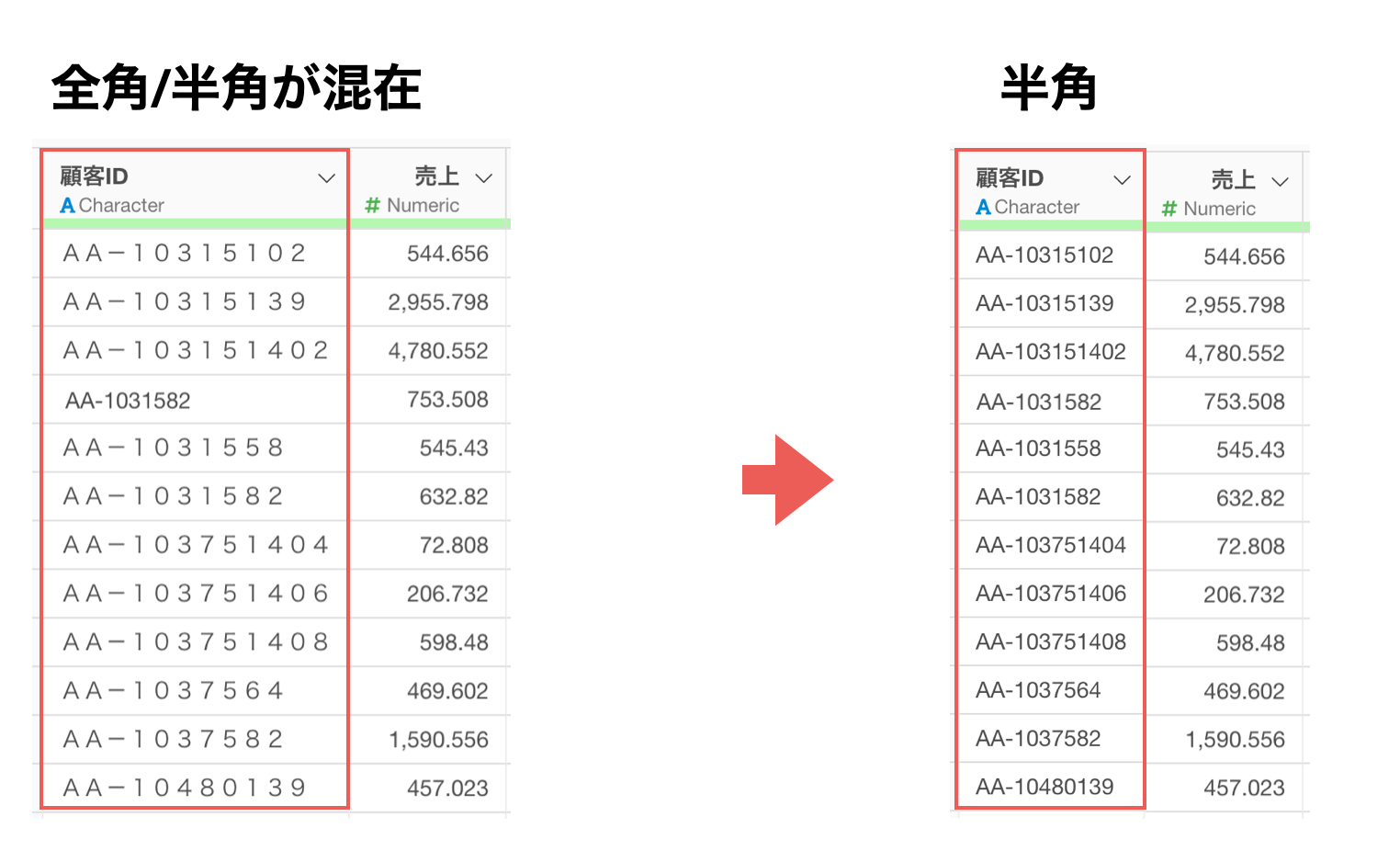
このデータを使って、顧客ごとに売上を集計すると、本来は同じ顧客であるにも関わらず、別の顧客として扱われてしまう、あるいは他のデータと結合をするときに、結合先の顧客IDが半角で統一されている場合、全角の顧客は認識されずにうまく結合ができなくなるわけです。
そこで、このような問題を解決するためには全角/半角を統一することが必要です。
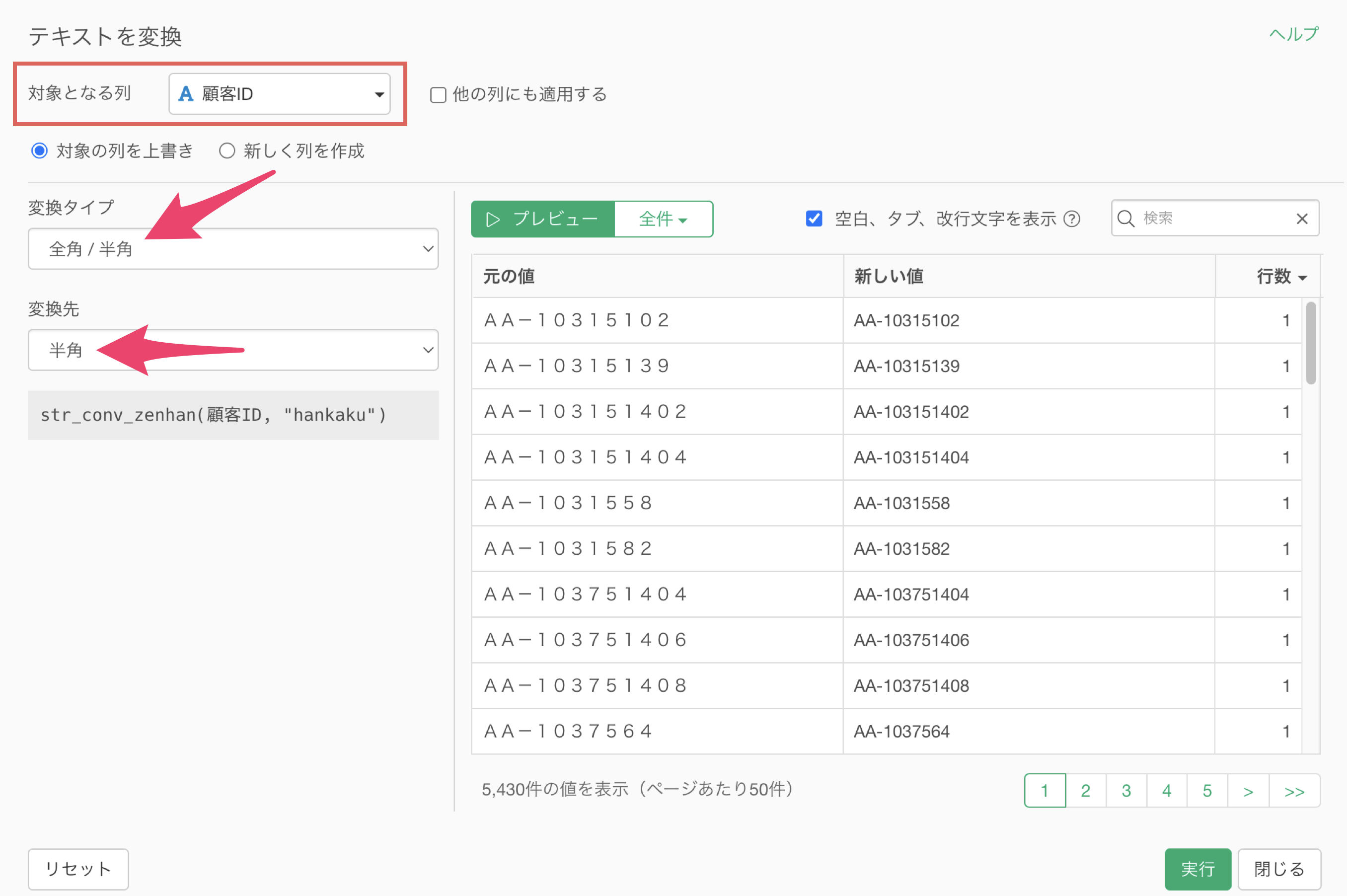
このとき、「列」に対して、全角/半角の変換ができると、1つ1つの「セル」に対して処理を行う必要がなくなるので、作業ミスを未然に防いだり、作業時間の短縮につながります。
2. 変換: 大文字/小文字
テイストデータのローマ字に大文字/小文字が混在していることで、本来であれば、同じ文字列として認識されて欲しいものの、別の文字列として認識されてしまうこともあります。
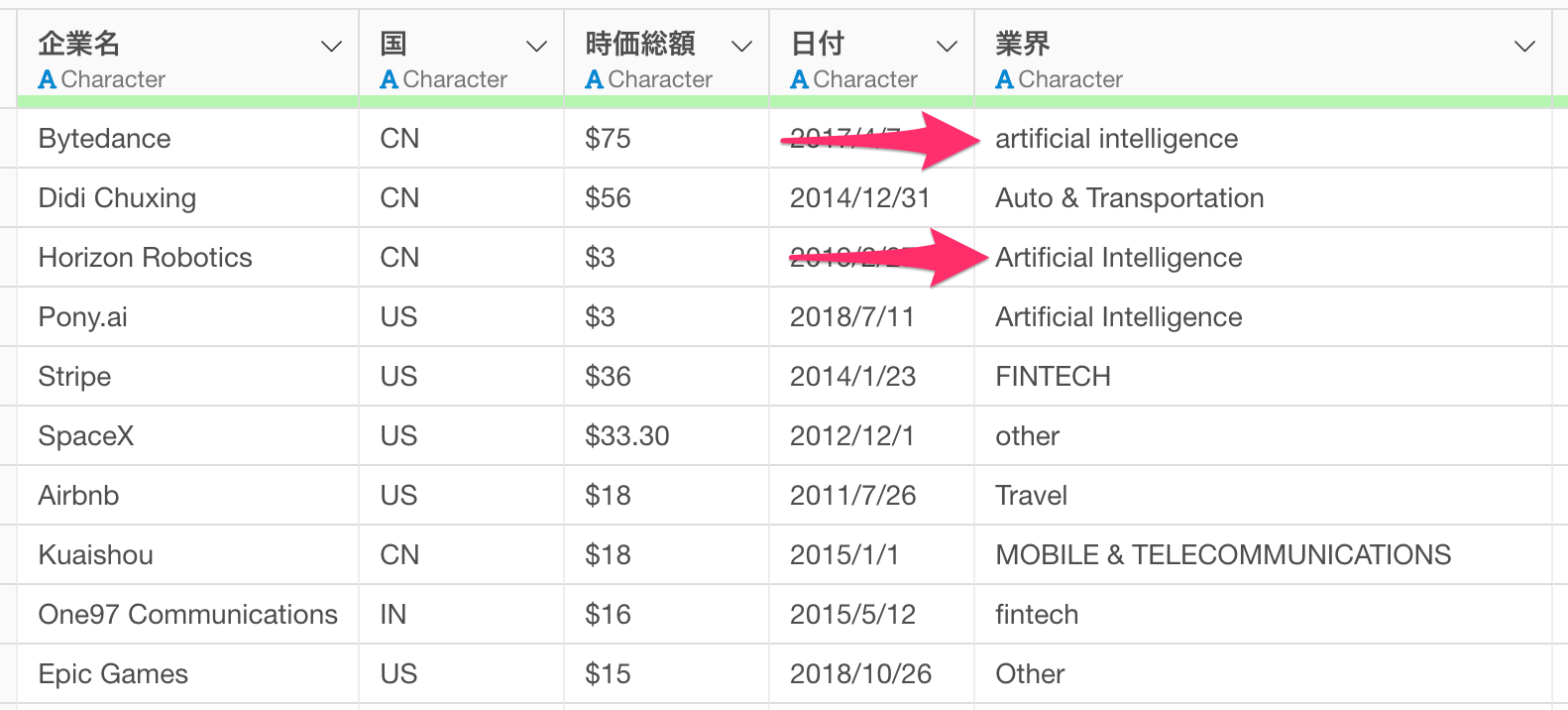
このようなときには、ローマ字を「大文字/小文字/タイトルケース」のいずれかに統一することが必要です。

全角/半角の変換と同様に、「大文字/小文字/タイトルケース」への統一が列に対して行えると、1つ1つの「セル」に対して処理を行う必要がなくなるので、作業ミスを未然に防いだり、作業時間の短縮につながります。
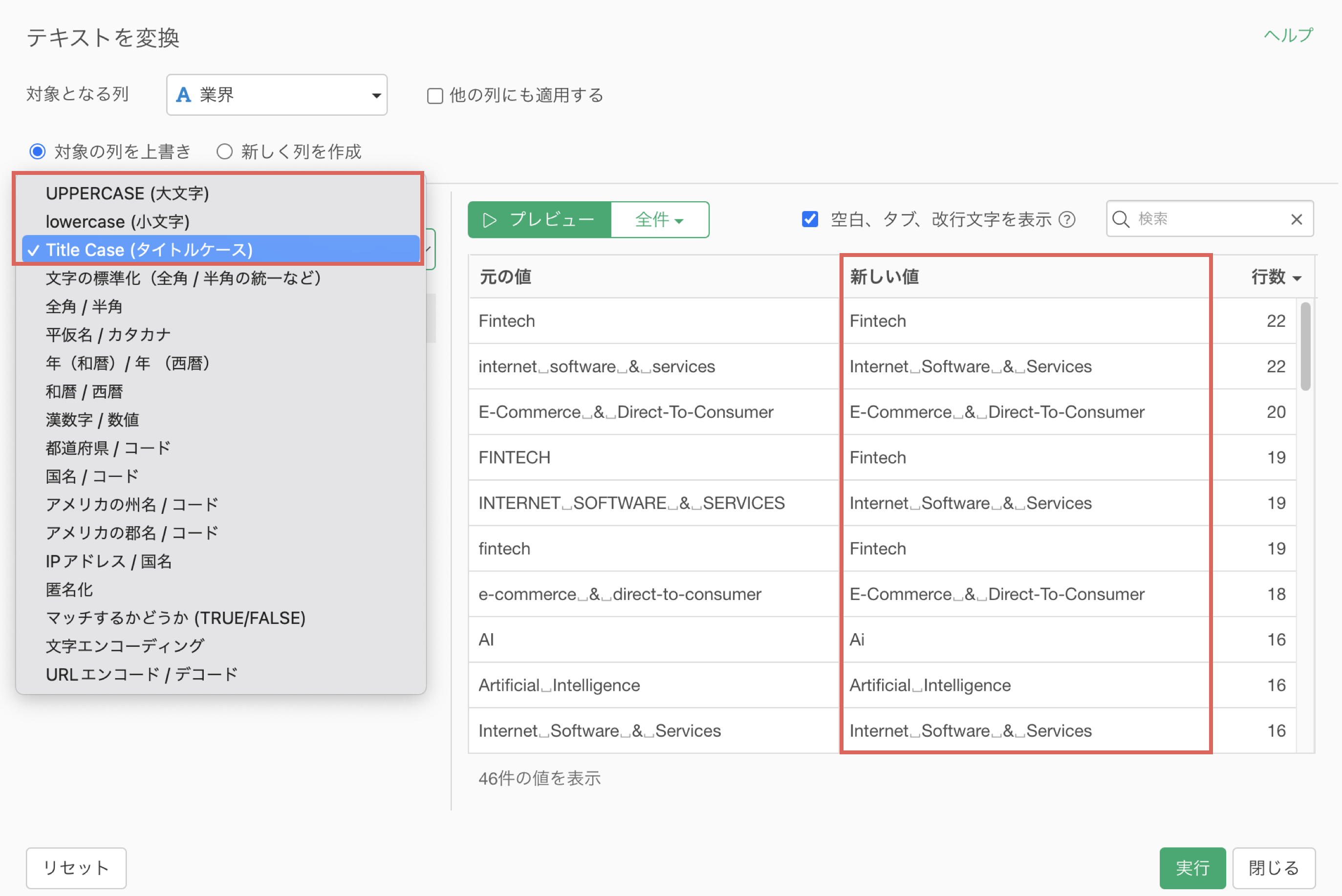
3. 置換: 値の置き換え
同じ意味を表しているにも関わらず、その文字列や言い回しが異なることで、別のカテゴリとして扱われてしまうケースもあります。
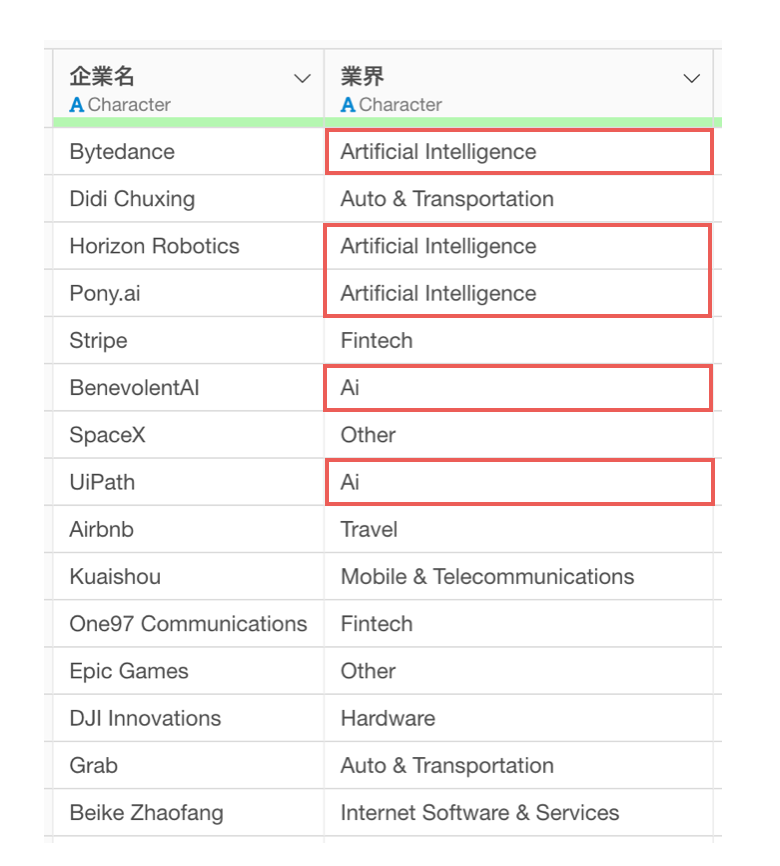
そういったときには、「値」を「別の値に置き換える」ことで、同一のカテゴリとして扱えるようになります。
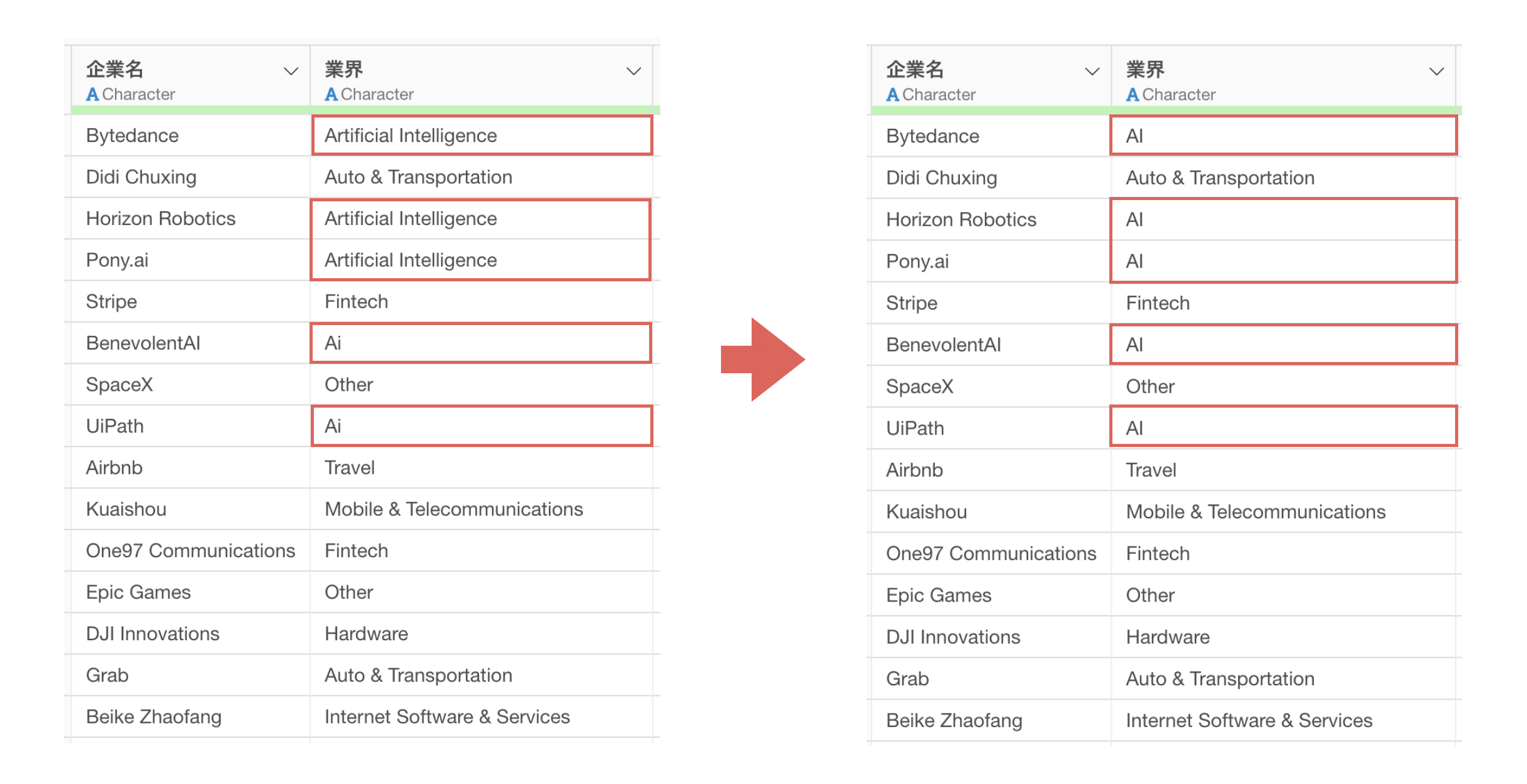
このとき、全ての値のリストに対応する形で、一度に新しい値を指定できると、一度に新しい全ての値を置き換えられるので、作業時間の短縮につながります。
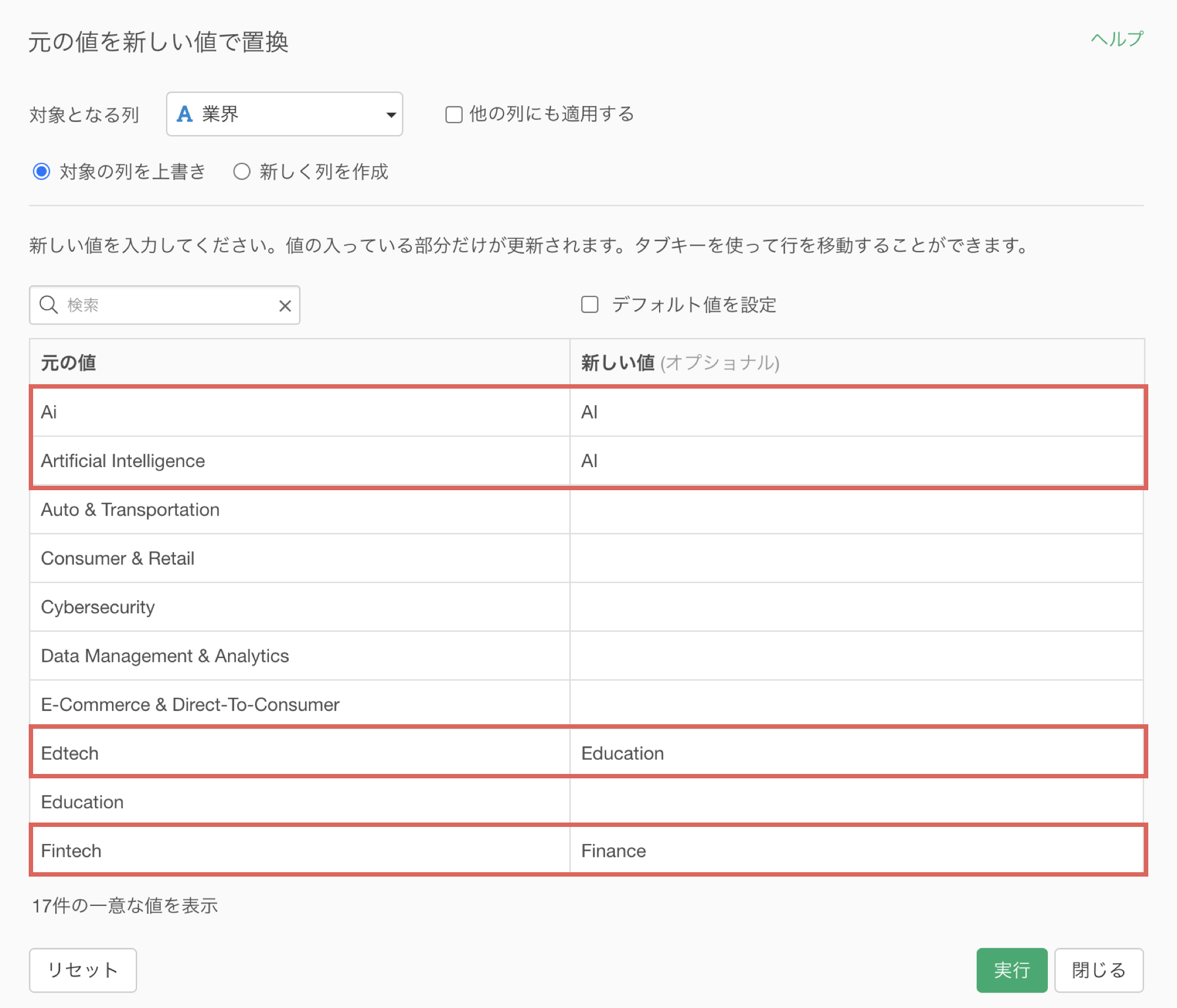
4. 置換: 指定した文字列の置き換え
先程の例は、「値」を置き換える例でしたが、任意の「文字列」を特定の値に置き換えたいこともあります。
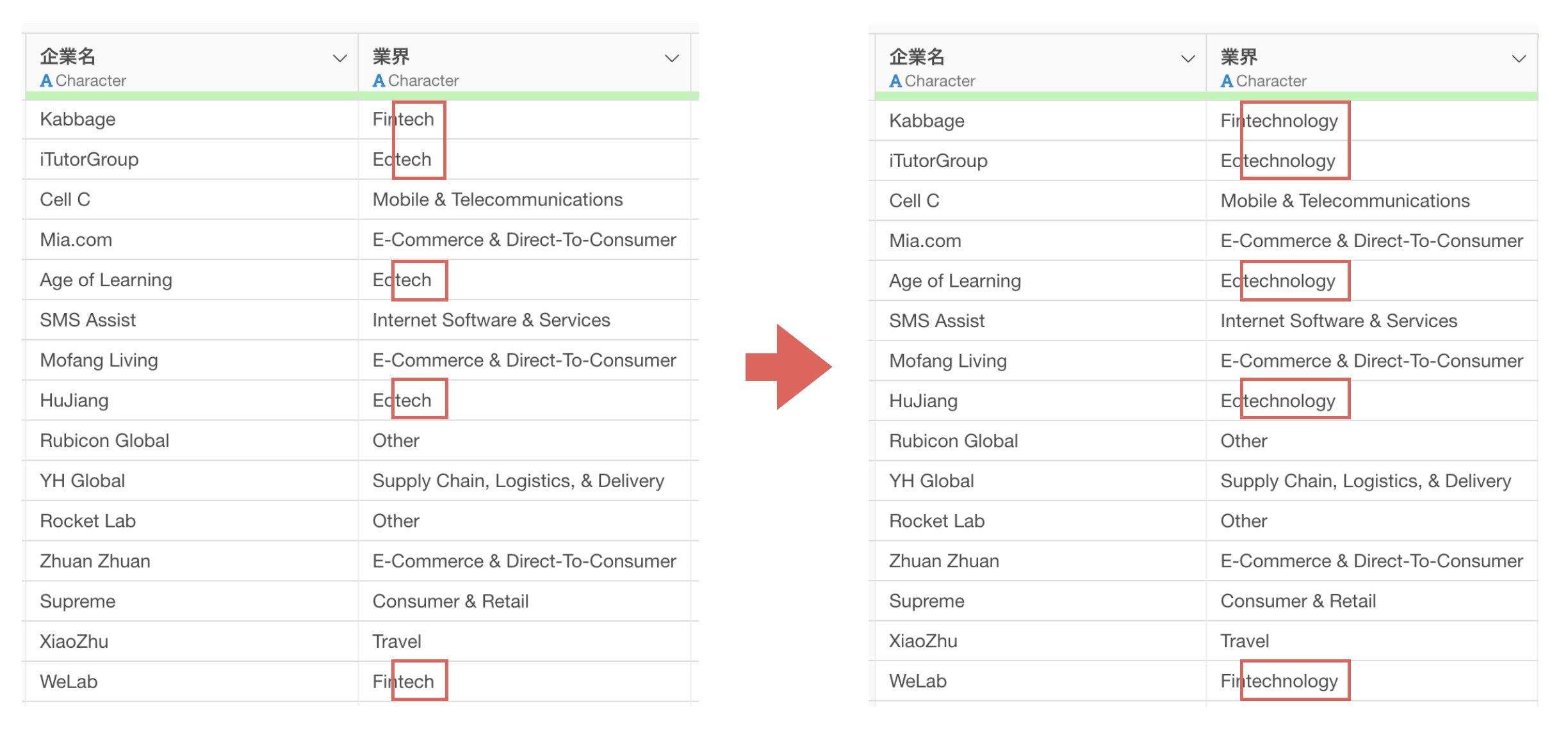
このとき、任意の文字列が存在する位置(例: 先頭、末尾)を指定できれば、より柔軟にデータを加工することができ、データに合わせてより柔軟な処理ができるようになります。
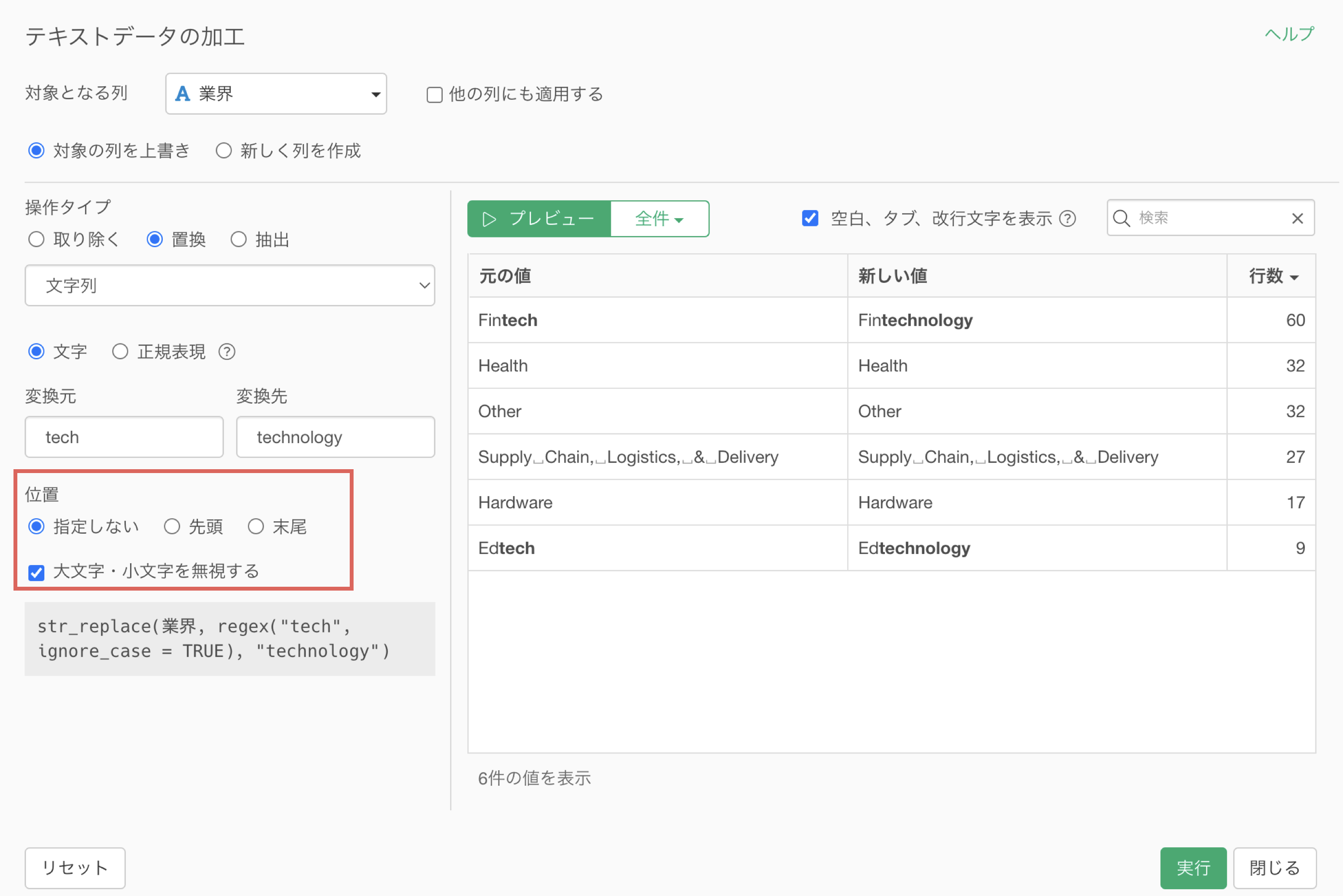
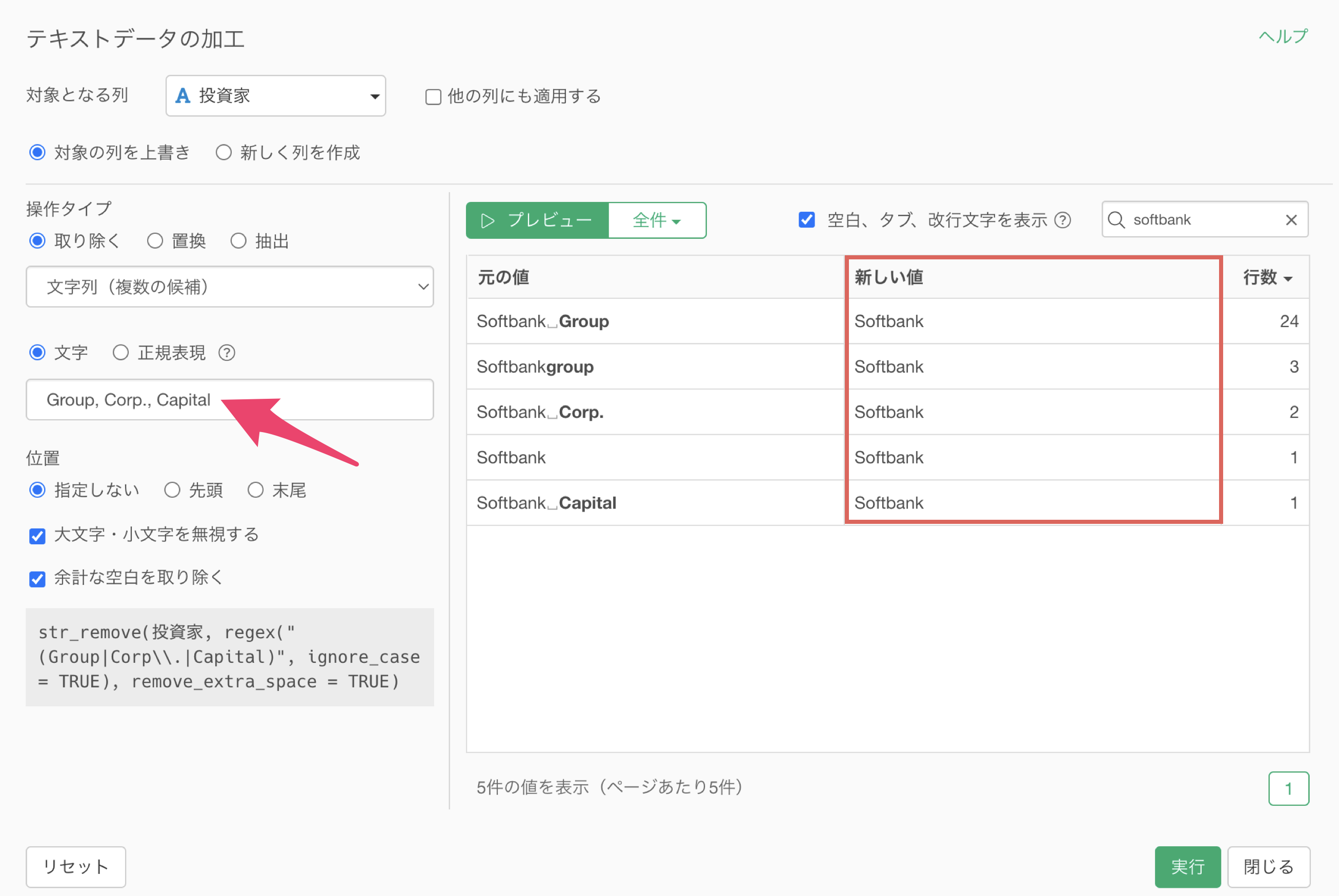
5. 取り除く: 指定した文字列
全く別のパターンとして、テキストデータに余計な文字列が付いていることで、別々のカテゴリーとして認識されてしまうケースもあります。
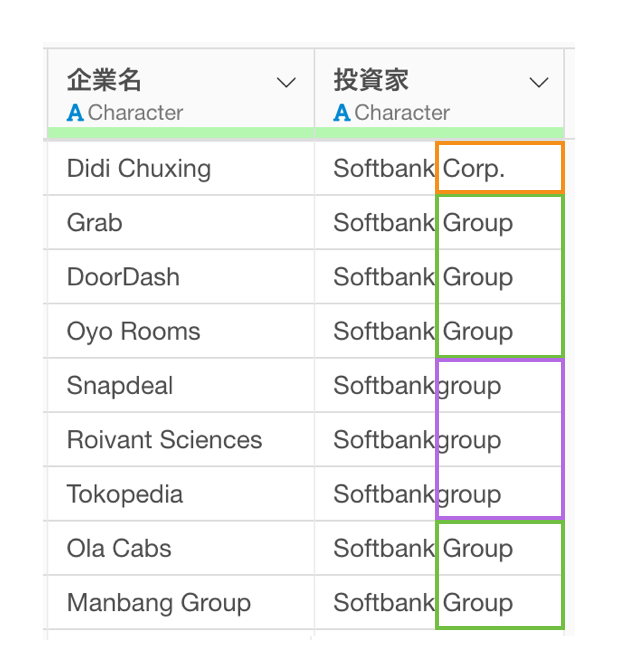
このようなときには、特定の文字列を削除することで、別々のカテゴリーとして認識されてしまうカテゴリーを同一のカテゴリーとして扱うことが可能です。
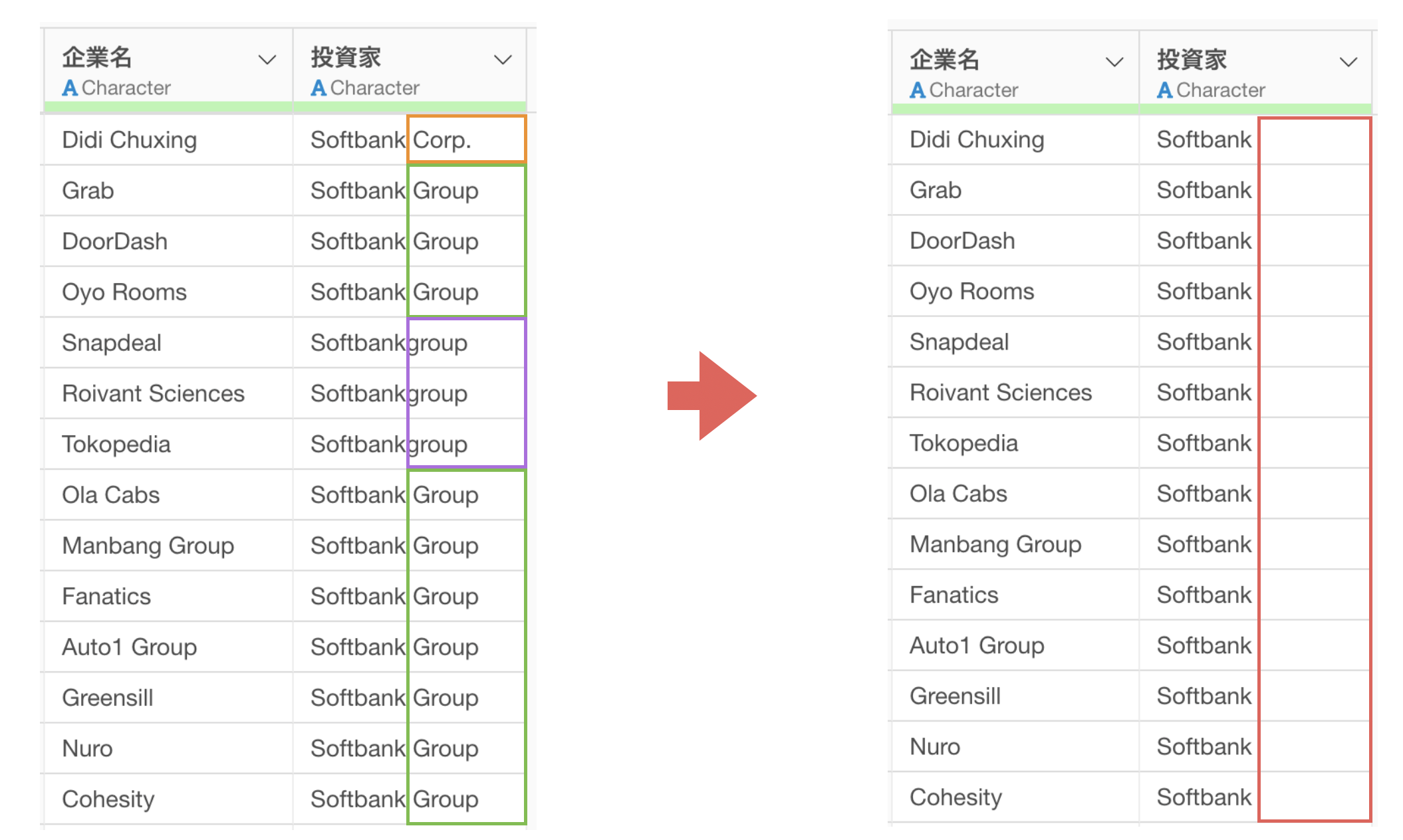
なお、このような処理をするときに、1つの文字列だけでなく、同時に複数のパターンの文字列を取り除くことができれば、パターンを変えて、何度も同じような処理をせずに済み、より効率的に作業を進められるようになります。
データの再現性と自動化
こういった名寄せの作業は一回きりで終わることはなく、多くの場合、異なるデータに対して、繰り返し同じような処理をしていくことになります。
そのため、名寄せにおいて最も重要なことは、データ加工の再現性です。
仮に過去に行ったテキストデータの加工のプロセスを時間をかけることなく再現することができ、さらに別のデータに対しても同じように実行できれば、テキストデータの加工にかかる時間を圧倒的に短縮することができるだけでなく、マニュルアル作業であるがゆえに生じるミスも未然に防ぐことが可能です。
もっと知りたい、やり方を学びたい!

今回は、名寄せなどのテキストデータの加工の際に必須の5つのテクニックを紹介しましたが、実際に汚いテキストデータを綺麗にして、使えるようにするためには、今回紹介したテクニックだけでは完結しないことも少なくありません。
そこで、今回紹介したテキストデータの加工を含む、様々なデータ加工のテクニックの詳細を知りたい、あるいは、そういった作業を自分でもできるようになりたい・自動化したい方は、来年の1月にデータラングリングのスキルを1から体系的に、そして効率的に身に着けていただくためのトレーニングを開催いたしますので、そちらへのご参加をご検討いただければと思います!