概要
Jason先生がきれいに、かつ実用的にまとめられていたので要所を備忘録として残す。本当はこれを紹介する程度にするつもりだったけど、データ前処理にハマったのでタイトルに変更した。
後日、グリッドサーチやBayesian Optimizationを投稿する。
- 実施期間: 2021年9月
- 環境:Colab
- パケージ:XGBoost
Gradient Boosting Decision Tree (GBDT)
Trainingにおいて、勾配降下法(GD)で目的関数の値(Loss)が小さくなるよう、数値最適化で弱いdecision treesを直列につないでいくアルゴリズム。DNNにおいてEpochが進むように、弱いdecision treeが追加されていく。どれくらい追加するかなどはハイパパラメータとなる。
要素としては下記となる。
- 最適化する目的関数としての損失関数:Classificationではcross entropy、RegressionではMSEなどが使用される
- 予測する弱いdecision tree:直列に複数連なったdecision treeで予測する
- 加算モデル:Lossが小さくなるように逐次decision treeが追加されていく。
以前のdecision treesの残留Lossが小さくなるように次のdecision treeが追加される。Lossを小さくするために以前のdecision treesが変更されることはなく、積み重なっていくだけ。
XGBoost (eXtreme Gradient Boosting)
GBDTの実装の一種類で、特に高速化のため下記の機能が実装されている。
- Trainingにおいて、全CPUコアを使用する並列処理
- クラスタ化されたPCを使用した分散処理
- datasetが大きくメモリに乗らない場合はOut-of-Core処理(外部記憶から適宜読み込み)
- データ構造のキャッシュ最適化
ただ、XGBoostよりもLoghtgbmはさらに高速化がなされている。
XGBoostはColabは最初からインストール済みだが、Colabでなければ下記でインストールできる。
# 標準Pythonなら
pip install xgboost
# Anacondaなら
conda install -c conda-forge xgboost
Dataset
今回使用するデータは米国のピマ・インディアンの血を引く21歳以上の女性について、糖尿病の陽性陰性を調査したも
下記から入手可能
各列の説明
- Pregnancies: 妊娠の回数
- Glucose: 経口ブドウ糖負荷試験における2時間後の血漿グルコース濃度
- BloodPressure: 拡張期血圧(mmHg)
- SkinThickness: 上腕三頭筋皮弁の厚さ(mm)
- Insulin: 2時間値の血清インスリン(μU/ml
- BMI: 肥満度指数(体重(kg)/(身長(m))^2
- DiabetesPedigreeFunction: 糖尿病の血統機能
- Age: 年齢(歳)
- Outcome: クラス変数(0:陰性(500個)、1:陽性(268個))
合計768個のデータが十分かわからないが、positive/negativeがimbalancedではないので良かった。
Datasetのロード
import pandas as pd
import numpy as np
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
df = pd.read_csv('diabetes.csv')
df.info()

Baseline
Nullはないようなので、このままモデルに入れるとどうなるか見てみよう。
XGBoostモデル用に成形する。
# split data into X and y
X = np.array(df.iloc[:,0:8])
Y = np.array(df.iloc[:,8])
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
Training
整形したtrainデータでまずaccを求め、無調整のXGBoostのbaselineを確認する。
# fit model on training data
model = XGBClassifier()
model.fit(X_train, y_train)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
Accuracy: 75.20%
良くはない。
どのように良くないかわからないので、test datasetを使ってTraining中のacc変動を確認する。metricはerrorとする。
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, eval_metric="error", eval_set=eval_set, verbose=True)
[0] validation_0-error:0.259843
[1] validation_0-error:0.26378
[2] validation_0-error:0.26378
:
[83] validation_0-error:0.212598
[84] validation_0-error:0.208661
[85] validation_0-error:0.204724
[86] validation_0-error:0.212598
:
decision treeが追加されるたびにtest datasetを使ったerrorが低下していっているが、上昇に転じる箇所が確認できる。本番のfit()ではearly stoppingでtreeの追加を止めることとする。metricはloglossとする。loglossが底を打ってから様子を見るため10回までfitは継続させる。
# fit model on training data
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
[0] validation_0-logloss:0.660186
Will train until validation_0-logloss hasn't improved in 10 rounds.
[1] validation_0-logloss:0.634854
[2] validation_0-logloss:0.61224
:
[54] validation_0-logloss:0.463379
[55] validation_0-logloss:0.462555
[56] validation_0-logloss:0.463003
[57] validation_0-logloss:0.462065
[58] validation_0-logloss:0.463195
[59] validation_0-logloss:0.464264
[60] validation_0-logloss:0.464393
[61] validation_0-logloss:0.464292
[62] validation_0-logloss:0.4644
[63] validation_0-logloss:0.464663
[64] validation_0-logloss:0.464624
[65] validation_0-logloss:0.464717
[66] validation_0-logloss:0.465197
[67] validation_0-logloss:0.465055
Stopping. Best iteration:
[57] validation_0-logloss:0.462065
Accuracy: 77.17%
Early stoppingでは改善しなかった。pre-processしなかったので当然データに問題がある。
Feature importance
XGBoostにはどの説明変数を参照していたか確認する機能があるので、現時点のそれを確認する。
from xgboost import plot_importance
from matplotlib import pyplot
_, ax = plt.subplots(figsize=(12, 4))
plot_importance(model, ax=ax,
importance_type='weight',
show_values=True)
plt.show()

説明変数(f0 ~ f7)が見づらいが下記の順である。
['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
簡単のため、early stoppingでtrainしてfeature importanceを描画するまでを関数にして、以降これを使う。
def xgb_train(my_df):
num = len(my_df.columns)-1
X = np.array(my_df.iloc[:,0:num])
Y = np.array(my_df.iloc[:,num])
# split data into train and test sets
seed = 27
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
eval_set = [(X_test, y_test)]
# fit model on training data
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
_, ax = plt.subplots(figsize=(12, 4))
plot_importance(model, ax=ax,
importance_type='weight',
show_values=True)
plt.show()
EDA
初めて使うデータなので説明変数の分布を確認する。
import matplotlib.pyplot as plt
import seaborn as sns
sns.pairplot(df.iloc[:,0:8])
plt.show()
df.iloc[:,0:8].describe()


ありえない説明変数にゼロが散見されるので調べてみる。
clmn = list(df.columns)
for i in clmn:
print(f'{i}: {sum(df[i] == 0)}')

'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI'の5つの説明変数はゼロになりえないのでデータの欠損とみなされ、これらのせいで精度が悪かったのは間違いない。
スポットのヒストグラムで確認する。
df_hist = df.loc[:,['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']]
df_hist.hist(figsize = (8,8), bins=20)

SkinThicknessとInsulinのゼロが特に目立つ。Feature importanceで両方の出現回数が低かったのはこのゼロのためか。
作戦としては次の2つが思いつく。
作戦1. 分布を参考にmeanやaverageで全ゼロを置き換える
作戦2. ゼロを含むデータを容赦なく削除する
作戦1
ゼロの補完
ヒストグラムより分布が左右対象なものは現分布の平均値で置き換え、裾野が片方に伸びたものは現分布の中央値で置き換えることとする。
つまり、'Glucose', 'Insulin'は中央値、'BloodPressure', 'SkinThickness', 'BMI'は平均値で置き換える。
Glucose_median = int(np.median(df[df['Glucose'] != 0]['Glucose']))
Insulin_median = int(np.median(df[df['Insulin'] != 0]['Insulin']))
BloodPressure_ave = int(np.average(df[df['BloodPressure'] != 0]['BloodPressure']))
SkinThickness_ave = int(np.average(df[df['SkinThickness'] != 0]['SkinThickness']))
BMI_ave = np.average(df[df['BMI'] != 0]['BMI'])
print(f'{Glucose_median}, {Insulin_median}, {BloodPressure_ave}, {SkinThickness_ave}, {BMI_ave}')
117, 125, 72, 29, 32.457463672391015
df['Glucose'] = df['Glucose'].replace(0, Glucose_median)
df['Insulin'] = df['Insulin'].replace(0, Insulin_median)
df['BloodPressure'] = df['BloodPressure'].replace(0, BloodPressure_ave)
df['SkinThickness'] = df['SkinThickness'].replace(0, SkinThickness_ave)
df['BMI'] = df['BMI'].replace(0.0, BMI_ave)
clmn = list(df.columns)
for i in clmn:
print(f'{i}: {sum(df[i] == 0)}')
df_hist = df.loc[:,['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']]
img = df_hist.hist(figsize = (8,8), bins=20)
Pregnancies: 111
Glucose: 0
BloodPressure: 0
SkinThickness: 0
Insulin: 0
BMI: 0
DiabetesPedigreeFunction: 0
Age: 0
Outcome: 500

ゼロは取れたが、SkinThicknessとInsulinの分布がいびつで気になる。
Feature importanceがどれだけ改善されるか、これでモデルに入れて精度を確認する。
Training
xgb_train(df)
:
[56] validation_0-logloss:0.44372
[57] validation_0-logloss:0.443915
[58] validation_0-logloss:0.44359
[59] validation_0-logloss:0.445002
[60] validation_0-logloss:0.445071
[61] validation_0-logloss:0.445515
[62] validation_0-logloss:0.446372
[63] validation_0-logloss:0.446125
[64] validation_0-logloss:0.446569
[65] validation_0-logloss:0.445882
[66] validation_0-logloss:0.445944
[67] validation_0-logloss:0.445446
[68] validation_0-logloss:0.444948
Stopping. Best iteration:
[58] validation_0-logloss:0.44359
Accuracy: 79.53%
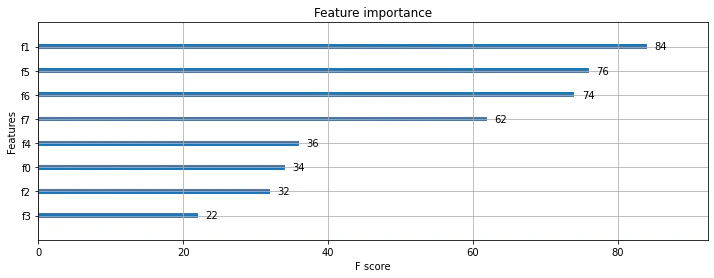
改善効果: 77.17% -> 79.53%
また、Feature importanceは上図となった。説明変数(f0 ~ f7)が見づらいが下記の順である。
['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
SkinThickness(f3)、Insulin(f4)のtree出現回数(参照回数)はbaselineより多くなり改善と言える。
SkinThickness(f3)が22回と低いが、そもそも出現回数の多いBMI(f5)とSkinThicknessに相関があるような気がするので確認する。
print(np.corrcoef(np.array(df['SkinThickness']), np.array(df['BMI'])))
print(np.corrcoef(np.array(df['Insulin']), np.array(df['BMI'])))
[[1. 0.54316229]
[0.54316229 1. ]]
[[1. 0.18016977]
[0.18016977 1. ]]
BMIとSkinThicknessはやや相関はあると言える。そのためBMIに食われてSkinThicknessの出現回数が減ったと思われる。
(Insulin-BMIの相関は参考値)
説明変数からSkinThicknessを除いてもよいのかもしれない。
冗長な説明変数(SkinThickness)の削除
df_copy = df.copy(deep = True)
df_copy = df_copy.drop('SkinThickness', axis=1)
xgb_train(df_copy)
[48] validation_0-logloss:0.444248
[49] validation_0-logloss:0.443776
[50] validation_0-logloss:0.442832
[51] validation_0-logloss:0.443451
[52] validation_0-logloss:0.443629
[53] validation_0-logloss:0.44426
[54] validation_0-logloss:0.44394
[55] validation_0-logloss:0.444451
[56] validation_0-logloss:0.44435
[57] validation_0-logloss:0.446117
[58] validation_0-logloss:0.444625
[59] validation_0-logloss:0.444344
[60] validation_0-logloss:0.443666
Stopping. Best iteration:
[50] validation_0-logloss:0.442832
Accuracy: 80.71%
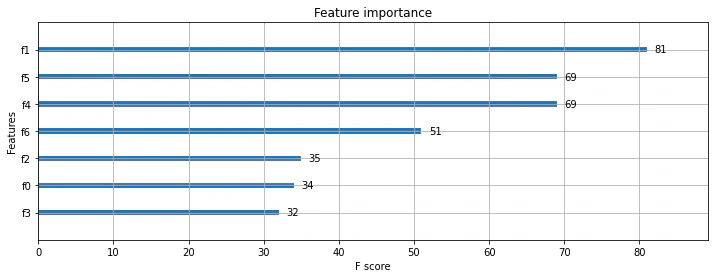
説明変数(f0 ~ f6)が見づらいが下記の順である。
['Pregnancies', 'Glucose', 'BloodPressure', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
さらに良くなり下記である。やはりSkinThicknessは不要だった。
改善効果: 77.17% -> 79.53% -> 80.71%
なんとなく、'Insulin'のゼロの置き換え方がイケてないような気がしてならない。今日はココまでとして他に手法がないか後日調べてみよう。
作戦2
ゼロの削除
まず、SkinThicknessが冗長であることがわかったので、これは使わない。
従い、先の4つの説明変数についてゼロが含まれるデータを削除する。
def multiply_list(lst):
result = 1
for i in lst:
result *= i
return result
df = pd.read_csv('diabetes.csv')
df = df.drop('SkinThickness', axis=1)
arr = np.array(df.loc[:, ['Glucose', 'BloodPressure', 'Insulin', 'BMI']])
df_del = pd.DataFrame(columns=df.columns)
# ゼロでなければ何らかの数値が入っている。
for i in range(len(arr)):
if (multiply_list(arr[i]) != 0):
print(list(df.iloc[i]))
df_del = df_del.append(df.iloc[i])
print(len(df_del))
df_del.describe()
sns.pairplot(df_del, hue = 'Outcome', diag_kind='hist')
plt.show()


データ数は392個に減ってしまったが、分布はとても自然
xgb_train(df_del)
:
[26] validation_0-logloss:0.512833
[27] validation_0-logloss:0.511745
[28] validation_0-logloss:0.510679
[29] validation_0-logloss:0.513842
[30] validation_0-logloss:0.514283
[31] validation_0-logloss:0.516222
[32] validation_0-logloss:0.518303
[33] validation_0-logloss:0.51677
[34] validation_0-logloss:0.514266
[35] validation_0-logloss:0.516112
[36] validation_0-logloss:0.515658
[37] validation_0-logloss:0.518273
[38] validation_0-logloss:0.52124
Stopping. Best iteration:
[28] validation_0-logloss:0.510679
Accuracy: 76.15%

説明変数(f0 ~ f6)が見づらいが下記の順である。
['Pregnancies', 'Glucose', 'BloodPressure', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
baselineよりも悪くなってしまった。データ数が少なくなりすぎたせいだろう。
以上