概要
よく参考にさせていただいている元Google brainのYouTuberの動画がすごくわかりやすかったので、Wikipediaの例に置き換えて書き残す。
前半はHMM(Hidden Markov Model)をBayes theorem視点から理解し、後半はその行動(observation)が連なったときに使用するcomputational costの低いViterbi algorithmについて理解する。
また最後にpomegranateの使い方も少し残す。
ここで扱うWikipediaの例とは
- Hidden state: rainy, sunny
- Observation: walk, shop, clean
のよくあるHMMである。
またパケージは旧来のHMMlearnではなく、より高機能なpomegranateを使用する。
- 実施期間: 2021年12月
- 環境:Ubuntu20.04LTS
- パケージ:pomegranate
Hidden markov model (HMM)
天気(state)と行動(observation)の遷移について過去統計から確率で図示するところまで説明する。
前提として全stateの遷移は統計的にわかっているものとし、また各stateからemitするobservationも統計的にわかっているものとする。
もちろんここらがわからないといったケースも十分にあり、その場合はforward-backward algorithm(Baum-Welch algorithm)を使用すれば解決可能でありpomegranateではこちらがデフォルトになっている。
過去の統計から天気が下図のように変化することがわかっている。できるだけWikipediaの例になるようにしたので長くなってしまった。

変化は4パターンしかなく、勘定すると下記は容易にわかる。
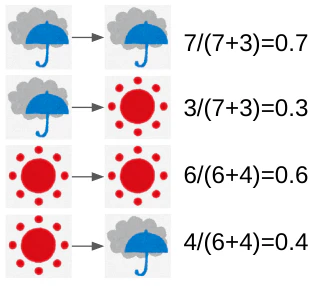
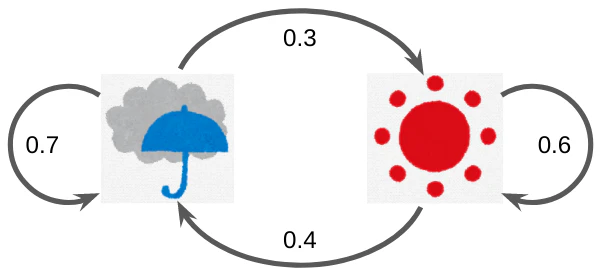
天気、つまりstate(後々hidden state)のtransition probabilityは下図となる。
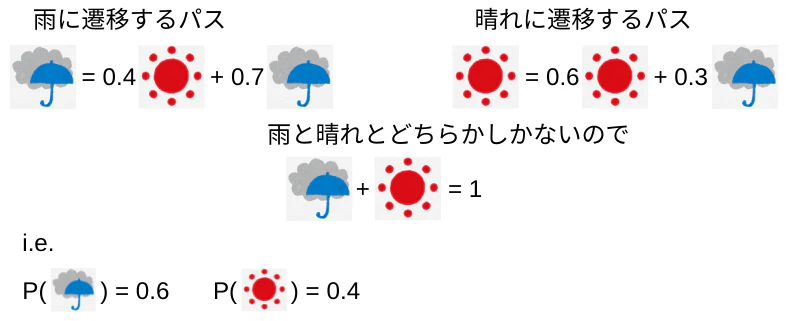
stateの初期状態をprior probability(事前確率)と呼び、次の3式で求めることができる。これで開始stateを確率で表現できる。
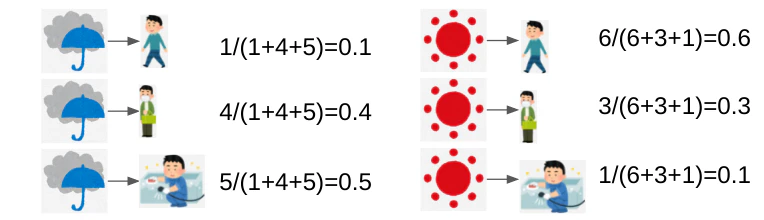
ここからはobservationの発生確率(emission probability)を考える。
stateがきっかけとなるobservationも統計的にわかっている。ここでは、walk, shop, cleanの3行動とする。
emission probabilityも上図を勘定するだけ。
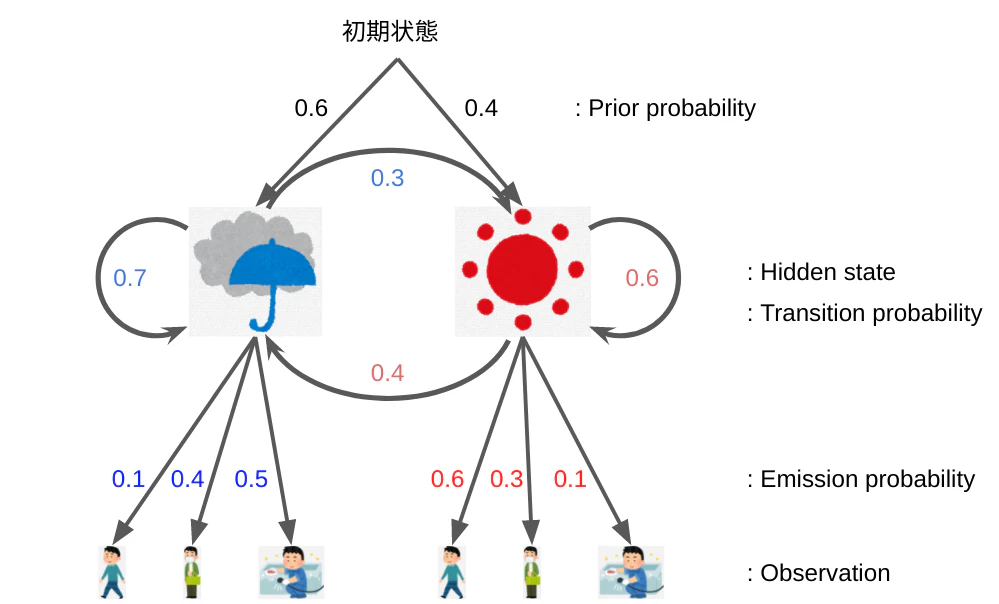
総合的にまとめるとモデルは下図となる。
Bayes theorem視点でHidden stateの推論
上記までで天気->行動を図示したが、ここからは行動変化->天気変化をBayes theoremで推論する。
HMMの本体であり行動が実際にどのように推移したらそのとき天気がどのように推移していたらしいか推論する。stateは不明なのでhidden stateと呼ぶ。
この「推移していたらしい」をposterior probability(事後確率)として求める。
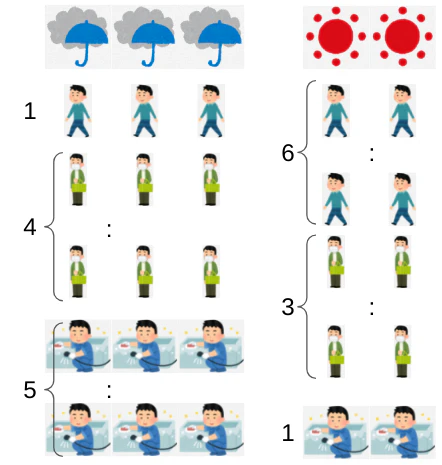
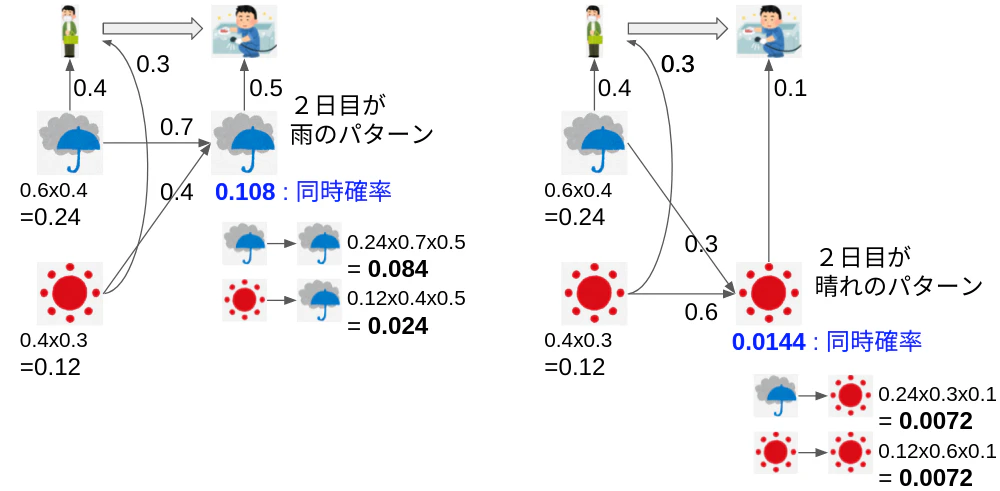
はじめに、observationが変化しないスポットでのhidden stateを推論してみる。
priorはすでにわかっており雨:晴れ=0.6:0.4なので雨3日、晴れ2日の計5日間の行動はモデルより下図となる。
上図より、observationがworkのときのposterior probabilityは
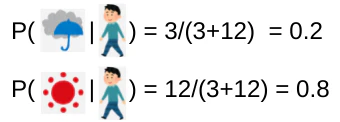
同様にshopとcleanは下記となる。
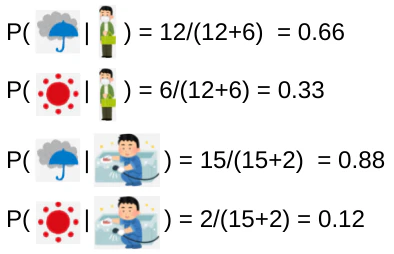
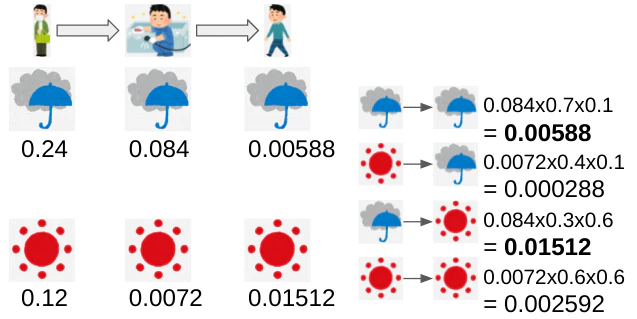
次に2連続変化するobservationから両日のhidden stateを推論してみる。
prior, transition, emissionの各確率を掛けるだけ、つまり下式の積算により最も確率の高いhidden state変化がどれなのかわかる。

月曜火曜の天気の変化は4パターンあるのでモデルは全体で下図の4モデルである。
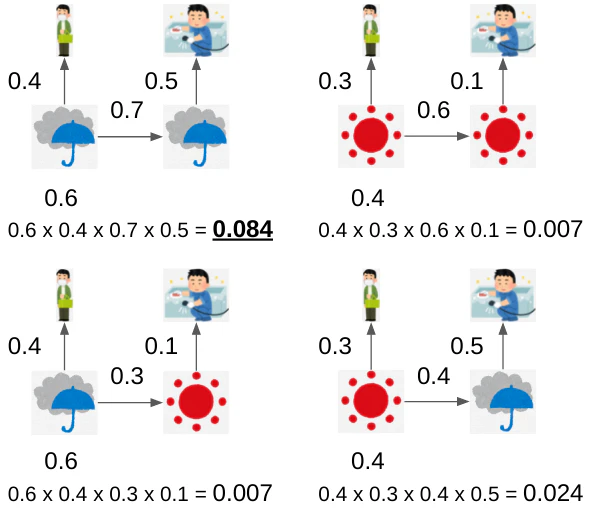
つまりもっともらしいhidden stateの変化は雨->雨であったことがわかる。
2番目、3番目に大きかった確率を気にする必要がなければこのあと説明するViterbi algorithmでhidden stateの遷移は推論することができる。
Viterbi algorithmで推論
hidden state数やobservationの変化数が増えると上述の計算方法では爆発してしまう。2xLxn^L(L:Observation長, n:Hidden state数)
そげなときは最大確率のみに注目するViterbi algorithmをつかうっちゃ。
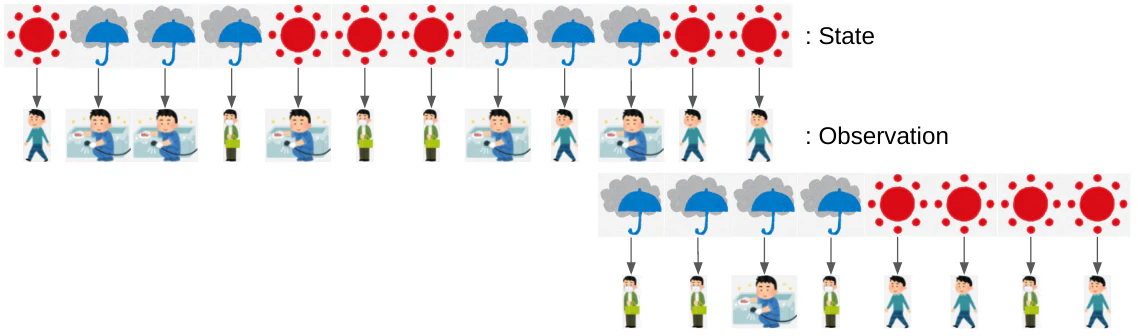
ここでは4日間のobservationからhidden stateを推論してみる。

手順は図示すると簡単で、それぞれの日における各hidden stateのposterior probabilityを計算し、最後にそれら4つの最大値を選ぶだけ。
1,2日目の変化は下図となる。
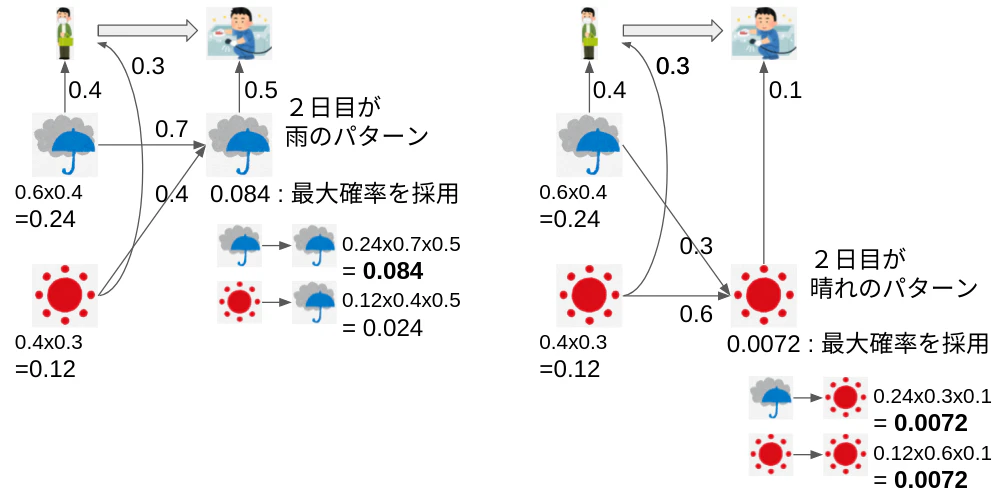
こんな感じに各日、各hidden stateの最大値を書き残していく。
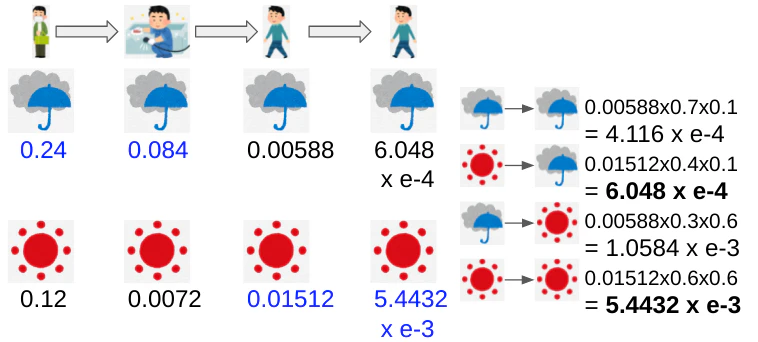
最終的に最大確率(青字)を結べばhidden stateの推論はおわり。

pomegranateで確認
Viterbi algorithm
pomegranateのチュートリアルでは上記で使用したWikipediaの例が使われている。
HMMのモデルを作成する。
from pomegranate import *
import random
import math
random.seed(0)
model = HiddenMarkovModel(name="Rainy-Sunny")
rainyとsunnyのstateを作成する。このときそれぞれのstateからemitされるobservationもそのemission prob.と一緒に辞書型で定義する。
rainy = State(DiscreteDistribution({'walk': 0.1, 'shop': 0.4, 'clean': 0.5}), name='Rainy')
sunny = State(DiscreteDistribution({'walk': 0.6, 'shop': 0.3, 'clean': 0.1}), name='Sunny')
はじめのstateをprior prob.(事前確率)を使ってモデルに定義する。
model.add_transition(model.start, rainy, 0.6)
model.add_transition(model.start, sunny, 0.4)
transition prob.をモデルに定義する。
model.add_transition(rainy, rainy, 0.7)
model.add_transition(rainy, sunny, 0.3)
model.add_transition(sunny, rainy, 0.4)
model.add_transition(sunny, sunny, 0.6)
bake()というコンパイルのようなファイナライズ処理を行いモデルを固める。
model.bake(verbose=True)
# 可読性のため戻り値のmatrixのindexを定義する。
rainy_idx = model.states.index(rainy) # bake後でないとindex()を認識しないから
sunny_idx = model.states.index(sunny)
推論させたい任意のシーケンスを設定する。ここでは手計算した前出のものを使用する。
sequence = [ 'shop', 'clean', 'walk', 'walk']
Viterbi algorithmで推論させる。
print(", ".join(state.name for i, state in model.viterbi(sequence)[1]))
Rainy-Sunny-start, Rainy, Rainy, Sunny, Sunny
手計算通りの結果が得られる。ここではstate.nameで抽出、joinしているが、viterbi()[1]の戻り値は下記であった。
print(model.viterbi(sequence)[1])

同時確率
同時確率(全確率和)による推定であればシーケンス途中の詳細を知ることができる。例えばforward algorithmの場合は下図のイメージに変わる。
naiveに全確率を計算させると爆発するのでforward, backward, forward-backward algorithmといったdynamic algorithmを使用する。詳細はWikipediaにコード付きで解説あり参照のこと。
| Algorithm | Official Docの説明 |
|---|---|
| forward | シーケンスを順方向に進み、各observationが各stateに整列する確率を計算する。全パスの対数確率の合計が出力される。アンダーフローのエラーを防ぐために各行を動的にスケールするため、正規化している。 |
| backward | シーケンスを逆方向に進み、各observationが各stateに整列する確率を計算する。全パスの対数確率の合計が出力される。 |
| forward-backward | emission matrixとtransition matrixを返す。emission matrixは全シーケンスが与えられたとき、各stateがそれらを生成する正規化された確率を返し、transition matrixはあるtransitionが使用される回数の期待値を返す。 |
実際のチュートリアルではモデルのend stateも定義している。end stateがなければ永遠にHMMをぐるぐる回り続けることになり現実的ではないからだろう。雨で終わるtransition prob.と晴れで終わるそれを各0.1と定義する。そのため上で求めた4つのtransition prob.からそれぞれ0.05差し引いている。
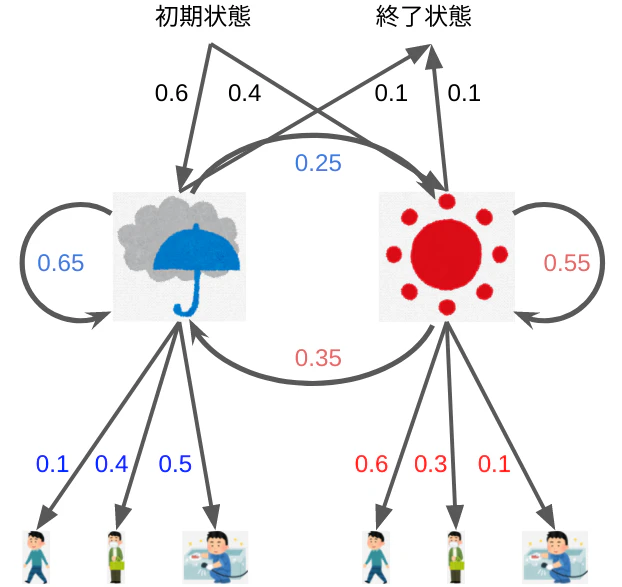
model.add_transition( rainy, rainy, 0.65 )
model.add_transition( rainy, sunny, 0.25 )
model.add_transition( sunny, rainy, 0.35 )
model.add_transition( sunny, sunny, 0.55 )
model.add_transition( rainy, model.end, 0.1 )
model.add_transition( sunny, model.end, 0.1 )
シーケンスが与えられたときの任意のステップが指定するhidden stateである確率は下記で得られる。
print(math.e**model.forward(sequence))

尚、end stateを設定しなければforwardの戻りは下記のようになり手計算と一致する。

行がシーケンスのステップ、列が各hidden stateの確率、最後から2列目は開始確率、最終列が終点確率になっている。従い、例えば最終ステップで晴れになる確率は下記で得られる。
print(math.e**model.forward(sequence)[len(sequence), sunny_idx])
0.007304040000000002
以降、わかりやすくするためにobservationのシーケンスを長くして確認する。Viterbiの結果も併記する。
sequence = [ 'walk', 'shop', 'clean', 'clean', 'walk', 'shop', 'walk', 'shop', 'clean', 'shop', 'clean', 'shop', 'clean', 'shop', 'walk', 'shop' ]
print(", ".join(state.name for i, state in model.viterbi(sequence)[1]))
Rainy-Sunny-start, Sunny, Rainy, Rainy, Rainy, Sunny, Sunny, Sunny, Rainy, Rainy, Rainy, Rainy, Rainy, Rainy, Rainy, Sunny, Sunny, Rainy-Sunny-end
forward-backward algorithmが出力するposterior prob.を確認する。
trans, ems = model.forward_backward(sequence)
# transition matrix
print(math.e**trans)
# emission matrix
print(math.e**ems) # model.predict_proba(sequence)の戻りと同じ
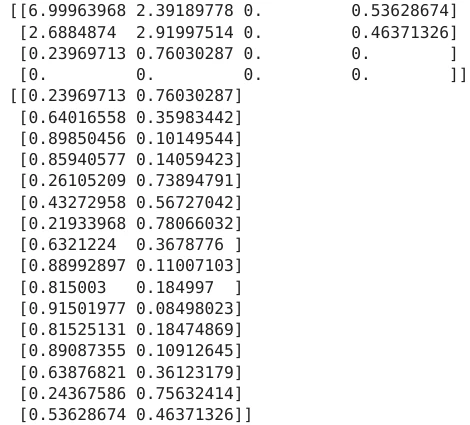
はじめのtransition matrixは下図のような正方行列になっていて、algorithmが推論したstate A -> state Bへの遷移回数が出力されている。
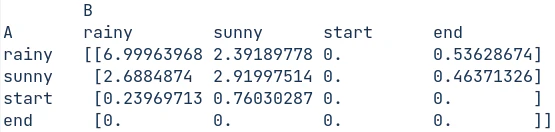
実際にVitabiの結果を数えてみると下図となる。
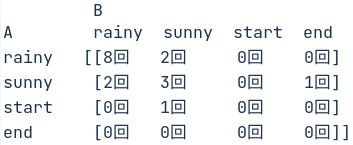
Viterbiは最後のhidden stateはsunnyだが、forwardではややrainyが大きくなっている。
それ以外の大小関係はあっている。3
次のemission matrixは同様に1列目がrainy, 2列目がsunny, 各行が入力observationに対する確率を示している。まとめると下図となり、最終行のend stateへ渡るhidden stateの推論がviterbiと異なっている以外は同じ結果となっている。
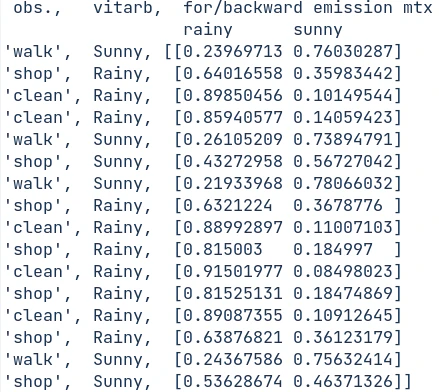
離散値で出力するviterbiよりも、確率で出力してくれるforward-backwardの方が使い勝手が良いだろう。グラフが大きくなったときのcomputational costが気になるところ。
backward algorithmの出力も見ておく。
print(math.e**model.backward(sequence))
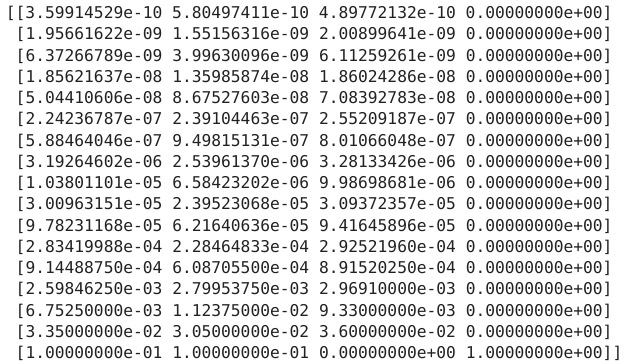
これだけがよくわからなかった。まず全般を通してDocumentには出力されるmatrixをどのように読むのか説明が一切ない。このbackwardは特に情報が少ないので予想になるが、行はシーケンスの終端から遡るので1行目がシーケンスの最後で最終行がシーケンスの先頭なことは間違いない。1,2列目はrainy, sunnyで間違いなく、3列目がend stateで4列目がstart stateになっているようにしか見えない。チュートリアルには各ステップの任意のhidden stateの確率が出力されているとなっているが、どのようにsumをとっても1にならず、本当に確率なのか不明。forward-backwardのためのbackwardなので、単独で使用する機会はないように思う。
forward-backwardが使えれば最強のように思えるが、今後使っていって何かわかったら更新することとする。
最後に最大の事後確率をつないだhidden stateの遷移を出力、というか表示する。確率はすでにforward-backwardで計算済み。
print(" ".join(state.name for i, state in model.maximum_a_posteriori(sequence)[1]))
Sunny Rainy Rainy Rainy Sunny Sunny Sunny Rainy Rainy Rainy Rainy Rainy Rainy Rainy Sunny Rainy
以上