マーケティング担当者にとって、より多くの新規顧客を開拓し、既存顧客のエンゲージメントを高めることが何よりも重要となります。
データを使うとより効率的に、顧客セグメントを発見しそれぞれの顧客に合ったプロモーションを行ったり、自社サービスを購入される可能性の高い見込み顧客に的を絞った効果的なマーケティング活動を実行していくことができるようになります。
しかし、いざデータを活用し始めようとすると困るのが、そもそもどういった分析手法を使えば良いのかわからないということです。
そこで、マーケティング担当者が使いこなせるようになるべき5つの分析手法を、どのようなシーンで利用できるかという例を使って紹介します。
5つの分析手法
今回は、以下の5つの分析手法と、それぞれのアナリティクスがどのような目的で利用できるのかを紹介します。
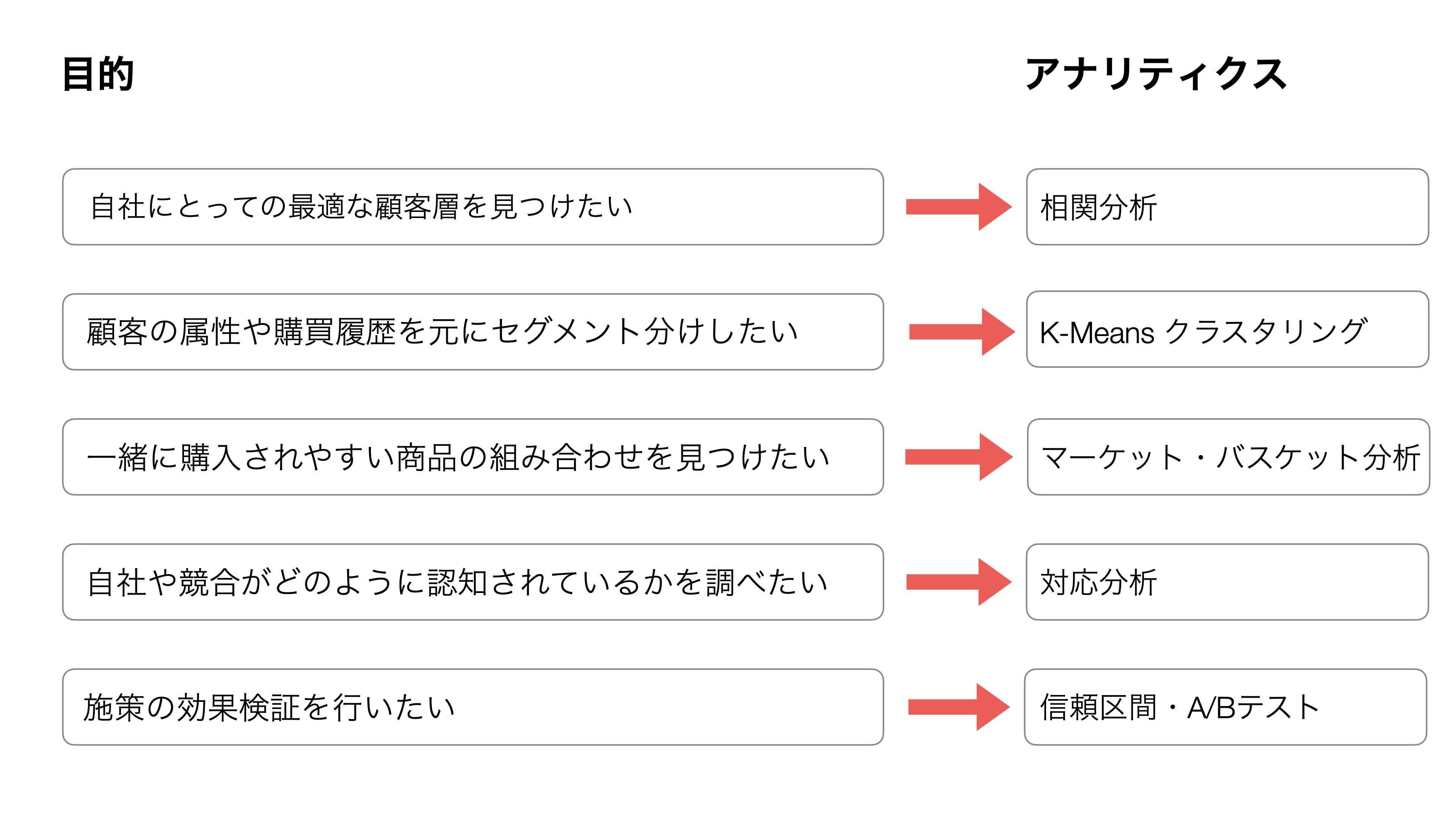
1. 相関分析: 自社にとっての最適な顧客層を見つける
「相関」とは、2つの変数のうち、1つの変数の値が変わると、もう1つの変数の値も一定の規則をもって一緒に変わる関係です。
例えばNetflixのような動画視聴サービスを例に考えてみます。
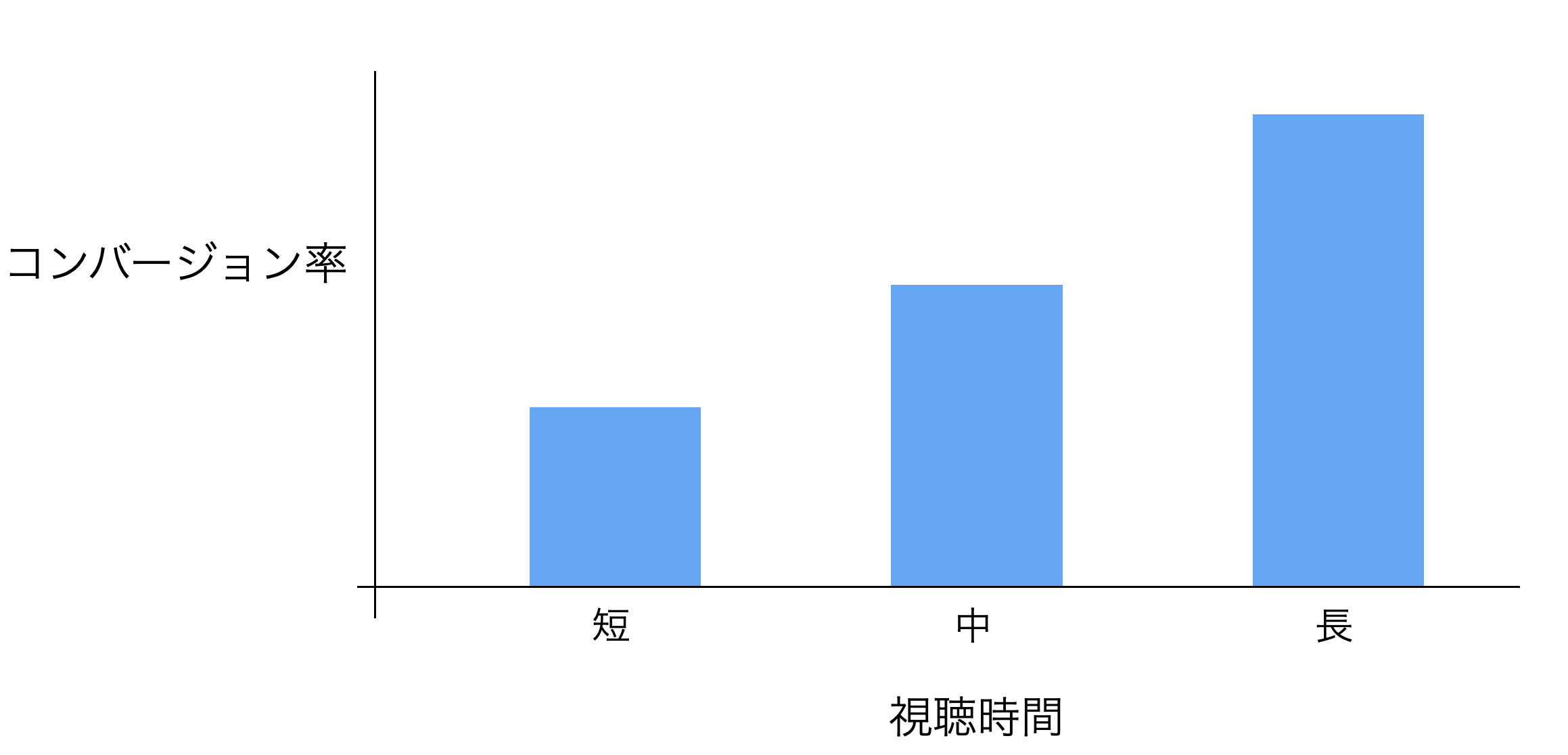
トライアル中の「視聴時間」が伸びると、コンバージョン率が上がるような「相関関係」を確認することができれば、視聴時間を伸ばすためのアクションを実行して、コンバージョン率(効率)を高められるかもしれません。
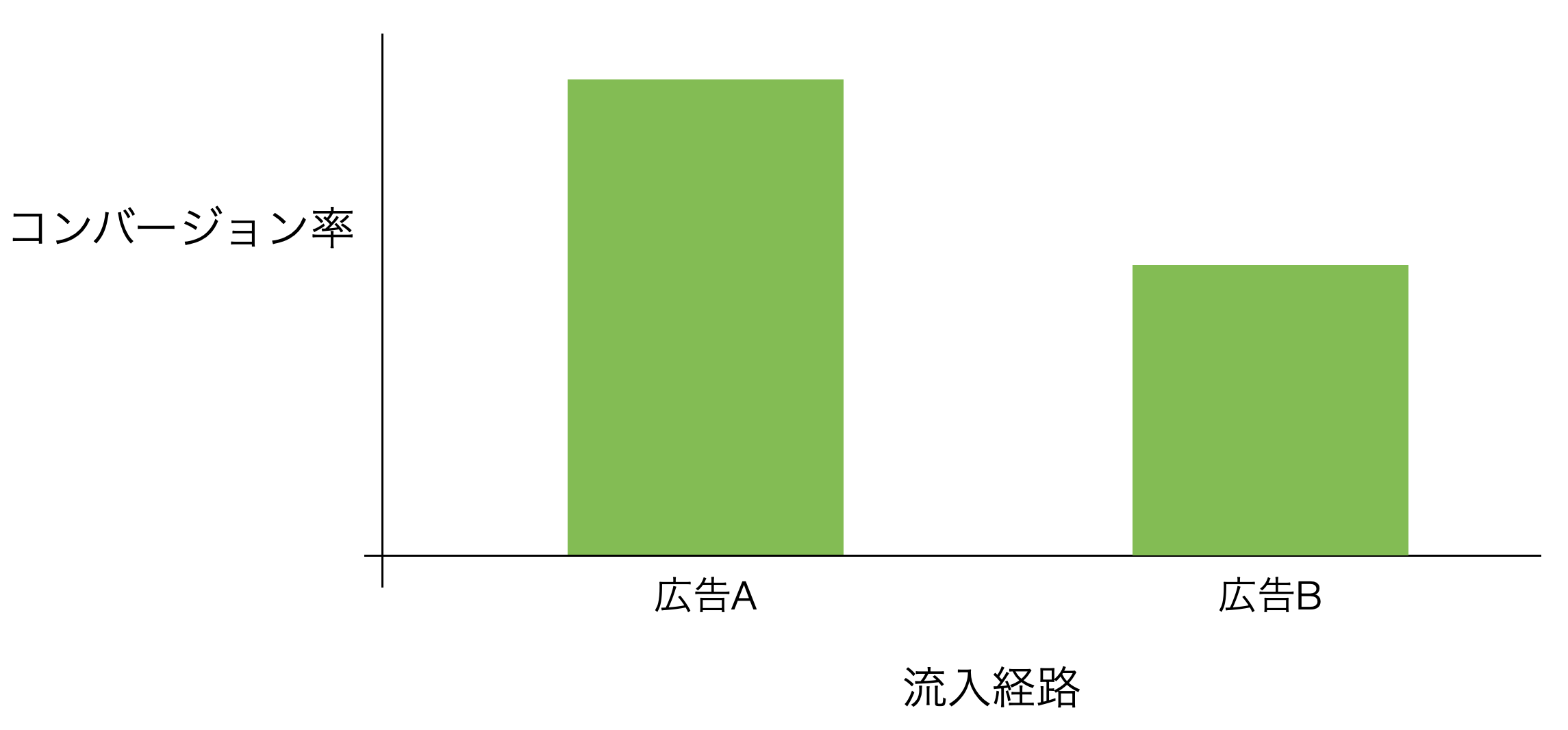
あるいは、特定の広告から流入してきて、トライアルを始めるとコンバージョン率が上がるのであれば、そういった効率の良い広告に予算を寄せることで、広告の効果を高められるかもしれません。
こういった相関関係を調べるときは、バーやラインなどのチャートを使って変数ごとにコンバージョン率を比べることになります。
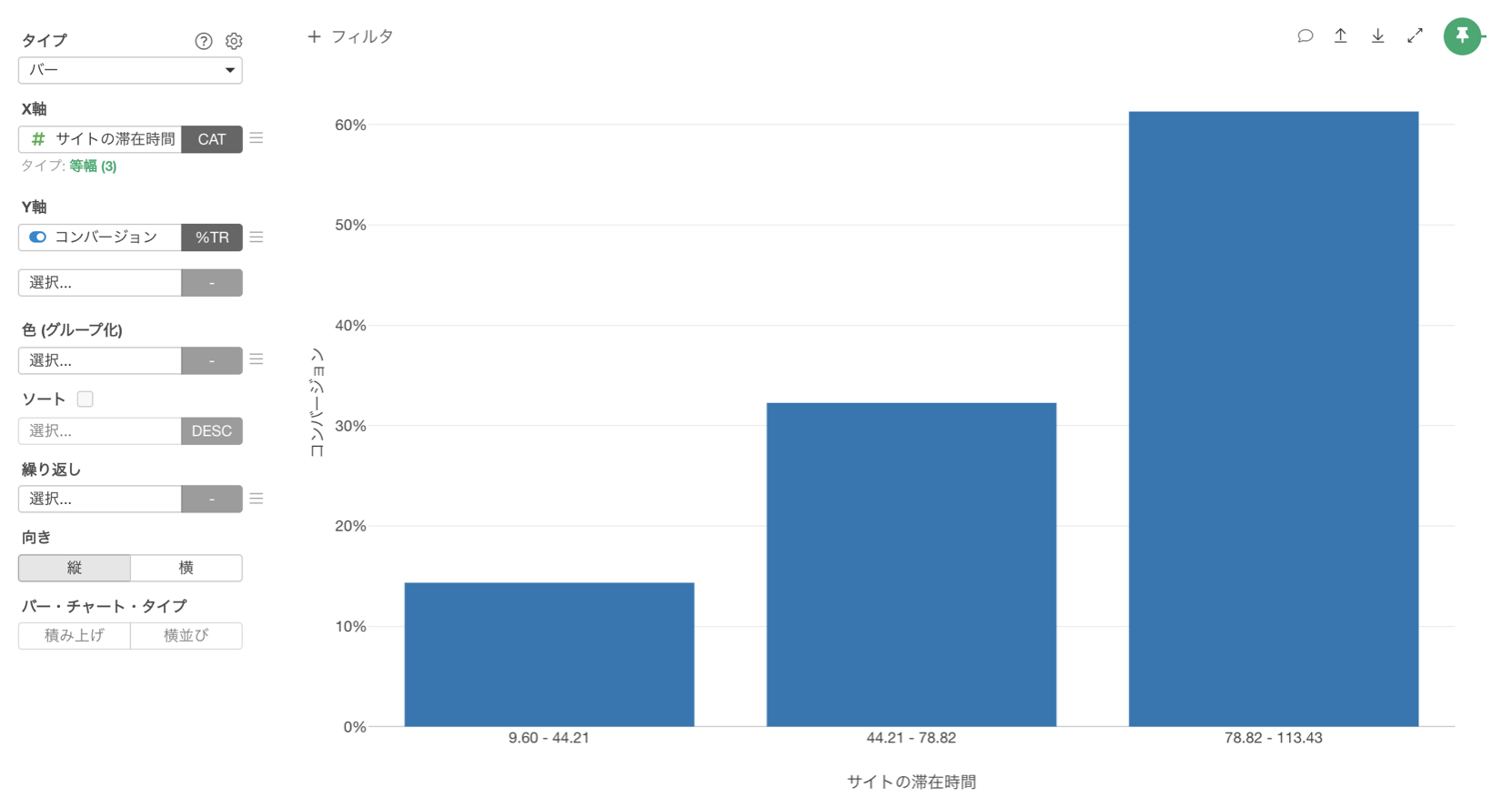
ただし顧客から取得可能なデータは多く、全てのデータ(変数)を使い沢山のチャートを作ってコンバージョン率を比べるのは手間がかかります。
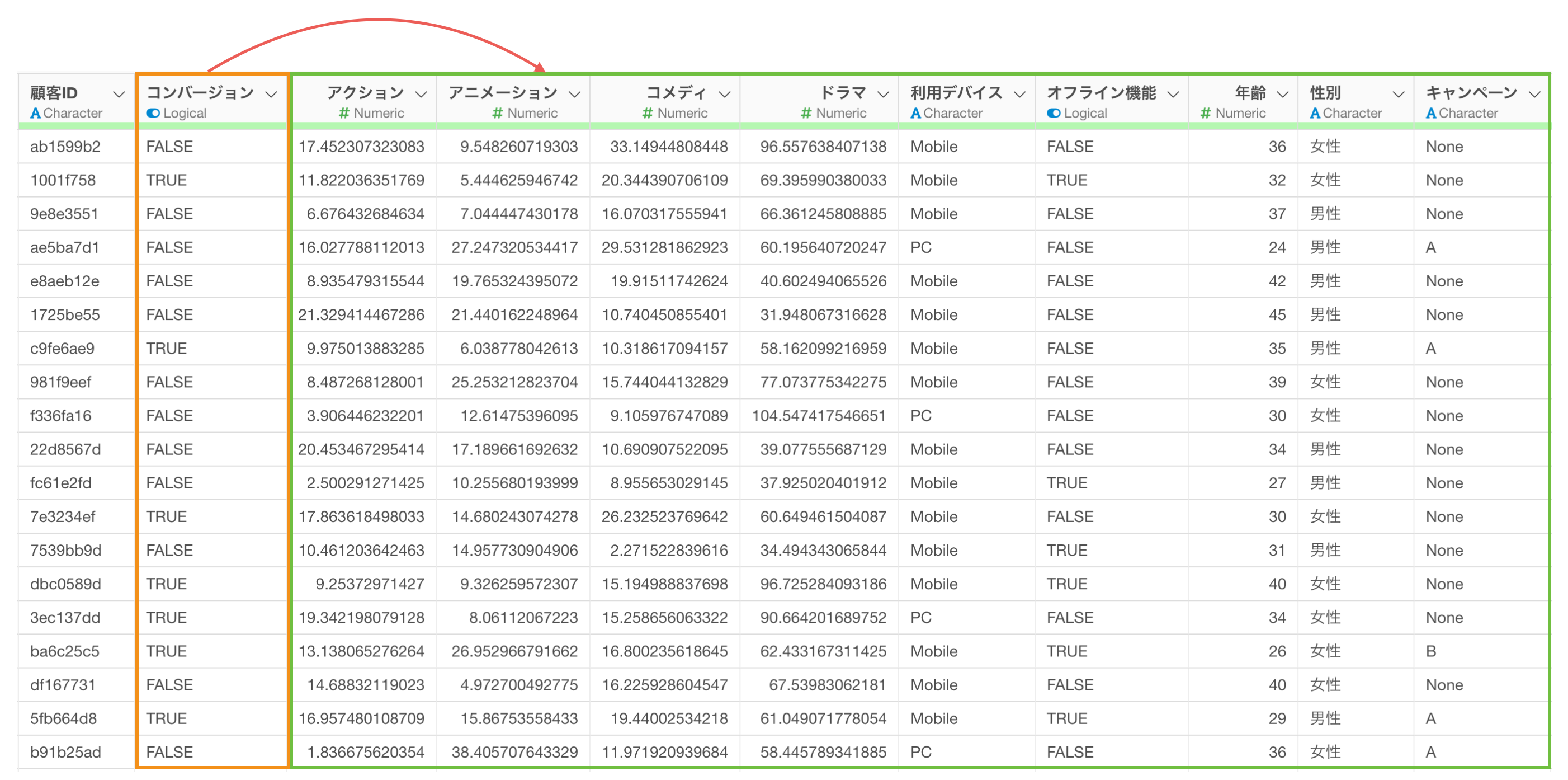
そこで、注目している変数(コンバージョン率)と、他の変数の相関関係を一度に調べることができれば、どういったセグメントや活動に注力すればいいかのヒントをスピーディーに調べられます。
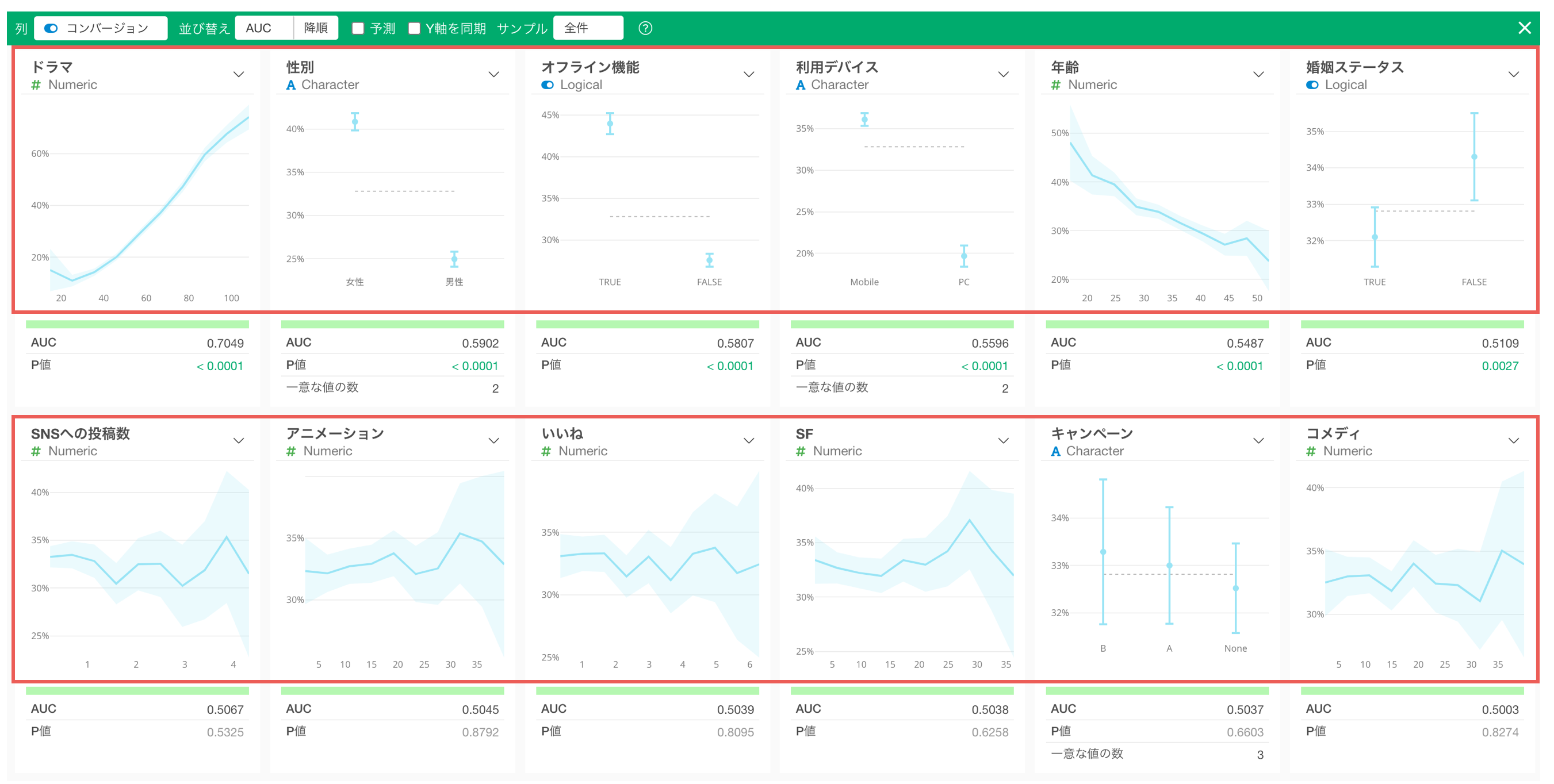
さらに、コンバージョンしたかどうかどうかのように、Yes/Noで答えられる変数との相関の強さは「AUC」という指標で計算できます。
そのため「AUC」が大きい順に変数を並び替えられれば、コンバージョンと相関が強い変数を一瞬で確認できます。
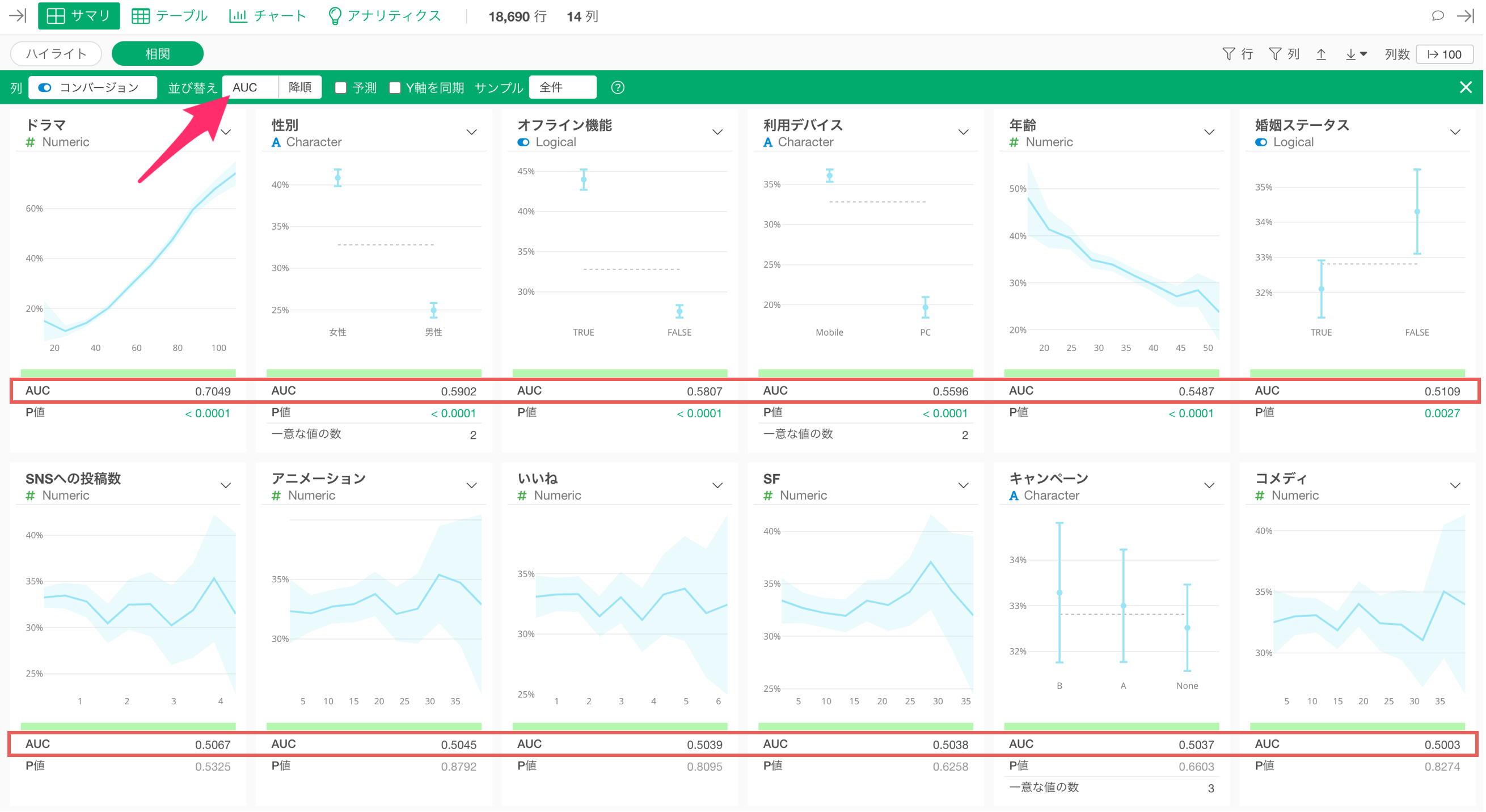
なお、データの加工、可視化、分析、レポーティングのためのUIツールのExploratoryでは、「相関モード」を利用して、注目している変数(例: コンバージョン)と相関関係が強い(AUCが大きい)順に変数をソートしたうえで相関関係を調べられるので、注力すべきやセグメントや活動に関するヒントを瞬時に得られます。
2. K-Means クラスタリング: 顧客の属性や購買履歴を元にセグメントに分ける
エンゲージメントやコンバージョン率を上げるために、顧客にメールなどで情報を発信したりキャンペーンをオファーすることは、よくやることの一つです。
そういったときに役立つ情報は人それぞれに異なるため、顧客ごとにパーソナライズしたコミュニケーションを取れることがベストですが、現実的には費用や労力の関係でそういったことは現実的ではありません。
そこで、顧客を「属性」や「購買行動」、言い換えれば、顧客ごとの特徴や嗜好をもとに顧客をグループに分けられたらどうでしょうか。
それぞれのグループに応じてプロモーションやコミュニケーションを進められるので、現実的なコストや労力の中でエンゲージメントやコンバージョン率を高めるためのコミュニケーションやアクションを実行できるのです。
しかし、実際に顧客のデータを扱うときに使える行動データやアンケートの回答には、多数の指標が多数あるため、それら全てを使って、人間がうまく顧客をグループに分けることは不可能と言えるでしょう。
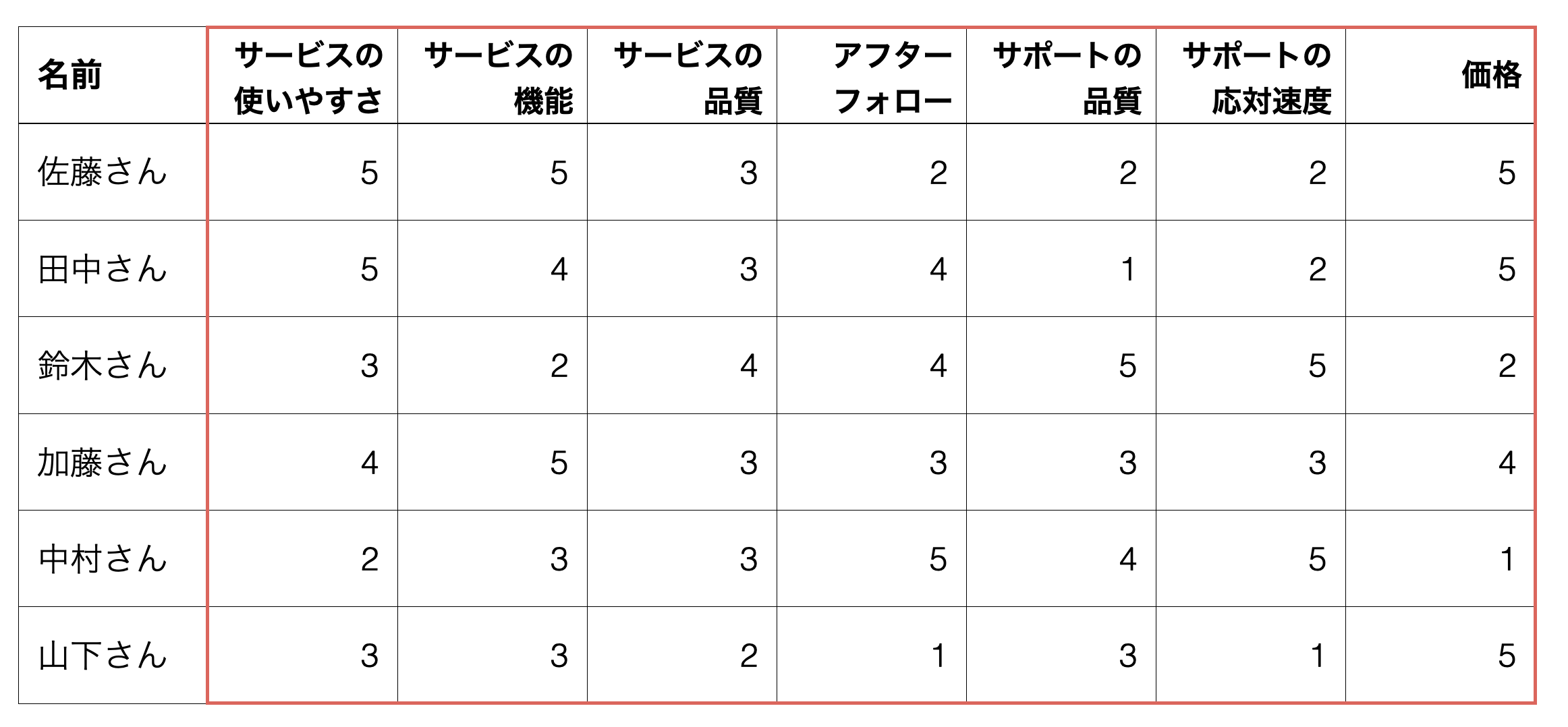
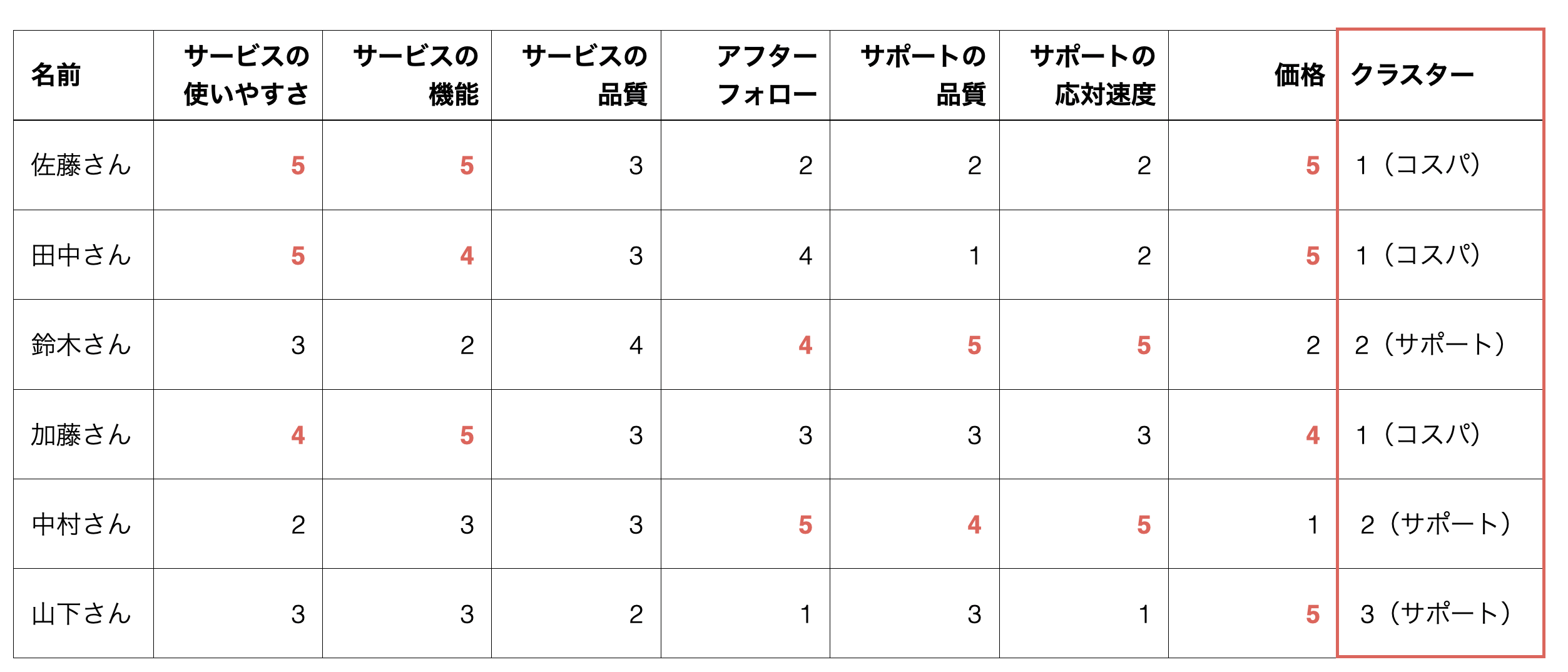
そういったときには、「K-Meansクラスタリング」という手法を使ってデータの中にあるパターンを読み取らせて、セグメントに分けることができます。
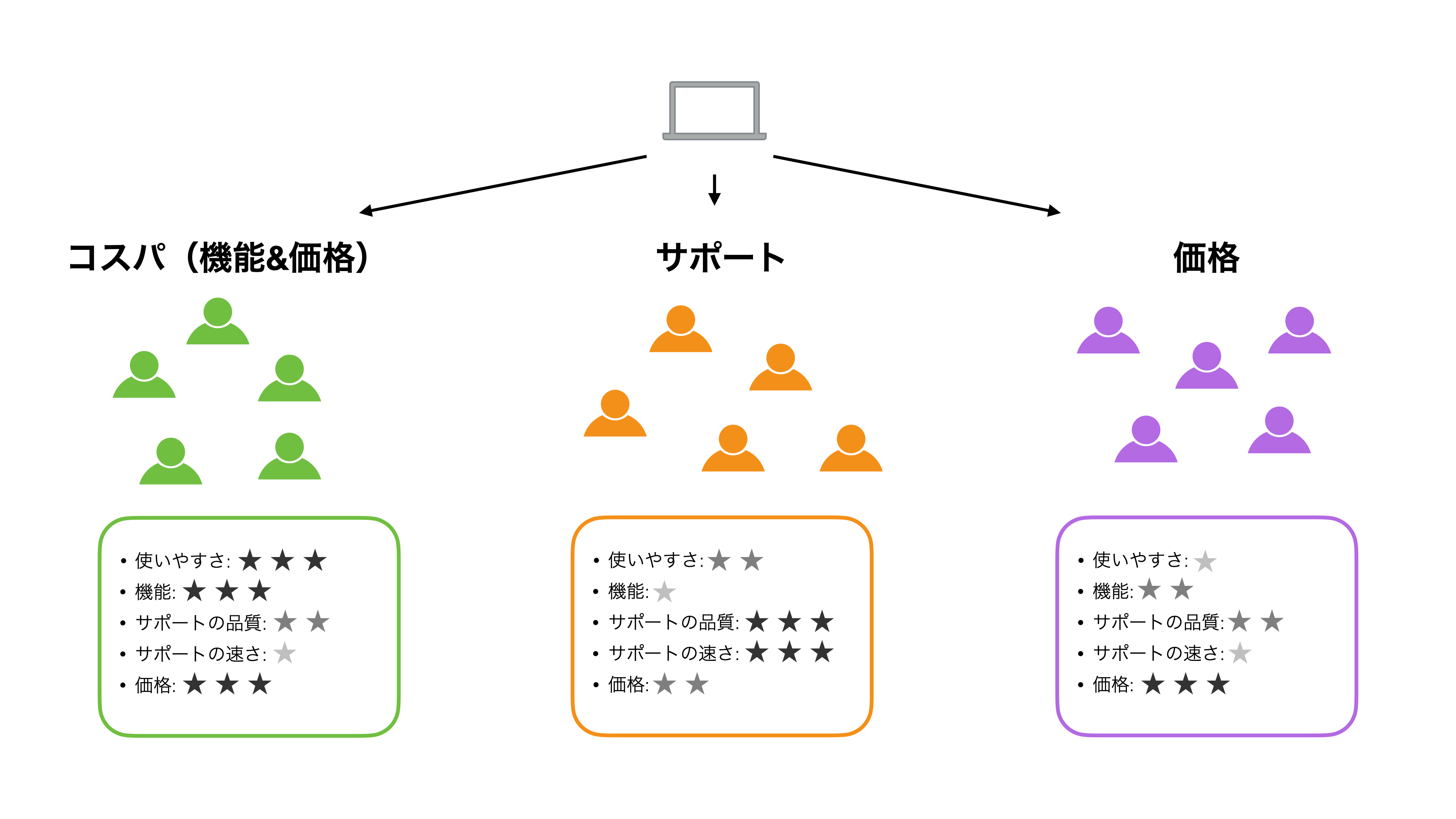
K-Meansクラスタリングを行い各顧客のデータにクラスター(セグメント)の情報を付与することで、その情報をもとにコミュニケーションやアクションを実行できるようになるわけです。
3. マーケット・バスケット分析: 一緒に購入されやすい商品の組み合わせを見つける
ECや小売のビジネスにおいて、1人の顧客からの得られる購入金額を増やすことは非常に重要です。
そこでセット販売することで売れやすい商品の組み合わせや、ある商品を購入しているときに購入されやすい別の商品の組み合わせを理解できれば、効果的なプロモーションやキャンペーンのヒントを得られます。
多くの場合、そういった組み合わせは勘や経験を元に考えることになります。しかし、このとき知りたいのは誰もが思い付くような「パンとソーセージ」あるいは「コーヒーと牛乳」のような当たり前の組み合わせではありません。
知りたいのは直感では思いつかないような「オムツとビール」の例のような新しい組み合わせのアイディアです。(米国のスーパーマーケットのPOSデータを分析をしたところ、おむつとビールがセットで購入されていることが発見されたという有名な逸話があります)

そこで、商品の販売データを使って、1回の購買の中で購入されている商品の組み合わせを集計することで、勘や経験では気付けない組み合わせを発見することが可能です。
これを実現するのが「マーケット・バスケット分析」という分析手法です。
なお、商品の組み合わせの数を計算するだけであれば、手作業で集計すれば済むように思うかもしれません。
しかし、単純に集計をしただけでは、最も多い商品の組み合わせは一番売れている商品と、二番目に売れている商品の組み合わせだったということになりかねません。
そういった情報は、マーケティングの打ち手に役立つような情報とは言えません。
そこでマーケット・バスケット分析では、商品の組み合わせの数を計算するだけでなく、上記のような取るに足らない組み合わせではなく、注目に値する組み合わせかどうかを判断することに役立つ指標を計算します。
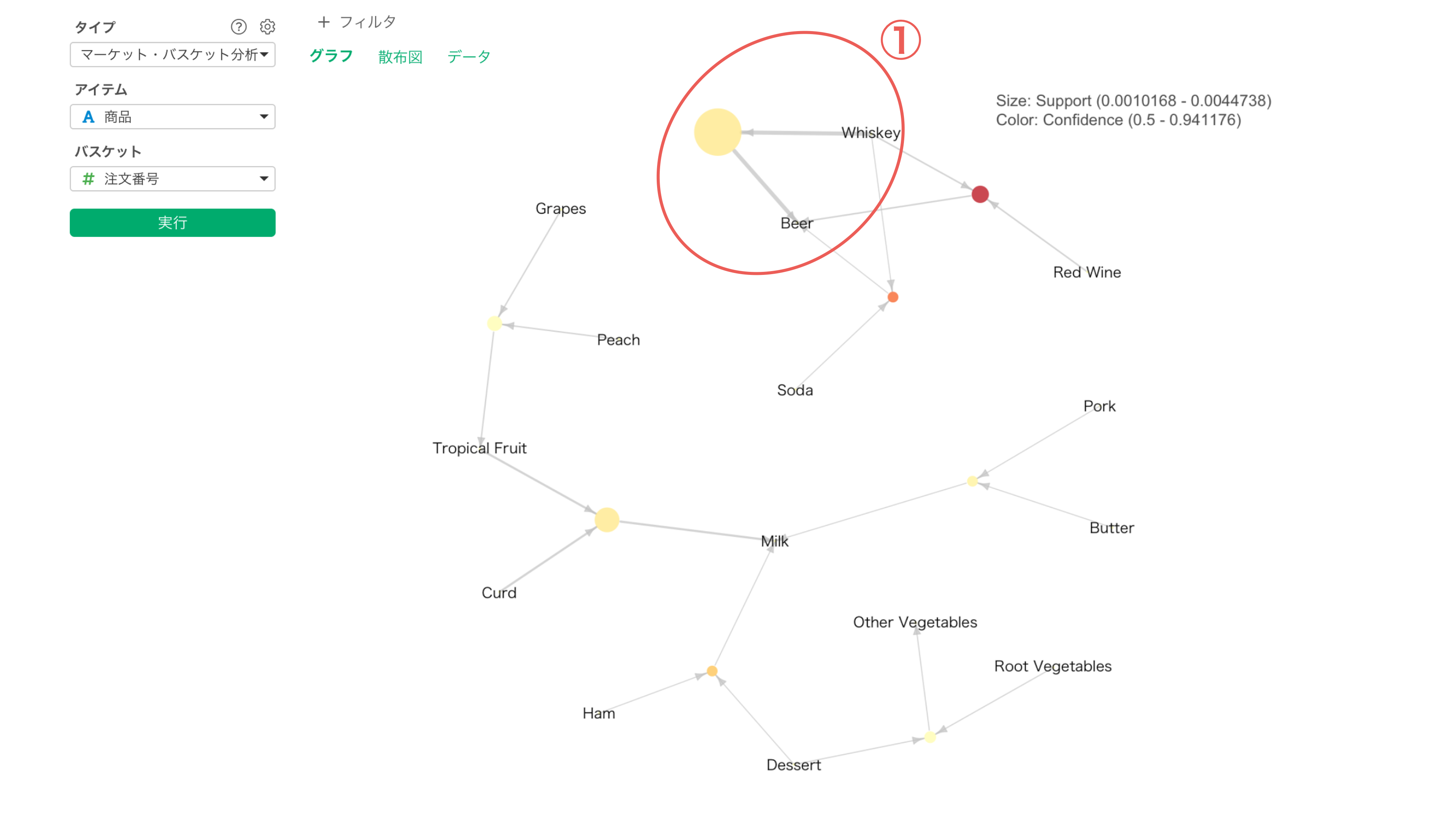
例えば以下はマーケット・バスケット分析の結果を表す「ネットーワーク図」ですが、①に注目すると、「ウィスキーを購入したときにビールも一緒に購入する」という組み合わせが最も多い組み合わせということが分かります。
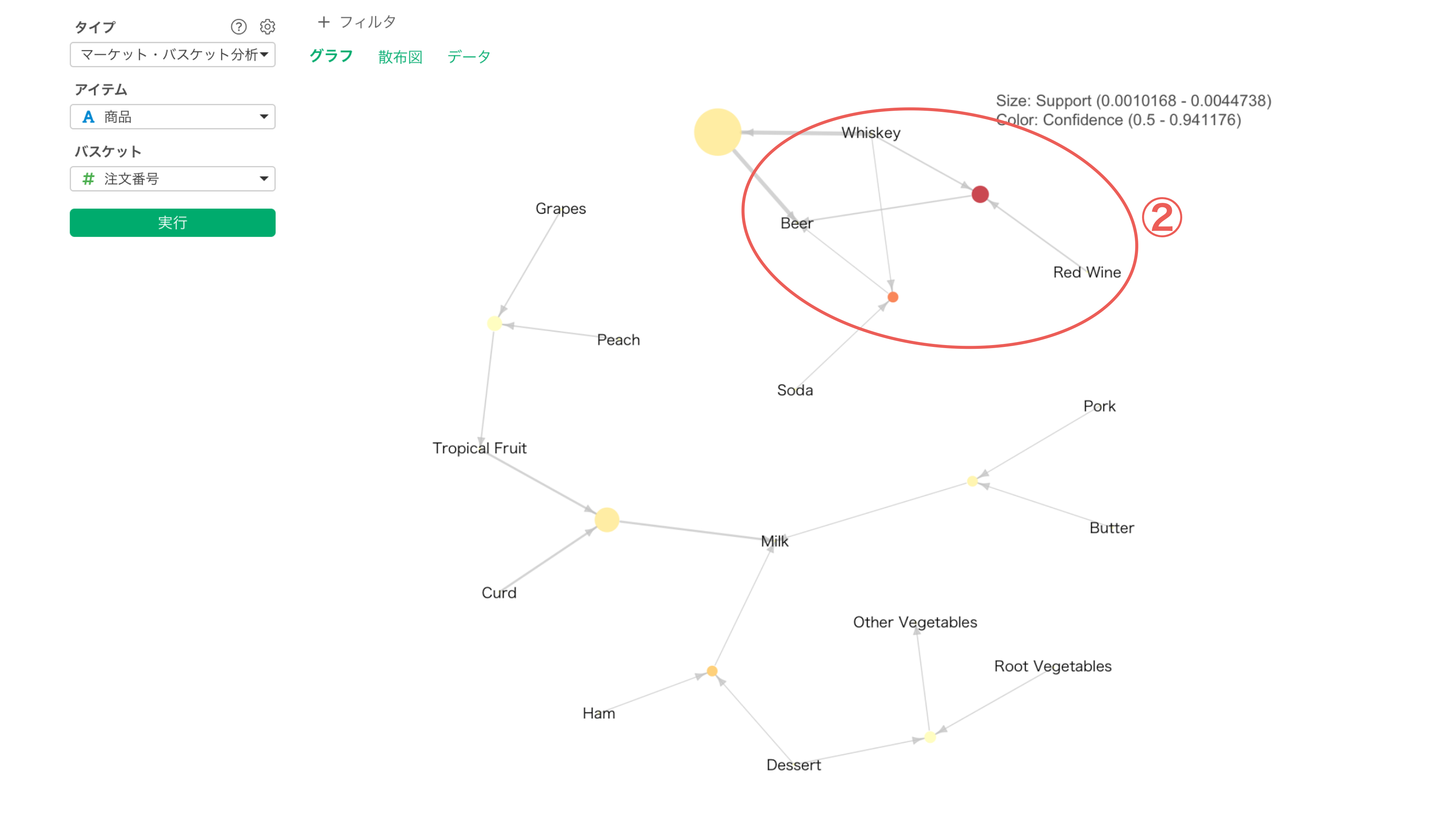
また②に注目すると、「ウィスキーと赤ワインを購入したときにビールが購入される」というルールが、最も一緒に購買される関係が強いルールと言えるのです。
このような結果からヒントを得て、商品の陳列やプロモーションやキャンペーンの設計のヒントを得られるわけです。
なお、このマーケット・バスケット分析の活用範囲は広く、一回ごとの購買(カゴの中身)に注目するのではなく、顧客購買行動全体をカゴに見立てて、顧客の生涯を通してどのような商品が組み合わせて購入されやすいかを分析して、クロスセルのプロモーションのヒントを得ることにも利用が可能です。
4. 対応(コレスポンデンス)分析: 自社や競合がどのように認知されているかを調べる
自社や競合がどのように市場に認知されているのかを理解して、マーケティング活動の中で発信するメッセージを決めていく/最適化していくことはマーケティング担当者にとって非常に重要なことです。
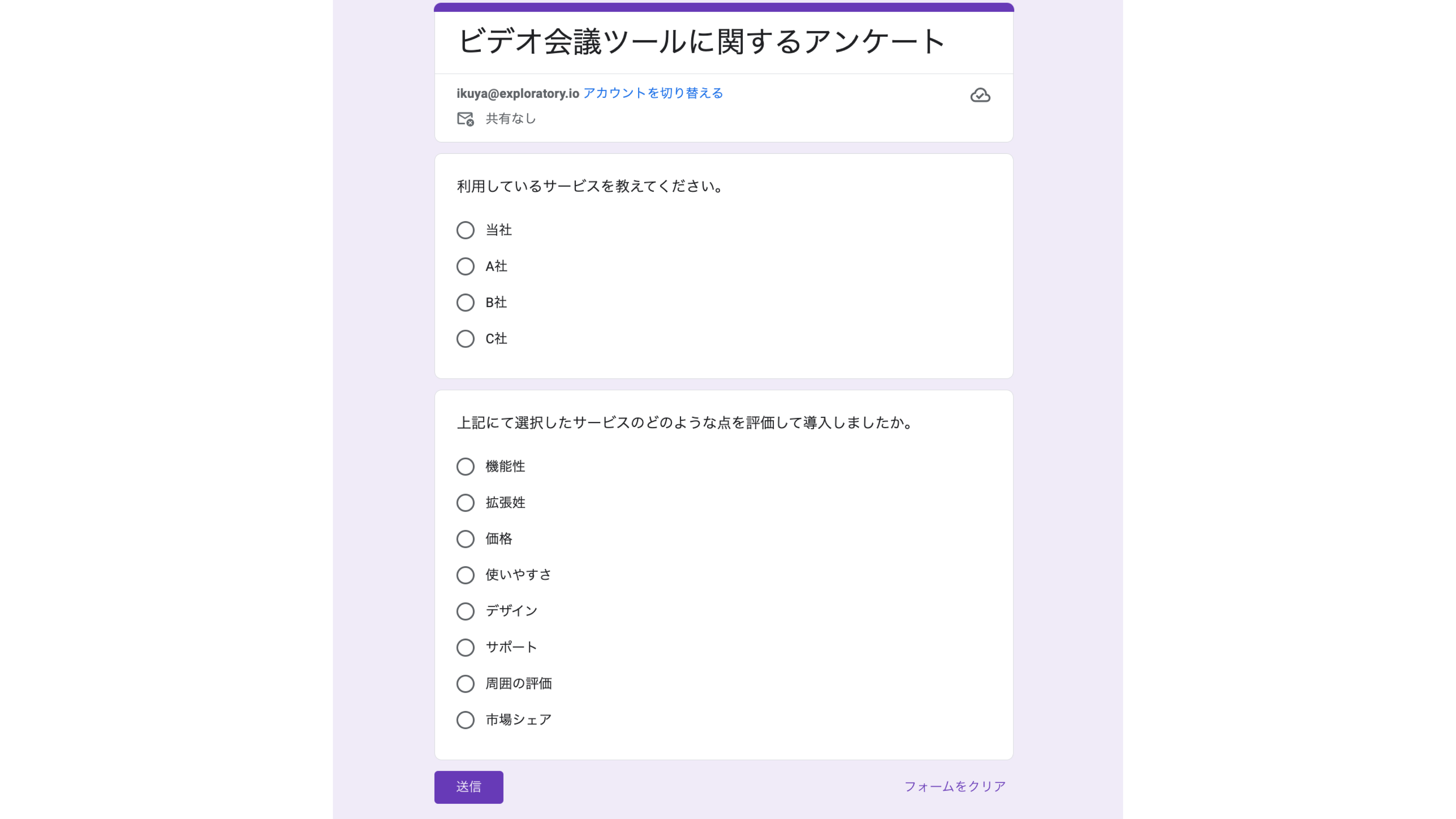
そこで多くの場合、市場調査やアンケートの結果をもとに、どういったところに自社や競合の回答が集中しているかを調べることになります。
例えば、以下のチャートは上記のアンケートの集計結果ですが、自社の「拡張性」「機能性」を評価されていることや、競合Bと似た評価をされていることがわかります。
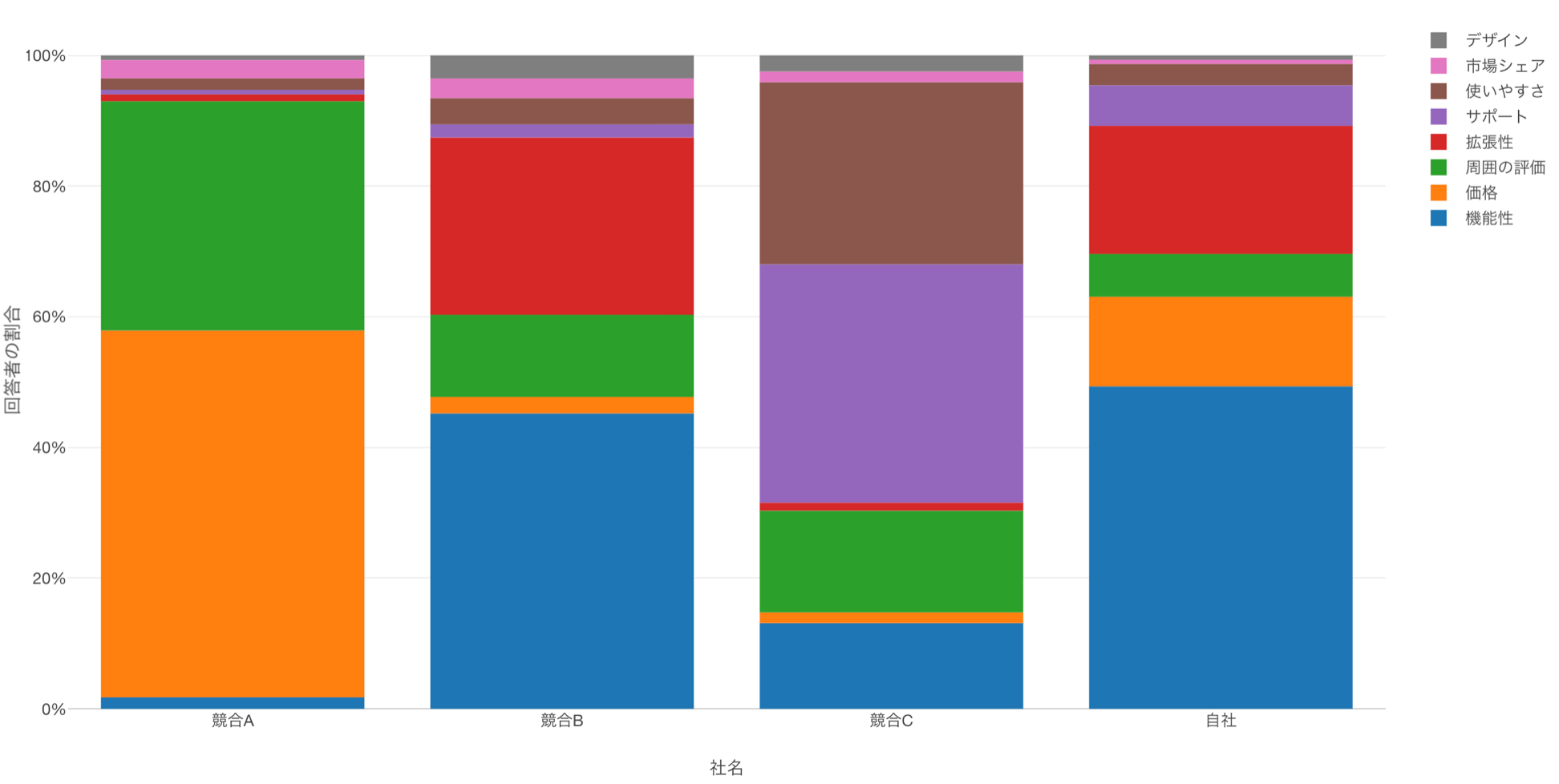
このような集計結果をもとに、自分達の発信しているマーケティングのメッセージが市場での受け取られ方と一致しているかを調べたり、競合Bに対して「拡張性」や「機能性」の観点で優位性を打ち出すようなメッセージを発信できるているのかを確認して、発信するメッセージを最適化することが可能です。
一方で、以下のように回答の選択肢が増えると、先程と同じように直感的に回答の特徴は把握しづらくなります。
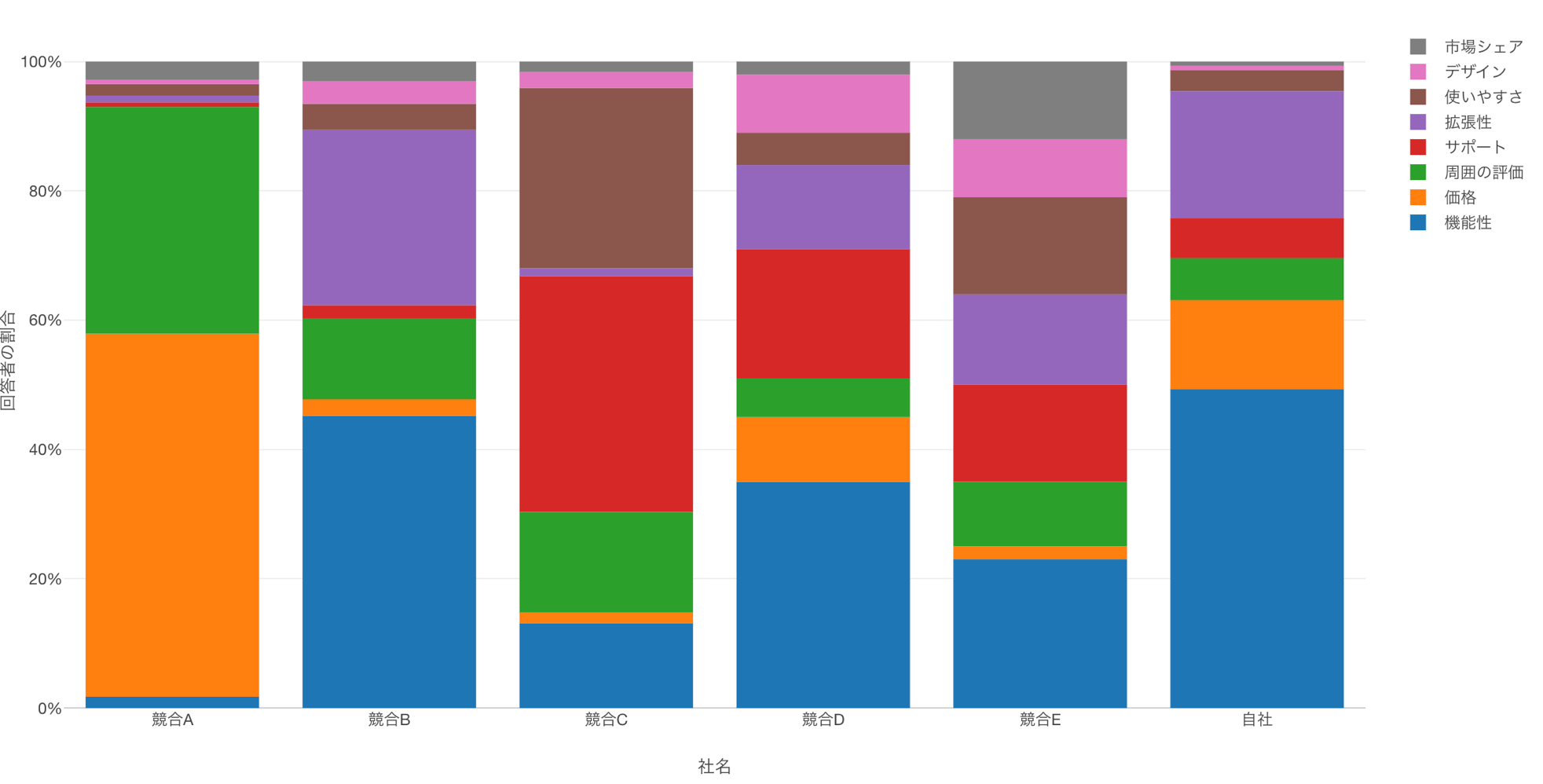
そこで、「対応(コレスポンデンス)分析」を行うと、こういった質問の項目間の関係や、競合他者との関係をより直感的に解釈することが可能になります。
対応(コレスポンデンス)分析ではアンケートなどから得られた各要素(例: 企業名、回答内容)を散布図上に配置します。また下記は、先程紹介したアンケートに対して、対応(コレスポンデンス)分析を実行した結果です。
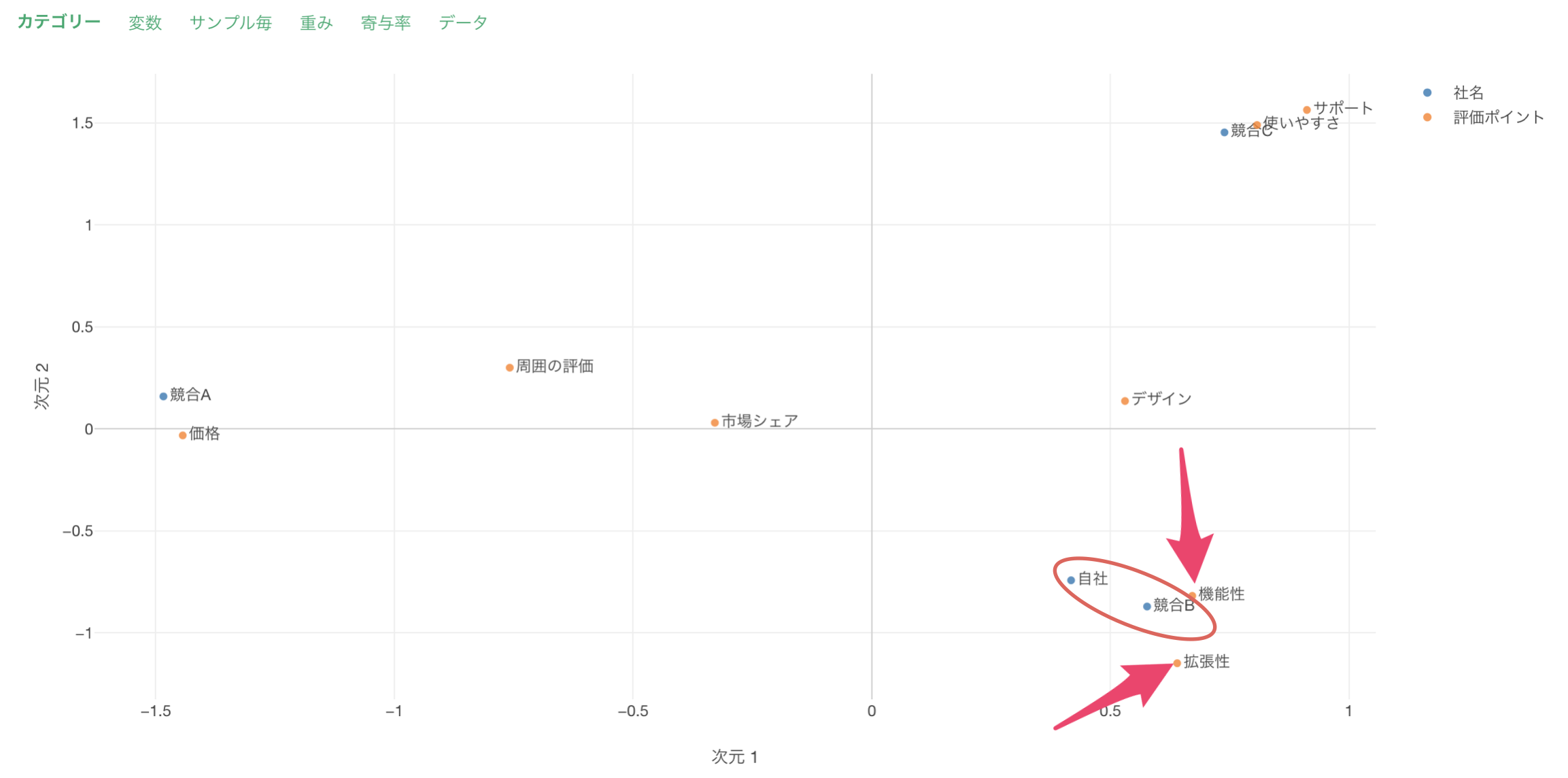
上記の結果から「自社」と「競合B」は近く配置されているため、回答の傾向が似ていることや、「拡張性」や「機能性」を評価されているため、近くに表示されているといったことを直感的に理解することが可能です。
このような結果から、ターゲットとする顧客セグメントが「競合B」と重なっていることを想定でき、競合Bに対して優位性を保てるようなサービスの開発、情報の発信をできているかをチェックして、発信するメッセージを改善できるわけです。
5. 信頼区間・ベイジアンA/Bテスト: 施策の効果を検証する
例えばコンバージョン率の改善のために新しいマーケティング施策の採用を検討するときなどに、2つのパターン(例AとB)を作成し、どちらがより良いのかを試して、最終的にどちらの案を採用するかを決めることはよくやることです。

このとき、例えば、片方のグループに年齢が若い人が集まってしまうと、年齢という別の要素の影響を受け始めてしまいます。
そのため、AとBのどちらがよい良いのかを適切に測りたければ、無作為(ランダム)に分けた2つのグループのコンバージョン率を比べることで、両者の集団が均一になり施策の効果を適切に理解できるようになります。

しかし仮に、「キャンペーン情報を表示させたページの方がコンバージョン率が悪い」という結果が得られ場合、「キャンペーンは失敗」で本当にいいのでしょうか。
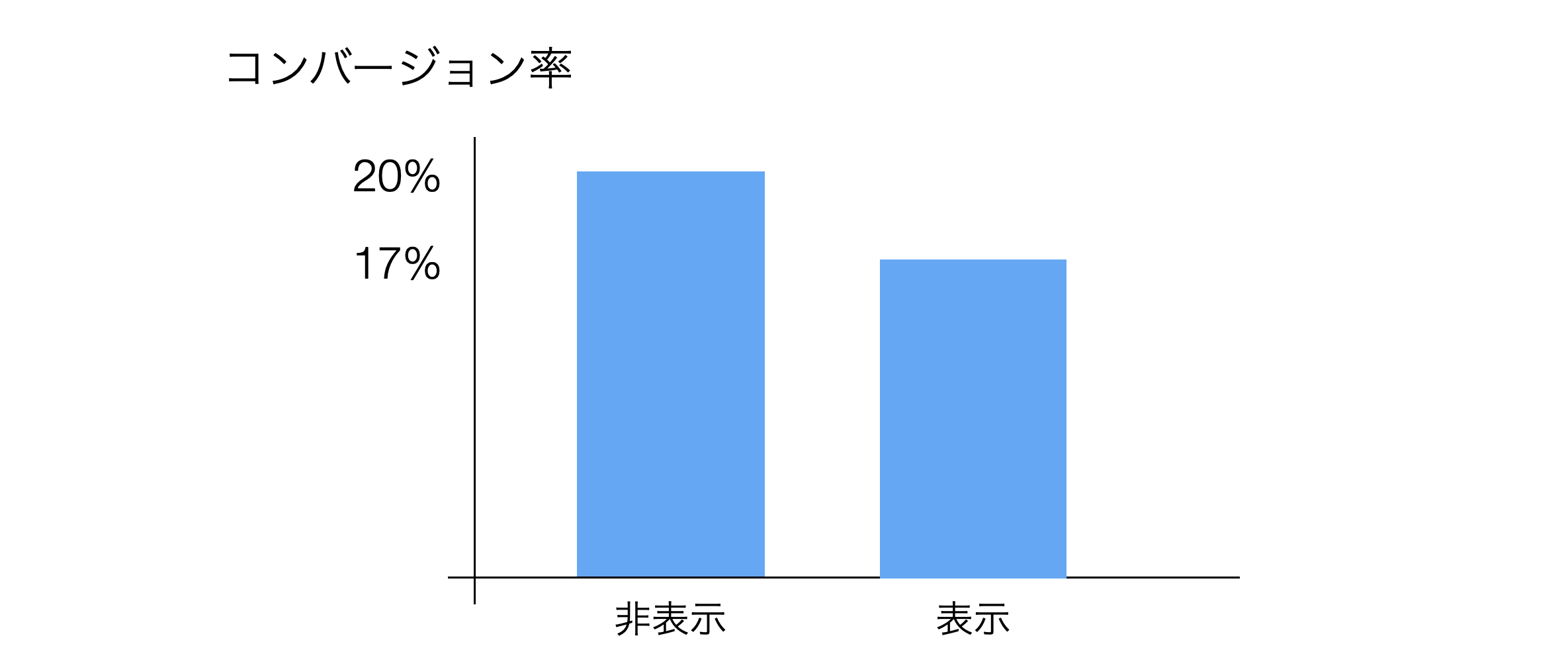
キャンペーン情報を表示しなかったページには300人分のデータがある一方で、キャンペーン情報を表示したページには30人分のデータしかなかった場合、たまたまキャンペーンを表示したページからコンバートした顧客がたまたま少し増えるだけで、コンバージョン率は大きく変動してしまいます。
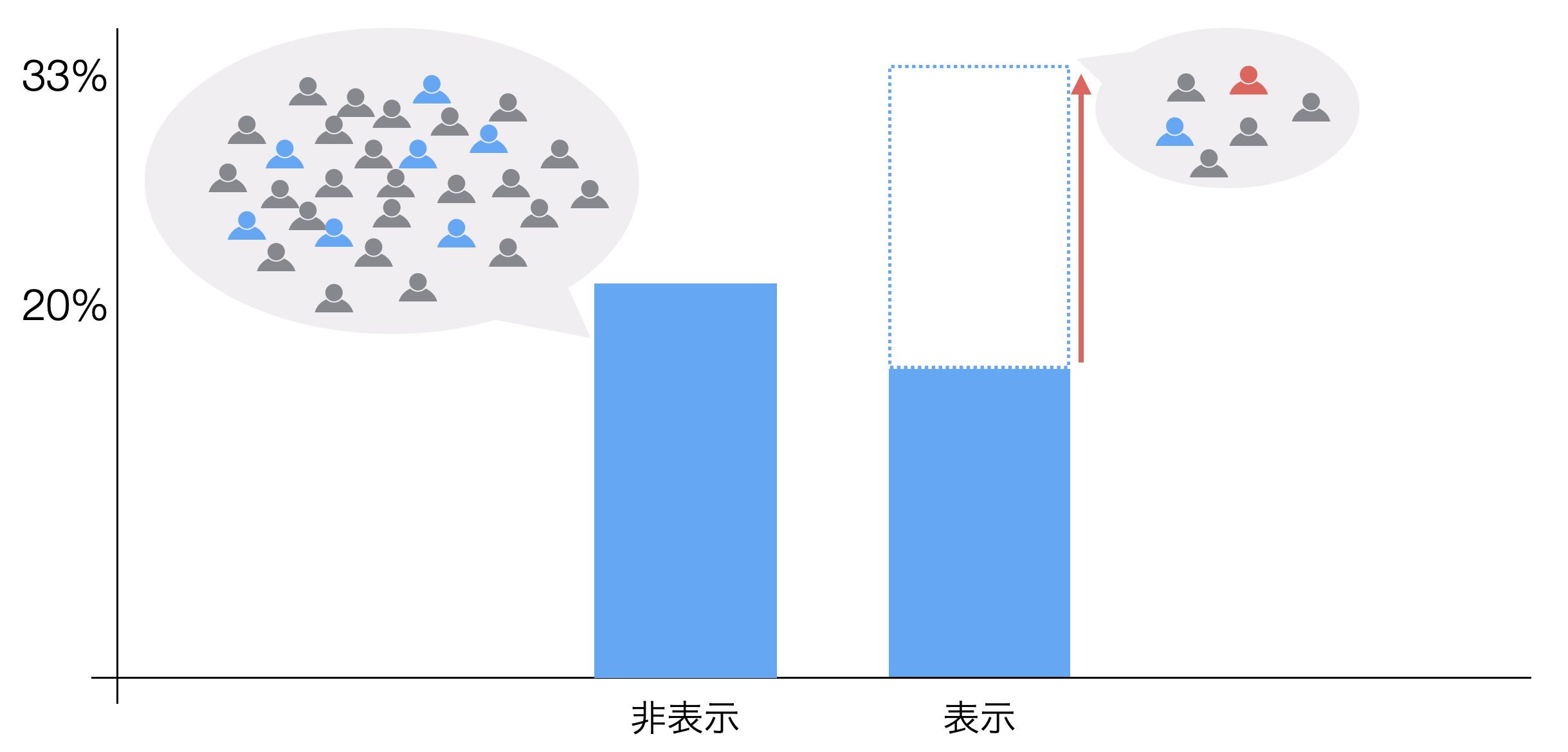
そういったときには、たまたま手元にあるデータだけではなく、そこに無いデータも含めて、同じ性質の顧客であれば、それらの集計値は大抵この間におさまるだろう、と推測される幅がわかれば、両者の間に意味のある差があるのかを理解できるようになります。
この誤差の幅または区間のことを統計学の世界では「信頼区間」と呼びます。
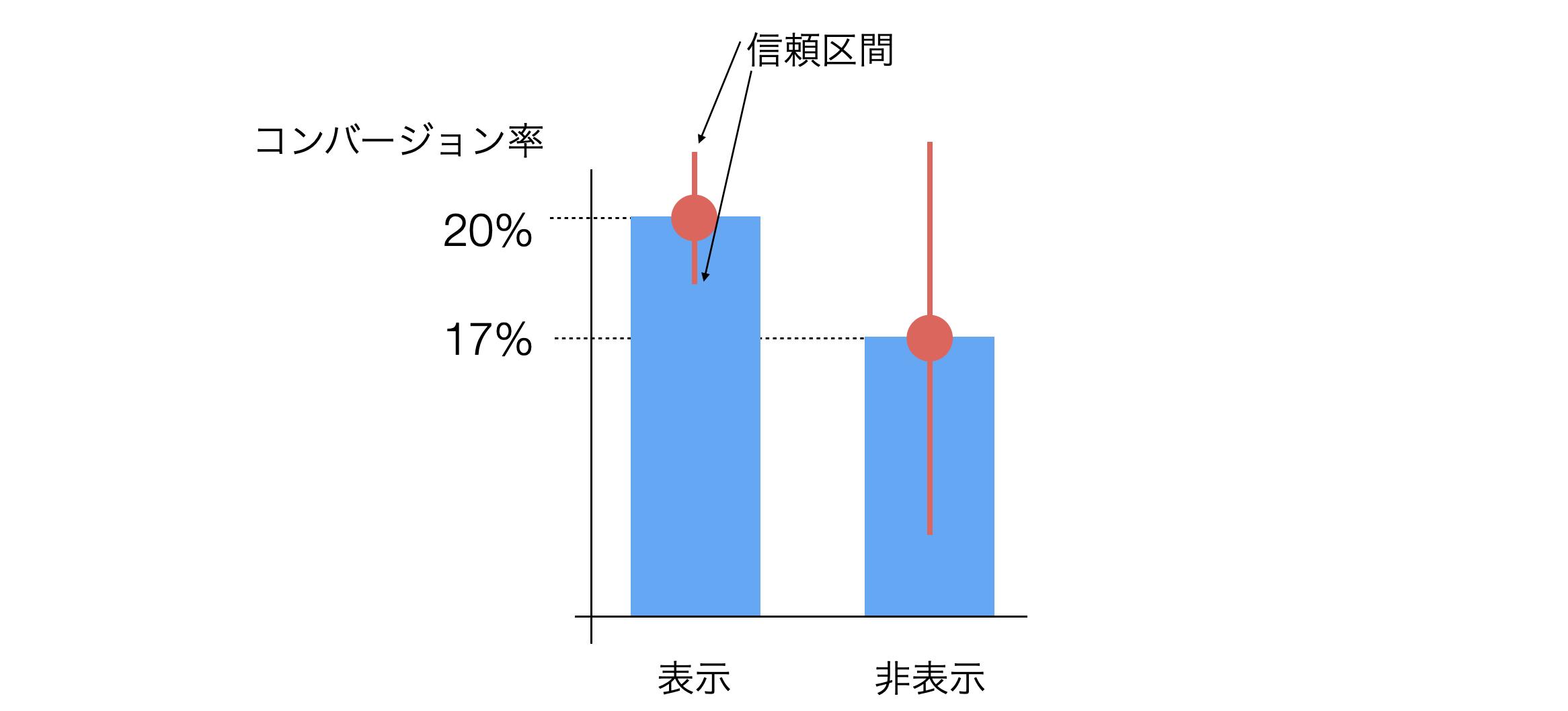
なお、信頼区間にはデータ量が少ないと幅が広くなり、逆に、データ量が増えるほど信頼区間の幅は狭くなるという特徴があります。
また信頼区間が重なっていることからは、「真」のコンバージョン率は同じかもしれないということ、言い換えれば、コンバージョン率に意味のある違いがあるとは言えないことがわかります。
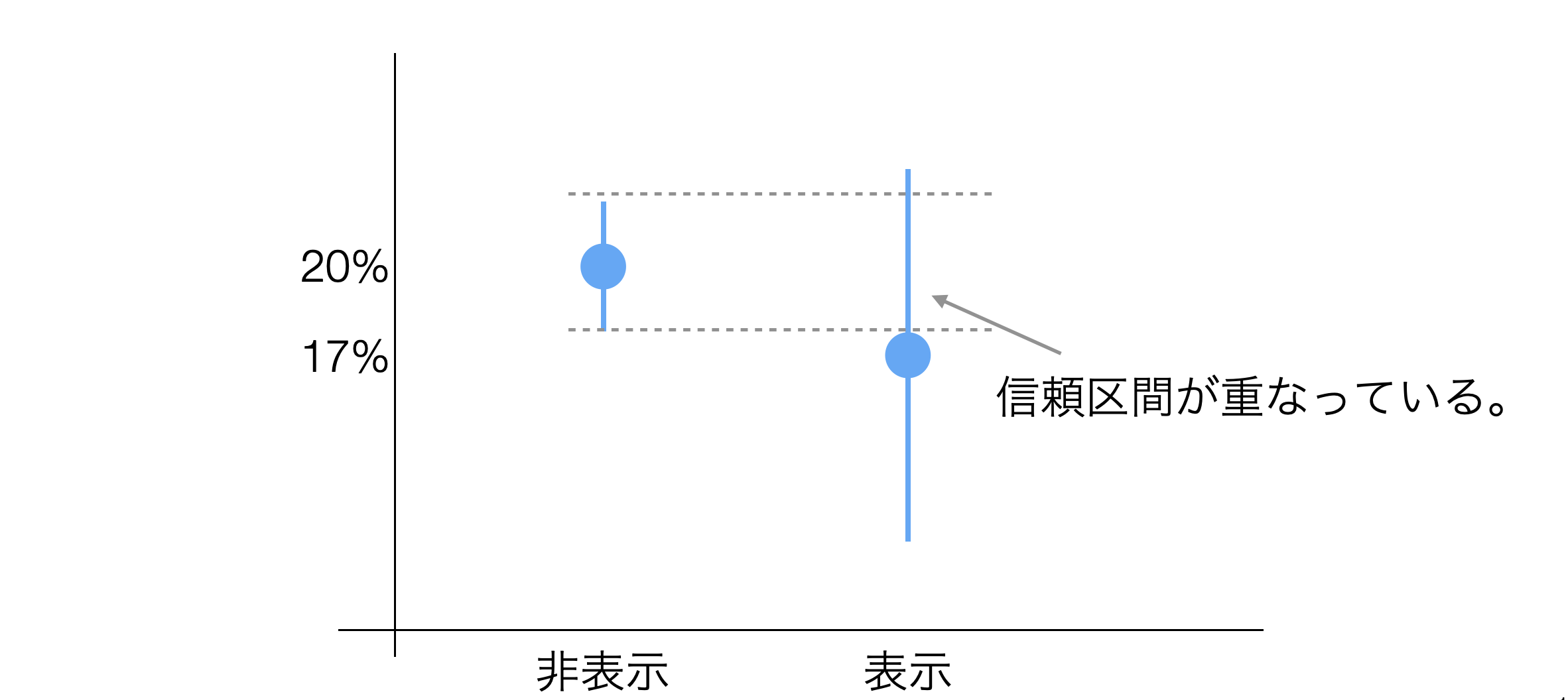
一方で、信頼区間が重なっているときには、キャンペーン前後の「真」のコンバージョン率には違いがあり、キャンペーン実施(表示)した方がコンバージョン率が良いと推定できるわけです。
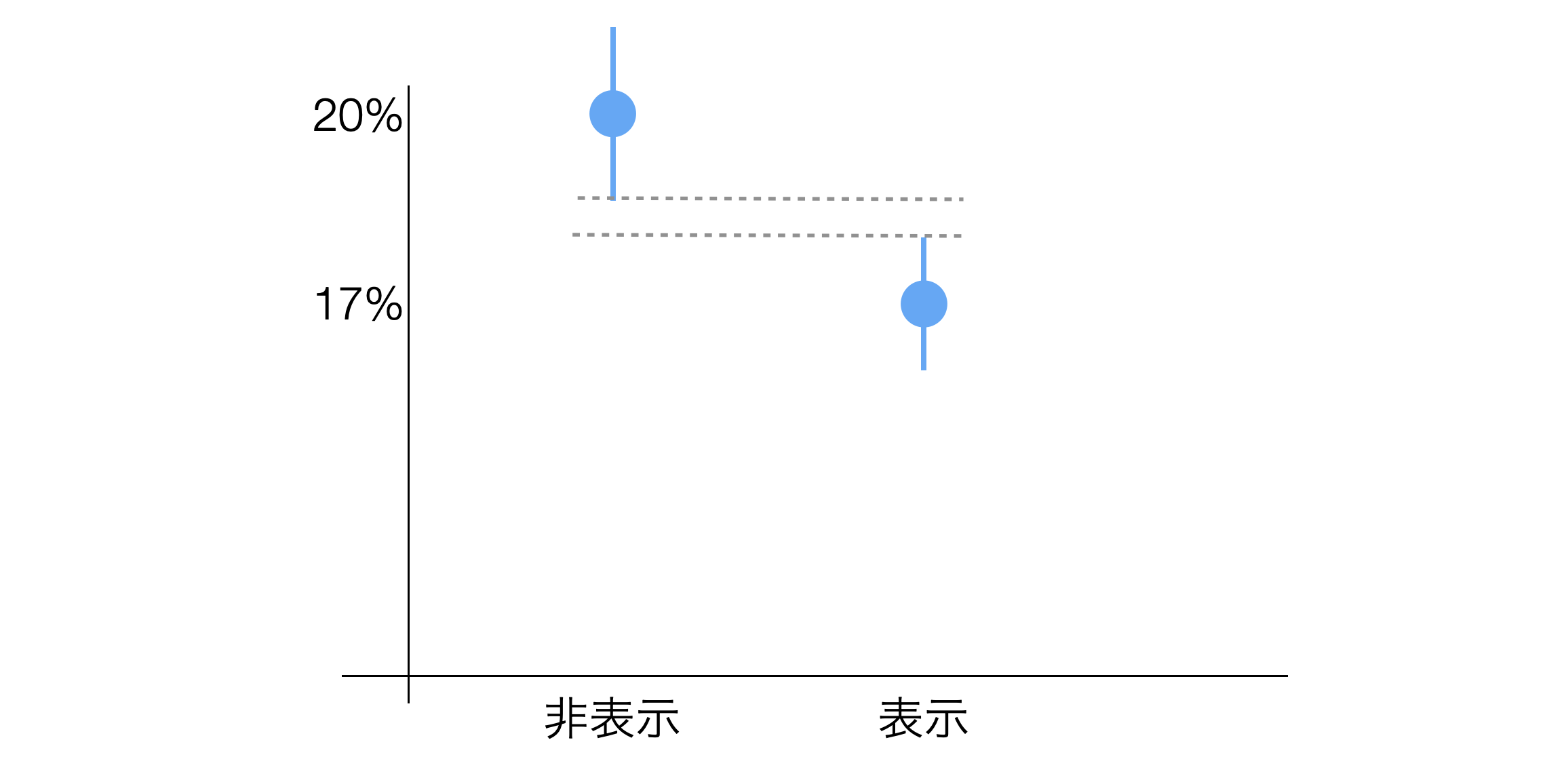
しかしデータ量が少なく信頼区間の幅が広いときにはデータが増えることで、得られる解釈が変わってくることがあるのであれば、いつまでテストを継続してデータを貯めればいいかが分かりません。
もちろん両者の間に意味のある差があると言い切るために必要なデータ量を計算することも可能なのですが、必要なサンプルサイズが集まるまで待てない、あるいは現実的なサイズにならないということもあります。
そういったときには、ある程度おおまかでもいいので、少ないデータでも施策を評価したいわけです。
そのようなときに有効なのが「ベイジアンA/Bテスト」です。
ベイジアンA/Bテストを行うと、そのページにキャンペーンを統一した場合、どの程度の確率で改善するのかを計算することが可能なため、少ないデータでも施策を適切に評価することができるようになります。

結果として、効果の高いキャンペーンに早いタイミングで寄せることができ、結果としてマーケティングの効率を高められるのです。
もっと知りたい、やり方を学びたい!
今回は、マーケティング担当者が使いこなせるようになるべき5つの分析手法を紹介しました。
いずれも有名な分析な手法ですが、実際に自分自身の力でこれらの分析をスピーディーに実行できるマーケティング担当者は多くはないようです。
そこで、今回紹介した分析手法についてもっと詳細を知りたい、さらに自分でもできるようになりたいという方は、この12月にデータドリブンなマーケティング活動を行うために必要なデータサイエンスの手法の習得に特化したトレーニングを開催いたしますので、そちらへのご参加をご検討いただければと思います!
自分のデータで試してみたい!
記事内の分析には、データの加工、可視化、分析、レポーティングのためのUIツールのExploratoryを利用しています。
ご自身のデータを使って、データの分析をしたい方は、下記のリンクより無料トライアルが可能ですので、是非、お試しください!