概要
データ前処理用パケージでやや有名なfeature engineの作者の方の講座から、scikit-learnを使用したMissing Data(欠損値のこと)のimputationについて、どんなケースでも使えるように網羅的に要点を抽出し残す。
使用するデータは下記である。説明変数が80個あり、すべてのケースを試すことができる。
- 実施期間: 2022年10月
- 環境:Colab
- パケージ:scikit-learn
1. 概要と処理の流れ
ここではデータの入出力はPandasのDataFrameを使用するものとする。
NaNを置き換える値はTraining用datasetから求める。従い、もしtraining/testにdatasetが別れていないのであれば、置き換え実施前にtrain_test_split()で分けること。
- NaNがランダムに存在
NaNがランダムに存在し、その割合がだいたい5%くらいまでであれば下記の手法で置き換えることができる。ランダムか否かはEDAで各人で判断しなければならない。
- 連続値(numerical value)
ヒストグラムを描き、外れ値を除いた後、平均値、中央値を求めてそれで置き換える
平均値or中央値はその分布から判断する。 - 離散値(categorical value)
最頻値で置き換える
- NaNがランダムに存在していない
NaNがランダムに存在していない、つまり何らか意図を持って欠損している場合
- 連続値
分布が正規分布なら、そのnσ(通常n=3)の値で置き換える
分布が歪んだ分布なら、IRQの1.5倍 or 3倍の値で置き換える
極端に大きな任意の値(999とか-1とか)で置き換える
新しい説明変数で、欠損(True)かそうでないか(False)を示す(indicate) - 離散値
任意の文字列で置き換える
新しい説明変数で、欠損(True)かそうでないか(False)を示す(indicate)
notebookの流れは下記となる。
- csvをDataFrame dataに確保し、種類(後述)ごとに説明変数名をリストにする。
- 種類ごとにEDAして方針決め。EDAが投稿の目的ではないので適当。
- train_test_splitでX_train/X_testに分割
- MissingIndicatorで任意の説明変数について新しい説明変数を追加
- SimpleImputerで任意の説明変数についてそのNaNをEDA方針で置き換え
- すべてをDataFrame化
説明変数の種類は下記としている。
- data.columns
- indicator_cols(欠損か否かを示す新しい説明変数)
- features_categorical (離散値)
- features_categorical_wo_na(NaNがない離散値)<-使わない
- features_categorical_w_na(NaNがある離散値)
- features_numerical(連続値)
- features_numerical_wo_na(NaNがない連続値)<-使わない
- features_numerical_w_na(NaNがある連続値)
- numeric_features_mean(NaNを平均値で置き換え)
- numeric_features_median(NaNを中央値で置き換え)
- remaining_lst(NaNがない説明変数)<-代わりにこっちを使う
使うのは下記の3クラス
引数などの説明はこれらオフィシャルを参照のこと。
2. EDAまで
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.impute import SimpleImputer, MissingIndicator
from sklearn.compose import ColumnTransformer
from sklearn.model_selection import train_test_split
data = pd.read_csv('houseprice.csv') # , usecols=cols_to_use)
print(data.shape)
(1460, 81)
features_categorical = [c for c in data.columns if data[c].dtypes == 'O']
features_numerical = [c for c in data.columns if data[c].dtypes != 'O']
features_numerical.remove('SalePrice')
print(len(features_categorical), features_categorical)
print(len(features_numerical), features_numerical)
43 ['MSZoning', 'Street', 'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'Heating', 'HeatingQC', 'CentralAir', 'Electrical', 'KitchenQual', 'Functional', 'FireplaceQu', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond', 'PavedDrive', 'PoolQC', 'Fence', 'MiscFeature', 'SaleType', 'SaleCondition']
37 ['Id', 'MSSubClass', 'LotFrontage', 'LotArea', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'MasVnrArea', 'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces', 'GarageYrBlt', 'GarageCars', 'GarageArea', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'MiscVal', 'MoSold', 'YrSold']
features_categorical_w_na = list(data[features_categorical].columns[data[features_categorical].isnull().mean()>0])
features_categorical_wo_na = features_categorical.copy() # 使わない
for i in features_categorical_w_na:
features_categorical_wo_na.remove(i)
features_numerical_w_na = list(data[features_numerical].columns[data[features_numerical].isnull().mean()>0])
features_numerical_wo_na = features_numerical.copy()
for i in features_numerical_w_na:
features_numerical_wo_na.remove(i)
print(len(features_categorical_w_na), features_categorical_w_na)
print(len(features_categorical_wo_na), features_categorical_wo_na)
print(len(features_numerical_w_na), features_numerical_w_na)
print(len(features_numerical_wo_na), features_numerical_wo_na)
16 ['Alley', 'MasVnrType', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'Electrical', 'FireplaceQu', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond', 'PoolQC', 'Fence', 'MiscFeature']
27 ['MSZoning', 'Street', 'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'ExterQual', 'ExterCond', 'Foundation', 'Heating', 'HeatingQC', 'CentralAir', 'KitchenQual', 'Functional', 'PavedDrive', 'SaleType', 'SaleCondition']
3 ['LotFrontage', 'MasVnrArea', 'GarageYrBlt']
34 ['Id', 'MSSubClass', 'LotArea', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces', 'GarageCars', 'GarageArea', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'MiscVal', 'MoSold', 'YrSold']
NaNを含む離散値の説明変数について、NaNの割合を見てみる。
data[features_categorical_w_na].isna().mean()
Alley 0.937671
MasVnrType 0.005479
BsmtQual 0.025342
BsmtCond 0.025342
BsmtExposure 0.026027
BsmtFinType1 0.025342
BsmtFinType2 0.026027
Electrical 0.000685
FireplaceQu 0.472603
GarageType 0.055479
GarageFinish 0.055479
GarageQual 0.055479
GarageCond 0.055479
PoolQC 0.995205
Fence 0.807534
MiscFeature 0.963014
dtype: float64
'Alley', 'FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature'の欠損はひどいので特に置き換えは行わず、新しい説明変数(missing indicator)をそれぞれに追加することにする。つまり説明変数が5列増えることになる。
置き換え対象としないので、features_categorical_w_naから除く。
almost_na = ['Alley', 'FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature']
for i in almost_na:
features_categorical_w_na.remove(i)
print(len(features_categorical_w_na), features_categorical_w_na)
11 ['MasVnrType', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'Electrical', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond']
NaNを含む連続値の説明変数について、NaNの割合を見てみる。
data[features_numerical_w_na].isna().mean()
LotFrontage 0.177397
MasVnrArea 0.005479
GarageYrBlt 0.055479
dtype: float64
'LotFrontage'は少しNaNが多いがとりあえず3つとも置き換え対象とする。
_ = data[features_numerical_w_na].hist(bins=20, figsize=(8,8))
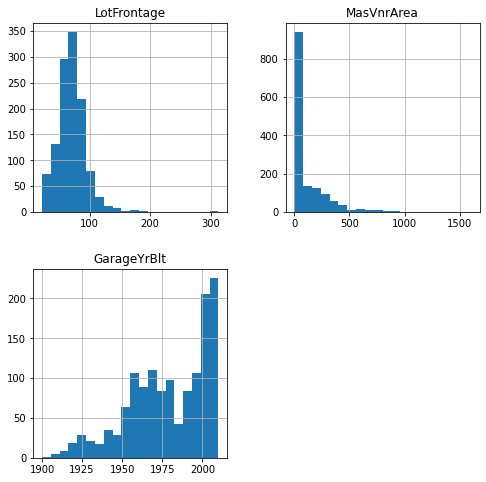
分布から'LotFrontage'は平均値で、その他2つは中央値で置き換えることにする。
3. Imputation
まず、train/testに分ける。
clmns = list(data.columns)
clmns.remove('SalePrice')
print(clmns)
X_train, X_test, y_train, y_test = train_test_split(
data[clmns], # just the features
data['SalePrice'], # the target
test_size=0.3, # the percentage of obs in the test set
random_state=0, # for reproducibility
)
X_train.shape, X_test.shape
['Id', 'MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street', 'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'MasVnrArea', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1', 'BsmtFinType2', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating', 'HeatingQC', 'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual', 'TotRmsAbvGrd', 'Functional', 'Fireplaces', 'FireplaceQu', 'GarageType', 'GarageYrBlt', 'GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual', 'GarageCond', 'PavedDrive', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'PoolQC', 'Fence', 'MiscFeature', 'MiscVal', 'MoSold', 'YrSold', 'SaleType', 'SaleCondition']
((1022, 80), (438, 80))
初めにNaNを含んでいるが置き換えない説明変数almost_naについて新しい説明変数を追加する。
indicator = MissingIndicator(
error_on_new = True, features='missing-only',
)
indicator.fit(X_train[almost_na])
説明変数名は元のそれの末尾に'_NA'を付けたものとする。
indicator_cols = [c+'_NA' for c in almost_na]
indicator_cols
['Alley_NA', 'FireplaceQu_NA', 'PoolQC_NA', 'Fence_NA', 'MiscFeature_NA']
X_train, X_testに適用する。
train_na_arr = indicator.transform(X_train[almost_na])
print(train_na_arr)
test_na_arr = indicator.transform(X_test[almost_na])
print(test_na_arr)
[[ True True True False True]
[ True False True True True]
[ True True True True True]
...
[ True True True True True]
[ True False True True True]
[ True True True True True]]
[[ True False True True True]
[ True False True False True]
[ True False True True True]
...
[ True False True True True]
[ True True True True True]
[ True False True True True]]
このようにindicatorの戻りはnumpy array型になってしまっているので、DataFrame型に変換し元のX_train, X_testに結合する。
X_train = pd.concat([
X_train.reset_index(drop=True),
pd.DataFrame(train_na_arr, columns = indicator_cols)],
axis=1)
X_test = pd.concat([
X_test.reset_index(drop=True),
pd.DataFrame(test_na_arr, columns = indicator_cols)],
axis=1)
X_testで追加されたか列名で確認する。
print(len(X_test.columns), list(X_test.columns))
85 ['Id', 'MSSubClass', 'MSZoning', ..., 'SaleCondition', 'Alley_NA', 'FireplaceQu_NA', 'PoolQC_NA', 'Fence_NA', 'MiscFeature_NA']
最後の処理用に列名を確保
x_clm_lst = list(X_test.columns)
NaNを含む連続値、離散値の置き換えを定義するSimpleImputerと、残りのNaNを含まない説明変数は何もしない('passthrough')ことを明示的に設定する。
SimpleImputerは1種類の置き換えしかできないが、ColumnTransformerに内包させることで複数種類の置き換え(ここでは4つ)が一度に実行できる。
ここで離散値はfeatures_categorical_w_naは前6説明変数を'Missing'に、残りを最頻出の値で置き換えるようにしている。
numeric_features_mean = ['LotFrontage']
numeric_features_median = ['MasVnrArea', 'GarageYrBlt']
preprocessor = ColumnTransformer(transformers=[
('numeric_mean_imputer', SimpleImputer(strategy='mean'), numeric_features_mean),
('numeric_median_imputer', SimpleImputer(strategy='median'), numeric_features_median),
('categoric_constant_imputer', SimpleImputer(strategy='constant', fill_value='Missing'), features_categorical_w_na[:6]),
('categoric_frequent_imputer', SimpleImputer(strategy='most_frequent'), features_categorical_w_na[6:])
], remainder='passthrough')
preprocessor.fit(X_train)
preprocessor.transformers
[('numeric_mean_imputer', SimpleImputer(), ['LotFrontage']),
('numeric_median_imputer',
SimpleImputer(strategy='median'),
['MasVnrArea', 'GarageYrBlt']),
('categoric_constant_imputer',
SimpleImputer(fill_value='Missing', strategy='constant'),
['MasVnrType',
'BsmtQual',
'BsmtCond',
'BsmtExposure',
'BsmtFinType1',
'BsmtFinType2']),
('categoric_frequent_imputer',
SimpleImputer(strategy='most_frequent'),
['Electrical', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'])]
imputerが置き換えようとしている値をPandasで検算してみる。
print(preprocessor.named_transformers_['numeric_mean_imputer'].statistics_)
print(X_train[numeric_features_mean].mean())
print(preprocessor.named_transformers_['numeric_median_imputer'].statistics_)
print(X_train[numeric_features_median].median())
print(preprocessor.named_transformers_['categoric_constant_imputer'].statistics_)
print(X_train[features_categorical_w_na[:6]].mode())
print(preprocessor.named_transformers_['categoric_frequent_imputer'].statistics_)
print(X_train[features_categorical_w_na[6:]].mode())
[69.66866747]
LotFrontage 69.668667
dtype: float64
[ 0. 1979.]
MasVnrArea 0.0
GarageYrBlt 1979.0
dtype: float64
['Missing' 'Missing' 'Missing' 'Missing' 'Missing' 'Missing']
MasVnrType BsmtQual BsmtCond BsmtExposure BsmtFinType1 BsmtFinType2
0 None TA TA No Unf Unf
['SBrkr' 'Attchd' 'Unf' 'TA' 'TA']
Electrical GarageType GarageFinish GarageQual GarageCond
0 SBrkr Attchd Unf TA TA
X_train, X_testに適用する。
X_train = preprocessor.transform(X_train) # ColumnTransformerを使ったので、戻りはnumpy array型になってしまう。
X_test = preprocessor.transform(X_test)
# ColumnTransformerの戻りもnumpy array型になる。
X_train.shape, X_test.shape
((1022, 85), (438, 85))
3. DataFrame化
ここからが少し面倒な処理。
DataFrameに再成形するためには、列名(説明変数名)の順序をX_train,X_testのそれぞれの行列順序と一致させなければならない。
上記の通り、ColumnTransformer()を使用したが、こいつは指定されたSimpleImputer順に処理する。従い列名もその順で作成する必要がある。
最初に置き換え処理をしたので、それらの列名は下記となる。
imputed_features_lst = numeric_features_mean + numeric_features_median + features_categorical_w_na
print(len(imputed_features_lst), imputed_features_lst)
14 ['LotFrontage', 'MasVnrArea', 'GarageYrBlt', 'MasVnrType', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'Electrical', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond']
X_train,X_testのarray行列の列は上記の順になっているからである。
次に、remainder='passthrough'、と指定したので残りのdataに入っていた列が何も置き換え処理されないままX_train,X_testの後半に戻ってきている。その列名は下記で作成できる。
remaining_lst = x_clm_lst.copy()
for i in imputed_features_lst:
remaining_lst.remove(i)
print(len(remaining_lst), remaining_lst)
71 ['Id', 'MSSubClass', 'MSZoning', 'LotArea', 'Street', 'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating', 'HeatingQC', 'CentralAir', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual', 'TotRmsAbvGrd', 'Functional', 'Fireplaces', 'FireplaceQu', 'GarageCars', 'GarageArea', 'PavedDrive', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'PoolQC', 'Fence', 'MiscFeature', 'MiscVal', 'MoSold', 'YrSold', 'SaleType', 'SaleCondition', 'Alley_NA', 'FireplaceQu_NA', 'PoolQC_NA', 'Fence_NA', 'MiscFeature_NA']
14個+71個=85個と思惑通り。
DataFrame化する。
X_train = pd.DataFrame(X_train,
columns=imputed_features_lst + remaining_lst)
X_test = pd.DataFrame(X_test,
columns=imputed_features_lst + remaining_lst)
念の為、csv出力し元csvと比較し中身は正しい順序になっていることは目視で確認した。
正直、ColumnTransformer()には、列名もわかっているはずなのでDataFrame型で出力してほしいところ。
以上