概要
8月、立て続けにOpenAIからCodexの発表が行われた。遅ればせながらwait listの順番が回ってきたので少し試してみた。
結果からいうと期待以上の出来で、これがまだbetaなのでリリースの完成度が楽しみ。
beta版でも業務で必要で小生の苦手なPythonのlist内包型や少し複雑なSQL文の作成に重宝しそう。実際にそれらも試してみた。
間違いなくStack overflowの投稿回数も大幅に減るだろう。
- 実施期間: 2021年9月
- 環境:OpenAI beta Playground
- パケージ:scikit learn
1. OpenAI Codex beta
ちゃちゃっと調べたことをまとめる。
GPT-3という言語モデルをベースに、Github上ののPythonやその他言語(JSやGoなど)で書かれた膨大できれいなソースを使用してtrainingされたモデルによるサービス。(GithubなのでMicrosoftが絡んでいるのが嫌な感じだが…)
使い方は、PythonのコードからAPIで結果(json)を取得する方法と、Playgroundで文章入力して結果を取得する(text-in, text-out)方法の2通りある感じ。
前者は実際に組み込みに使用できるが使用した文字数に比例するTokenに従い料金が発生するらしい。Codex以外の言語サービスはすでにAPIで提供されていて料金体制も記載あり。
今回お試しする後者のCodex betaについては料金は発生しない(アカウント作成時にカード情報入力なし)が、お試し期間は3ヶ月。小生のコーディング業務サポートであればPlaygroundだけで十分。
なお、OpenAIの利用規約からPlaygroudについては生テキストではなくキャプチャで掲載する。
2. Kmeans + scatter plotコーディング
実力を測るため、みんな大好きアヤメちゃんのクラスタリングをやってもらう。
下図の反転以前が入力した文字で、反転しているのが自動生成されたコード(以降共通)。
出力コードを読んでみると、まず指示通りにクラスタ数は変数n_clustersで渡せるように書かれている点に関心する。
def clustering(data, n_clusters):
驚くべきところは、描画指示に対しクラスタ数を3と決め打ちしているところ。irisが3ラベルあることはML界の常識だが、それを"3"と指定している。
むしろgithubのコードにoverfitしているともいえる。
kmeans = clustering(data, 3)
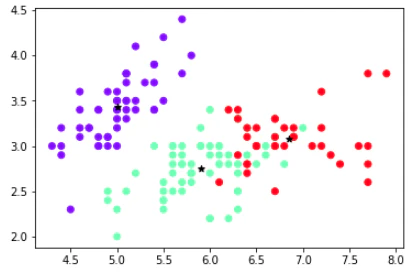
コード部分(一切編集なし)をColabで実行させた結果が下図。
指示しなかったのでfeaturesは4つある内、最初のsepal length, sepal widthが使用され描画させている。
センターの星が黒色になったので、指示に"in yellow"を追加すると驚くべきことに下図となった。
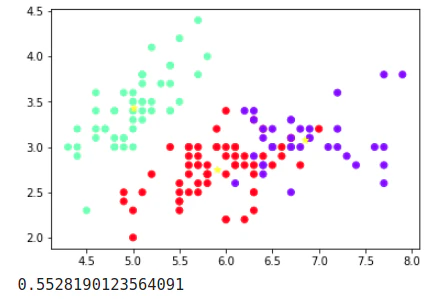
指示にないシルエットスコアを計算している!
【感想】
デフォルトのdavinci-codexでは所望のコードが得られないことが多く、cushman-codexに切り替えると安定した。うまく行かないときはいろいろパラメータを触ってみると良いだろう。
ちろん生成されたコードをそのまま鵜呑みにはできない。まずOverfitが気になるし、指示が長くなることでtrainingで使用される元コードのケースが限定されるので、その品質が問題となる。
それでもコードの全体像をsyntax errorが出ない程度に自動生成してくれるので、出力を手直ししながらコーディングすればかなりの時短になる。
3. デンドログラムに変更
2.で味をしめ、デンドログラムが書けるか指示を変更してみた。
AgglomerativeClusteringを使うかどうか見てみたいのでClusterは指定しない。
人にお願いするときと同程度以上の情報は必要と思うので、先頭行でデンドロ描画が目的でありHierarchicalであることを明示した。
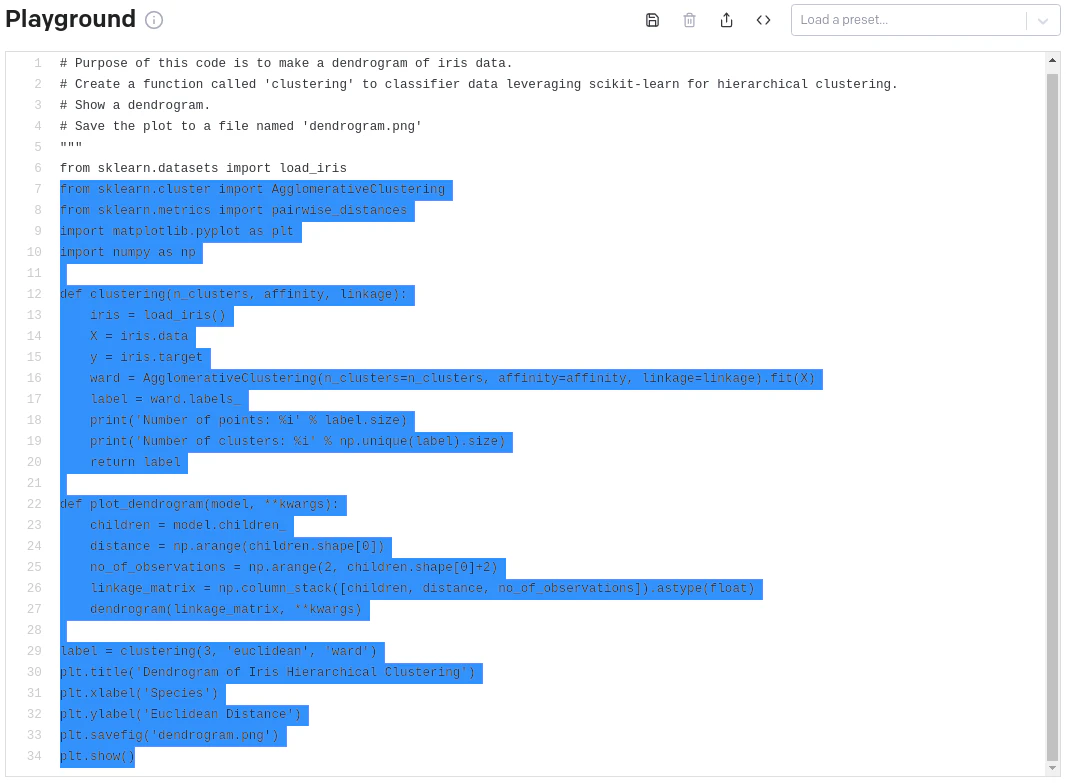
残念ながらコードが足りてないので、手で追加修正したのが下記
# 一箇所目
from scipy.cluster.hierarchy import dendrogram
# 二箇所目
return label, ward
# 三箇所目
label, ward = clustering(3, 'euclidean', 'ward')
plot_dendrogram(ward)
修正し、Colabで確認
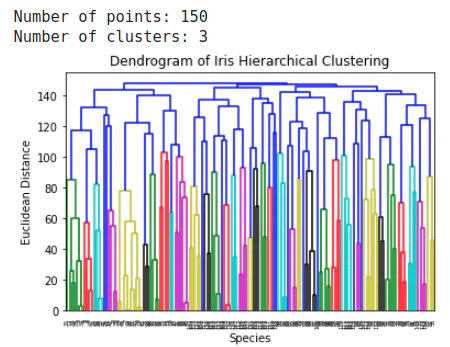
十分だと思うよ。本当に。
4. Kmeans + scatter plotの説明
2.で得たコードを説明してもらう。コードから自然言語に変換する逆パターンもおちゃのこサイサイさぁ〜

- アイリスデータセットの読み込み
- データを3つのクラスターに分類する
- データとクラスター中心をプロットする
- シルエットスコアの算出
そのとおりです。
これらはExamplesを参照すれば、簡単に入力できると思う。
5. listの内包型表記
他言語からPythonに移行した小生にとって内包型にはいつも苦労する(それと文字の正規表現も)。
未熟なオイラの代わりに内包型が出力できるか確認した。こういうやつをいつもStack overflowで教えてもらっている。
恥ずかしながら下記は先週内包型でかけなかったForループで、やっていることはlst1の要素においてlst2中の要素とかぶる要素を取り除くもの。

自分の無知ぶりに恥じ入るばかり。pop()やdel()で取るイメージばかりだったけど、逆にかぶらないものを加えるのね。
書いてもらうと「あぁ、そうだよね。」ってことは多いけど、自分で書くのとは違うもの。
ついでにこの内包型の説明していただくと、

そのとおりです。
5. SQL query
普段簡単なSELECTやINSERT INTO, UPDATE, JOINしか使わないので、先月苦労したのが下記。boss_idをどうやってEmployeeテーブルから取ってくるのかわからなかった。
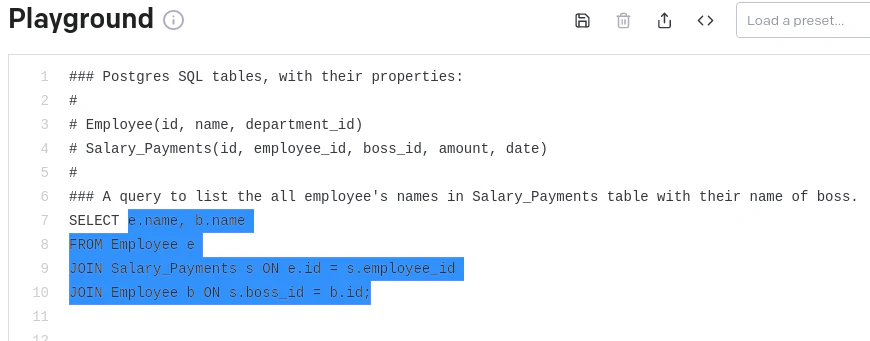
ありがとうございます!
ちなみに下記ではすでにCodex betaを組み込んだベンダーが付加価値をつけたサービスの提供を開始している。
以上