自由記述アンケートのテキスト分析 Part 2:よく一緒に使われる単語の組み合わせの集計と可視化
どうも!ExploratoryのIkuyaです。
前回は自由記述のアンケートのテキストを分析するために、文章を単語化して、ワードクラウドで可視化する方法を紹介しました。

- Part1:文章の単語化とワードクラウド - Link
このワードクラウドは、どのような単語が多く出現するかを直感的に理解することには向いていますが、一方でどのような文脈で各々の単語が使われているかが分かりづらいといったことがあります。
そこで本日は文章の中で使われている単語の組み合わせを集計して、自由記述のアンケートを分析する方法を紹介します。
自由記述のテキストを分析するステップ
今回はExploratoryを使って、以下の3ステップに沿って説明していきます。
- 文章を単語化する
- 単語の組合わせをカウントする
- 単語の組み合わせを可視化する
1. 文章を単語化する

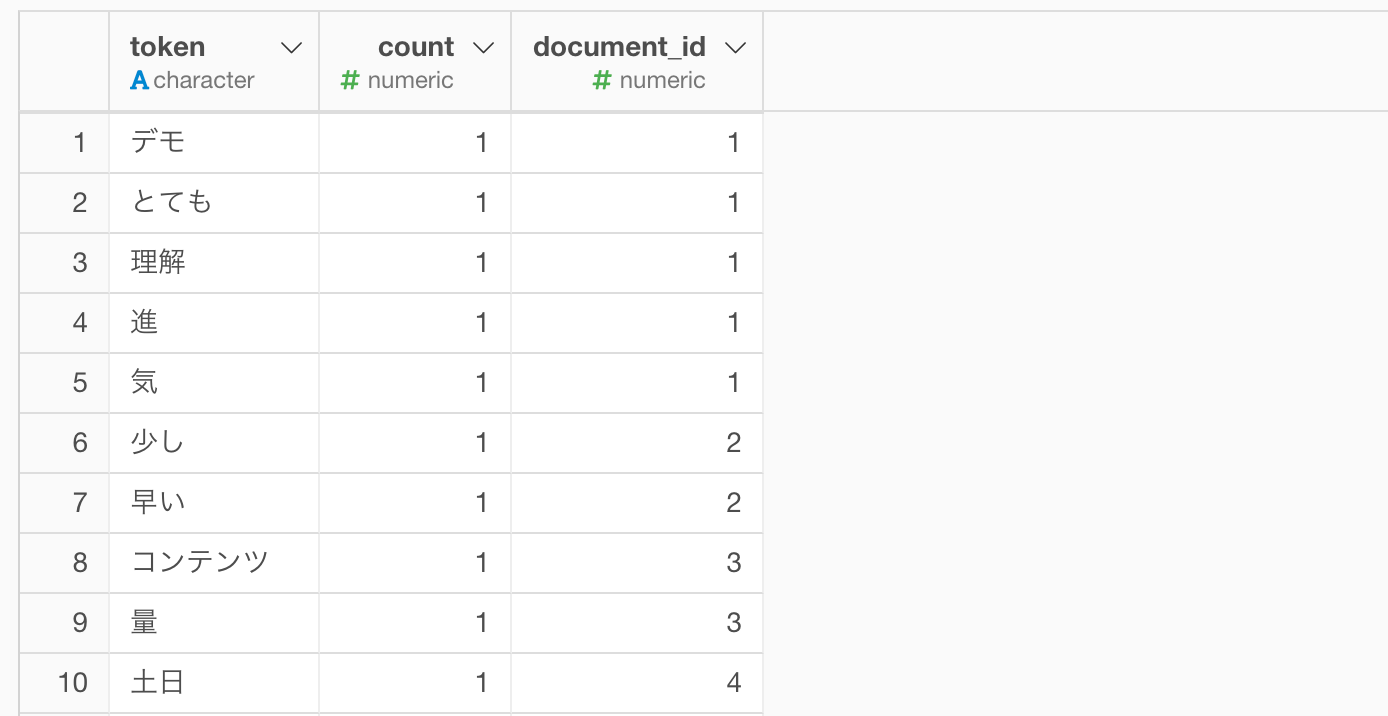
今回は上記のようなアンケートのデータを下記のように単語化しておいたデータを利用していきます。(文章を単語化する方法についてはこちらをご参考ください。)
2. 単語の組み合わせをカウントする
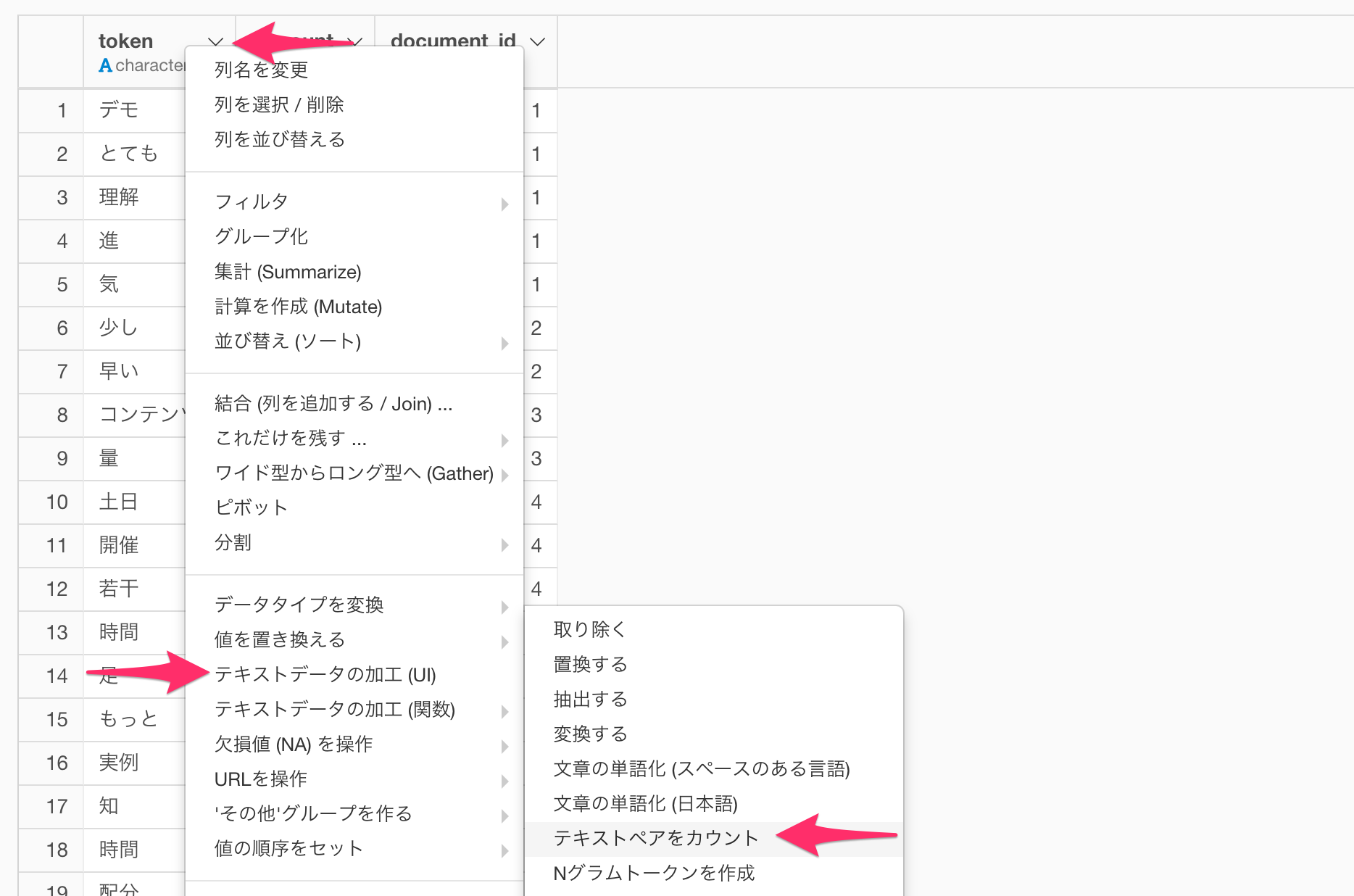
今回のデータでは文章がすでに単語化されているので、早速、単語の組み合わせを集計していきます。「token」の列ヘッダーメニューから、「テキストデータの加工(UI)」、「テキストペアをカウント」を選択します。
すると、「テキストペアをカウント」ダイアログが表示されるので、そのまま実行します。
なお「文書IDの列」には文章ごとにユニークなIDを選択します。今回はすでに文章ごとにユニークなIDである「document_id」が選択されているので、デフォルトのまま実行します。
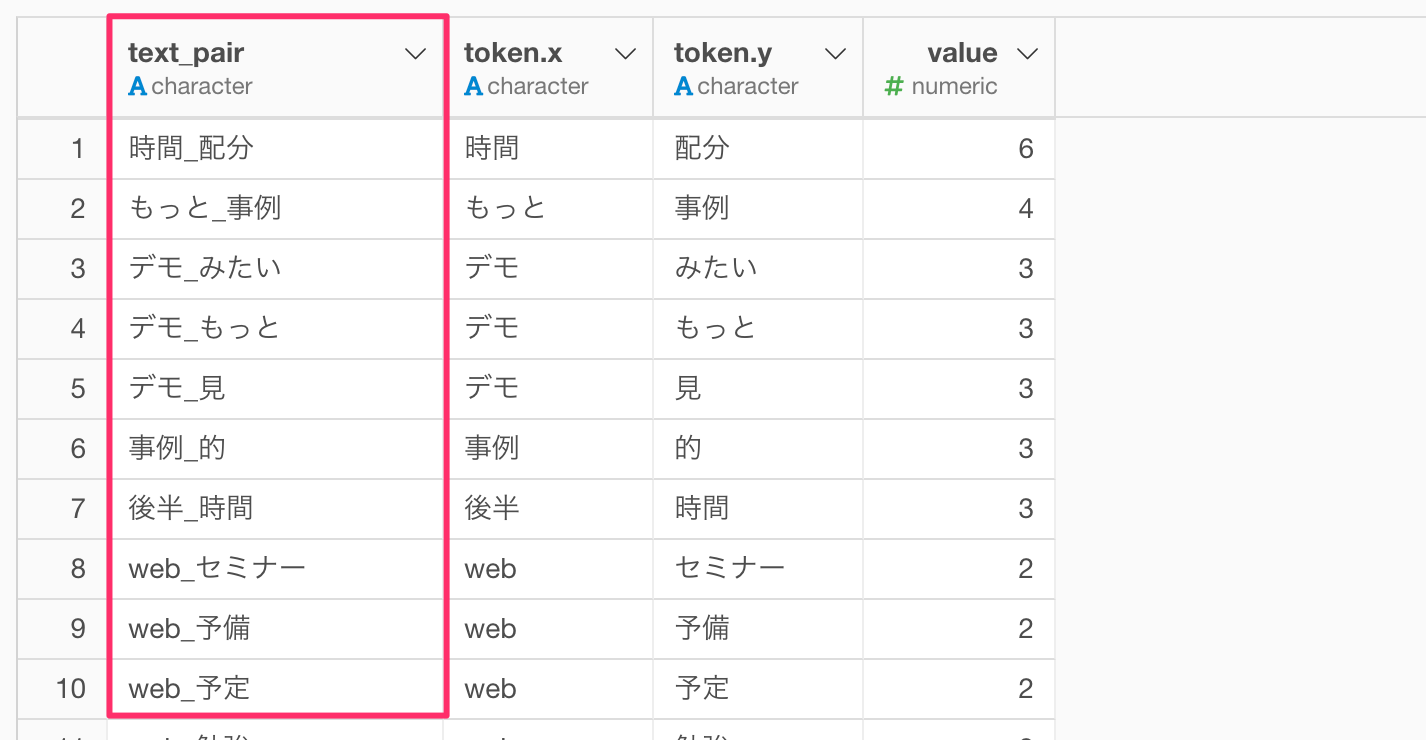
それぞれの単語の組み合わせの回数を列として作ることができました。
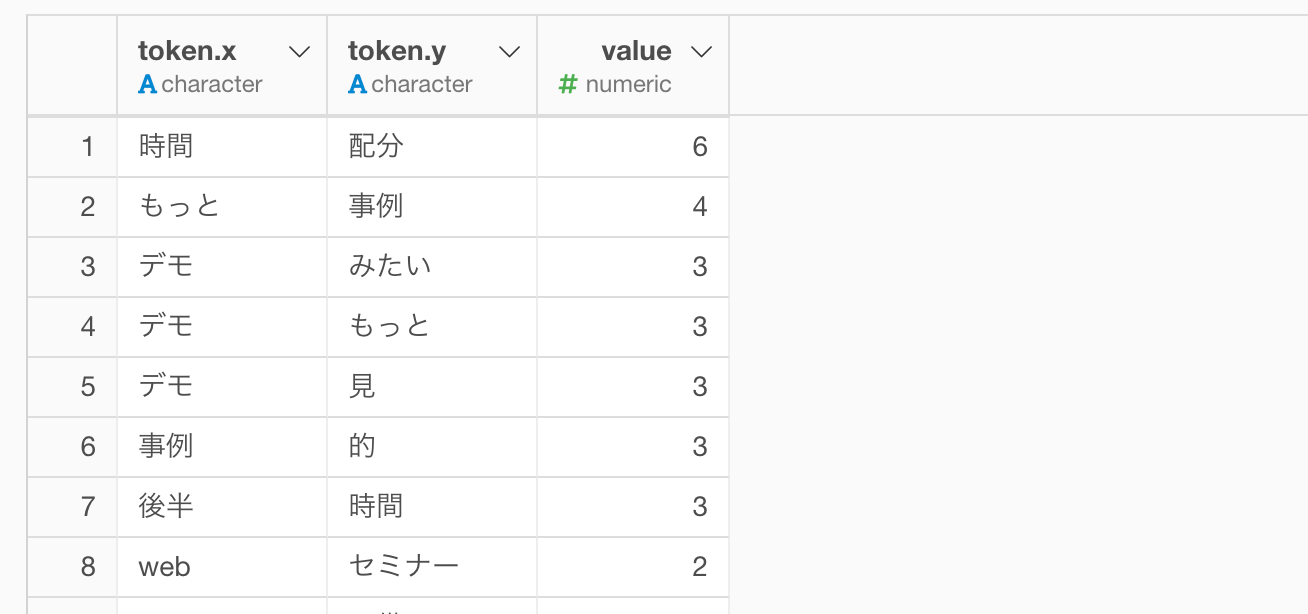
ただ残念ながら単語のペアが別々の列に分かれているため、このままでは可視化がしづらいということがあります。そこで可視化がしやすいように単語のペアを一列にまとめていきます。
一つ目の単語である「token.x」列と二つ目の単語である「token.y」列を選択したら、列ヘッダーメニューから「複数の列をつなげる(Unite)」を選択します。
すると「複数の列をつなげる(Unite)」ダイアログが表示されるので、新しい列名を「text_pair」として実行します。
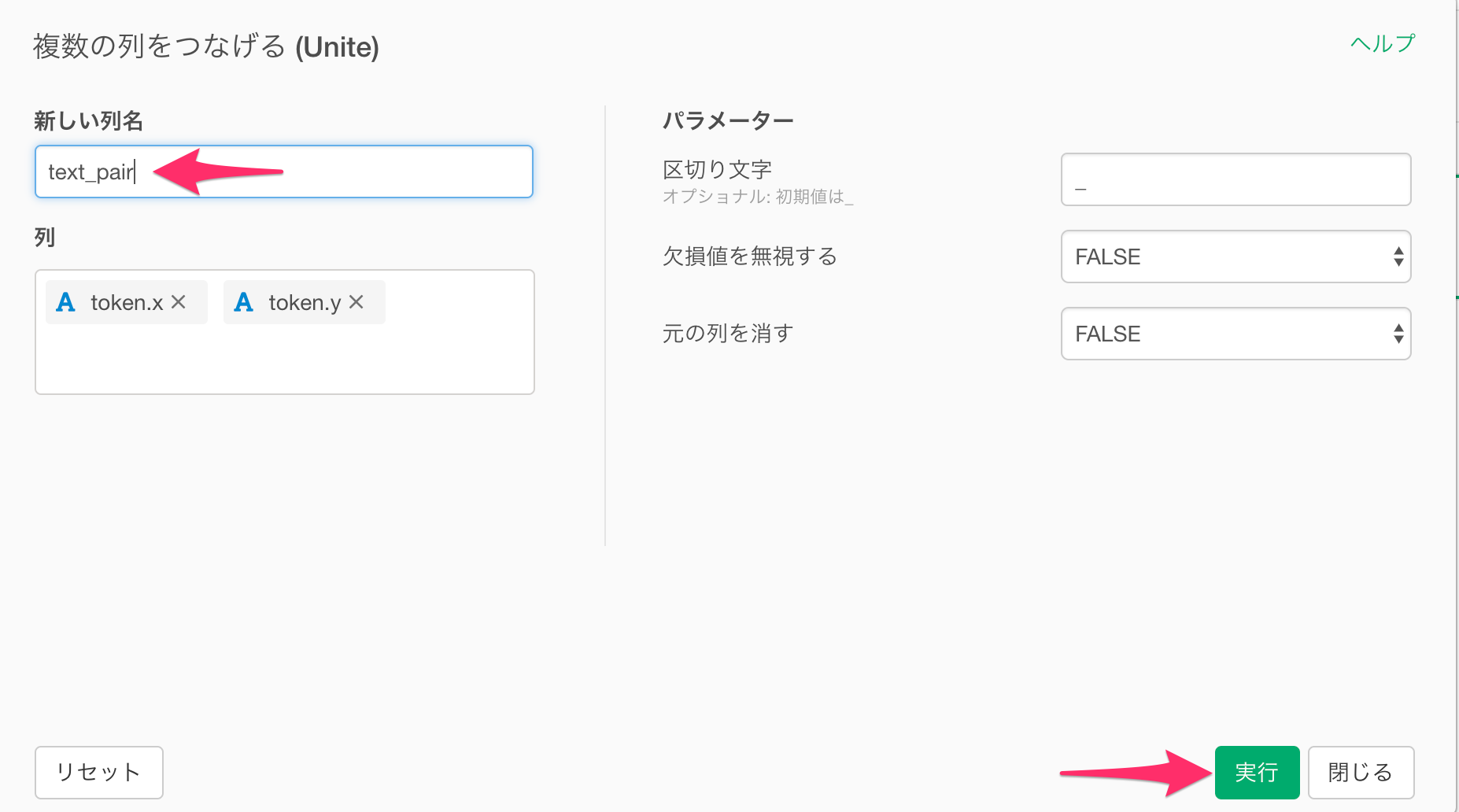
無事、単語のペアを一列にまとめるこができました。
3. 単語の組み合わせを可視化する
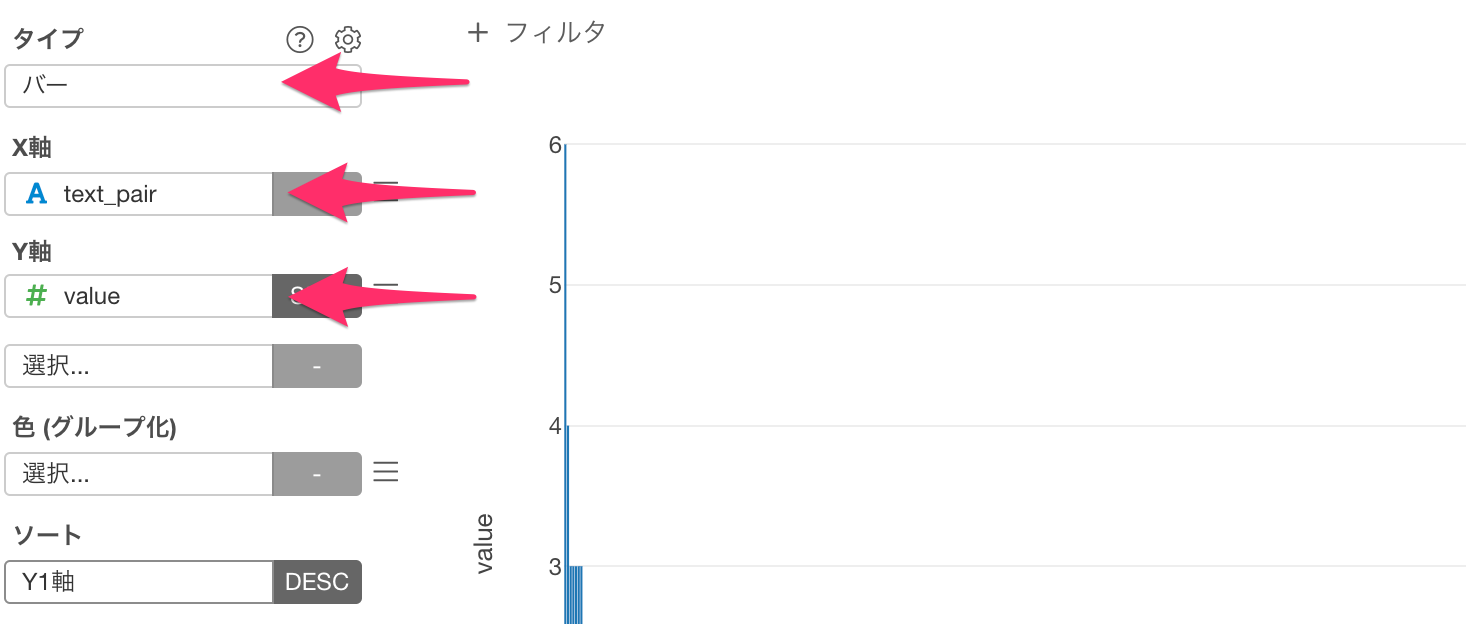
最後に単語のペアの出現数を可視化していきます。チャートビューに移動したら、チャートのタイプに「バー」、X軸に「text_pair」、Y軸に「value」を選択します。
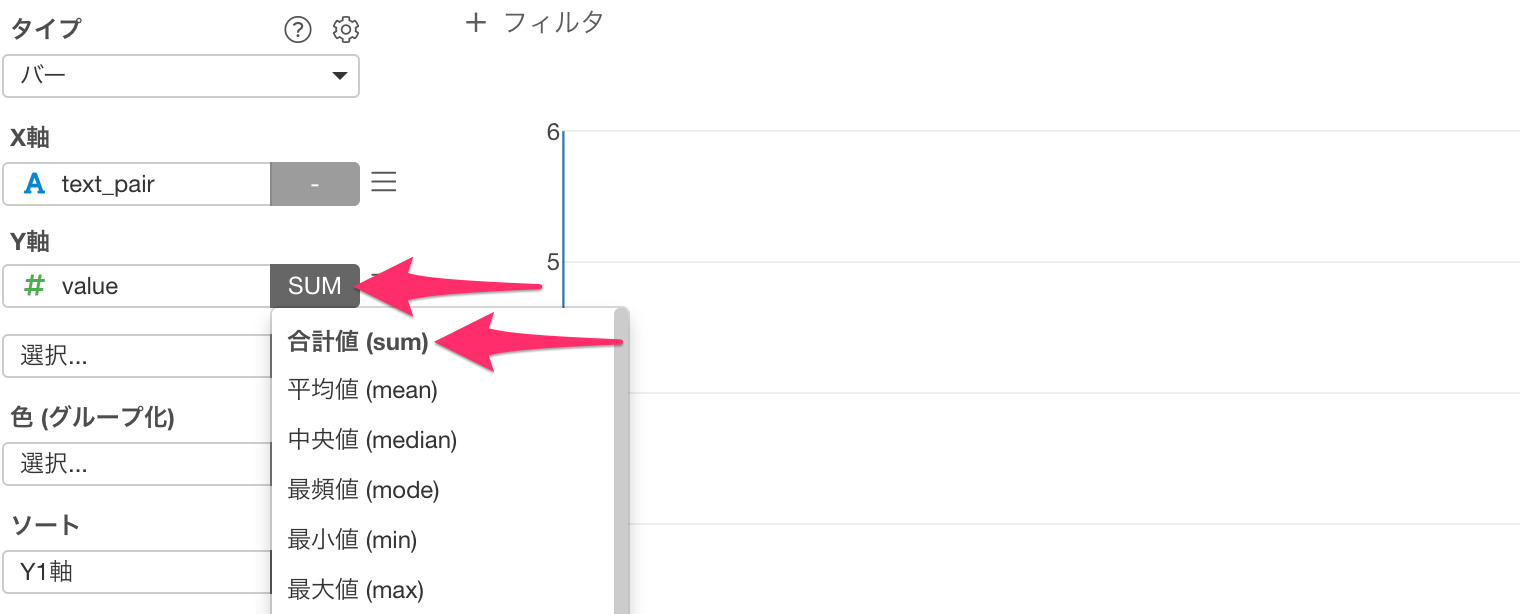
続いてY軸の集計関数に「合計値(sum)」を選択します。
最後にソートに「Y1軸」を選択します。
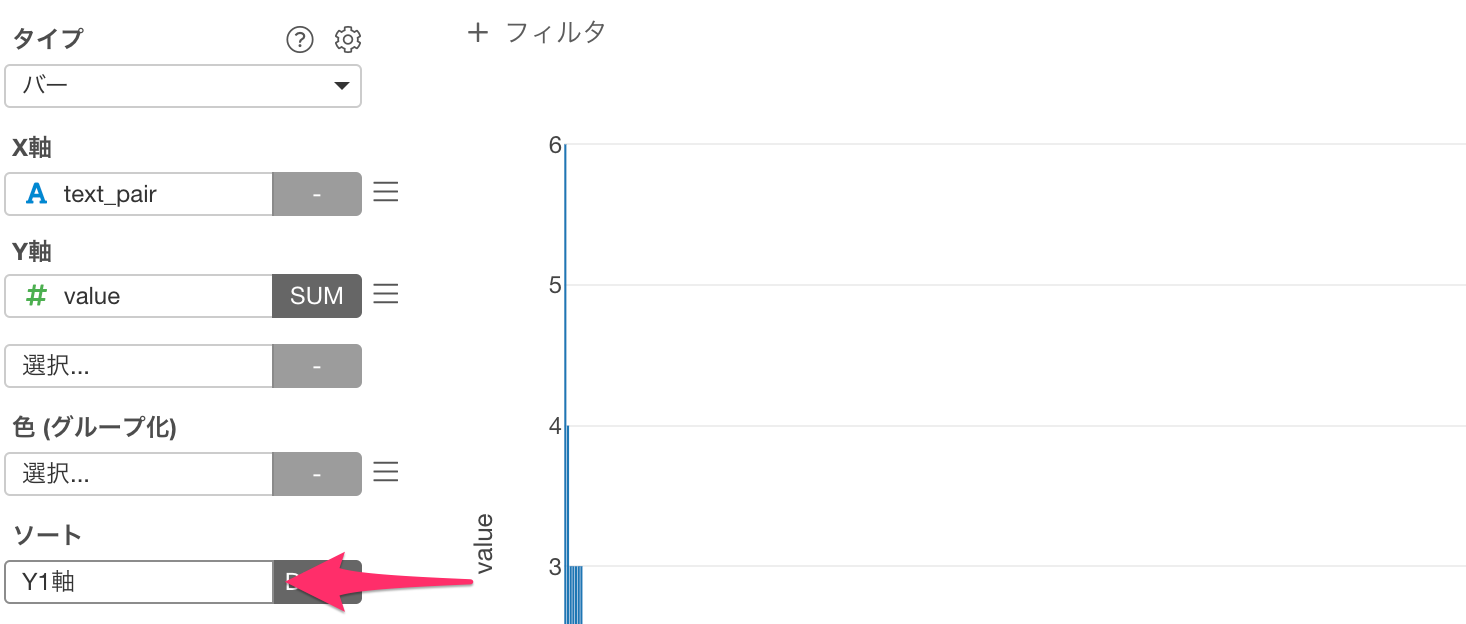
これで単語のペアを出現回数の多い順に可視化できました。
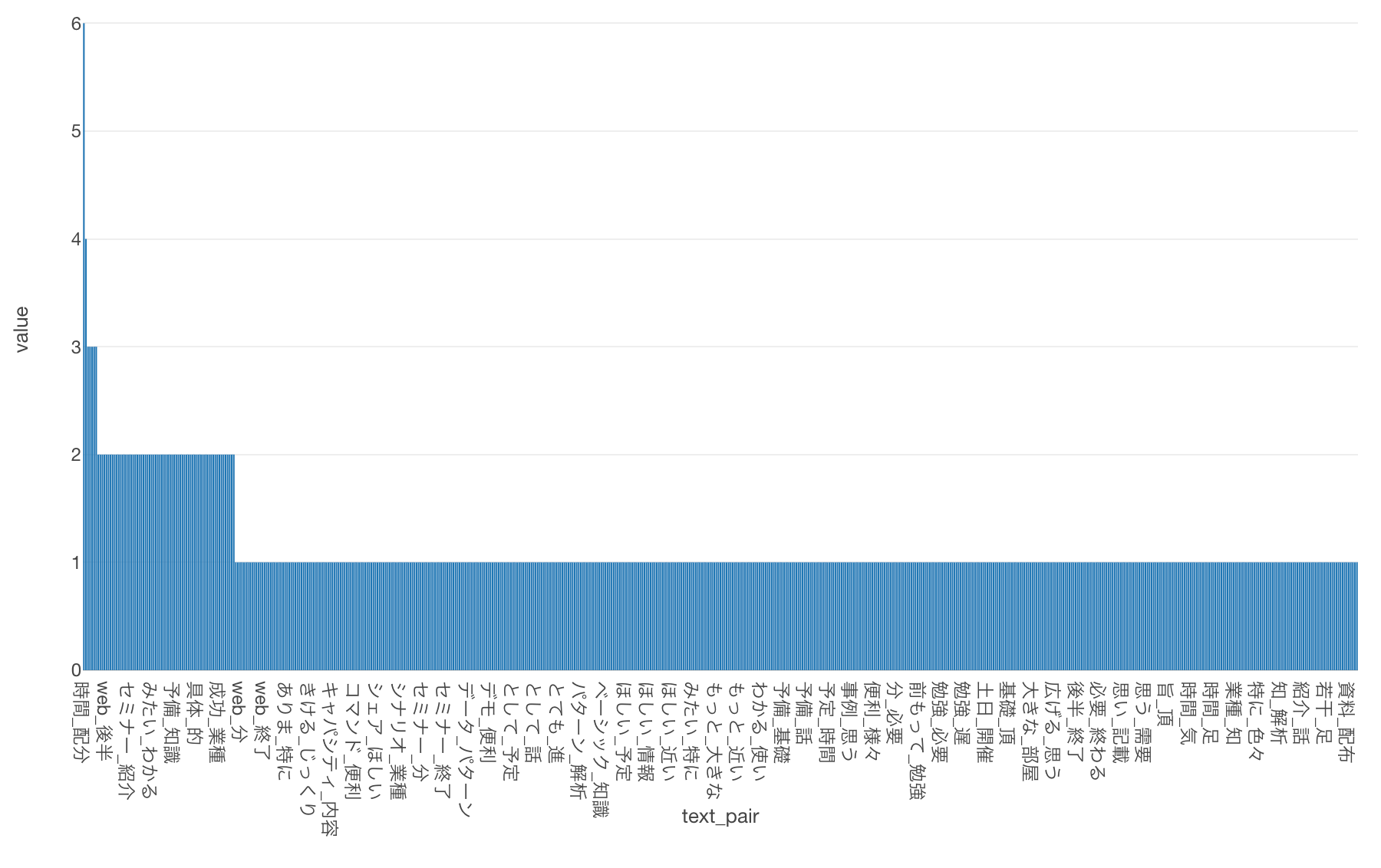
ただし、今のままだと単語のペアがあまりにも多く見づらくなってしまっています。さらに1回しか出現しない単語のペアも多くなっています。1回しか出現しないペアはたまたま使われた組み合わせの可能性が高いので、今回は3回以上出現した単語のペアに絞っていきます。
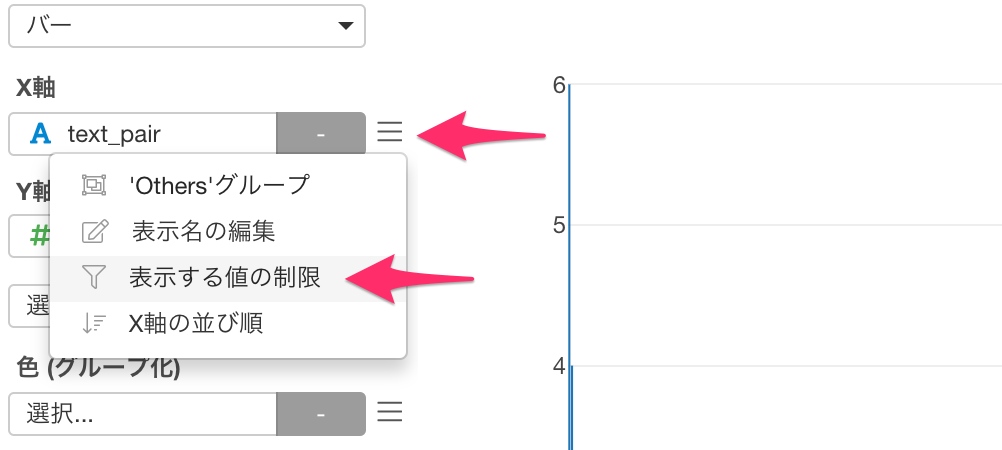
先ほどのチャートのX軸メニューより「表示する値の制限」を選択します。
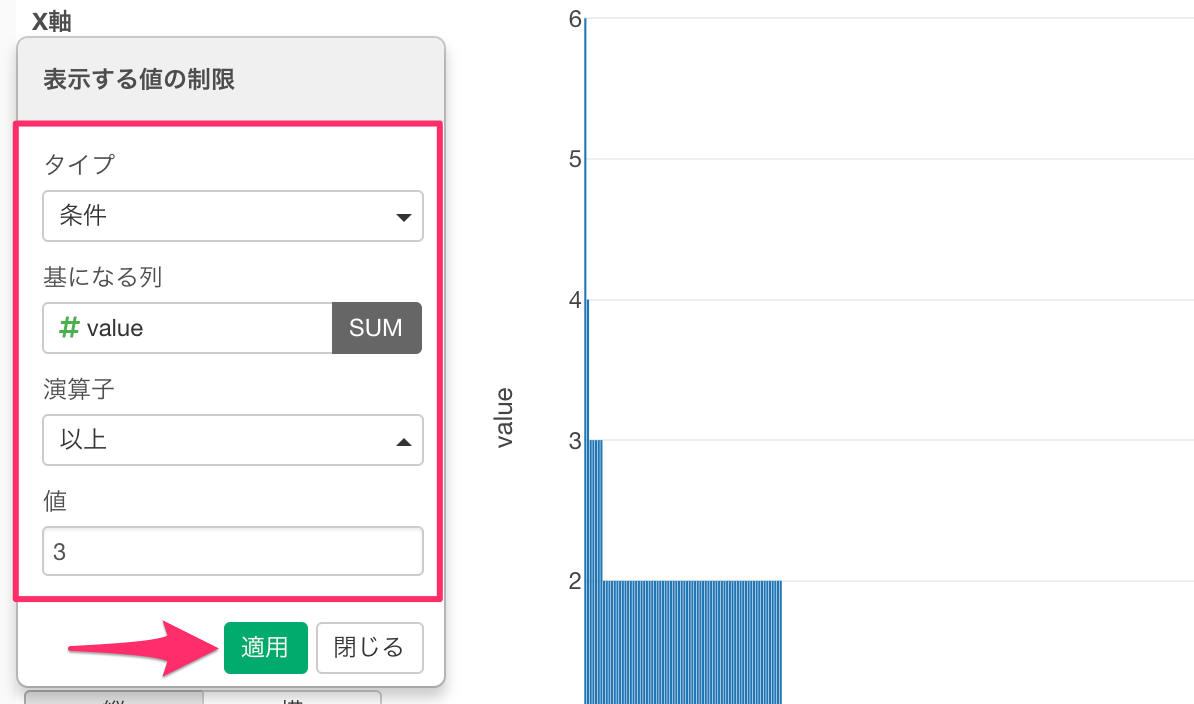
続いてタイプを「条件」、基になる列を「value」、演算子を「以上」、値に「3」と入力し、適用します。
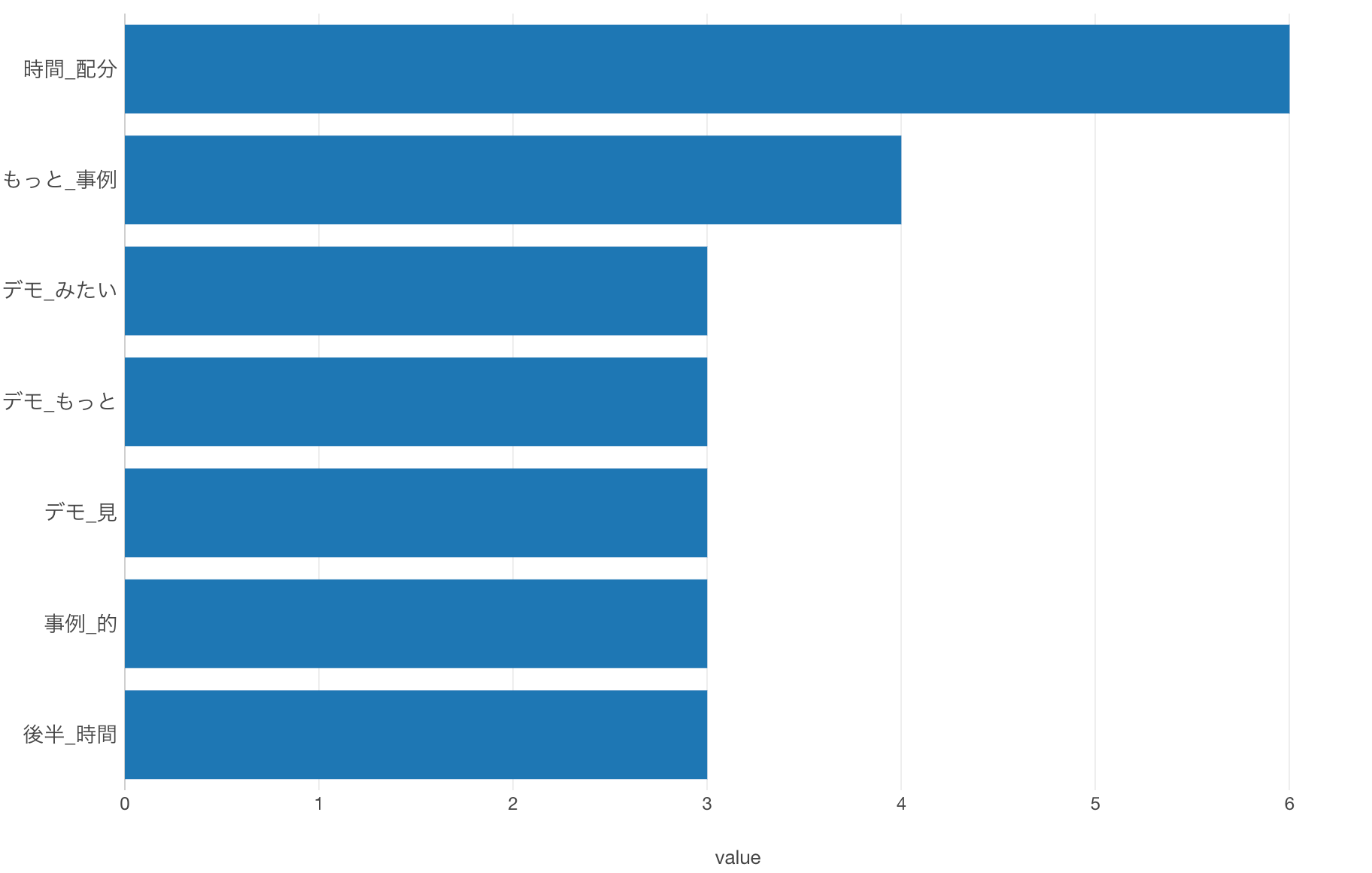
すると3回以上、出現した単語の組み合わせが表示され「時間_配分」や「もっと_事例」、「デモ_みたい」といった組み合わせが多いことが分かりました。
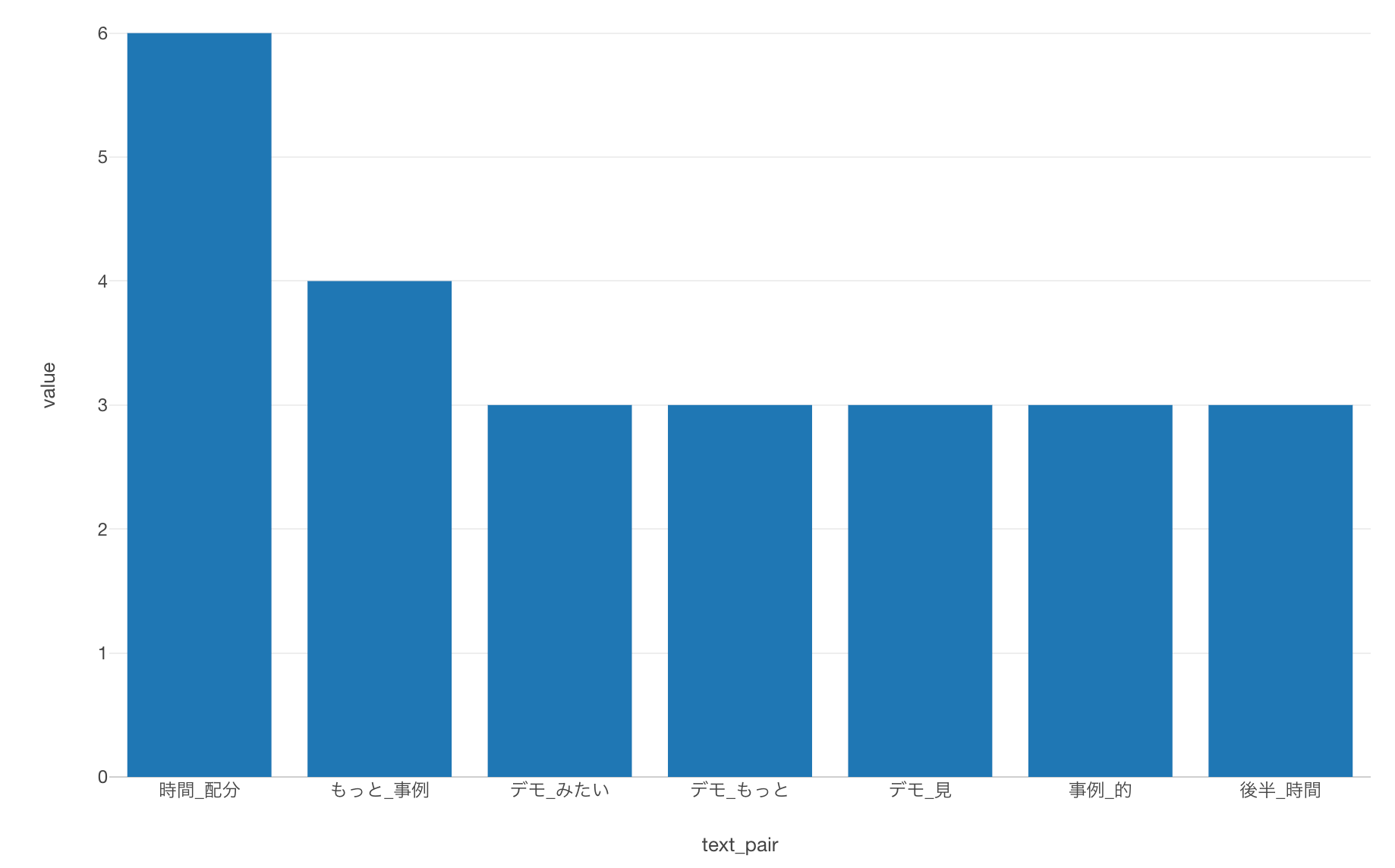
このように単語の組み合わせを集計し、さらに可視化することで、セミナーの「時間の配分」を改善したり、「もっとデモ」を増やしたりしたほうがいいのではないかというインサイトを得ることができました。
自分のデータで実際に試してみる
Exploratoryでは30日間、無料でトライアルができます。実際に自分達のデータを使って試してみたい方は下記より無料トライアルをご利用ください!