概要
gensimを使った2byte文字のNLPは経験があったが、形態素解析を含む日本語の処理を行ったことがなかったので勉強がてらやってみた。
手頃な文章でgensim使って類似評価なども行いたかったので、「憲法」を使うことにした。
最初は日米比較をしようとしたが、憲法の意味合いが両国で異なるようで面白い結果にならなかったので、現行憲法と明治憲法の新旧比較を行うことにした。
- 実施期間: 2021年7月
- 環境:Ubuntu20.04 LTS
- パケージ:mecab, networkx
- 表示:socnetv
以下の順に備忘録として残す。
- 準備
- 素材
- 前準備
- 形態素解析
- ネットワーク分析
- SocNetVでネットワーク分析
1. 準備
下記をインストールした。
- Mecab: Mecabの本体
- mecab-python3: MecabのPythonパケージ
- 追加辞書(mecab-ipadic-neologd): Mecabの追加辞書
- SocNetV: Social Network Visualizer
詳細は下記を参照
特に引っかかることはなかった。
https://qiita.com/Sak1361/items/47e9ec464ccc770cd65c
https://socnetv.org/docs/index.html#Ubuntu
追加辞書の更新手順は下記
cd mecab-ipadic-neologd
sudo ./bin/install-mecab-ipadic-neologd -n -a
2. 素材
現行憲法については究極超人あ〜る語が散見されたので、下表の置換だけは原文確認しながら手で行った。
さすがのMecabもあ〜る語は処理ができなかった。
コードにすると簡単な置換処理にはなりそうになく、該当箇所も少なく。。。
もっともPythonで複雑な置換処理をする力量がなかったことは秘密なのだ。
| 置換前 | 置換後 |
|---|---|
| やう | よう |
| ふ | う |
| ゐ | い |
| つて | って |
| へ | え |
| ひ | い |
| や | よ |
明治憲法は置換では済まないほど現代人では理解できない文章のため、下記サイトの現代語訳を使用させていただいた。
素晴らしい翻訳だったので、置換は行っていない。
3. 前処理
いつものパケージたちから取捨選択
import re
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
import MeCab
import itertools
from IPython.core.debugger import Pdb
from collections import Counter
ここでは、現行憲法の処理を書いているが、明治憲法もファイルを変更するだけで実行可能
邪魔なキャラクタを削除しながら、doc_lineにドキュメントごとに分割したものを入れる。
なお、一部は下記を参照させて頂いた。
path = 'constitution_jp.txt'
# path = 'constitution_meiji.txt'
doc_line = []
code_regex = re.compile('[\t\s!"#$%&\'\\\\()*+,-./:;;:<=>?@[\\]^_`{|}~○「」「」〔〕“”〈〉'\
'『』【】&*()$#@?!`+¥¥%><0123456789一二三四五六七八九十]')
with open(path) as f:
for s_line in f:
#改行コード(\r\nや\n)だけをまとめて削除
s_line = re.sub(r"[\r\n]", "", s_line)
#改行、タブ、スペースなどをまとめて削除
s_line = re.sub(r"\s", "", s_line)
#いくつかのスペース(例えば全角スペース、半角スペース、タブ)をまとめて削除
s_line = re.sub(r"[\u3000 \t]", "", s_line)
s_line = re.sub(r"[第?章第?条]", "", s_line)
s_line = re.sub(r"[\[?\]]", "", s_line)
s_line = re.sub(r"[0-9]+", "", s_line)
s_line = code_regex.sub('', s_line)
if s_line != '':
doc_line.append(s_line)
doc_lineはこんな感じになる。
['日本国民は,正当に...', '日本国民は...', ..., '...ときは,当然その地位を失う。']]
4. 形態素解析
mecabに上記で取得した全ドキュメントを品詞単位に分割してもらう。
# MeCabで単語に分割する
m = MeCab.Tagger("-Ochasen -r /dev/null \
-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd")
wordcountlist = []
for sentense in doc_line:
mecablist = []
wlist = m.parse(sentense).splitlines() # 結果を単語情報リストのリストに整形する
for u in wlist:
xlist = []
for v in u.split():
xlist.append(v)
mecablist.append(xlist)
# 得られた単語情報リストのリストから、単語の部分だけを取り出したリストを作る
wordbodylist = []
for u in mecablist:
wordbodylist.append(u[0])
# 単語数のリストを作る
wordcountlist.append(len(wordbodylist))
# 文単位で形態素解析し、名詞だけ抽出し、基本形を文ごとのリストにする
sentensemeishilist = [ \
[v.split()[2] for v in m.parse(sentense).splitlines() \
if (len(v.split())>=3 and v.split()[3][:2]=='名詞')] \
for sentense in doc_line]
sentensemeishilistはこんな感じになる。名詞以外は取り除かれている。
[['日本国民', '正当', '選挙', '国会', ...], ['日本国民', '恒久', '平和', ...], ..., [..., '選挙', '任命', 'とき', '地位']]
なお、形態素解析なのでTaggerの引数を
m = MeCab.Tagger("-Ochasen")
とすると、下記リンクを参照させるエラーが発生する。
-rオプションはリソースファイルのパスを指定するもので、上記のコードのとおりでよい。
-dオプションはシステム辞書のパスを指定する。今回は追加辞書を使用するのでそのパスを指定している。
適宜指定すればエラーは出なくなる。
ちなみにGoogle Colaboratoryでも、引数はこの通りで動作した。
5. ネットワーク分析
形態素解析とネットワーク分析については下記テキスト中のコードを一部使用させていただいた。
本書中のサンプルPythonコードは勉強になるところが多い。
ただ章立てや構成がどうもいまいちで全体を通して冗長な感じがする。
Bi-gramを作成する。
doubletslist = [ \
list(itertools.combinations(meishilist,2)) \
for meishilist in sentensemeishilist if len(meishilist) >=2 ]
alldoublets = []
for u in doubletslist: # 文ごとのペアリストのリストをフラットなリストにする
alldoublets.extend(u)
ネットワーク分析用に出現頻度がminfreq以上のBi-gramをnetworkx用に取得する。
minfreq = 4 # グラフ描画のときは4に設定し、見やすくする
# 名詞ペアの頻度を数える
dcnt = Counter(alldoublets)
# 出現頻度順にソートした共起ペアを出力する(上位30ペア)
print('pair frequency', sorted(dcnt.items(), key=lambda x: x[1], \
reverse=True)[:100]) # 頻度順に表示
# 名詞ペアの頻度辞書から、頻度が4以上のエントリだけを抜き出した辞書を作る
restricteddcnt = dict( ( (k, dcnt[k]) for k in dcnt.keys() if dcnt[k]>=minfreq ) )
charedges = restricteddcnt.keys()
vertices = list(set( [v[0] for v in charedges] + [v[1] for v in charedges] ))
# charedgesは(['名詞','名詞'])の形なのでvertid(数字)ペア([1,3])に変換する
edges = [(vertices.index(u[0]), vertices.index(u[1])) for u in charedges]
networkxで描画する。
なお、.draw_circularを.draw_networkxにするとnode間の最短距離で描画される。
G = nx.DiGraph() # 有向グラフ
G.add_edges_from(charedges)
fig = plt.figure(figsize=(24, 24))
# node_shapeのoptionsは、#so^>v<dph8
nx.draw_circular(G, node_shape="o", \
with_labels=True, \
node_color=["y"], \
font_family="Noto Sans CJK JP")
# nx.draw_networkx(G, with_labels=True)
plt.show()
ご覧の通りとても見づらい。
こんなこともあろうと、この後socnetvで描画するためpajek形式でexportする。
(networkxのGML形式だとnodeの名前が文字化けした。)
nx.write_pajek(G, "constitution_jp.net")
# nx.write_pajek(G, "constitution_meiji.net")
最初、**font_family="Noto Sans CJK JP"**がわからずだいぶ調べた。
どの名詞がネットワークで多く参照されているのかdegree centralityで評価してみる。
そのnodeにつながるedge数(degree)が多いほど、ネットワークの中心にいることになることと仮定している。
# Nodeのdegree
lst1 = sorted(G.degree(), key=lambda x: x[1], reverse = True)
print(lst1[:30])
# Nodeのdegree centrality
dic1 = nx.degree_centrality(G)
dic2 = sorted(dic1.items(), key=lambda x:x[1], reverse = True)
print(dic2[:30]) # Top30を表示
# Nodeのeigenvector centrality(おまけ)
# dic1 = nx.eigenvector_centrality(G, max_iter=100)
# dic2 = sorted(dic1.items(), key=lambda x:x[1], reverse = True)
# print(dic2[:30])
Nodeのdegreeは、
[('これ', 76), ('国民', 59), ('こと', 48), ('衆議院', 38), ('憲法', 36), ('国会', 36), ('議決', 36), ('法律', 28), ('とき', 28), ('議員', 20), ('参議院', 17), ('われら', 14), ('地位', 14), ('裁判官', 14), ('両議院', 14), ('平和', 12), ('出席', 12), ('ため', 11), ('権利', 10), ('指名', 10), ('場合', 10), ('行為', 9), ('任命', 9), ('その他', 9), ('中', 9), ('以内', 9), ('報酬', 9), ('内閣', 8), ('すべて', 8), ('日', 8)]
Nodeのdegree centralityは、
[('これ', 0.47500000000000003), ('国民', 0.36875), ('こと', 0.30000000000000004), ('衆議院', 0.23750000000000002), ('憲法', 0.225), ('国会', 0.225), ('議決', 0.225), ('法律', 0.17500000000000002), ('とき', 0.17500000000000002), ('議員', 0.125), ('参議院', 0.10625000000000001), ('われら', 0.08750000000000001), ('地位', 0.08750000000000001), ('裁判官', 0.08750000000000001), ('両議院', 0.08750000000000001), ('平和', 0.07500000000000001), ('出席', 0.07500000000000001), ('ため', 0.06875), ('権利', 0.0625), ('指名', 0.0625), ('場合', 0.0625), ('行為', 0.05625), ('任命', 0.05625), ('その他', 0.05625), ('中', 0.05625), ('以内', 0.05625), ('報酬', 0.05625), ('内閣', 0.05), ('すべて', 0.05), ('日', 0.05)]
代名詞の「これ」が邪魔だけど削除するとskip-gramになりそうなので我慢する。
6. SocNetVでネットワーク分析
ターミナルからsocnetvを起動する。
socnetv
上で書き出した現行憲法のpajekファイルと、別途同じ手順で出力した明治憲法のpajekファイルを開く。
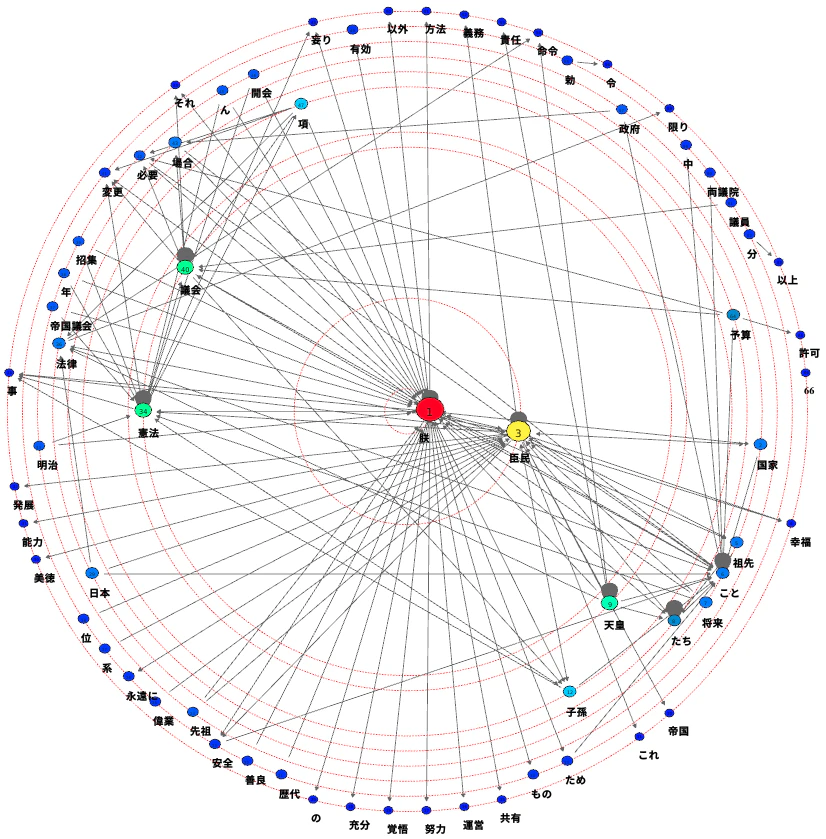
中心がわかりやすくなるように、同じく"Radial by prominence index"の"Degree Centrality"で描いてみる。
中心に近いほど参照される機会が多いことを示し、最外周は一度も参照されなかった単語ということになる。
明治憲法
現行憲法
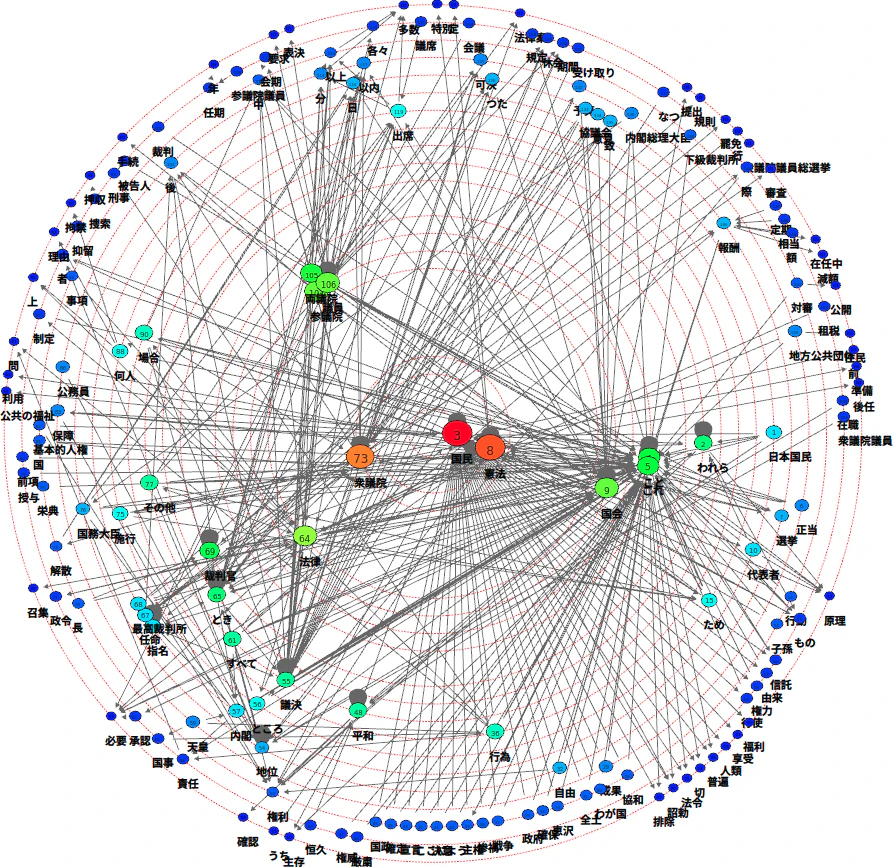
まず、文章の長さがそれぞれで大きく異なるので抽出された文字数に違いがある。
誰もがそう思う通り、明治憲法では中心にいるのが「朕」で寄り添うように「臣民」が位置する。一方現行憲法では主体は当然「国民」であり「憲法」である。「天皇」は左下の方に国事行為関連の単語とつながる程度の位置に追いやられてしまっていることがわかる。
なんとなくこうかなぁ、と漠然としていたイメージを数値やグラフで表現できる点がデータサイエンスの醍醐味である。
SocNetVはdegree centralityの他にも多くの指標が実装されているので、遊んでみることをお勧めする。
以上