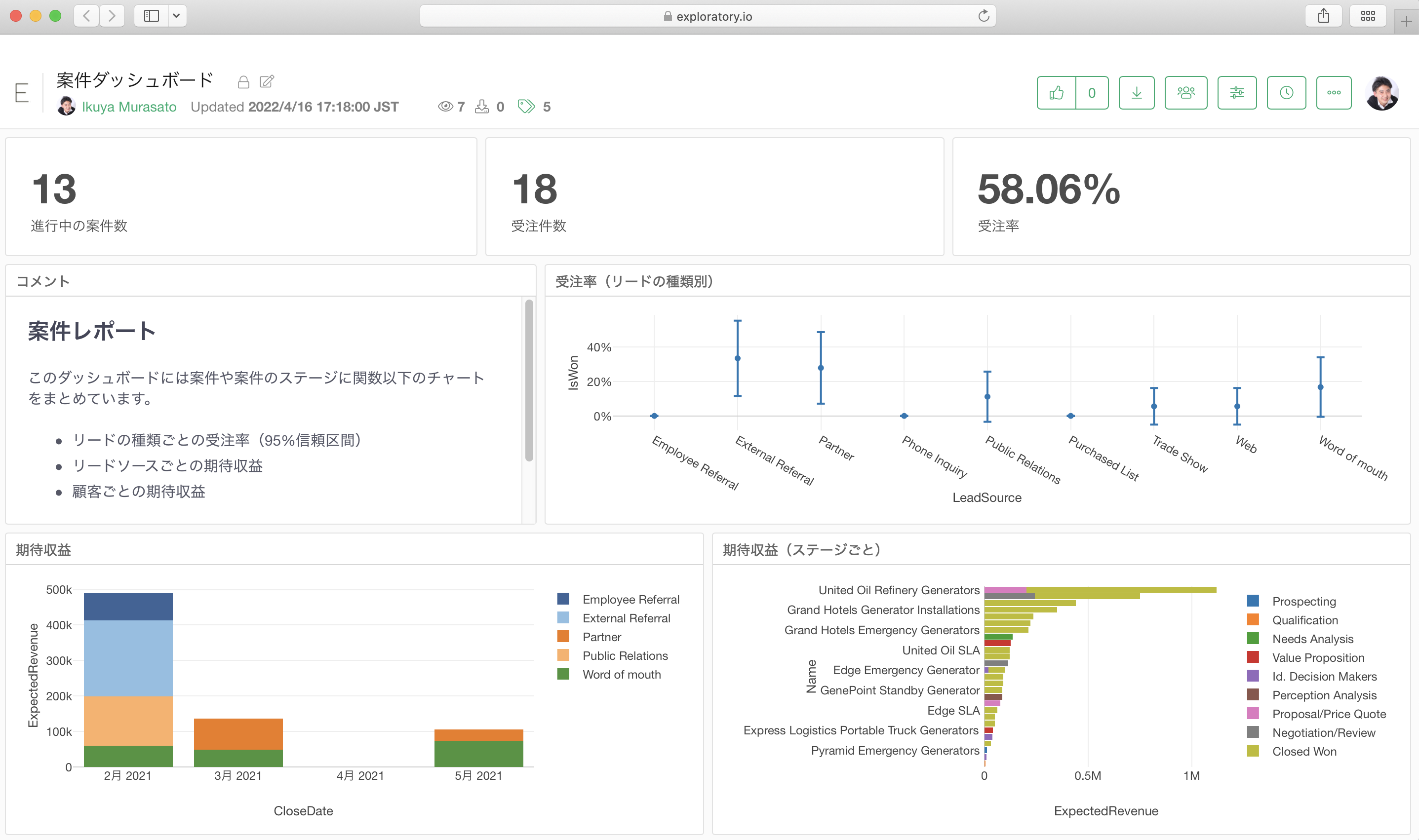
ビジネスの現状を把握し、さらにモニターし続けるためにダッシュボードなどを使ったBI(ビジネス・インテリジェンス)の仕組みを社内に導入したものの、社内ではあまり活用されていない、またはプロジェクトが途中で終わってしまったといった話をよく聞きます。
そこで、こちらの記事ではBI導入やダッシュボード作成プロジェクトを進めるときにぶつかることの多い問題、さらには、そうした問題を乗り越えてプロジェクトを成功に導くための5つのポイントを紹介します。
1. データの加工
ダッシュボードの作成プロジェクトに関わるタスクを考えると、真っ先に思い浮かぶのは、ダッシュボードに、どのようなチャートを入れるのかや、そのレイアウトをどうするかといったことです。
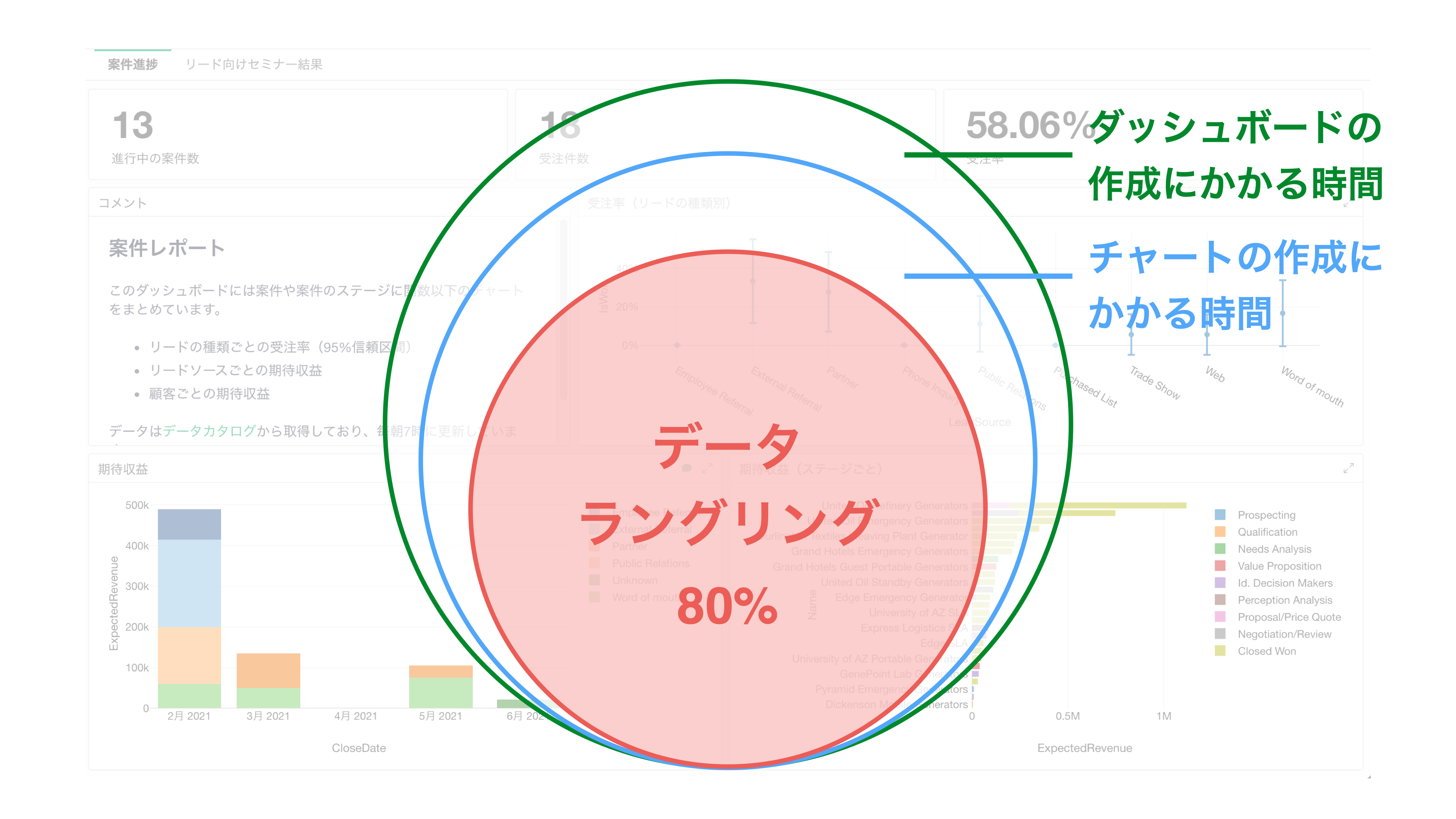
しかし、ダッシュボードの作成に関わるタスクを紐解くと、ほとんどの業務はダッシュボードに入れるチャートの作成にかかる時間ということになります。また、チャートの作成に関わるタスクを分解すると、「データラングリング」と呼ばれるデータの加工に関する作業が大半を占めることになります。
このように考えると、ダッシュボード/BIプロジェクトに関するタスクの大半は、データラングリングのタスクと言うことができるわけです。
データを思うように加工できないことの問題
そこで多くの方が「可視化のためのデータの加工」から始めることになりますが、いざデータを加工しようと思うと、データが汚かったり、自分達では対応できない複雑なデータ加工が求められ、作りたいチャートの作成を諦めてしまい、基本的な指標の可視化にとどまり、誰の役にも立たないダッシュボードができあがってしまうこともあるようです。
一方で、そのような問題を解決するために、外部の会社からのサポートを得ることもできますが、初期コストや見たい指標やチャートが変わってきたときのメンテナンスコストの問題が生じるため、なかなかうまくいかないこともあるようです。
そういった意味においても、自分達で思うような形にデータを加工できることがBI/ダッシュボード導入を成功に導くためには重要なポイントと言えます。
データ加工のタイプ
では、「可視化のためのデータの加工」にどのようなタイプがあるかというと、大別すると以下の2つがあります。
- データが汚いため、きれいにする加工が必要なタイプ
- データはきれいだが、それでも加工が必要なタイプ
データが汚いため、きれいにする加工が必要なタイプ
1つ目はデータ自体に問題があって、そのままでは可視化ができないため、加工が必要というタイプとなります。
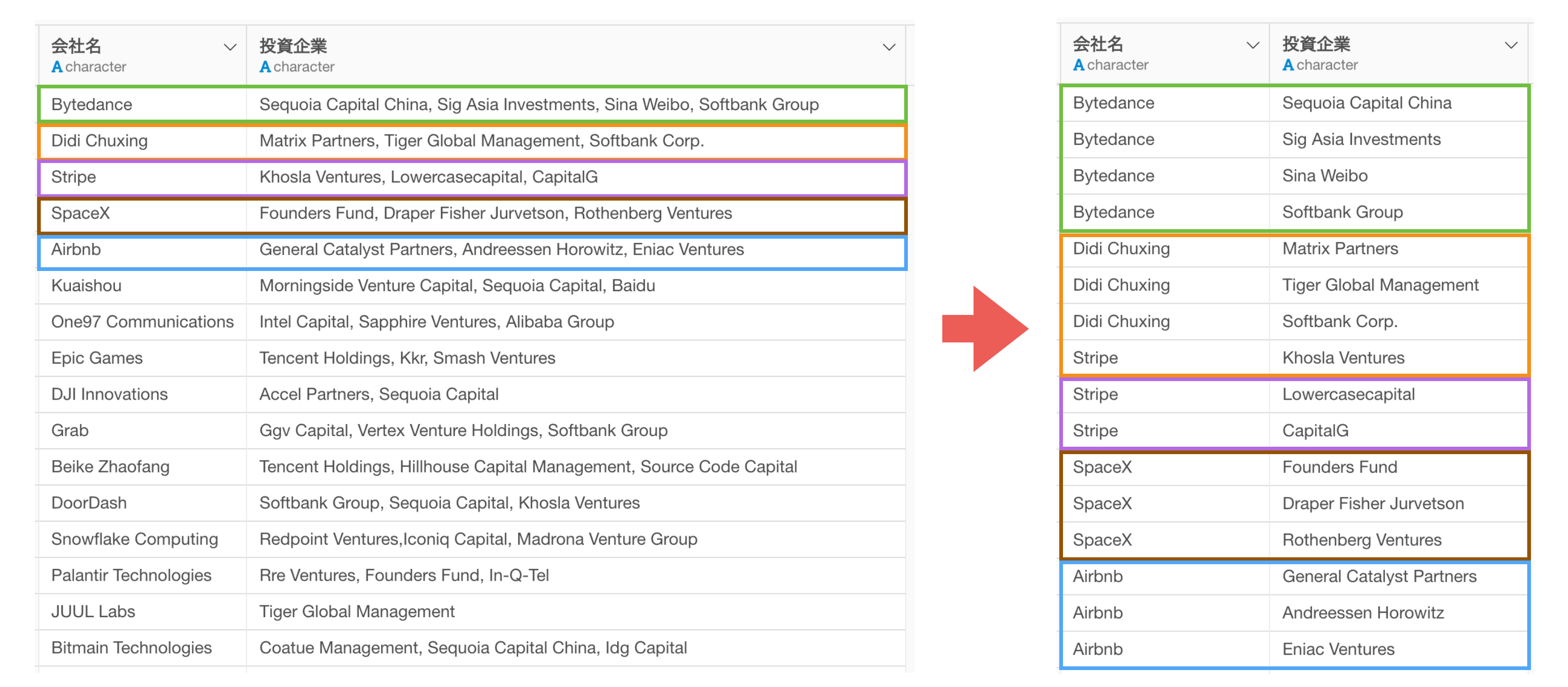
具体的な例を挙げたらきりがありませんが、例えば、1つ列にカンマ区切りで複数の値が入っているデータがあったときに、それぞれの値を集計したチャートを作成したければ、1つの「行」に対して「値を分割」する必要があります。
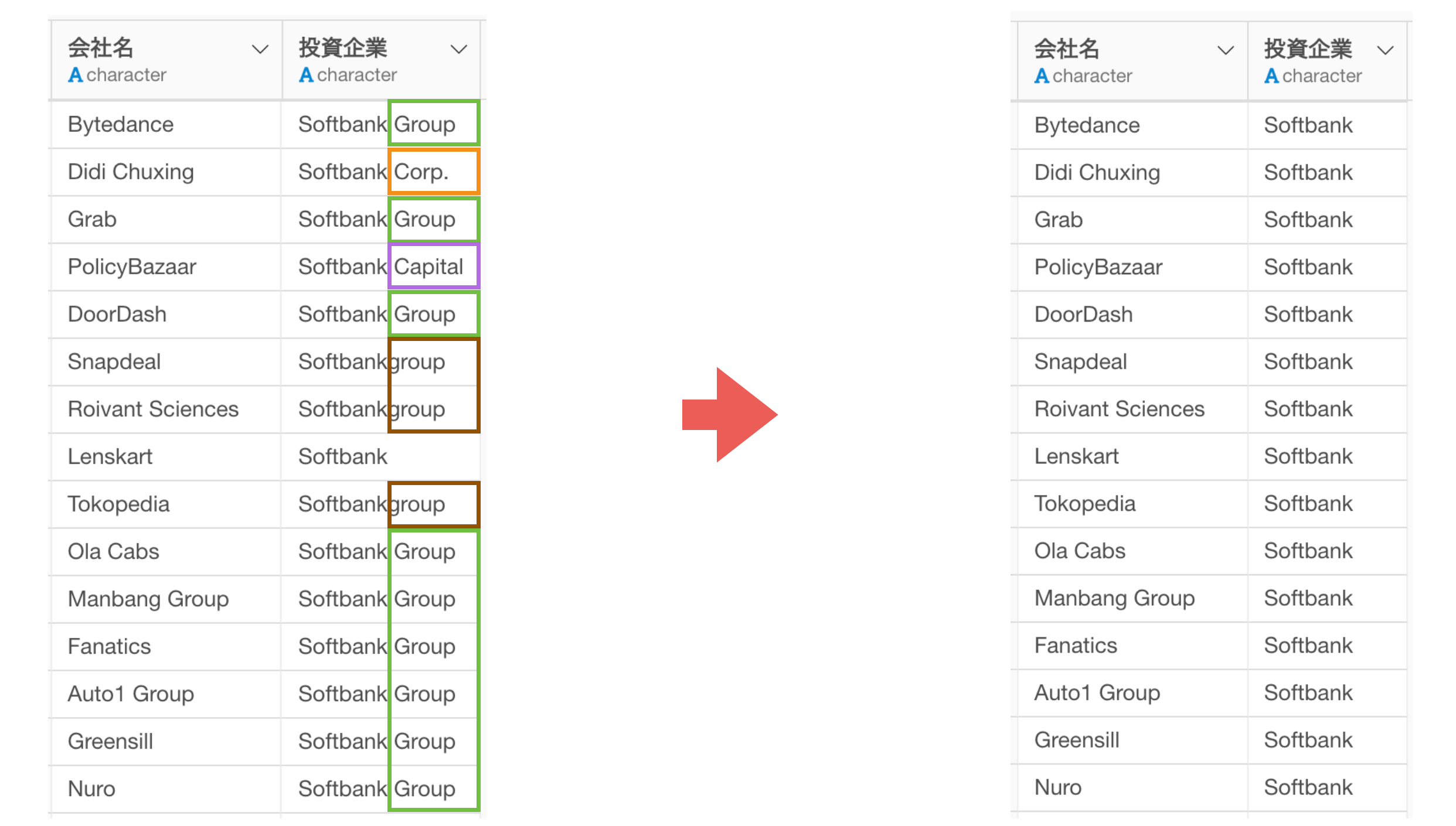
あるいは、データの中に表記揺れがあると、うまく集計ができないので、テキストデータを加工して、「名寄せ」をする必要があるかもしれません。
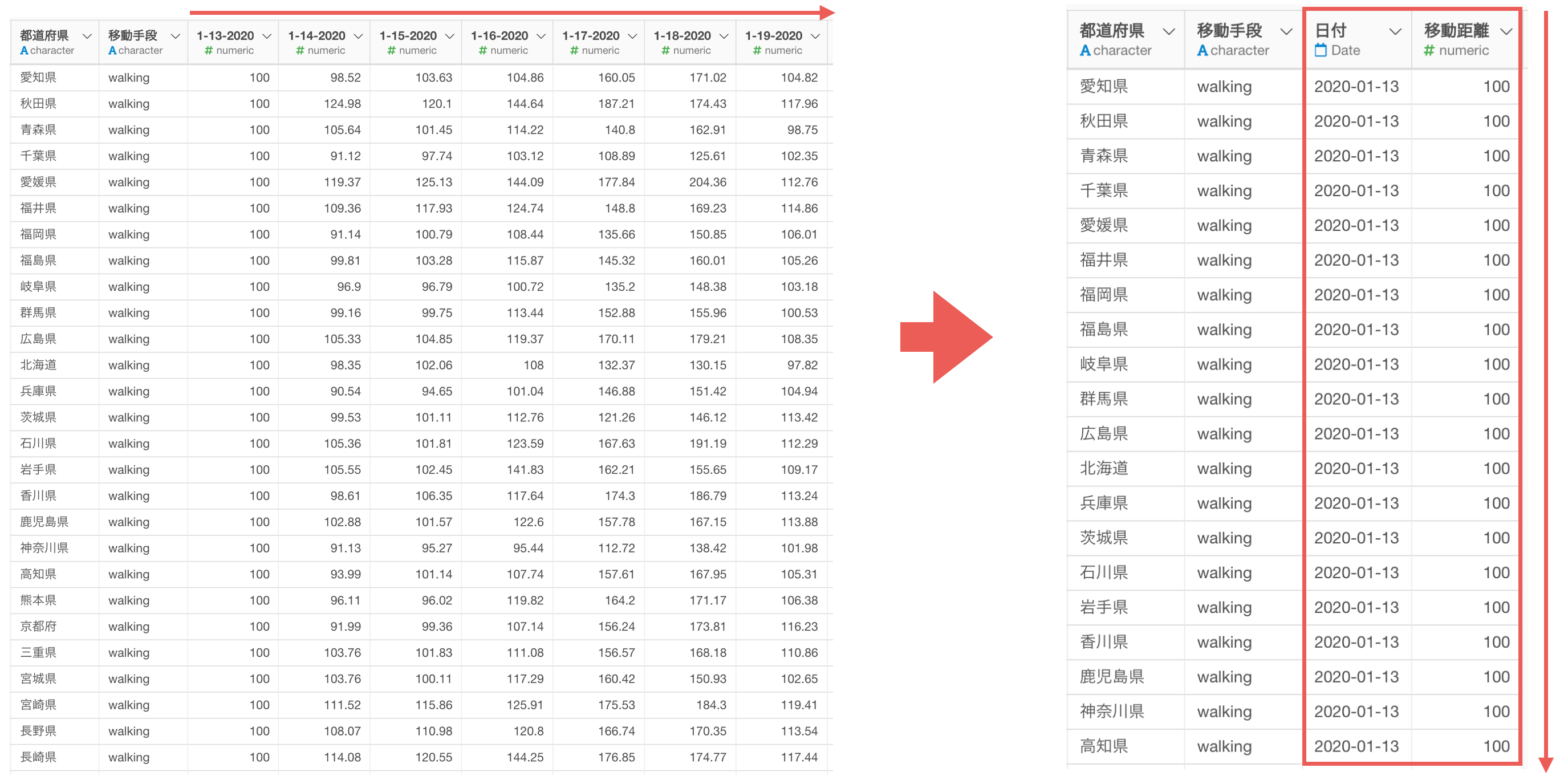
他にも、データが増えるほど横長になる「ワイド」型のデータでは、そのままだと可視化がしづらいといったこともあります。
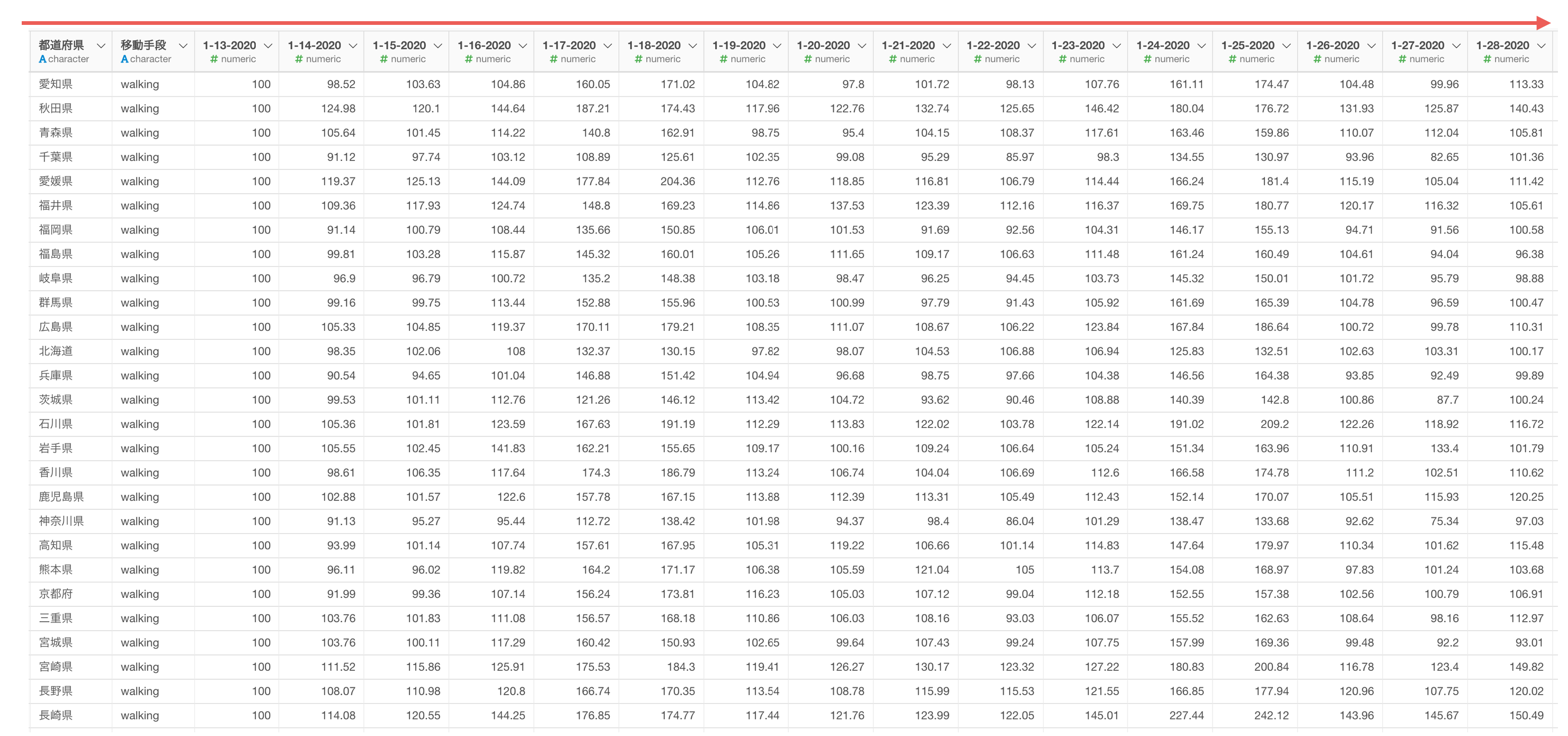
「ワイド」型のデータは「ロング」型に変換することで、可視化がしやすくなるのですが、手元のデータが「ワイド」型の場合、それを「ロング」型に変換する必要があるわけです。
データはきれいだが、それでも加工が必要なタイプ
もう1つは、データに問題はないものの、可視化のためにデータを加工する必要があるようなタイプとなります。
こちらも具体的な例を挙げだらきりがありませんが、例えば、1行が1注文になっているデータを1行1顧客のデータに「集計」する必要があるようなケースが挙げられます。
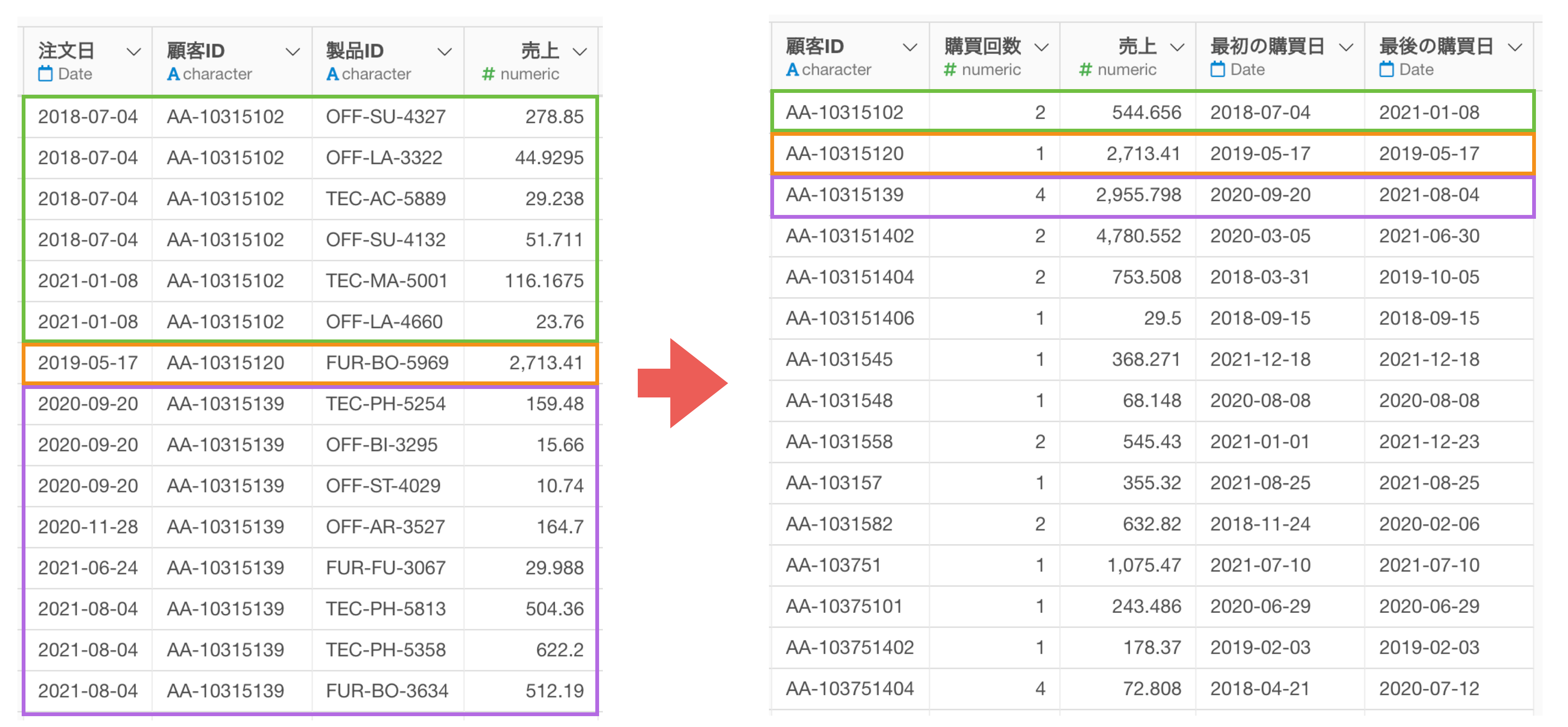
さらに集計したデータに、別のデータを結合して、結合した情報を使って可視化をしたいときもあります。
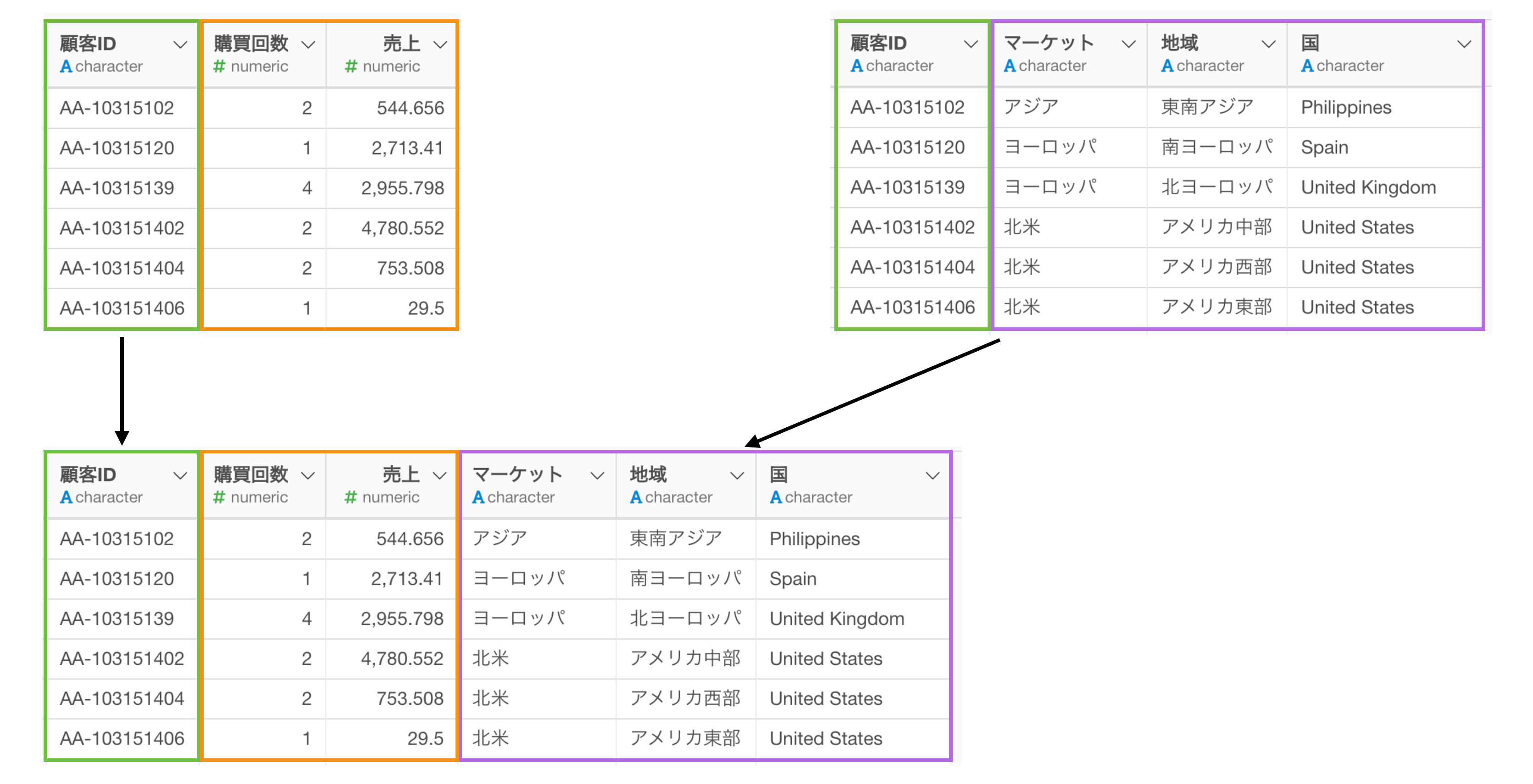
他にも、集計した売上の数値データを使って、顧客の売上げランク(順位)という別の値の計算をしたいようなケースもあるかもしれません。
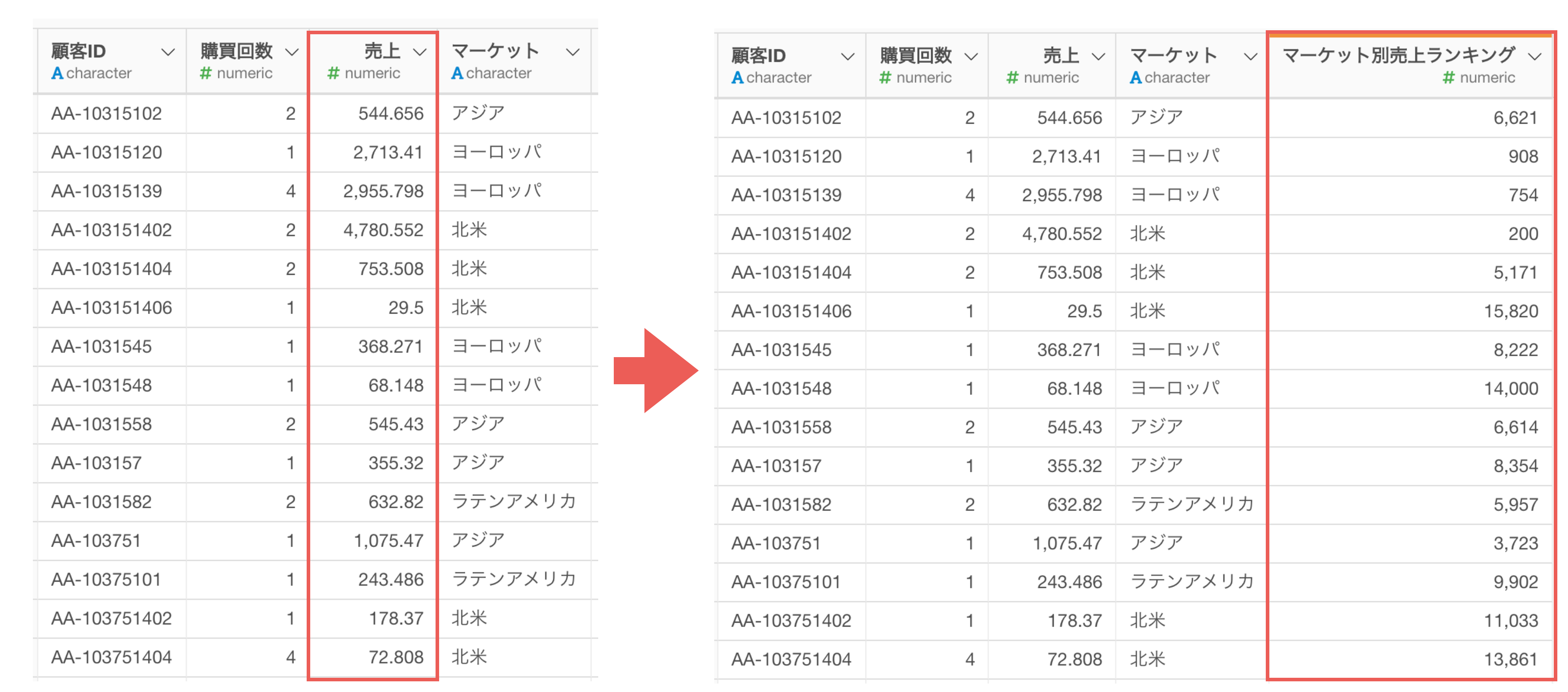
あるいは、そのような計算を「データ全体」に対して行うのではなく、「グループごと」に行いたいこともあるかもしれません。
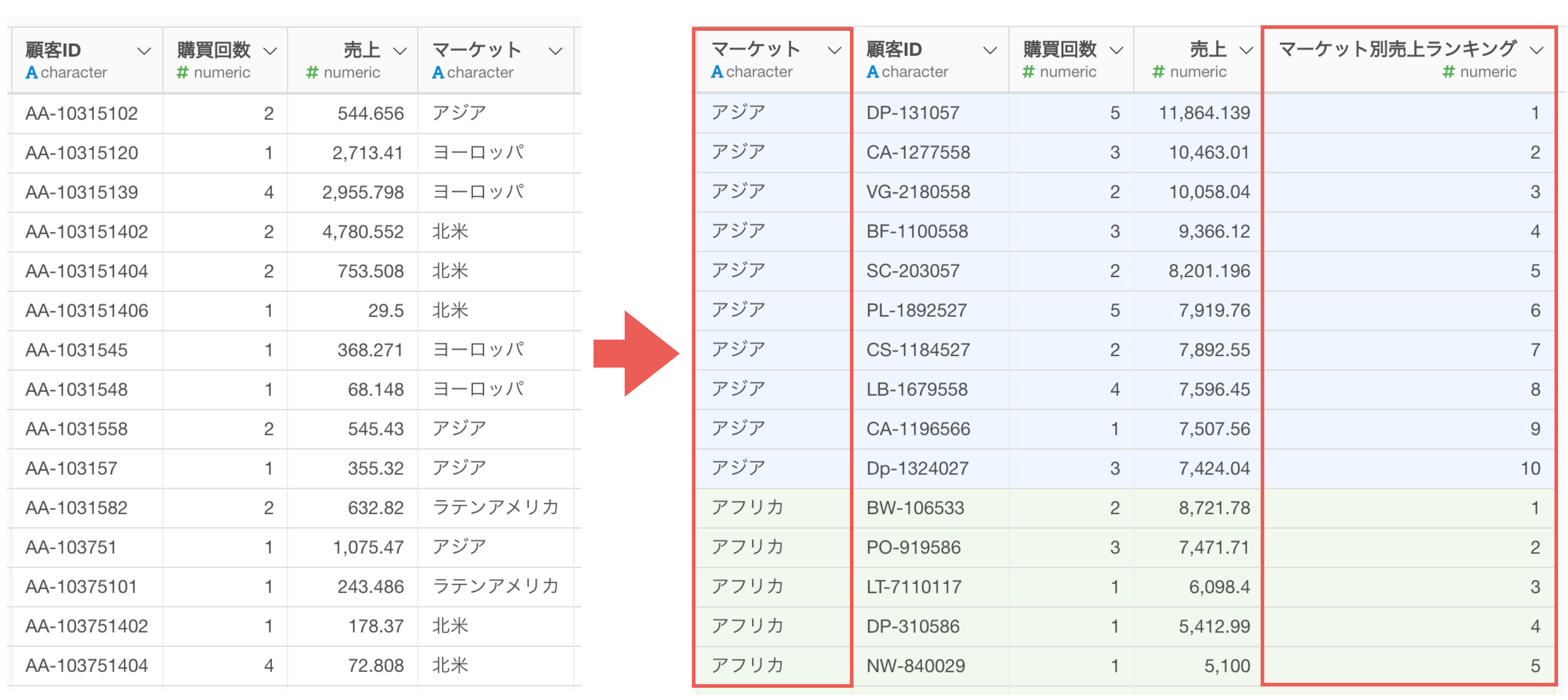
ここで紹介したのは一部の例ですが、このように一口に「データ加工」といっても、様々なタイプの加工が求められることになるわけです。
データを柔軟かつスピーディーに加工する
このようなデータ加工のスキルはBI/ダッシュボードの導入を進めるうえで必須のスキルとなりますが、BI/ダッシュボードのプロジェクトは、そのようなスキルがないところから始まることも少なくありません。
また、BI/ダッシュボードの導入プロジェクトを進めるときは、時間的な余裕がないことも多く、1からデータを加工するためのコードの書き方を学習するのは効率的とは言えません。
そういったときには、コードを書くことなく、UIから直感的に様々なデータ加工を柔軟にできれば、前述の問題を解決することができるわけです。
なお、データの加工、可視化、分析、レポーティングのためのUIツールのExploratoryを利用すると、UIを通して様々な形にデータを加工していくことができます。
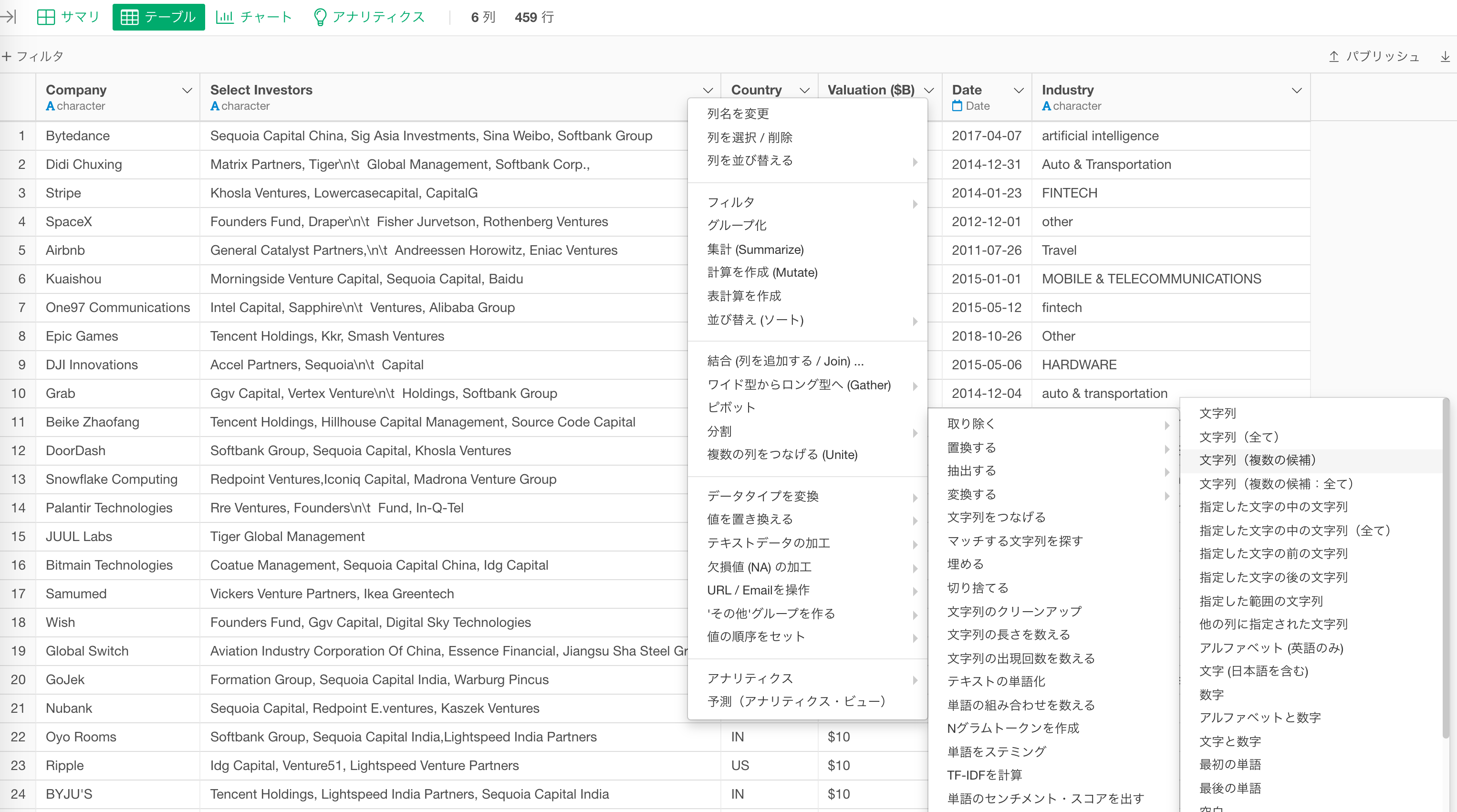
また、データ加工に関わる細かい処理も、UIから直感的に設定できるので、事前知識がない方も、コードを書かずに、より柔軟にデータを加工していくことができるようになっています。
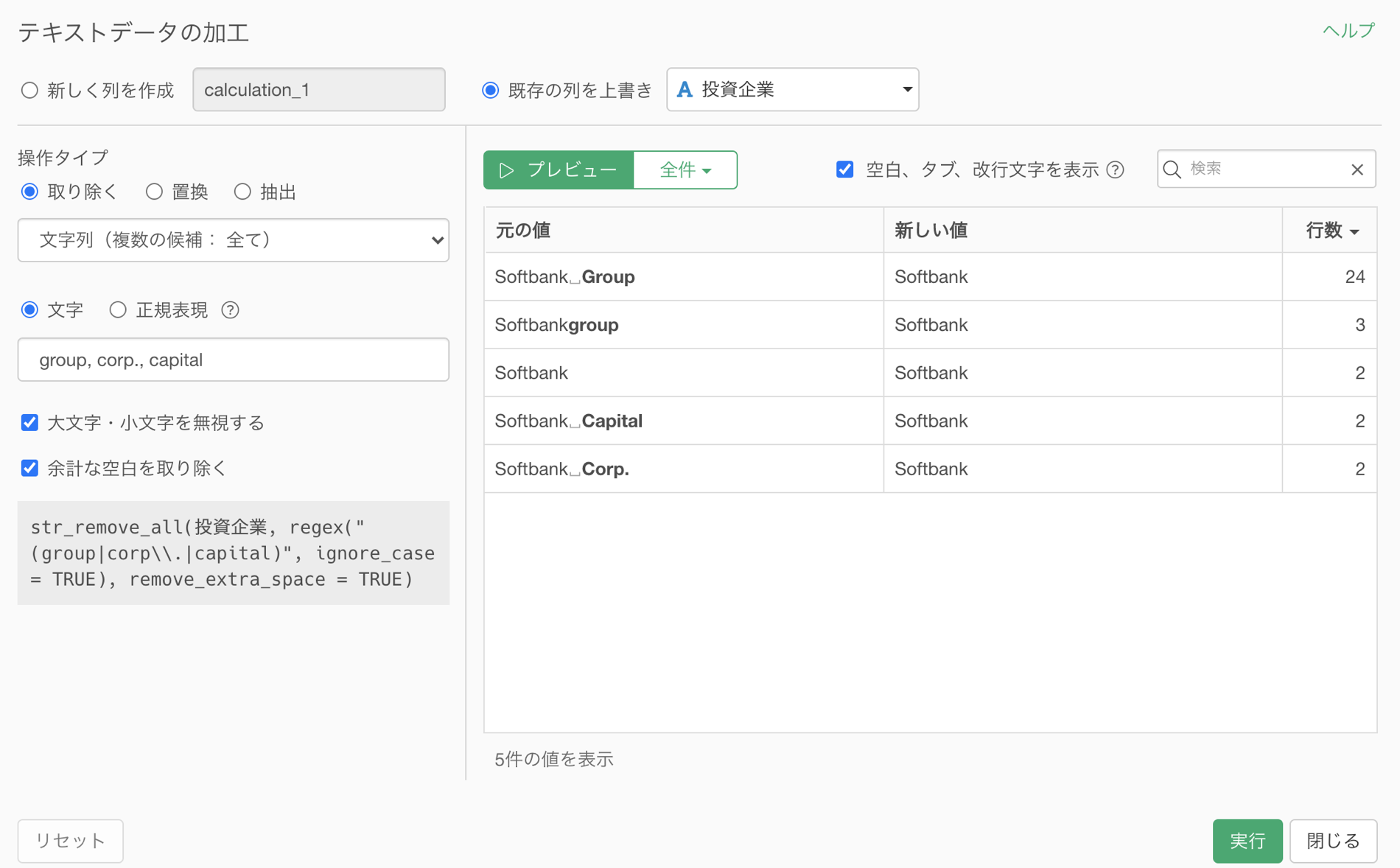
さて、ここまでは、「思うような形にデータを加工できるかどうか」の話をさせていただきましたが、データを加工するときは、加工が簡単に、そして柔軟にできるかどうか、あるいは正確かつ効率的にできるか、といったことも重要です。
なぜなら、ただ単にデータを加工ができるだけでは、以下のような手間を解決できないからです。
- 加工した結果が誤っていたときに、どこが問題だったのかが分かりづらいと修正に時間がかかる。
- データ加工をする度に集計や可視化をして、データが適切に加工されているかどうかを確認していては手間がかかる。
- 1つのデータから複数のチャートを作成するために、複数の加工データを用意していては、手間がかかる。
そこで、Exploratoryでは、「ステップ」や「サマリ」といった機能によって、データの加工を効率的に進められるようにしています。
Exploratoryで追加した加工の処理は、その順番とともに「ステップ」として自動的に記録されており、1つ1つのステップの単位でデータの加工の処理内容を変更したり、順番を入れ替えたりすることが可能です。
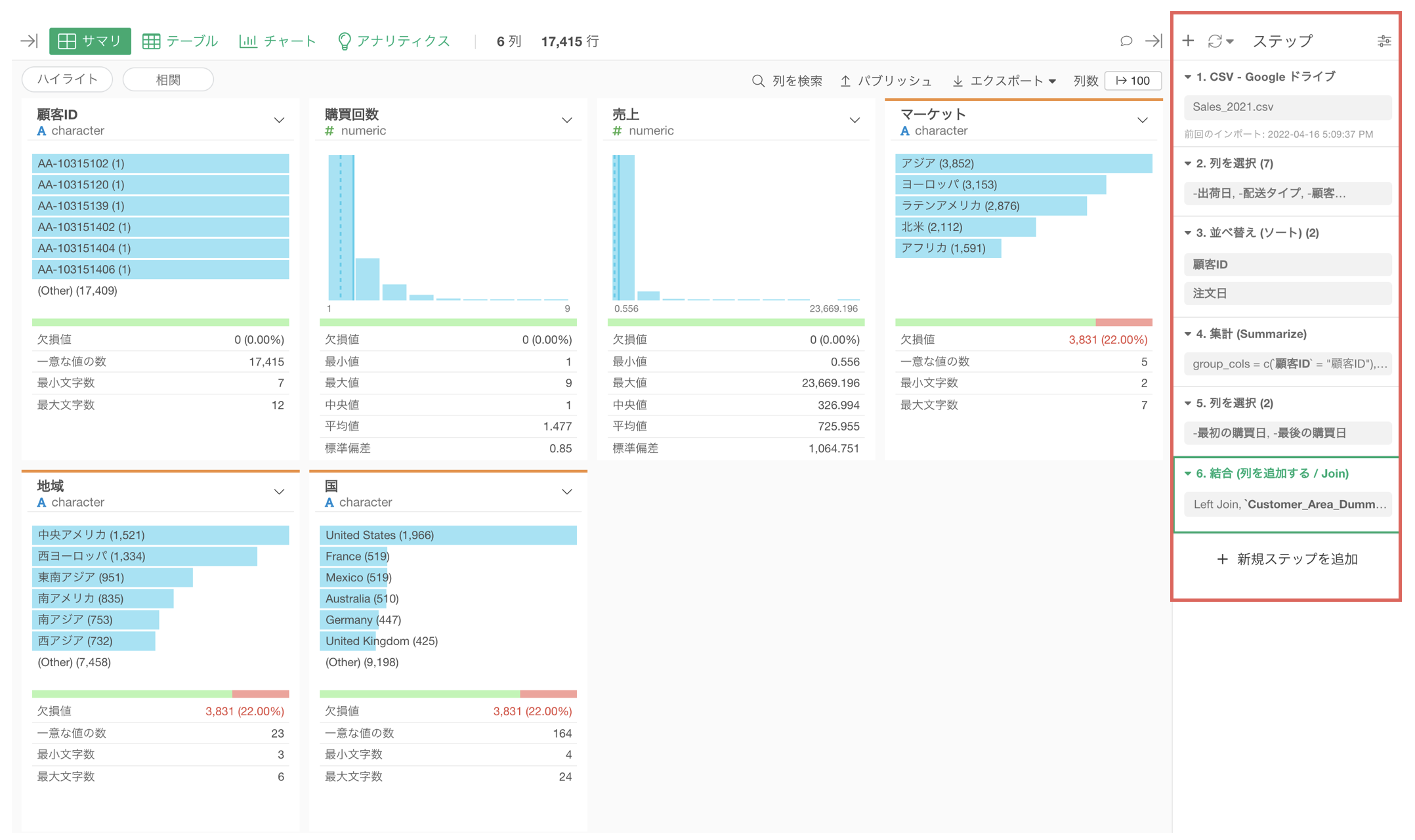
さらに、全てのデータの加工の処理を追加/変更する度に、各列のサマリ情報が自動的に計算されるので、データ加工の結果をビジュアルで確認できるようになっています。
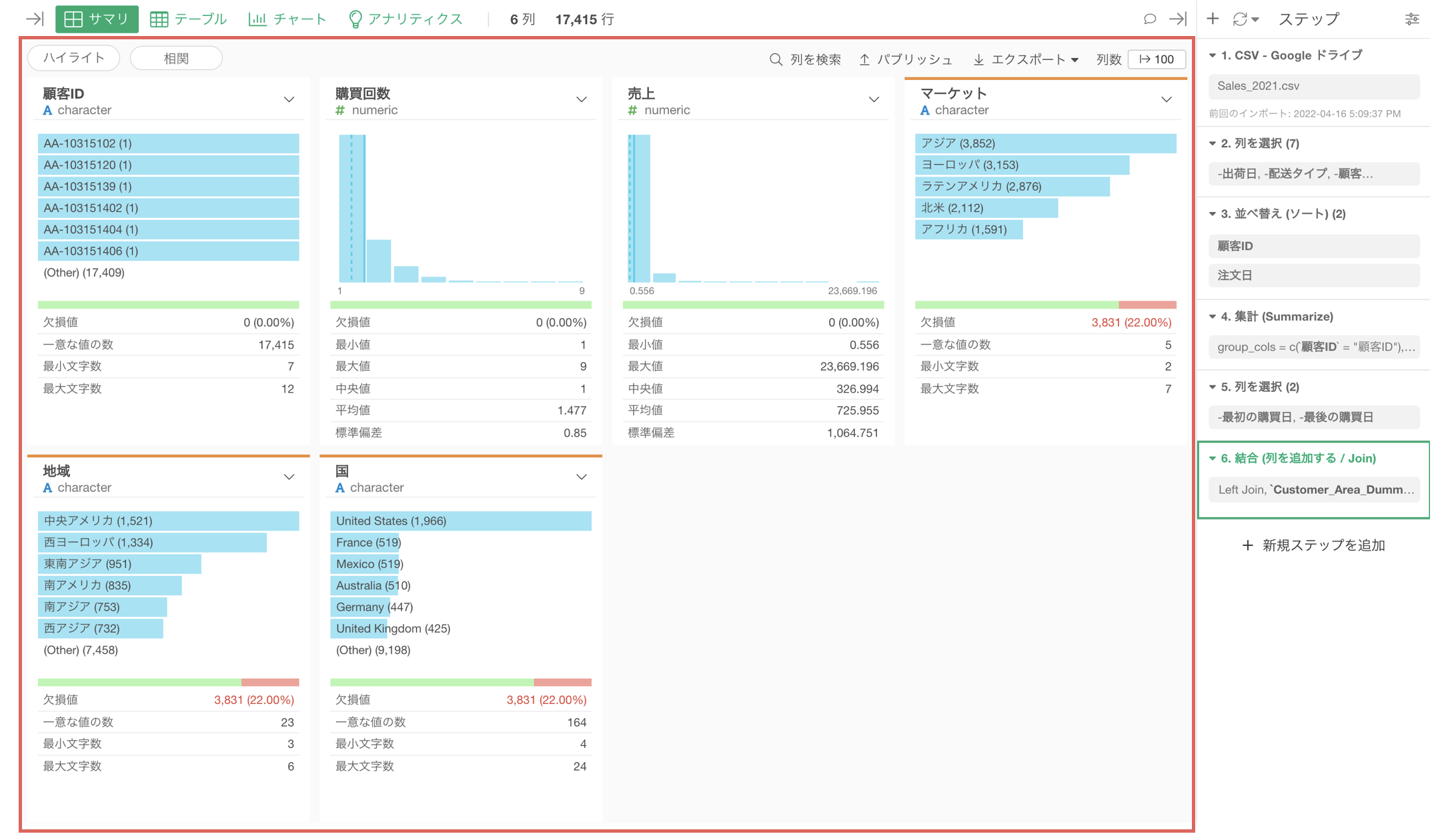
また、任意のデータ加工のステップに紐付けて複数のチャートを作成することもできるので、1つのデータの加工の流れの中で複数のチャートを効率的に作成して、様々なデータ加工のステップに紐付けられた複数のチャートを1つのダッシュボードにまとめることができます。
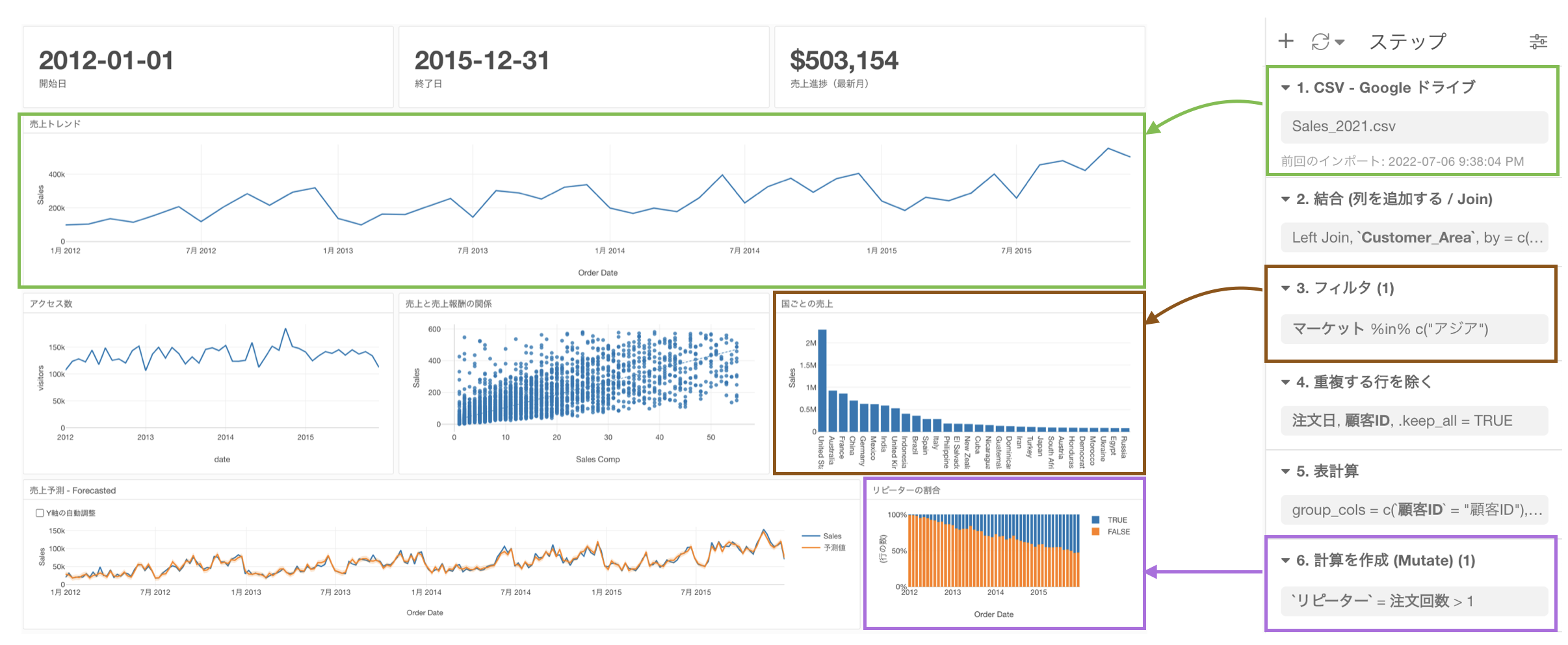
2. ばらつきの可視化
BIの基本機能は集計、または集計データの可視化です。
しかし、データを集計して1つの「代表値」にまとめてしまうと、データのばらつきやトレンドに関する重要な情報が失われてしまうことがあります。
ばらつきを可視化しないときの問題
例えば、自社の顧客の年齢に対する理解を深めるために、顧客の平均年齢を集計することは、よくやることの1つですが、平均値は、非常に低い、または高い数値の影響を受けやすく、集計データだけを見ていると、データへの理解が歪んでしまうことがあります。

ばらつきの可視化するためのチャート
そこでデータを適切に理解するためには、データのばらつきを可視化できる以下のようなチャートを使うことが有効です。
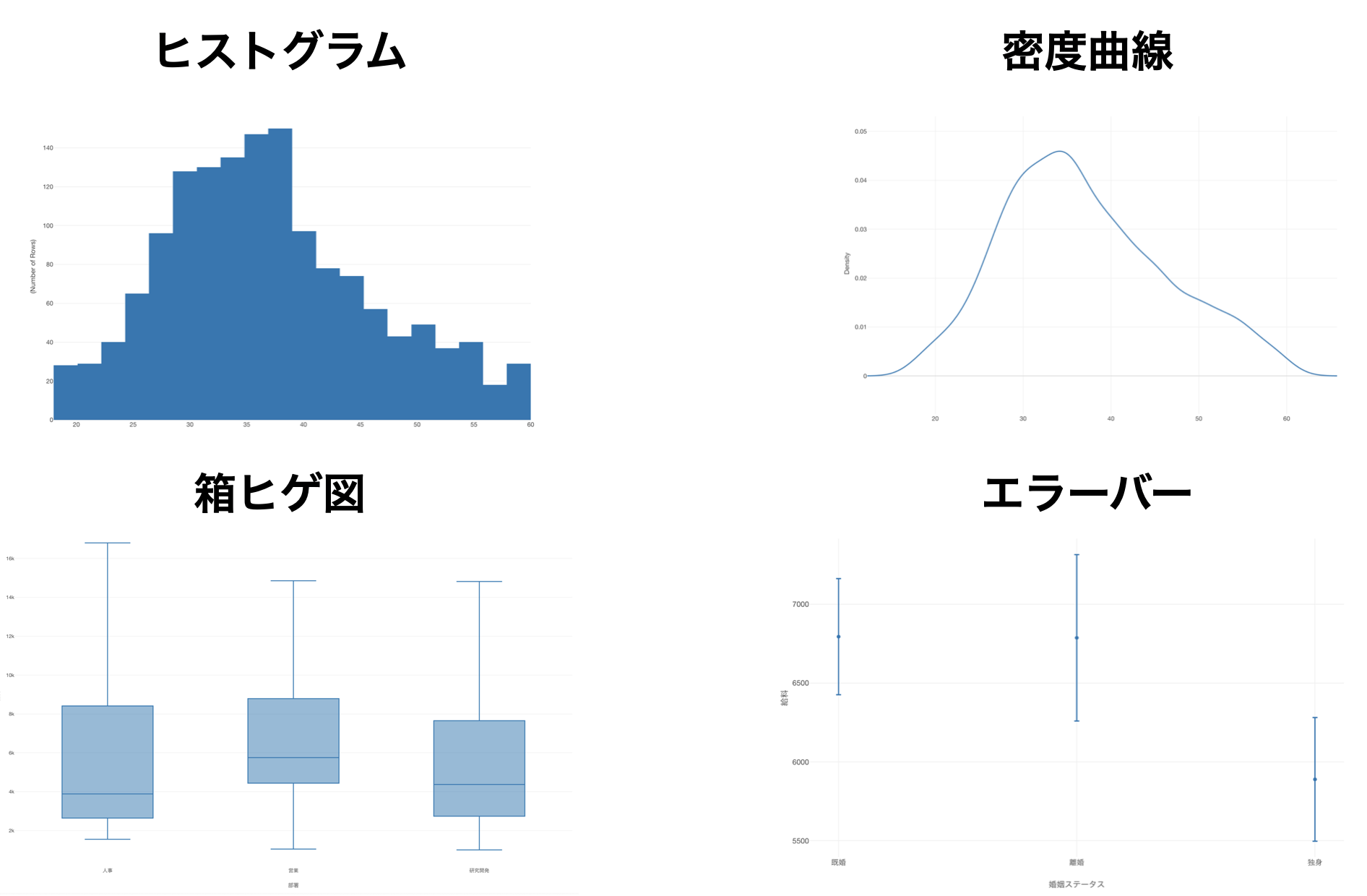
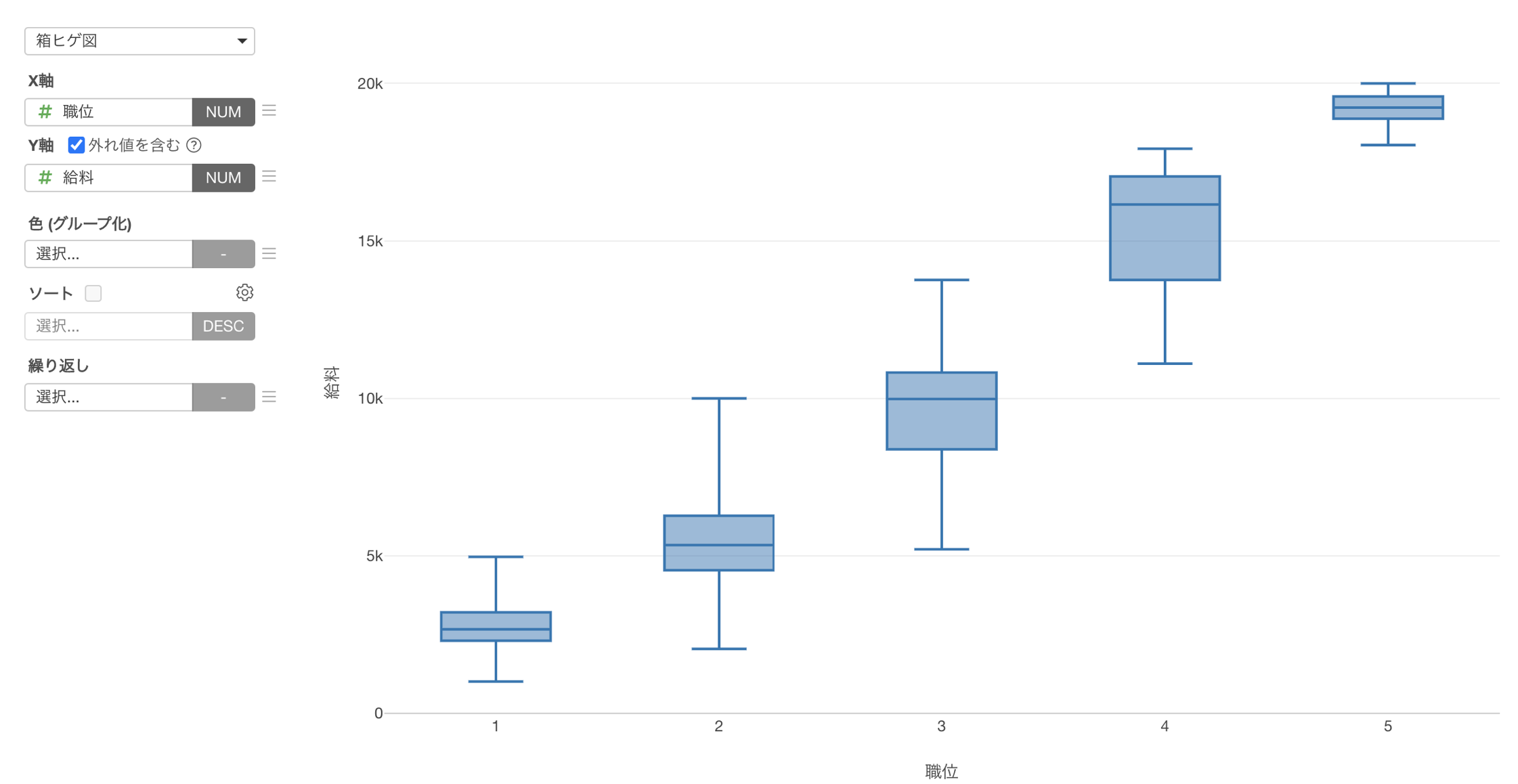
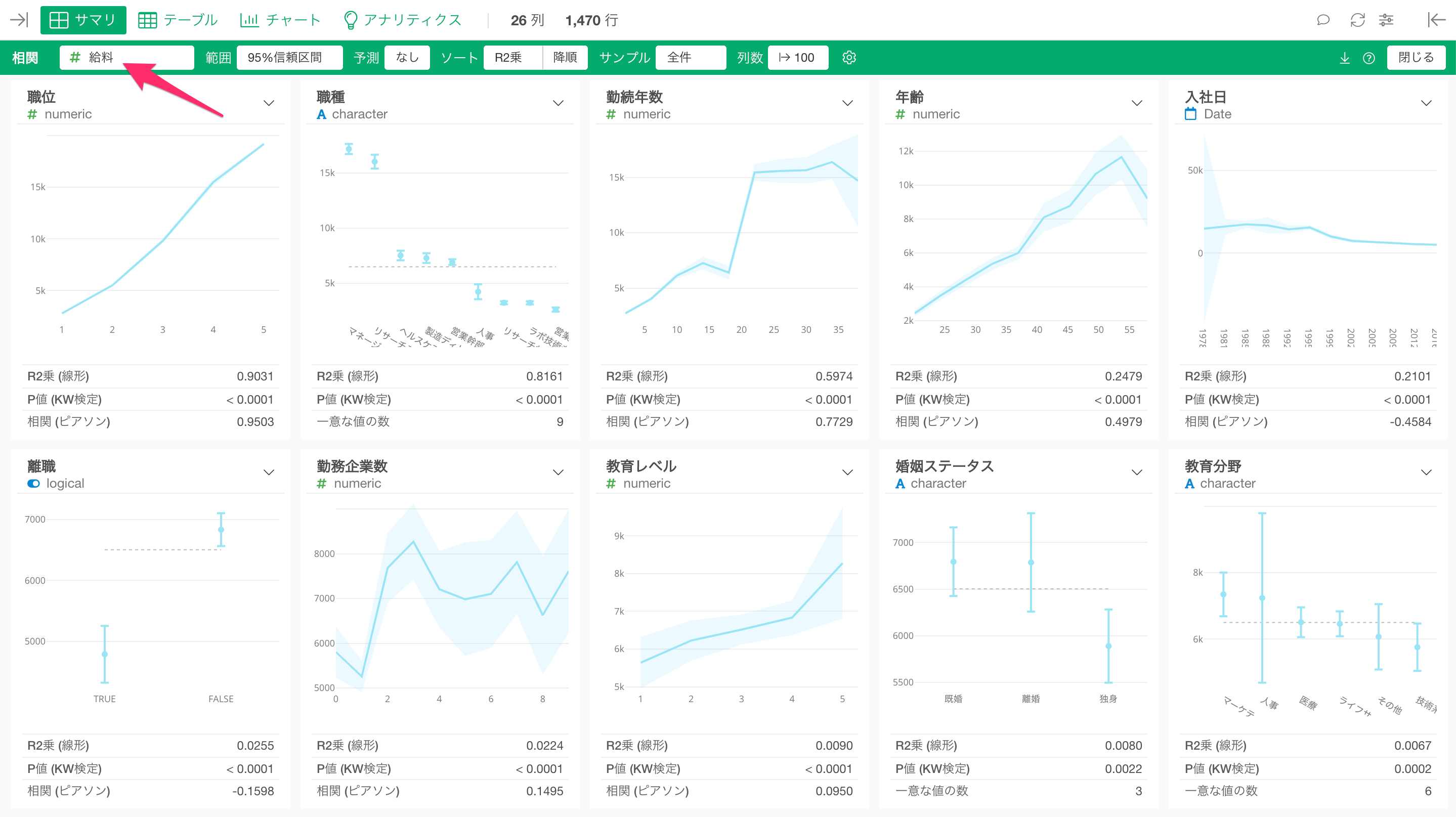
例えば、「教育レベル」が上がると「給料」の平均値が高くなるようなデータがあったとします。
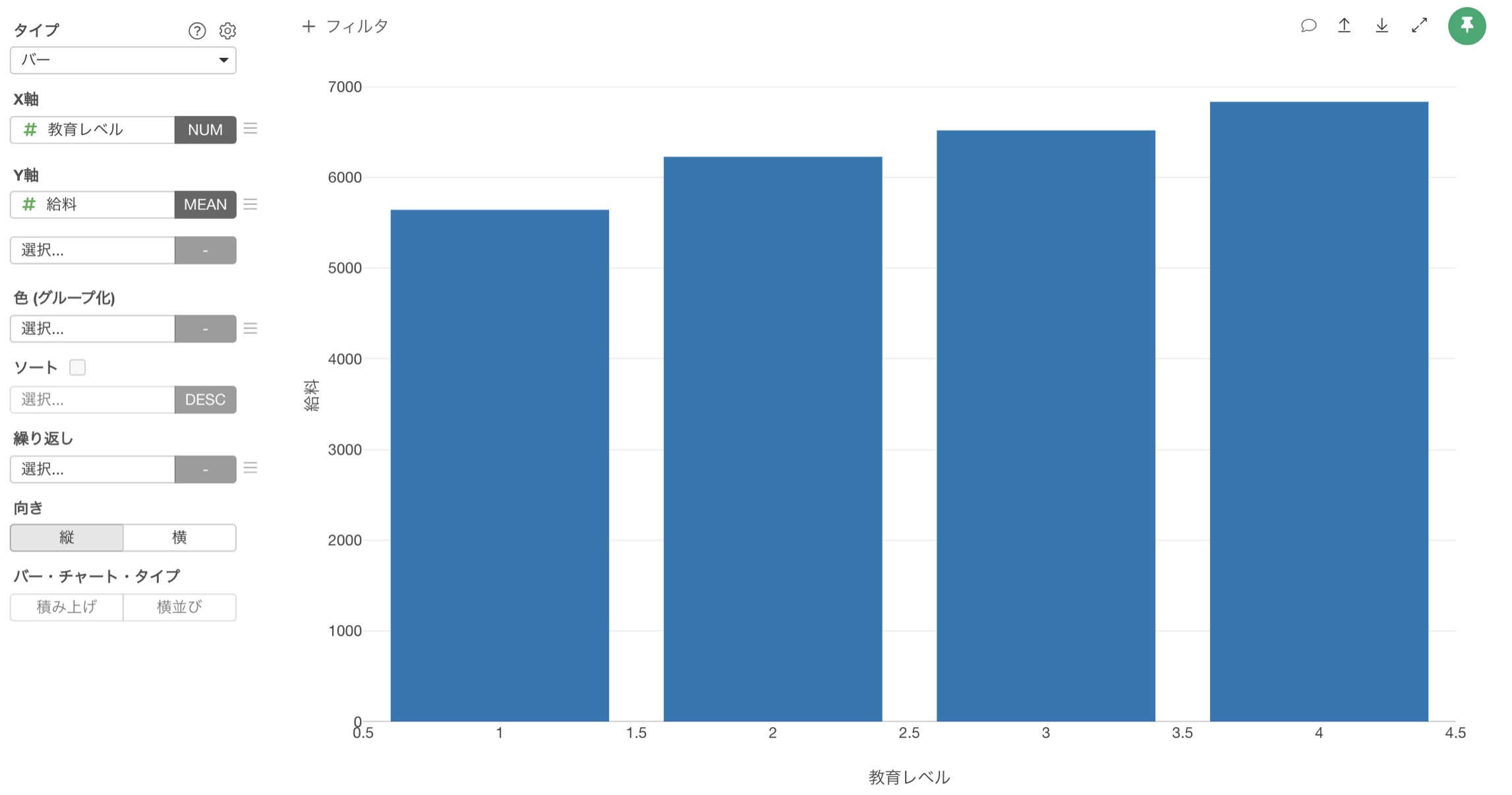
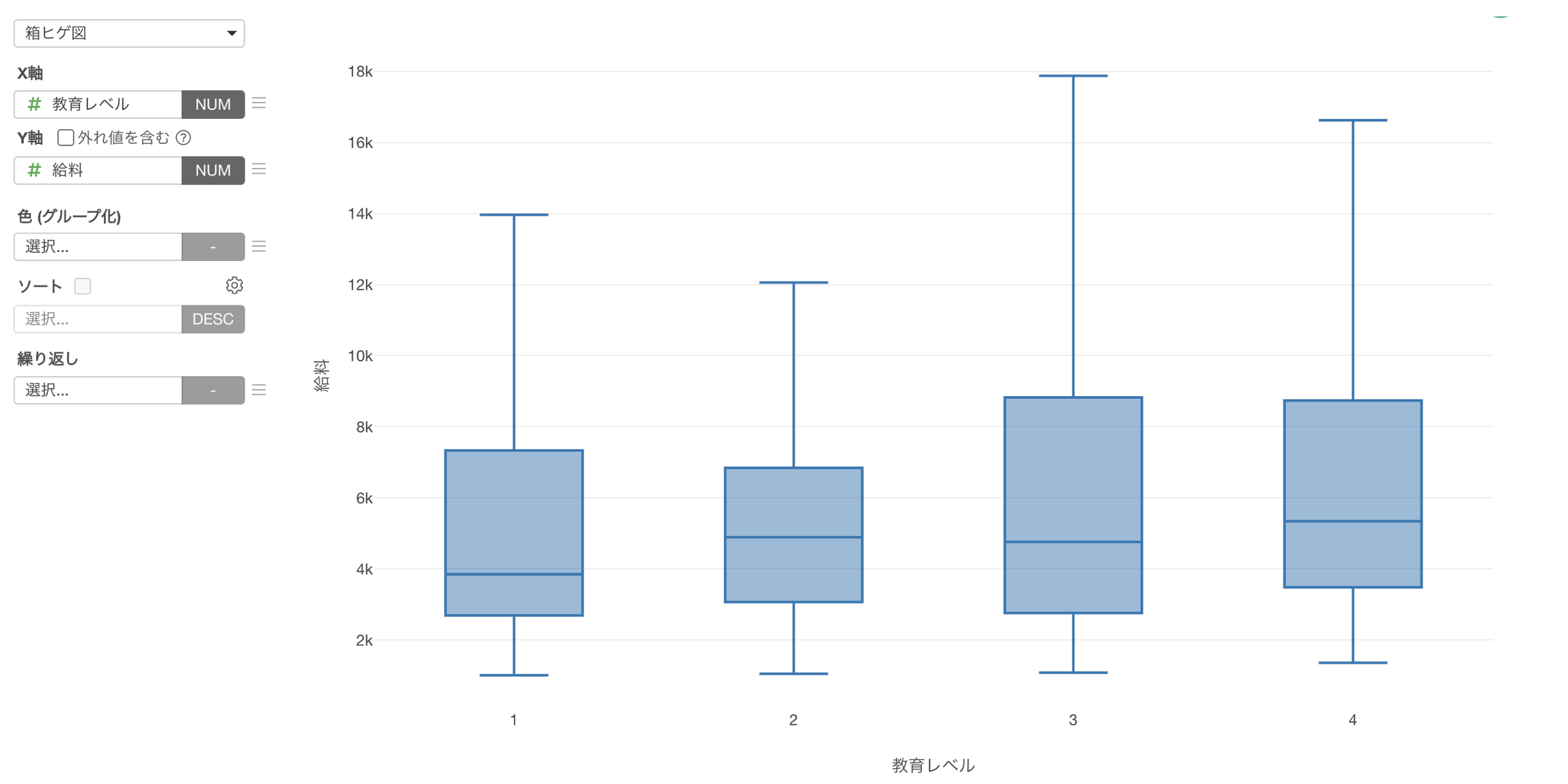
このデータを使って、データのばらつきを可視化するチャートである「箱ヒゲ図」で、「教育レベル」と「給料」の関係を可視化してみると、教育レベルが上がっても必ずしも皆の給料が上がるとは言えないことが分かります。
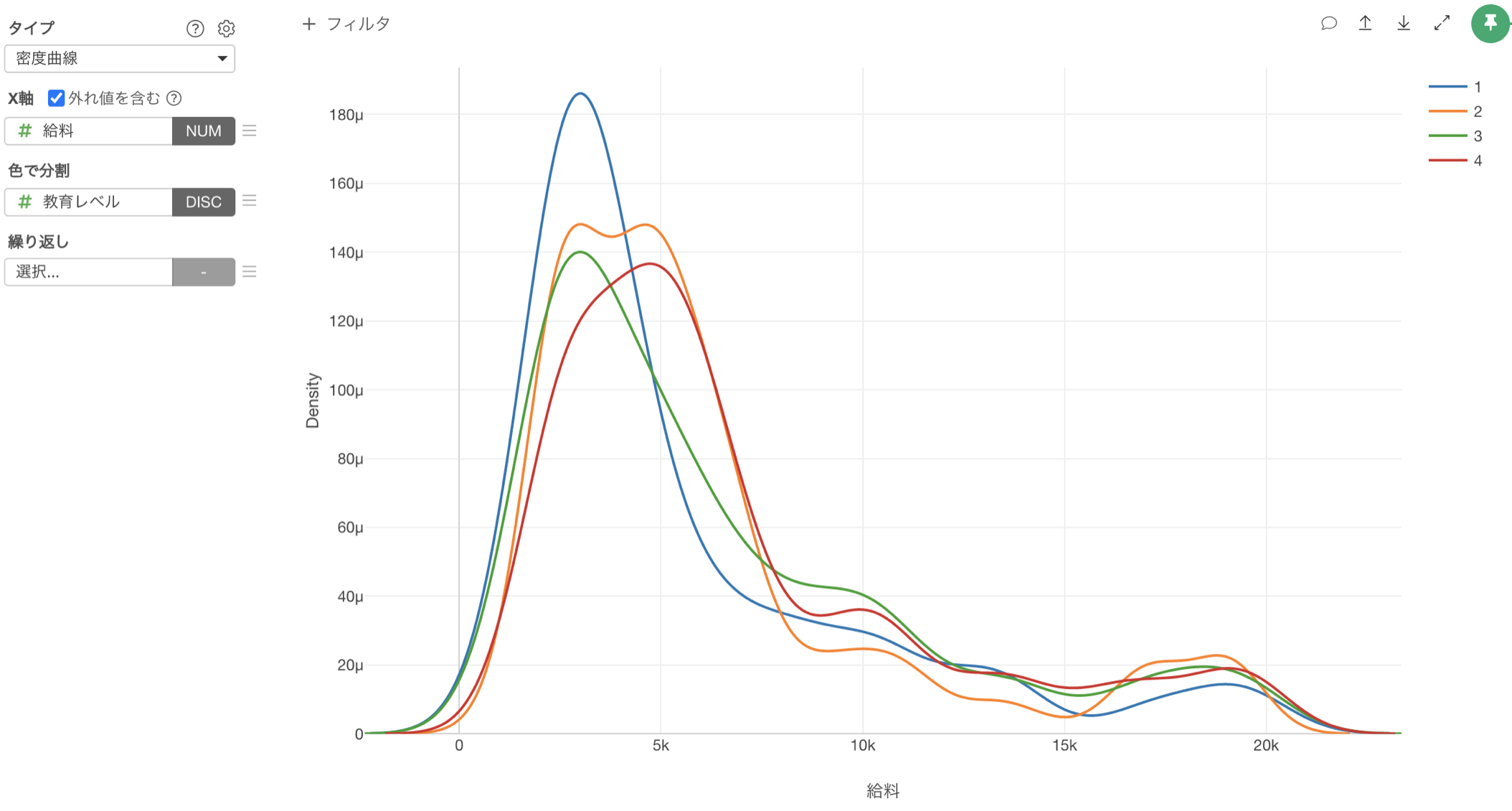
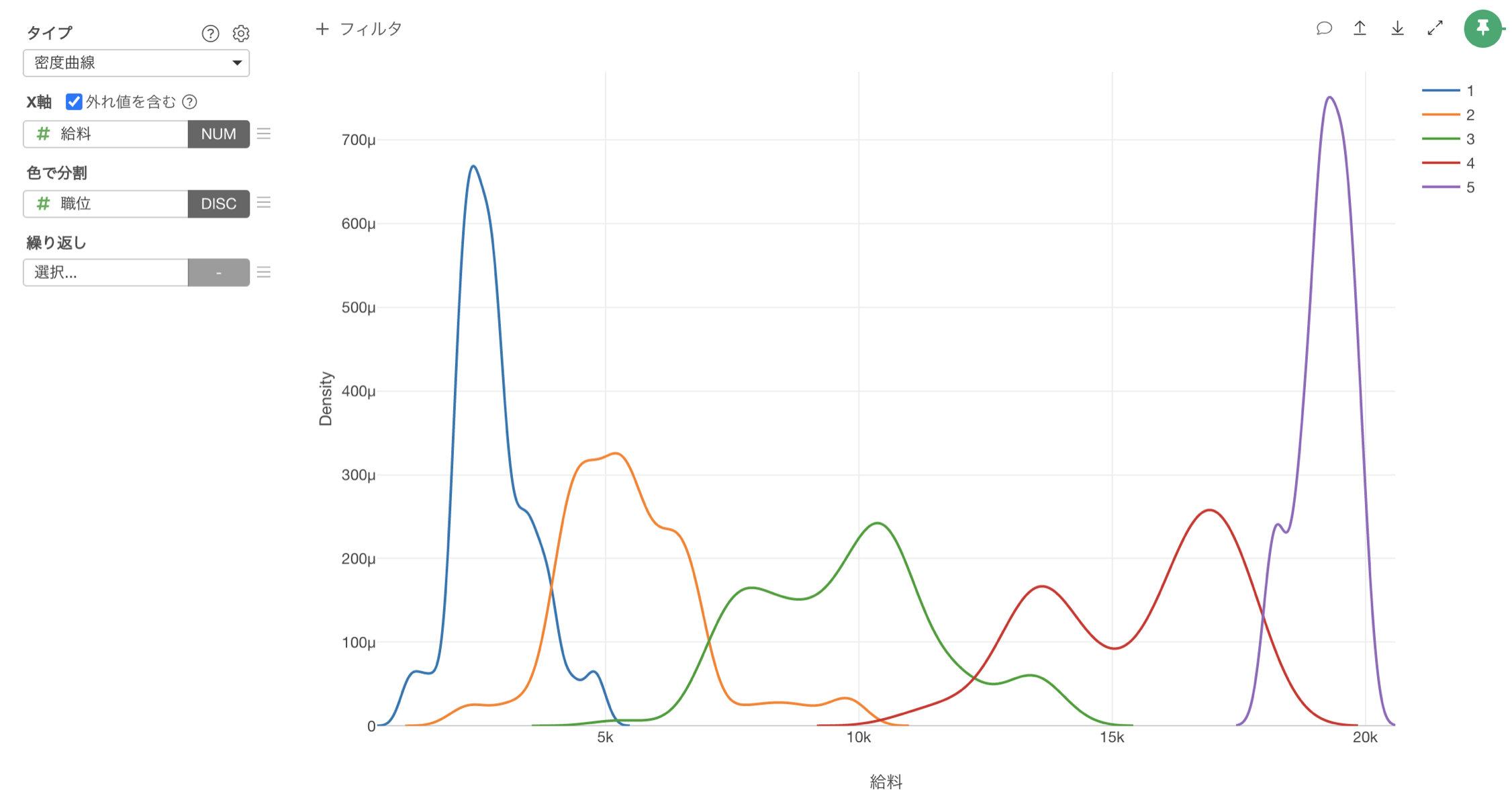
また「密度曲線」を利用すれば、教育レベルが1の人は、他と人達と分布の仕方が違うようですが、他の教育レベルの人達の給料の分布は、ほぼ変わらないといったことも分かります。
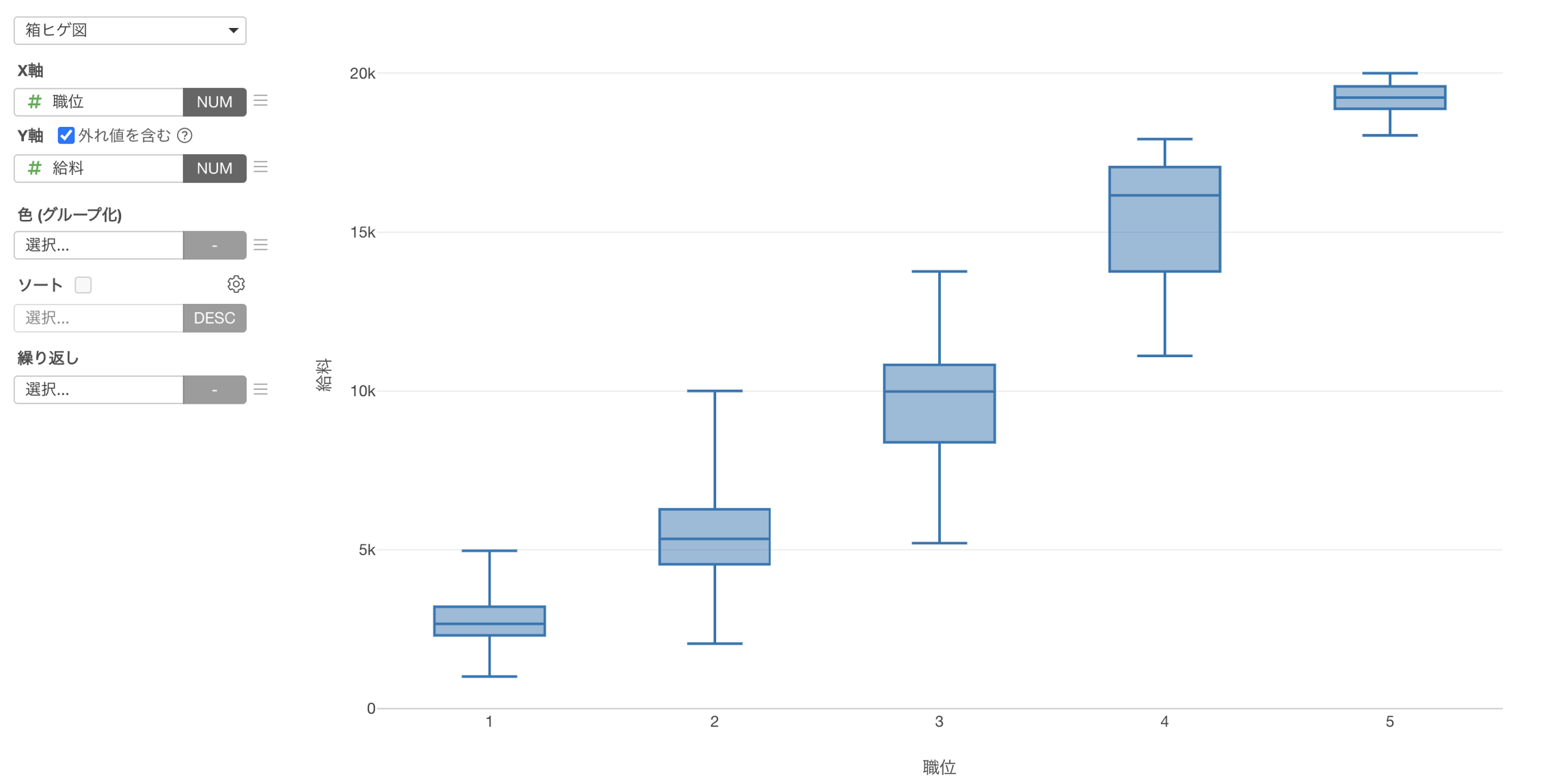
一方で、「職位」が上がると、「給料」の平均値が高くなるような関係があったとします。
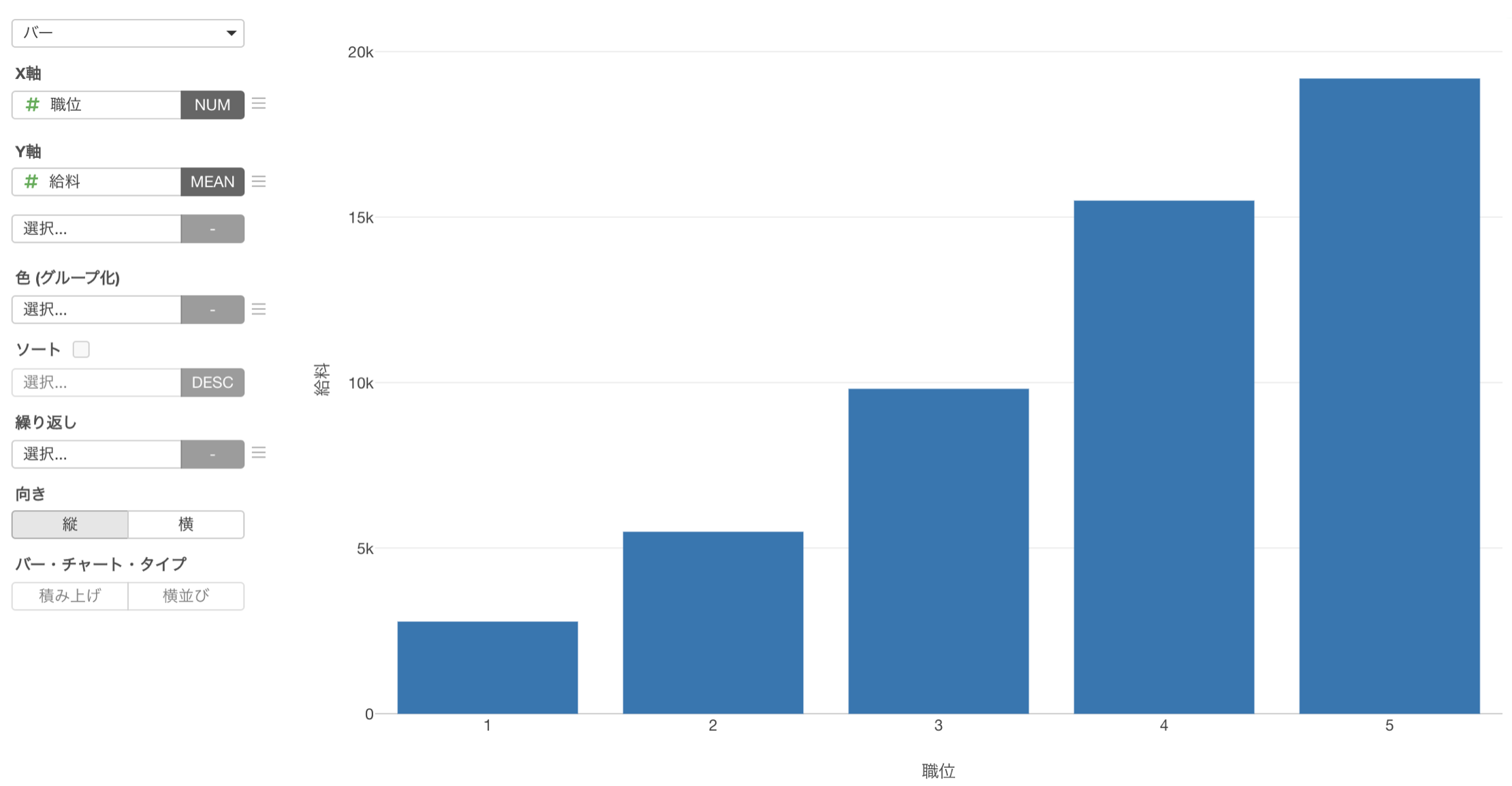
箱ヒゲ図を使って分布を可視化しても、職位が上がると給料は上がっていく関係があることが分かります。
また密度曲線を利用して、分布を可視化してみても、職位による給料の分布の違いがより明らかに見えてきます。
エラーバー:信頼区間
ところで、購買データなどを利用して2つのグループの平均購買金額を比べると、アメリカの方が平均購買金額が高く見えるデータがあったとします。
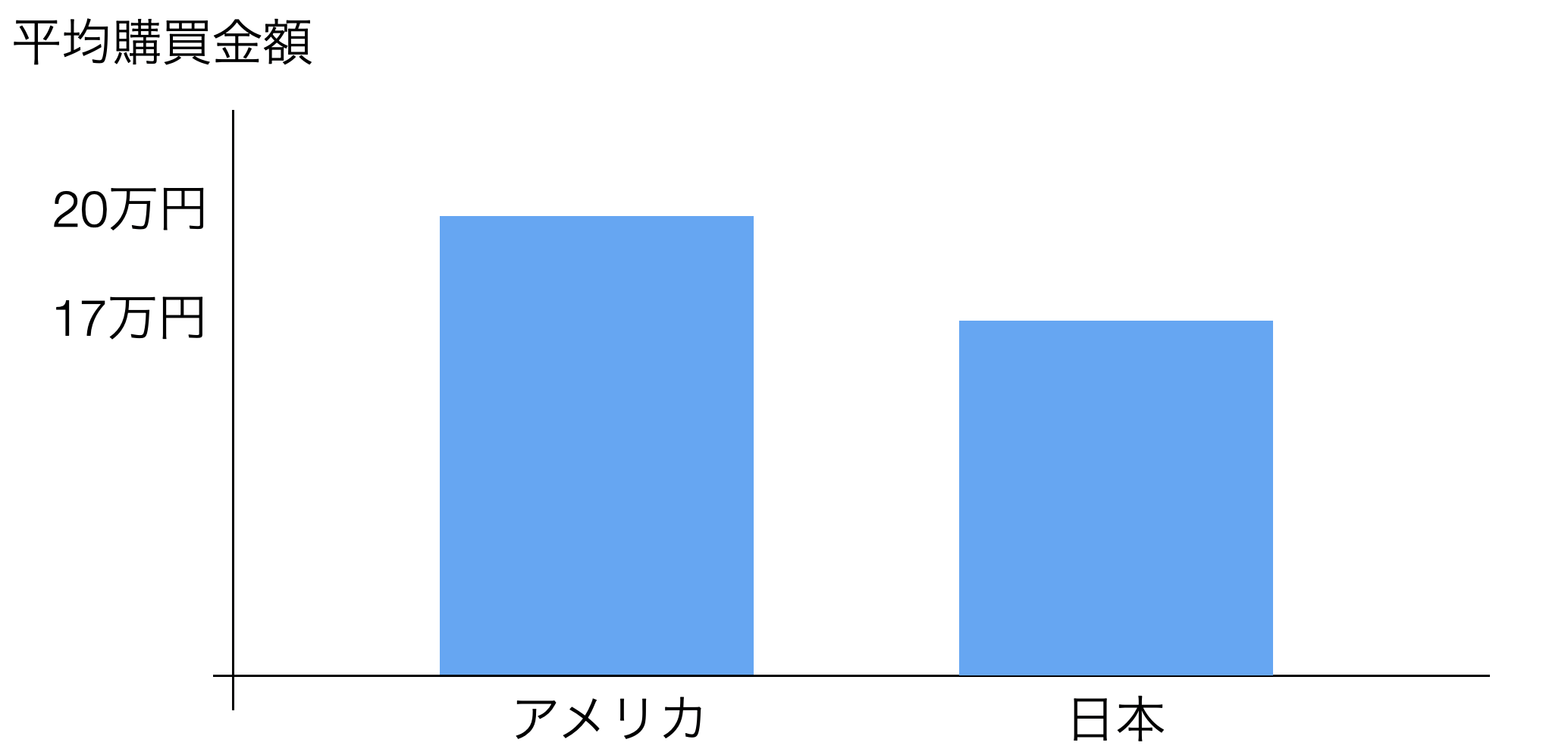
このとき、本当にアメリカの顧客は日本の顧客よりも購買金額が高いと言い切れるのか、という話もあります。
どういうことかと言うと、アメリカには300人分のデータがあるのに対して、日本には30人分のデータしかなかったときに、日本はデータの数が少ないので集計値の値を信頼できないということが起こりえます。
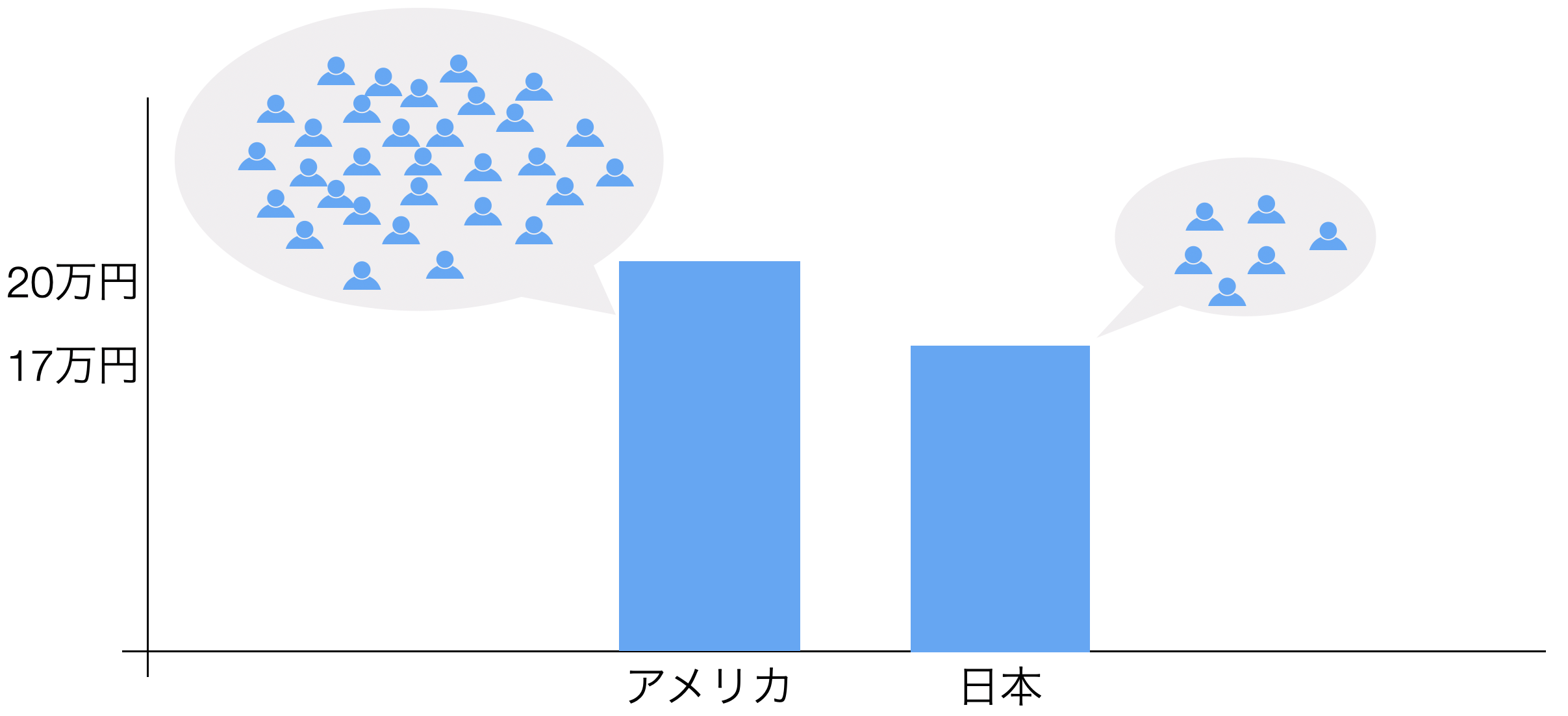
なぜかというと、データ量が少ないと購買金額が低い/高い顧客が少し増えただけで、平均購買金額は大きく変動しまうからです。
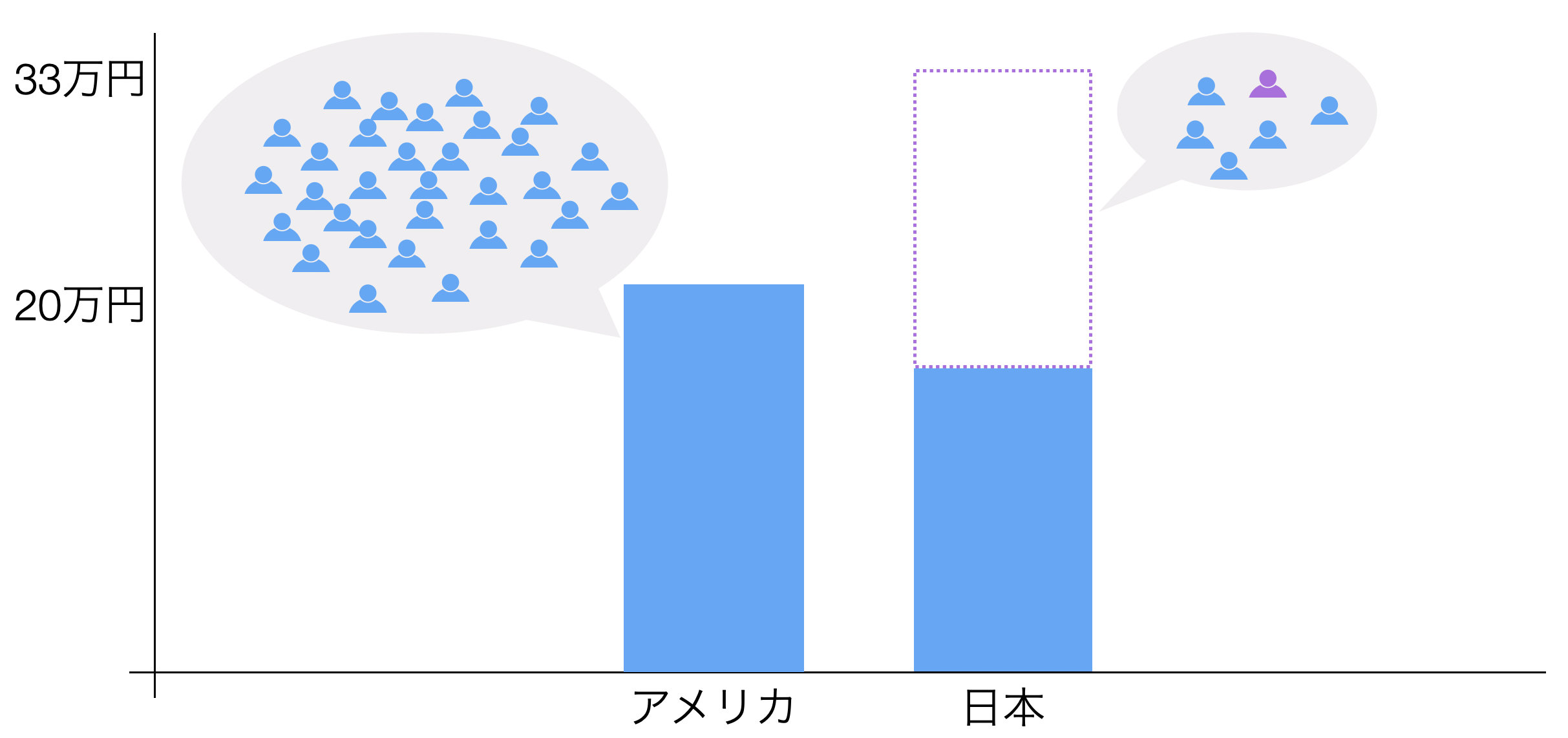
多くの場合、データを比べるときは、意味のある違いがあるかどうかを調べたいので、このままではデータから言えることが曖昧になってしまいます。
そこで、「エラーバー」というチャートを利用すると、集計値(平均値や割合など)で比べるのではなく、データのばらつきや量などを考慮した誤差(信頼区間)を含めて、意味のある違いがあるかどうかを比べることができるようになります。
例えば、以下のチャートはメルマガを購読している人と、そうでない人の購買金額の平均を可視化したエラーバーのチャートになります。
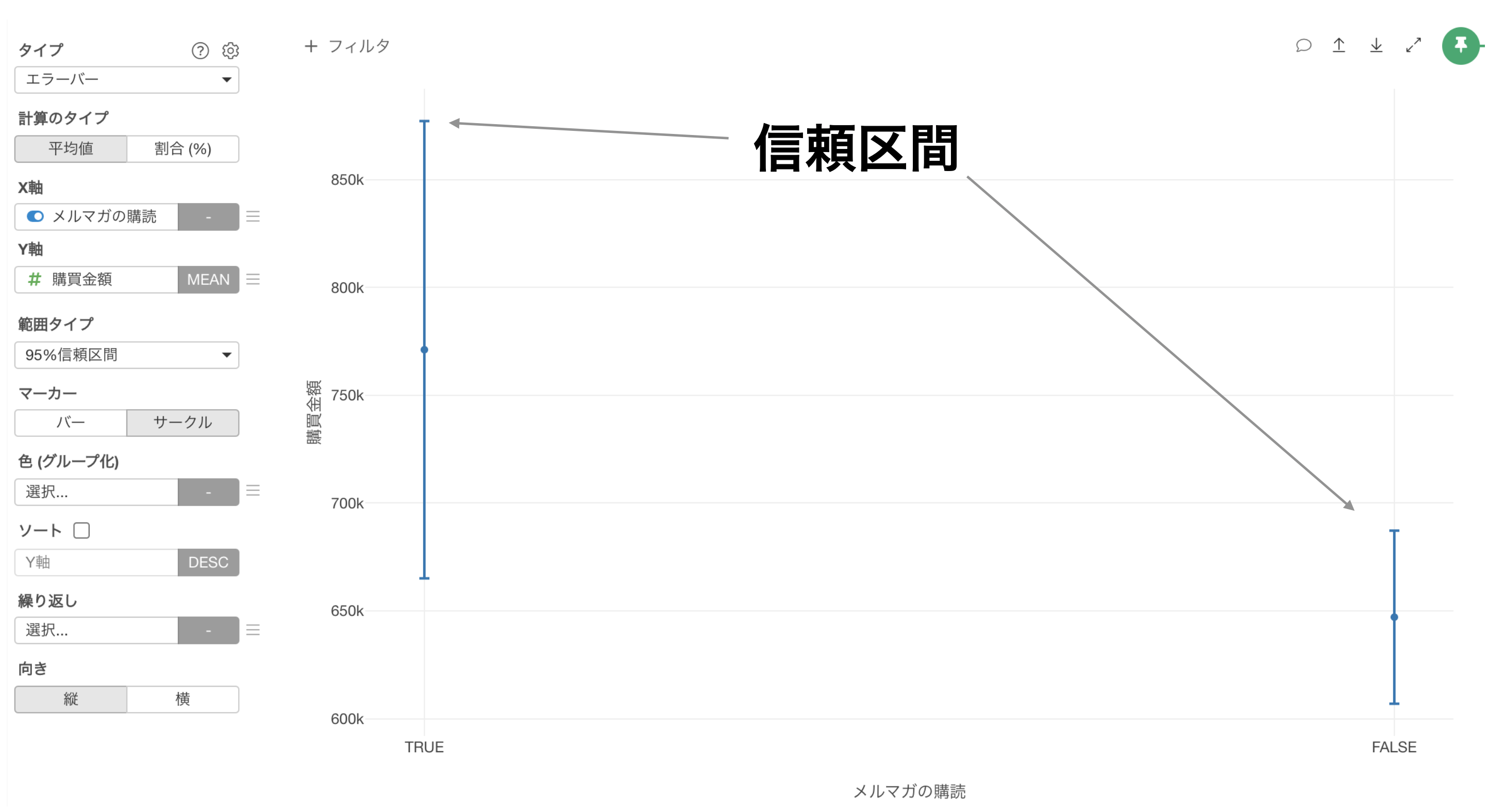
なお、信頼区間の中間にある点は各々のグループの購買金額の平均値を表していて、その上下に伸びているのが購買金額の誤差である信頼区間になります。
各グループの平均購買金額だけを比較すると、メルマガに購読している人の方が平均購買金額が高いので、メルマガの購読者を増やして、平均購買金額を高めようと考えてしまうこともあるかもしれません。
しかし、今回のエラーバーではメルマガに購読してる人と、そうでない人で購買金額の平均値の信頼区間の範囲に重なりがあるので、2つのグループの平均購買金額は同じような値を取り得る、と解釈できるため、メルマガの購読者を増やしたとしても、全体の購買金額が上がるとは限らないということを、エラーバーから理解することができます。
逆にもし両者の信頼区間に重なりがない場合は、両者の間に意味のある違いがあると考えることができるわけです。
このように、信頼区間を利用することで、データのばらつきや量を気にすることなく、異なるグループの間に注目すべき差があるかを調べられるようになるので、データから適切な気付きを得ることができるようになります。
なお、Exploratoryでは、UIから数クリックでエラーバーを作成することができます。エラーバーの詳しい説明や、作り方を知りたい方は、こちらのセミナーで詳しく紹介をしていますので、よろしければ、ご参考ください。
3. 相関と因果関係
多くの場合、データの可視化の目的は2つの変数の間に関係があるかを調べることにあります。
また変数間の関係には、「一方が上がると、もう一方も上がる」ような「相関関係」と呼ばれる特殊なパターンがありますが、相関関係を見つけることができれば、そのことによって値がどう変わるのかを説明できるだけでなく、片方の値が分かれば、もう片方の値を予測できるようにもなるため、可視化を通してデータの中に隠れた相関関係を見つけて、ビジネスの改善のヒントを得ようとすることも少なくありません。
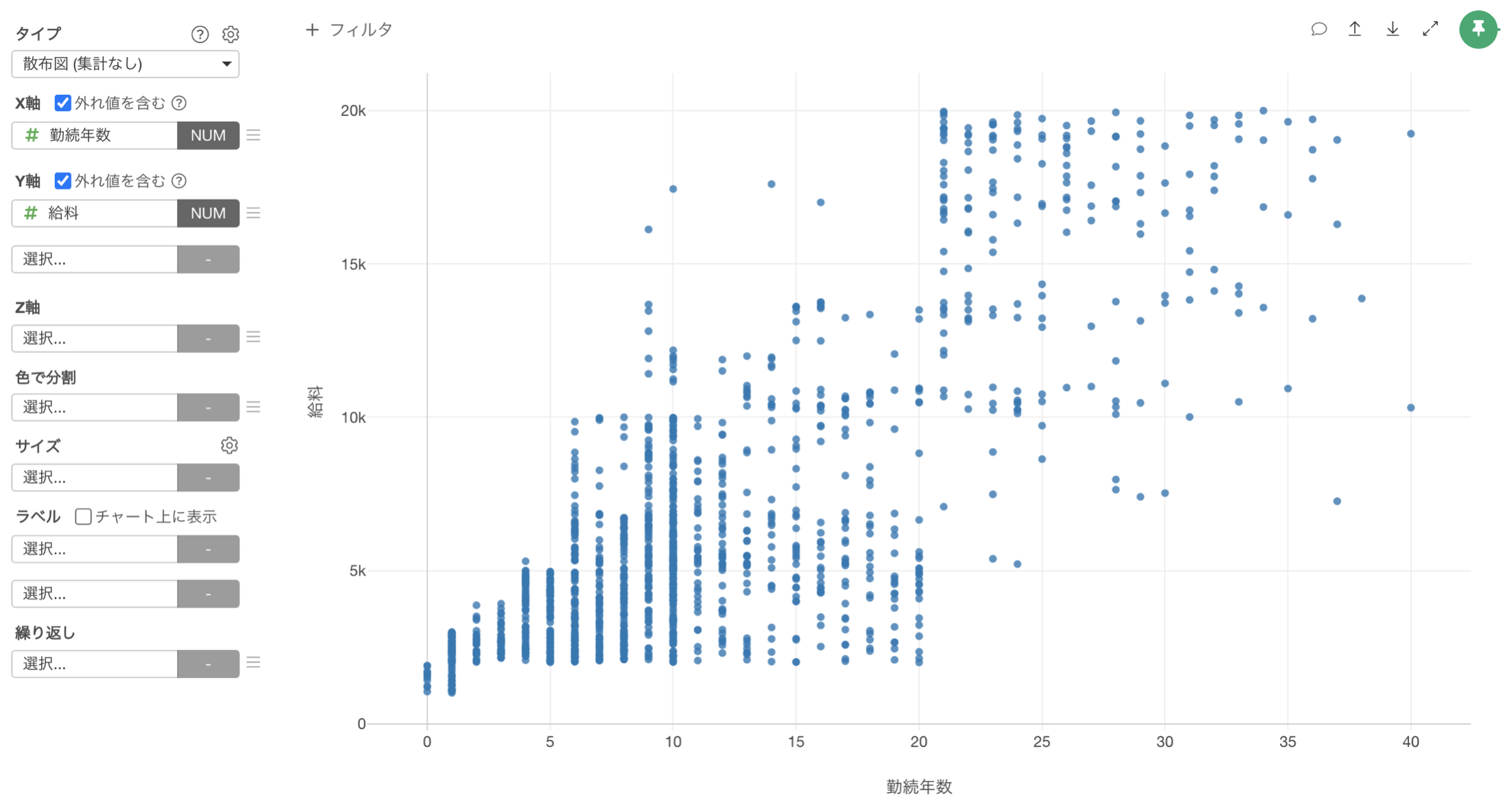
しかし、列の数が増えれば全ての組み合わせを可視化して調べることは大変ですし、見落としも出てくることになります。
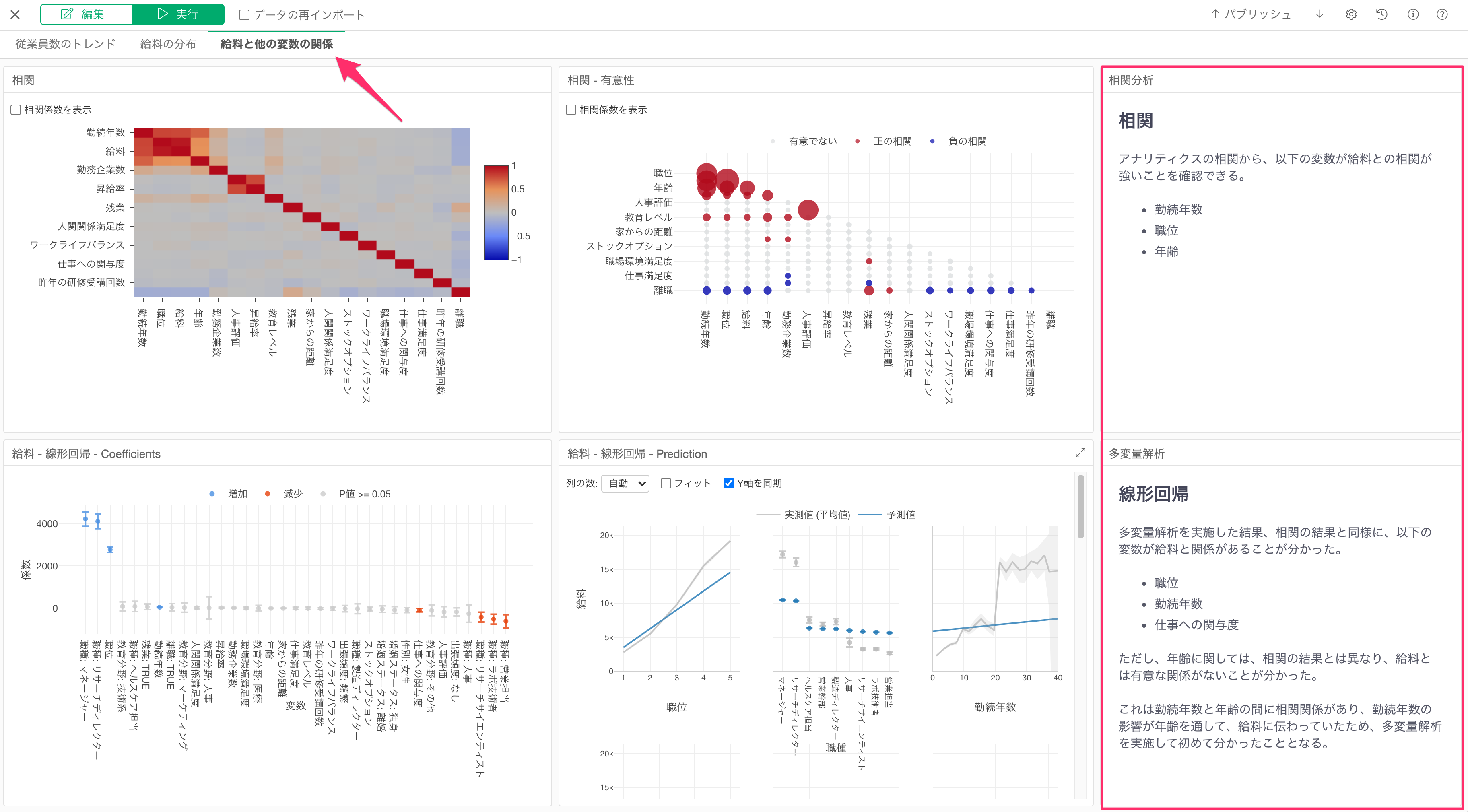
そこで、Exploratoryでは相関のアルゴリズムを使って、全ての変数の組み合わせの相関を一気に調べることができるだけでなく、
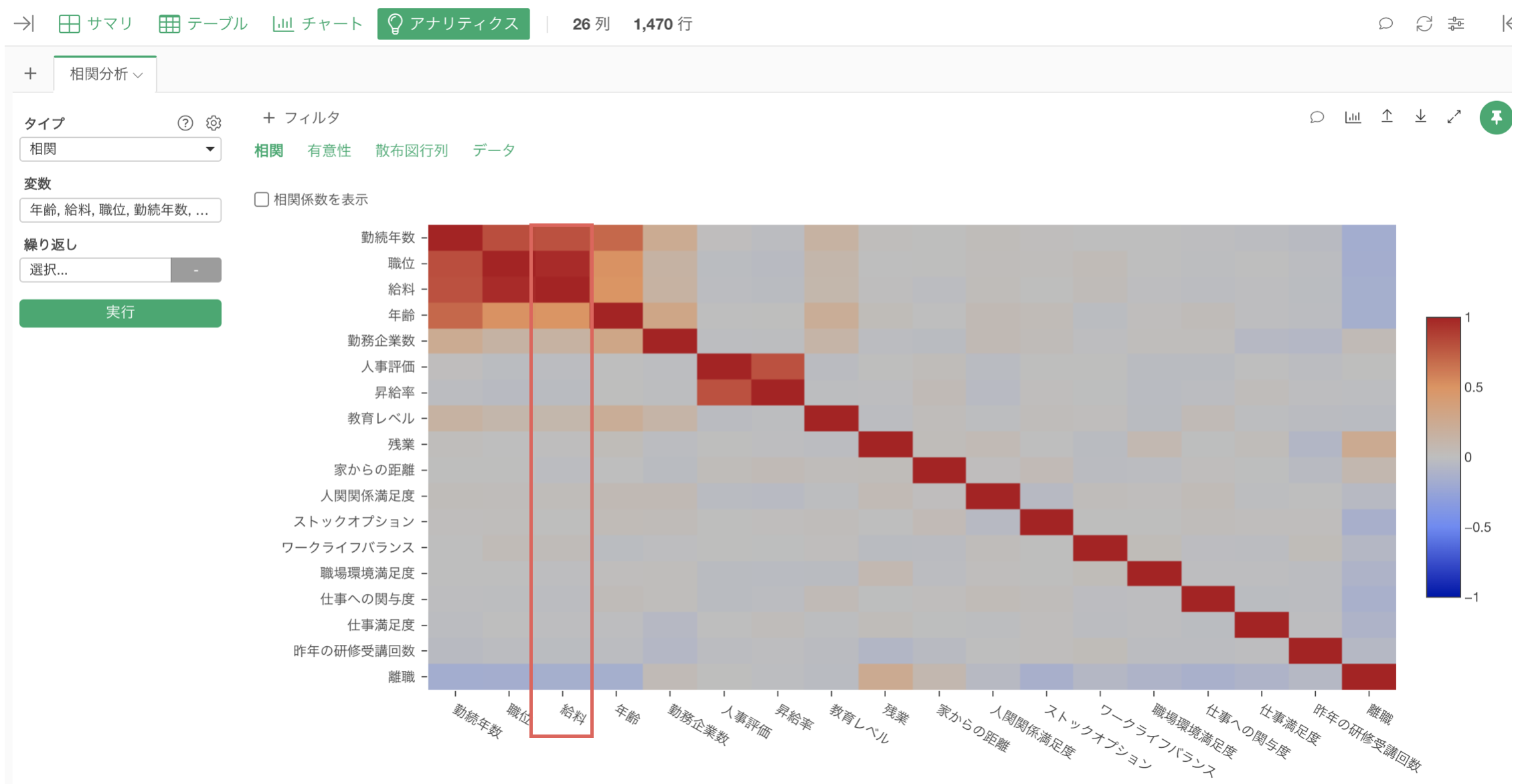
相関モードなどを利用して、相関が強い変数を探索的に調べて可視化することができます。
しかし、ここで気を付けなくてはいけないことがあります。
それは相関関係と因果関係は異なるということです。
相関関係を因果関係と勘違いしてしまうときの問題
以下のチャートはサメの襲撃件数とアイスクリームの売上を日ごとに可視化したものになります。
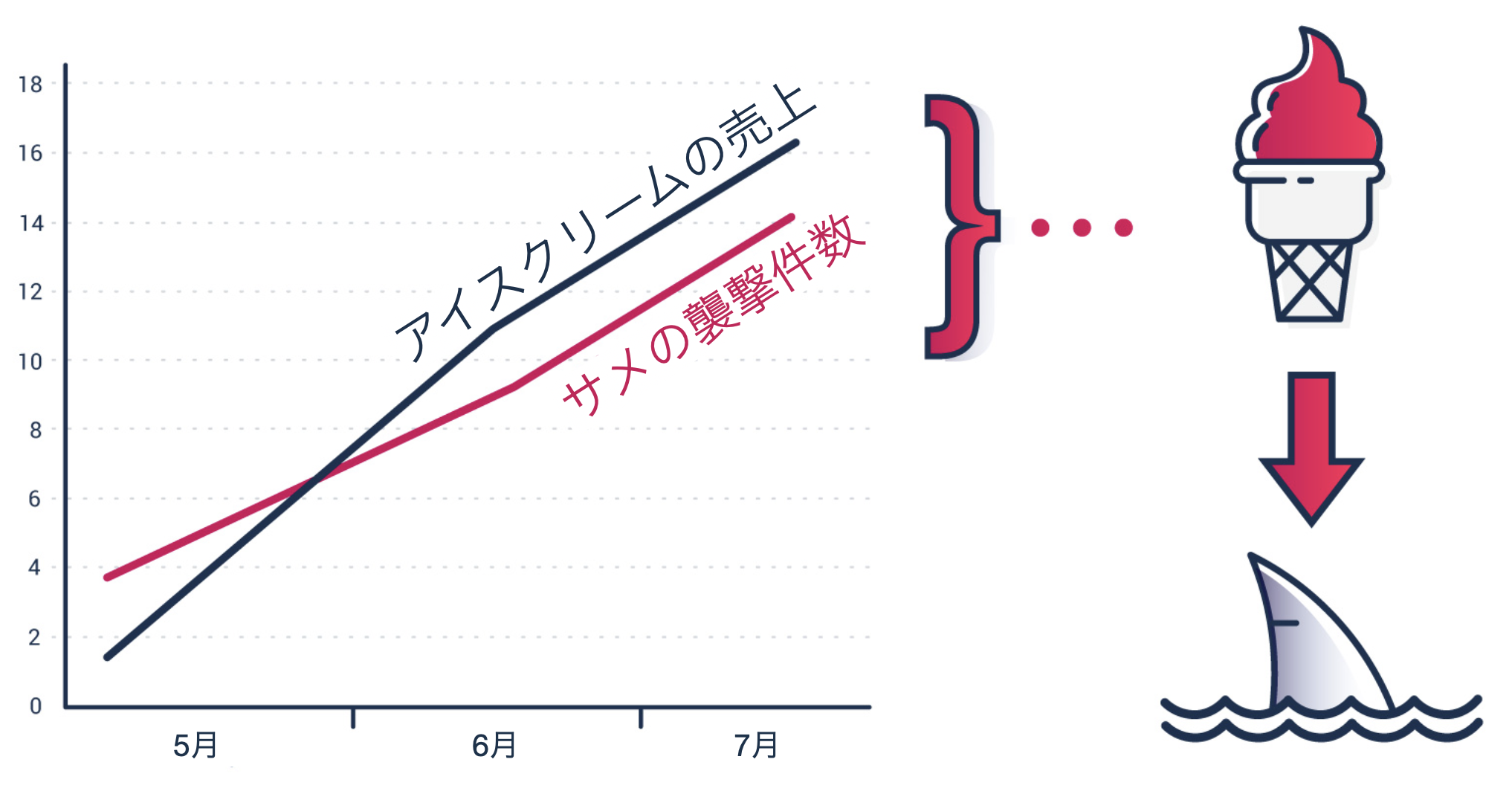
このようなチャートからは、アイスクリームの売上が増えると、サメの襲撃件数が増えるような相関関係を読み取ることができます。
しかし、実際のところ、アイスクリームの売上が増えると、サメの襲撃件数が増えるような関係や、その逆の関係があるとは考えづらく、夏が近づくに連れて気温が上がるため、アイスクリームを食べる人が増えたり、海に入る人が増えるため、サメの襲撃件数が増えているといったことが想定されます。
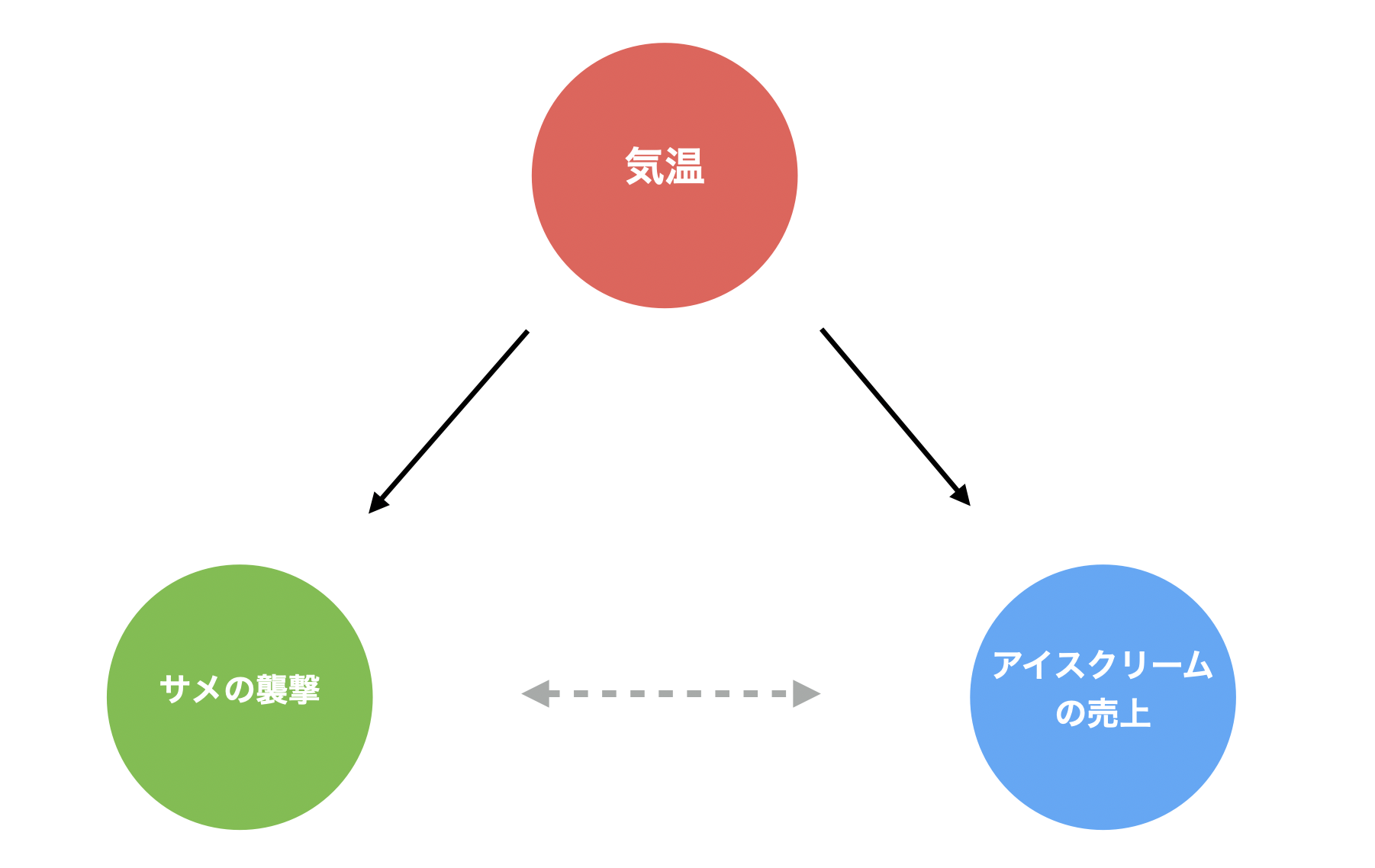
ただし、チャートだけを見ていると、気温が上がるとサメによる襲撃回数とアイスクリームの売上が増えるもような関係があるにも関わらず、気温が上がるとアイスクリームの売上が上がるような関係があるため、その結果として、あたかもアイスクリームの売上が増えるとサメによる襲撃回数が増えるような関係を見出してしまうことがあるわけです。
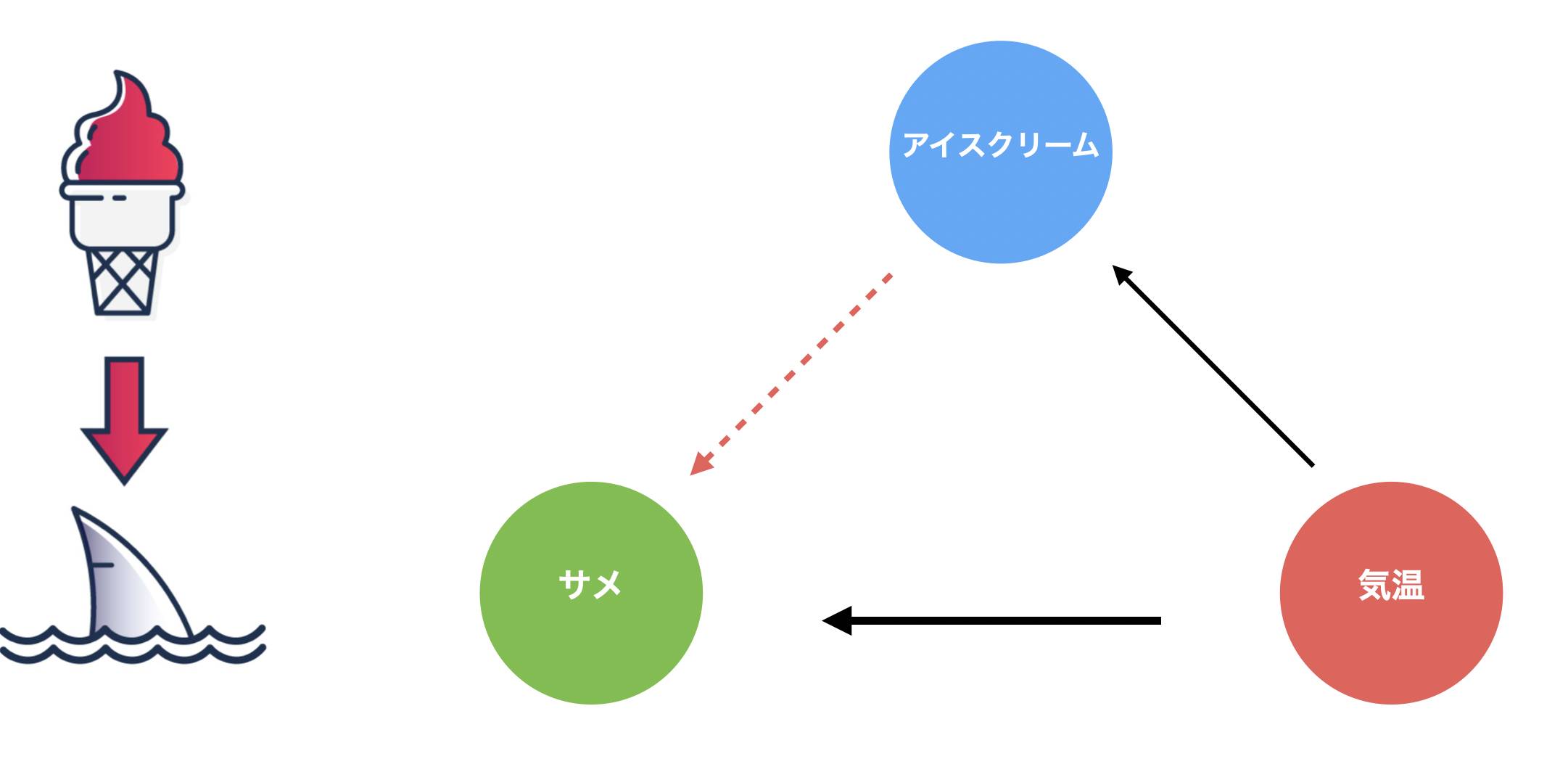
このように、注目した変数間の相関関係(アイスクリームの売上とサメの襲撃件数)の両者に影響する変数(気温)が存在するような関係を「交絡」と呼びます。
今回の例で言いますと、アイスクリームの売上が増えることでサメの襲撃件数が増えるような関係がないことは常識的に考えれば分かりますが、ビジネスの変数に変数が置き換わったり、扱う変数が増えていくと、こういった交絡に気付かず、誤った因果関係を自分の頭の中に描いて、不適切な行動を起こしてしまう(例: サメの襲撃件数を減らすために、アイスクリームの販売をやめてしまう)ことも生じます。
交絡を取り除く分析手法:多変量解析
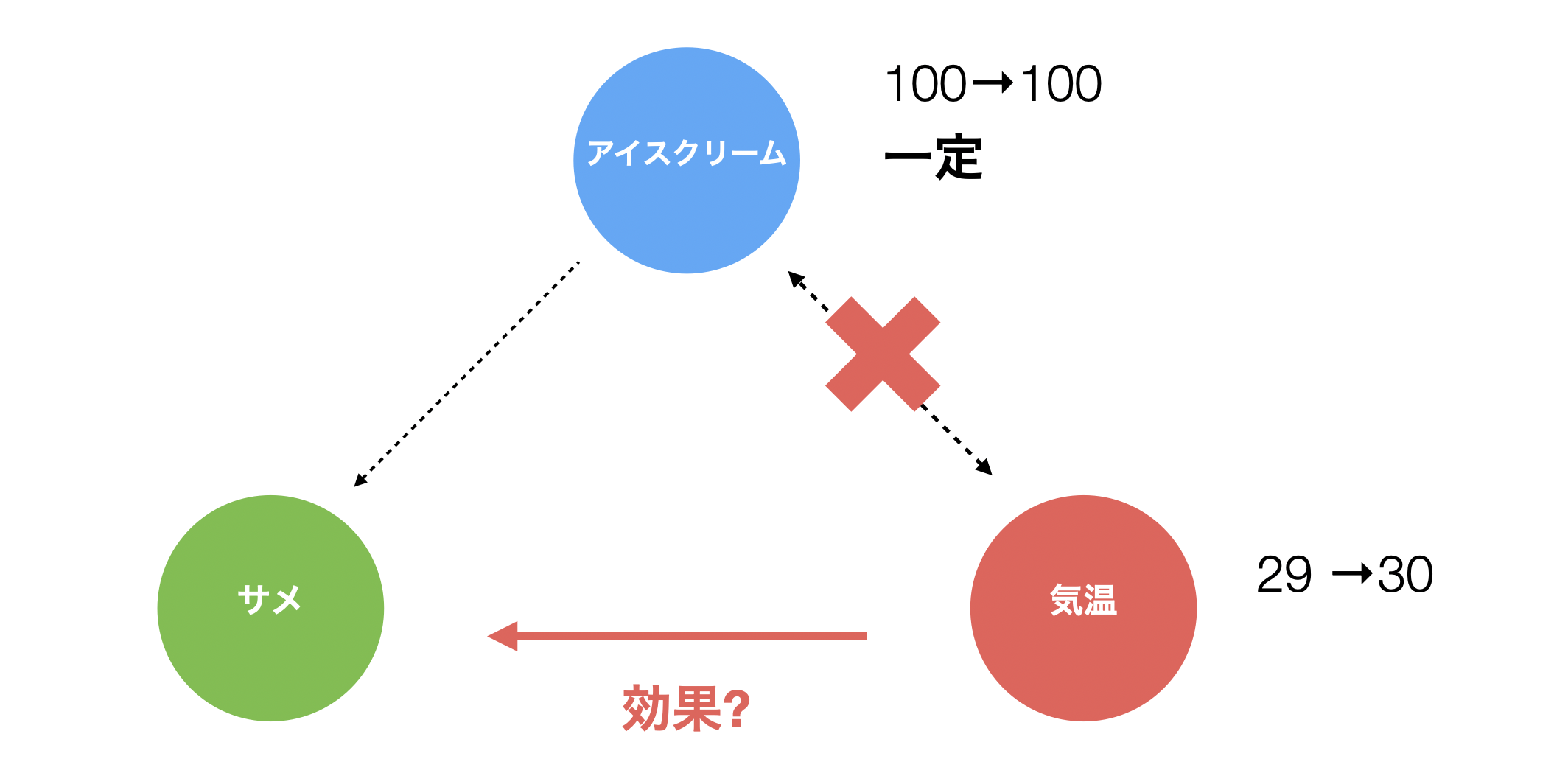
では、どうすれば、このような交絡を見抜くことができるかと言いますと、「1つの変数のみを変化させて、他の変数を一定に保ったときに、それでも注目している変数は変わるのか」を調べれることで交絡に気付きやすくなります。
例えば、アイスクリームの売上は一定で、気温だけが変わったときに、サメの襲撃回数が実際に変化したかどうかを調べて、サメの襲撃回数が増えるようであれば、気温がサメの襲撃回数に影響を与えていると考えることができます。
逆に、気温が同じ日にアイスクリームの売上が変わったとき、サメの襲撃回数が実際に変化するかどうかを調べて、サメの襲撃件数が増えるようであれば、アイスクリームの売上がサメの襲撃回数に影響を与えていると考えることができます。
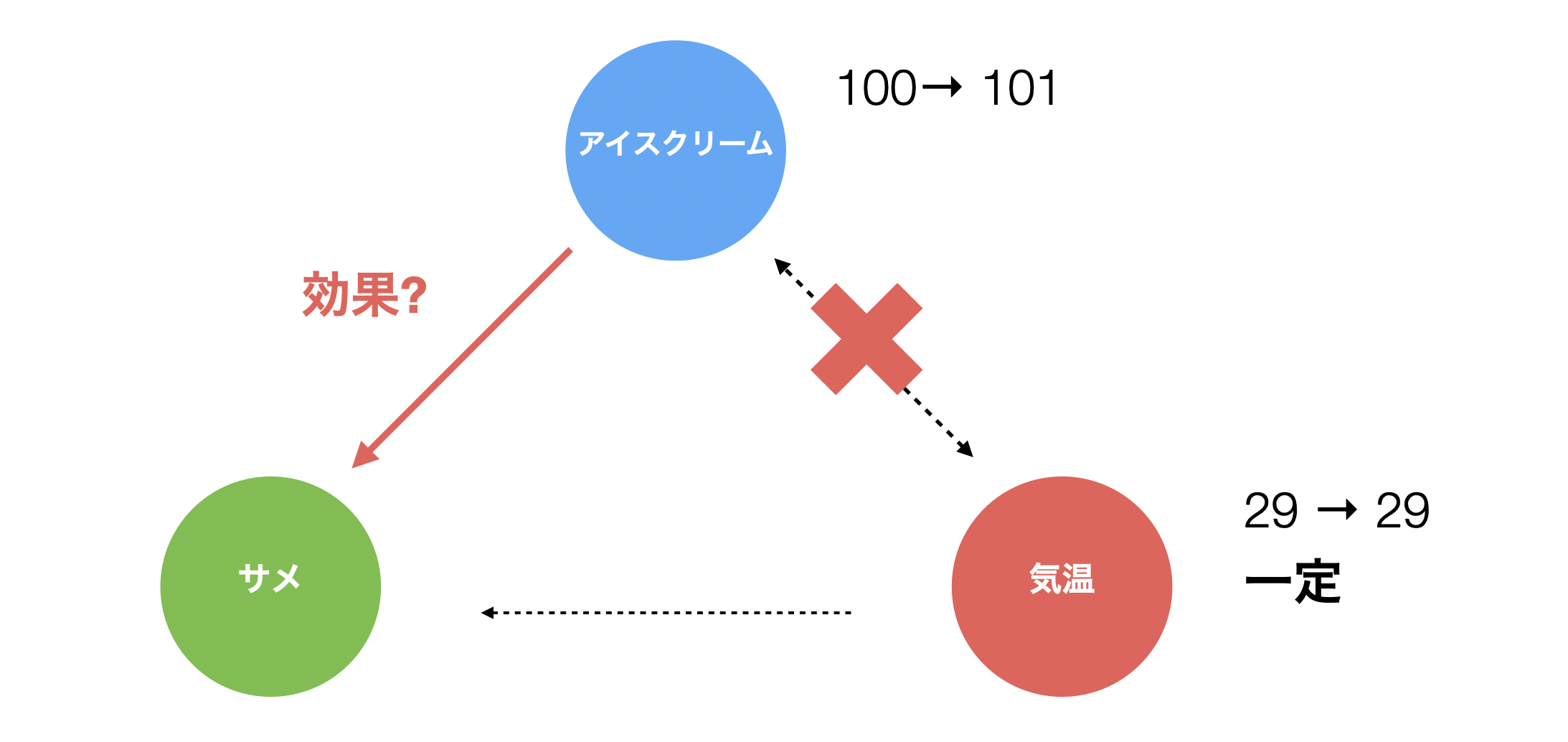
そして、このようなことは「多変量解析」という分析手法を使うと、調べていくことができます。
回帰分析のアルゴリズムを利用すると、「多変量解析」を行うことができ、Exploratoryでは、回帰分析のモデルをUIから実行して、他の変数の値が一定だったときの効果を調べて、因果関係に近づき、誤ったアクションを防いだうえで、ビジネスの指標をコントロールできるようになるわけです。
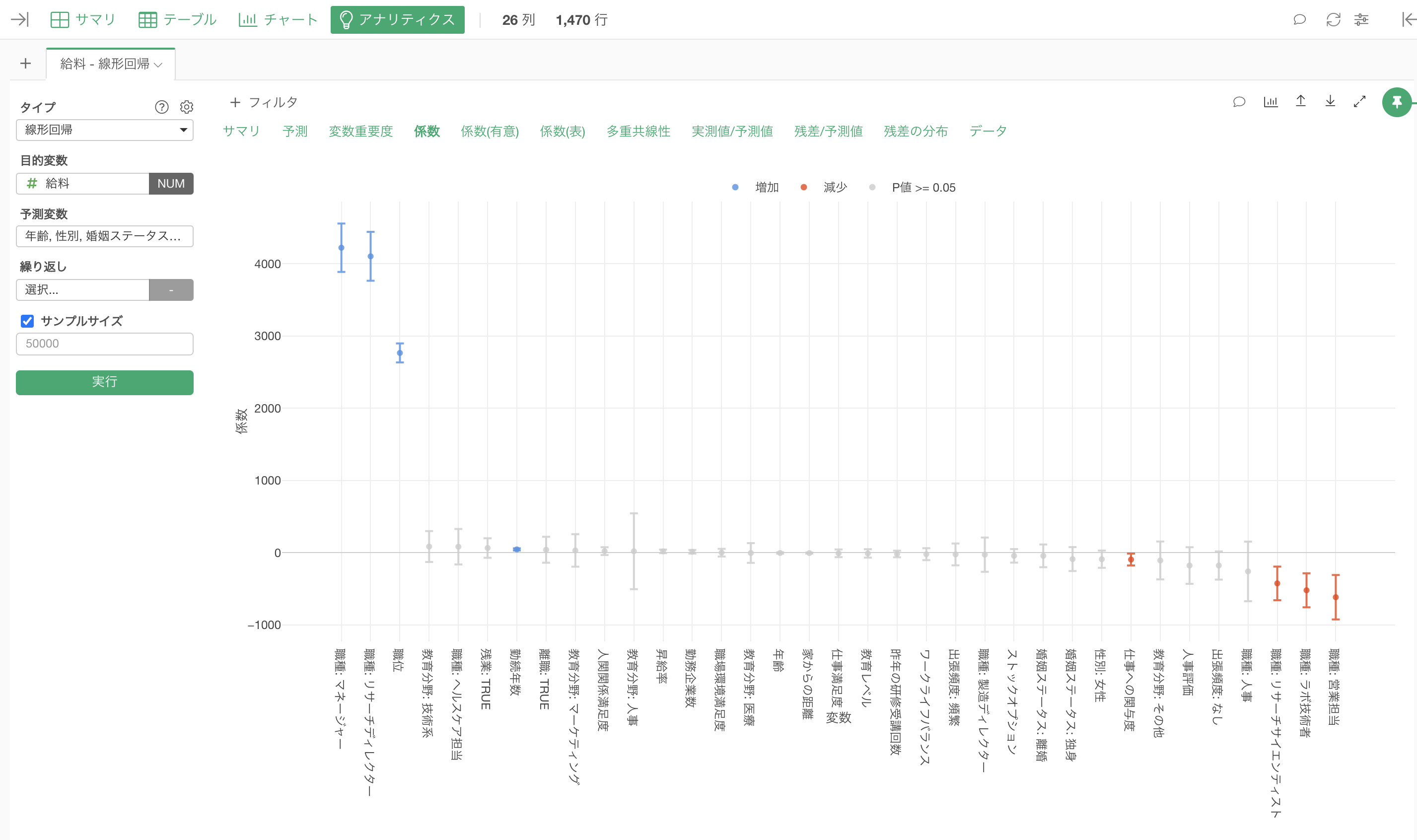
なお、相関と因果関係や多変量解析については、以下の無料セミナーで詳しく紹介をしていますので、よろしければ、ご参考ください。
4. コラボレーション
多くの場合、作成したダッシュボードはWebやファイル形式で関係者に共有されることになります。
ただし、ダッシュボードは一度共有したらそれで終わりということはなく、多くの場合、ダッシュボードで見たいチャートやデータは、人によって異なってきますのでダッシュボードの作成者には多くのアップデートの依頼が集まることになります。
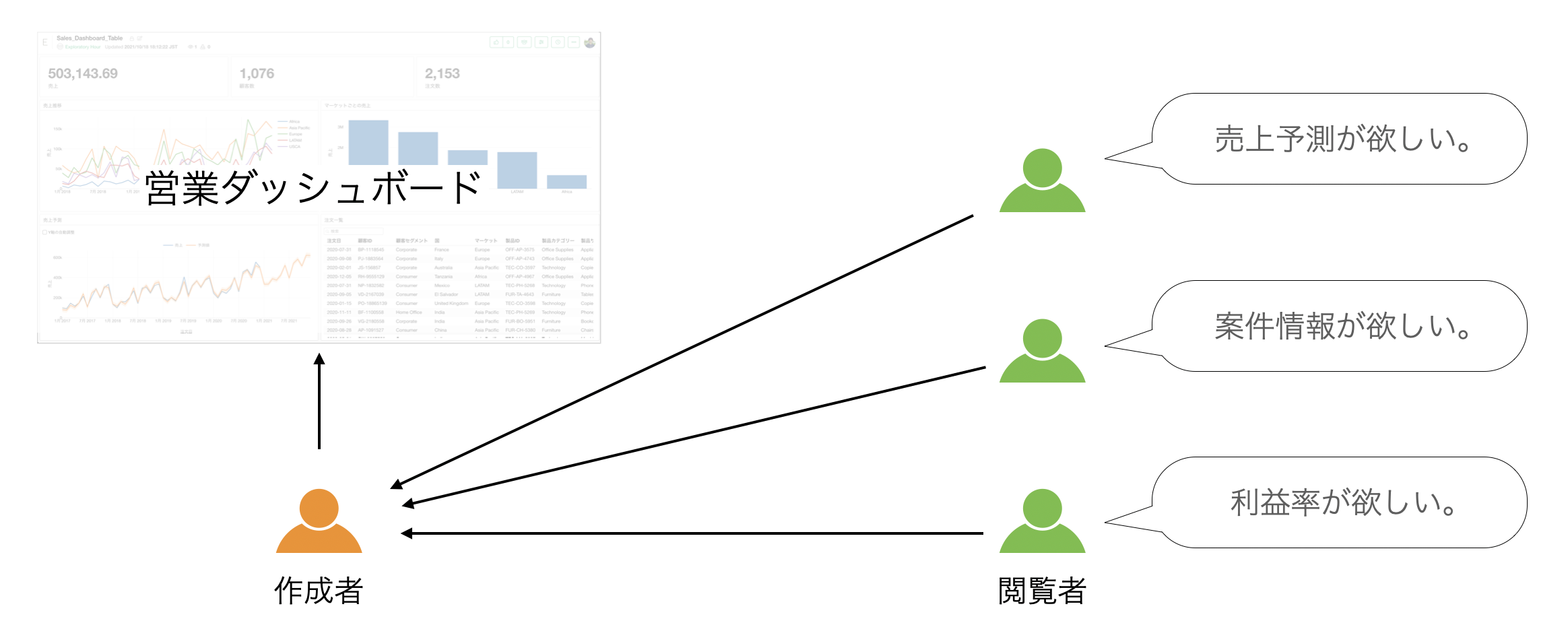
コラボレーションをできないときの問題
ダッシュボードの閲覧者が増え、リクエストが増えること自体は、データの活用が進んでいるという点において喜ばしいことですが、ダッシュボードの閲覧者が増えるほど、ダッシュボードに対するリクエストは増えるため、個人がダッシュボードを編集していると、閲覧者が増えるほど、様々なリクエストに対して迅速な対応ができなくなり、その担当者がボトルネックになってしまいます。
このような問題は、ダッシュボードの管理や編集をチーム単位でできれば解決できます。
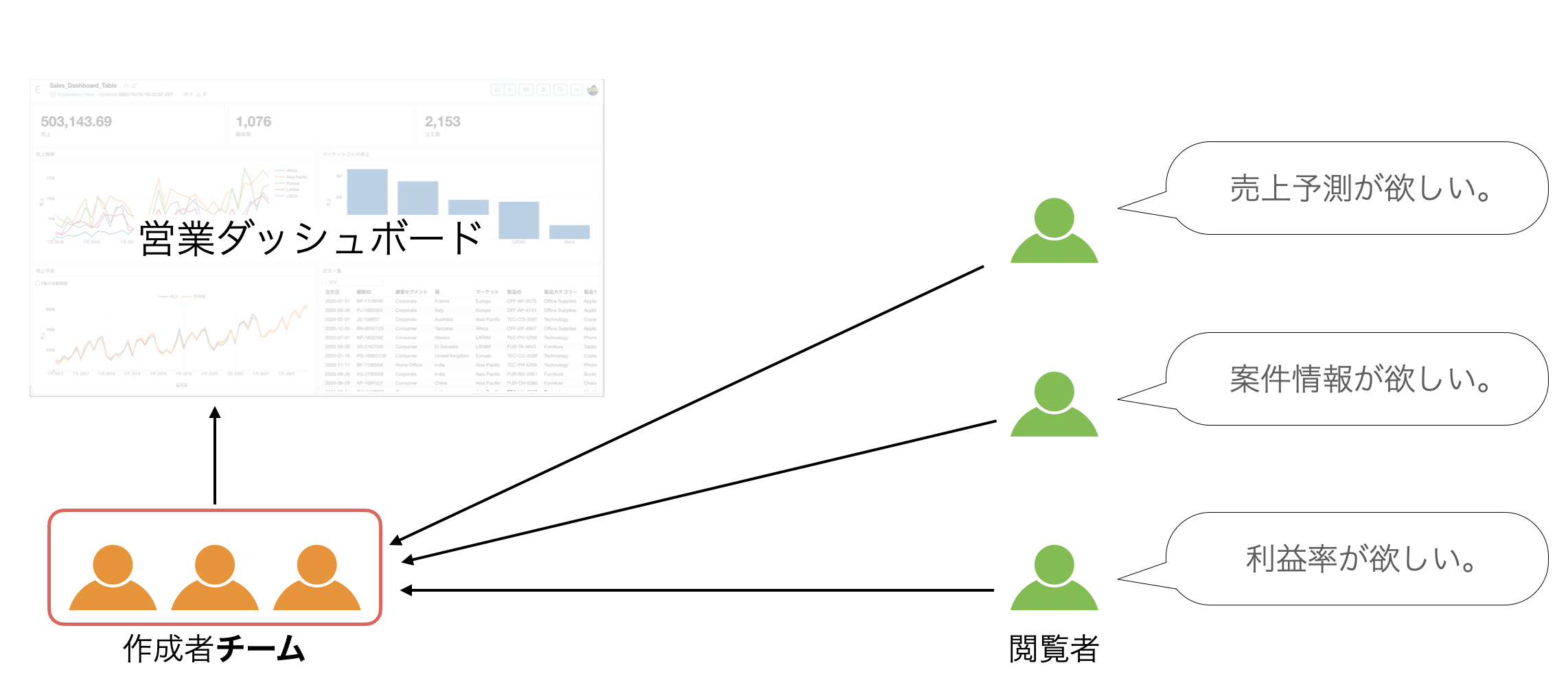
ただし、ダッシュボードを複数人で編集する権限を持っているだけでは不十分で、ダッシュボードをチームで管理・編集していくためには、ダッシュボードを作るために必要なデータ、その加工のプロセス、作成したチャートがチームに共有されていないと他の人の業務を引き継いだり、他の人に業務を効率的に引き継ぐことができません。
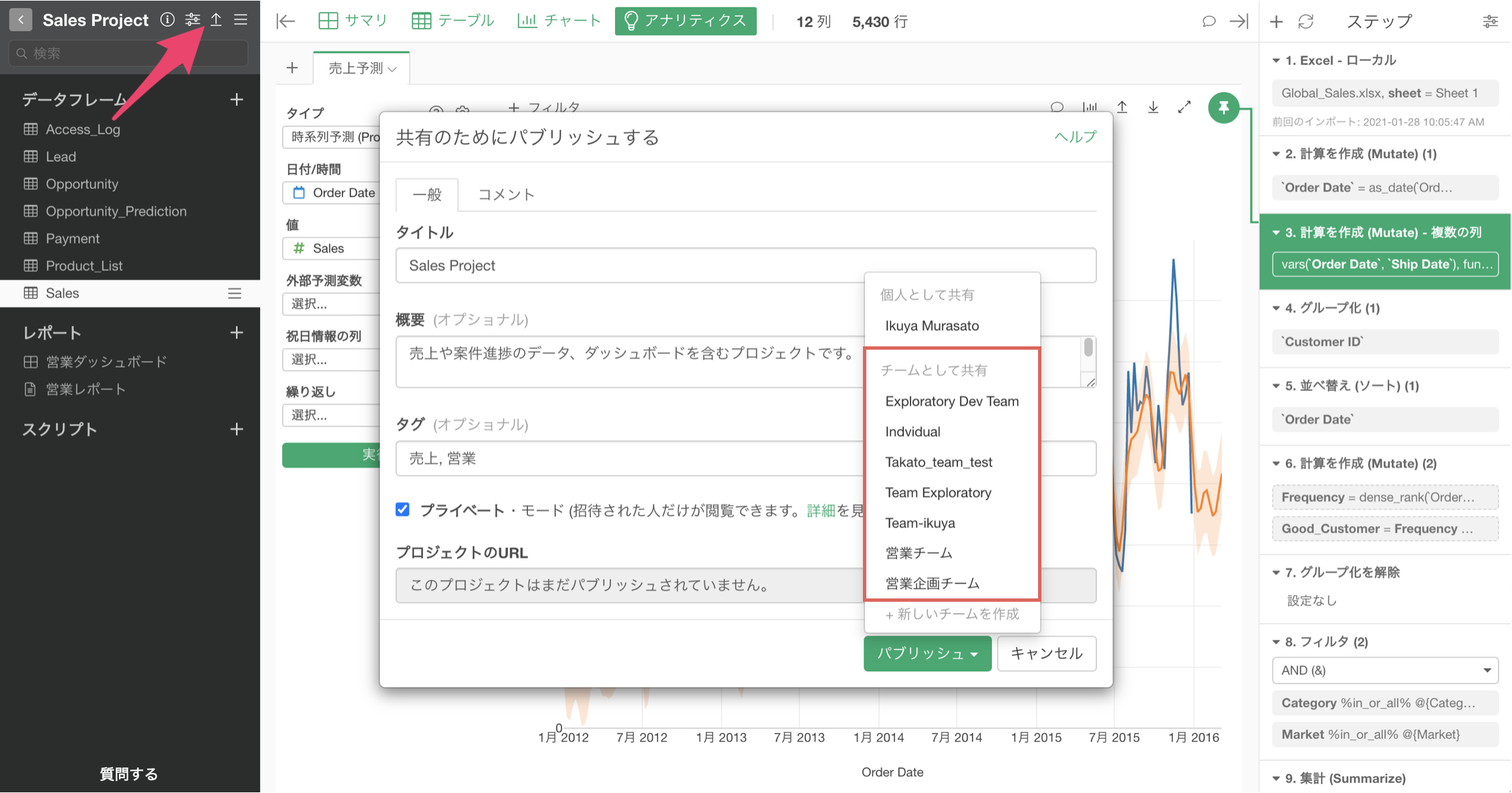
そこで例えば、Exploratoryでは、ダッシュボードをチームで管理するために、ダッシュボードや、その元となるデータやチャートを含む「プロジェクト」をチームとしてパブリッシュし、共有・編集していくことが可能です。
Exploratoryを使ったコラボレーションに興味がある方は、以下の無料セミナーで詳しく紹介をしていますので、よろしければ、ご参考ください。
5. BI ≠ ダッシュボード
ダッシュボードは、指標やトレンドをモニターすることには適していますが、一方で、分析の結果から分かったことを効果的に伝えることには向いていない面があります。
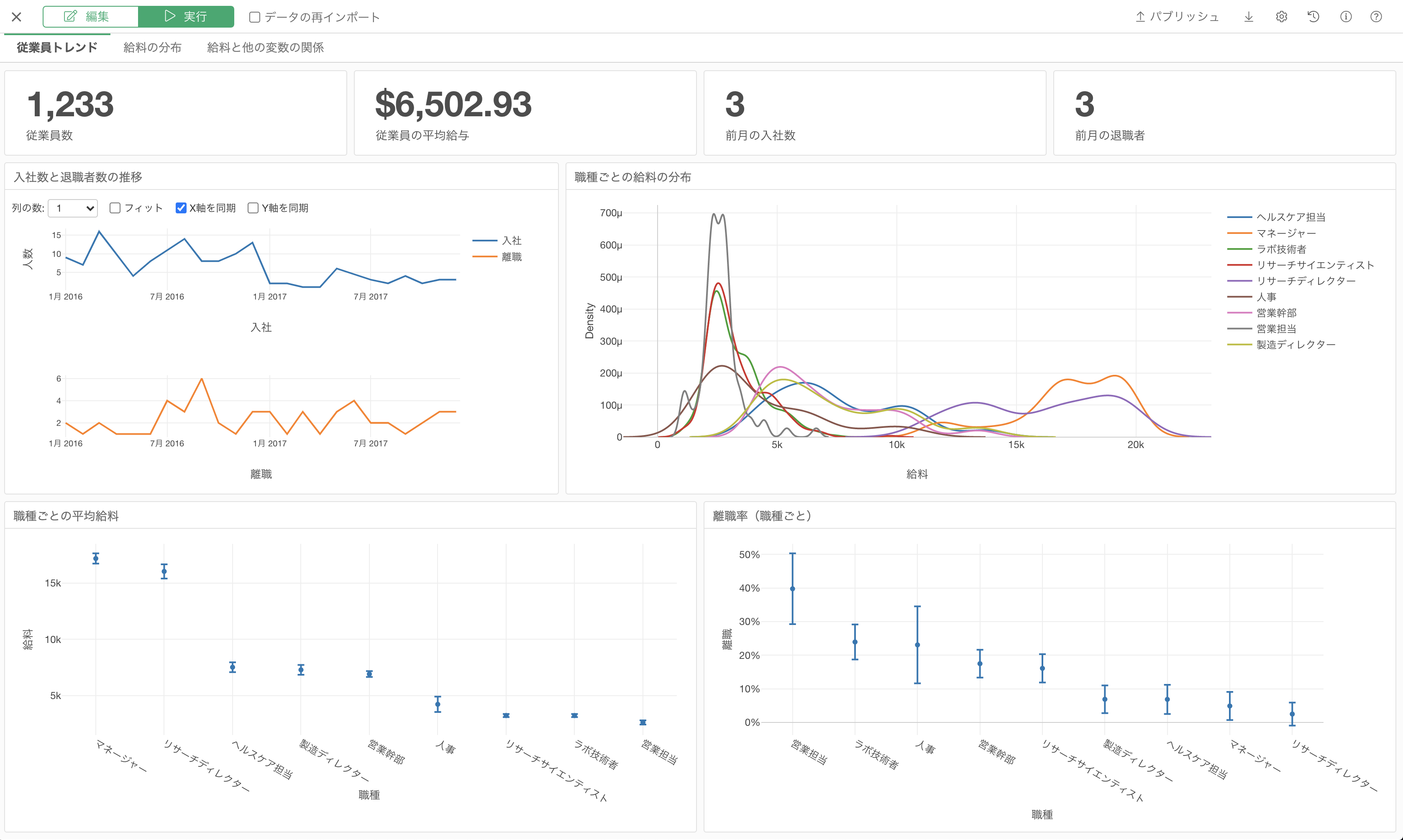
もちろん、テーマごとにダッシュボードのページを分けて、データから分かることを整理したり、ダッシュボードにテキストボックスを追加して、ダッシュボードの内容に関する説明を追加することは可能です。
ただし、ダッシュボードの場合、1つ1つのチャートを順を追って説明をして、1つのストーリーやレポートを作っていくことには向いていないため、そういったニーズに対しては、多くの場合、パワーポイントやワードなどのBIツールとは異なるレポーティングツールを使っていくことになるかと思います。
そういったときに問題になるのは、作成したチャートの画像を書き出して、レポートツールに貼り付ける手間です。
また、レポートを作成する過程で、データやデータ加工に誤りがあったことに気付いた場合、BIツールに戻って修正をして、またチャートの画像をエクスポートをして、といった具合に作業が煩雑になってしまいます。
そういった手間を解決できるように、Exploratoryでは、ダッシュボードだけでなく、「ノート」形式のレポートも作成できるようになっています。
ノートもダッシュボードと同じように、様々なデータ加工のステップに紐付けられた複数のチャートを1つのレポートとしてまとめることが可能です。
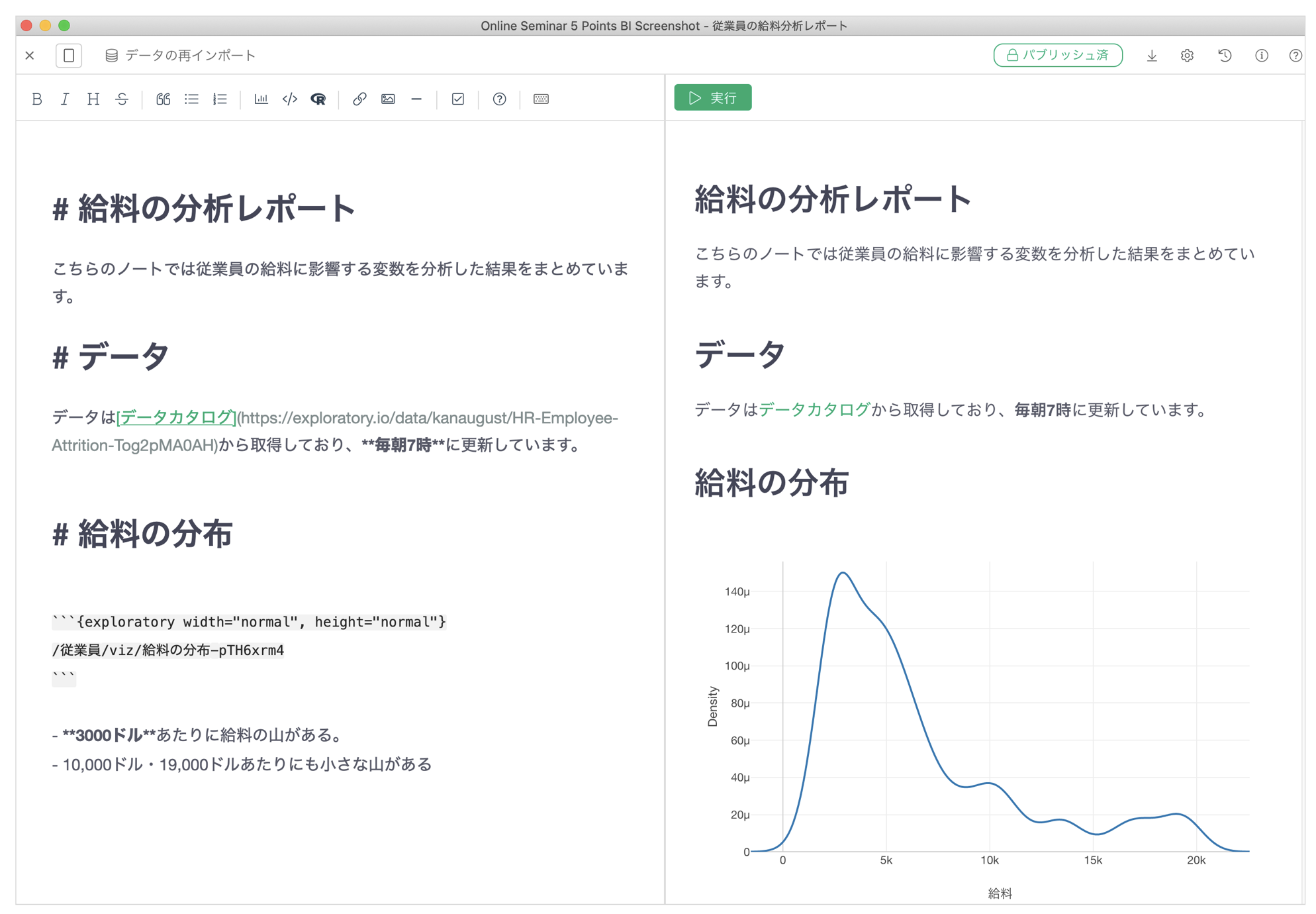
なお、ノートでは作成したチャートやアナリティクスをまとめるだけでなく、見出しを設定したり、テキストのフォーマットを変更して、ストーリーを伝えやすい形で、レポートを作成していくことが可能です。
自分達のデータで試して見たい!
今回は、BI/ダッシュボード導入を成功に導くための5つのポイントを紹介しましたが、実際にExploratoryを使って、自分達のデータを使ってBI/ダッシュボードを構築したい方は、30日間の無料トライアルができますので、こちら、または下記のリンクより無料トライアルをお試しください!