概要
日本には美しい四季があることが自慢らしい。しかし日本は亜熱帯地域にあるため雨季を加えなければならないのではなかろうか。
四季が適当か五季が適当か機械学習で吟味してみる。
クラスタリング手法は多くあるが天気予報を文章と捉えたとき、LDA(Latent Dirichlet Allocation)で納得の行くクラスタ数(季節数)を得ることができるのか。
本当は出力が確率分布なのでクラスタ内の各分布距離を計算しながらクラスタ数の落としどころを探す手法を試したかっただけ。確率分布ではAICやBICが使えないから。
そのときの備忘録
- 実施期間: 2022年6月
- 環境:Ubuntu20.04 LTS
1. パケージ
LDAはgensimではなくscikit learnで作成する。確率分布距離はJensen-Shannon distanceをscipyのAPIで計る。
import numpy as np
import pandas as pd
import statistics
import matplotlib.pyplot as plt
from sklearn.preprocessing import KBinsDiscretizer
from sklearn.preprocessing import LabelEncoder
from scipy.spatial import distance
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.datasets import make_multilabel_classification
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
2. データ
よく利用させていただいている気象庁から、1996年から2011年の東京の気温、湿度、天気(午前・午後)を使用する。DLした元データは下図のような列構成。
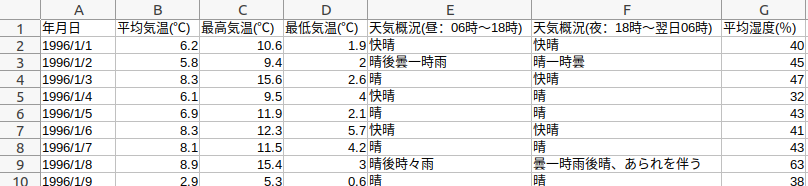
ただし最低最高気温、湿度は使っていない。
数値である気温をラベルに変換するが、北海道でも沖縄でも比較できるように常識的な気温範囲で最初にラベルを作成しておく。
# 平均気温をラベル化
kbd_temp = KBinsDiscretizer(n_bins=16, encode='ordinal', strategy='uniform')
arr_gen = np.arange(-30, 50, 5).reshape(-1, 1) # -30~45℃(常識範囲)の5℃間隔の気温をエンコードしておく
kbd_temp.fit(arr_gen)
arr_gen_t = kbd_temp.transform(arr_gen)
lst_gen_t = list(arr_gen_t.T[0])
str_temp = ['temp{:0=2}'.format(int(i)) for i in lst_gen_t]
dic_temp = {}
for k, v in zip(lst_gen_t, str_temp):
dic_temp[k] = v
print(dic_temp)
1週間分の天気の連結し文章を作成することにする。1月分でも良かったけど四季か五季かの判断には荒すぎるので週とした。
df = pd.read_csv('1996_2010_tokyo.csv')
# 日付の加工
df['date'] = pd.to_datetime(df['年月日'], format='%Y/%m/%d')
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['weekofyear'] = df['date'].dt.isocalendar().week
df['dayofweek'] = df['date'].dt.dayofweek
arr = np.array(df['平均気温(℃)'])
arr = arr.reshape(-1, 1)
lst = list(kbd_temp.transform(arr).T)[0]
df['ave_temp'] = lst
df = df.replace({'ave_temp': dic_temp})
稀にある天気中の「、XXXを伴う」は列に分離する。たぶん使わない。
# 「、〜を伴う」表現を分離
lst = list(df['天気概況(昼:06時~18時)'])
lst2 = []
lst3 = []
for s in lst:
lst1 = s.split('、')
lst2.append(lst1[0])
if len(lst1) == 1:
lst3.append(np.NaN)
else:
lst3.append(lst1[1])
df['noon'] = lst2
df['noon_sub'] = lst3
lst = list(df['天気概況(夜:18時~翌日06時)'])
lst2 = []
lst3 = []
for s in lst:
lst1 = s.split('、')
lst2.append(lst1[0])
if len(lst1) == 1:
lst3.append(np.NaN)
else:
lst3.append(lst1[1])
df['night'] = lst2
df['night_sub'] = lst3
元データはもはや用済みなので列を削除する。
df.drop(columns=['年月日', '平均気温(℃)', '最高気温(℃)', '最低気温(℃)',
'天気概況(昼:06時~18時)', '天気概況(夜:18時~翌日06時)', '平均湿度(%)'],
inplace=True)
こんな感じになる(湿度を示すave_hmdの作成コードは省略)。

各年(1996~2011)で共通するweekofyear(1~52)単位にひっつけて文章化する。
lst_all = []
for int_year in range(1996, 2011):
for int_week in range(1, 53):
arr = df[(df['year'] == int_year) & (df['weekofyear'] == int_week)][['ave_temp', 'noon', 'night']].to_numpy()
arr = arr.flatten()
lst_all.append((int_year, int_week, list(arr)))
print(lst_all)
docs_lst = []
for i in range(len(lst_all)):
doc = (" ".join(lst_all[i][2]))
docs_lst.append(doc)
print(docs_lst)
3. LDA
corpusを通して単語に重みをつけたいのでtf-idf処理を行い全文章をLDAモデル用に加工してもらう。
ここでは、下表としている。
| 引数 | 設定 | 意味 |
|---|---|---|
| max_df | 0.6 | corpusを通して60%以上のDocsに出現した単語は無視 |
| min_df | 1 | corpusを通して1回以上出現した単語を使う(つまり全部) |
tfidf_vectorizer = TfidfVectorizer(max_df = 0.6, min_df = 1).fit(docs_lst)
X = tfidf_vectorizer.fit_transform(docs_lst)
print(len(tfidf_vectorizer.get_feature_names_out())) # 使用する単語数
tf-idf処理しないのであれば下記となる。
tf_vectorizer = CountVectorizer(max_df=0.6, min_df=1) # , stop_words='english'
X = tf_vectorizer.fit_transform(docs_lst)
まず、クラスタ数を4と指定してモデル作成する。以降、クラスタ数の指定を変えたいときはこのセル移行を繰り返すだけ。
ただしVectorizerでTransformした文章はscipyのsparce matrix型に圧縮されていて、このままではクラスタリング結果と文章が紐付かない。各文書のクラスタリング結果が知りたいので、個別(x1)にモデルに入力しクラスタリングしてもらう。
topic_num = 4
lda = LatentDirichletAllocation(n_components=topic_num, random_state=44)
lda.fit(X)
DPD_lst = []
for i in range(len(docs_lst)):
x1 = tfidf_vectorizer.transform([docs_lst[i]])
wkarr = lda.transform(x1) # 全DocのDirichlet P.D.
DPD_lst.append(wkarr[0])
結果を距離計算用に辞書型、描画用にDataFrameにそれぞれ入れる。
LDAはgensimでも苦労したが、random seed(random_state)次第でクラスタリング結果が大きく異なる。今回も全く使用されないクラスタがあったりした。下記コード中段の「使われていないクラスタ」を確認しながらrandom_stateを調整する必要あり。
dic = {}
for t in range(topic_num):
dic[t] = []
idx_4_df = []
for i in range(len(docs_lst)):
max = DPD_lst[i].max()
idx = np.where(DPD_lst[i]==max)[0][0] # 最も確率の高いTopic番号
idx_4_df.append(idx)
wklst = list(DPD_lst[i])
dic[idx].append((wklst, lst_all[i][0], lst_all[i][1], docs_lst[i])) # クラスタごとに辞書型に登録・振り分ける
# 全文章が各クラスタに分類され、使われていないクラスタがないか確認する。
for i in range(topic_num):
print(len(dic[i]))
# 結果用のDataFrameに入れる。
df_week = pd.DataFrame(columns=['year', 'week', 'doc', 'Topic_4'])
df_week['year'] = [lst_all[i][0] for i in range(len(lst_all))]
df_week['week'] = [lst_all[i][1] for i in range(len(lst_all))]
df_week['doc'] = docs_lst
df_week['Topic_4'] = idx_4_df

4. 結果
4クラスタに分けたときの8年分を描画する。
fig, axes = plt.subplots(nrows=2, ncols=4, figsize=(16, 8))
plt.subplots_adjust(wspace=0.2, hspace=0.4)
_ = df_week[df_week['year']==1996].plot.line(ax=axes[0, 0], x='week', y='Topic_5', legend=False)
_ = df_week[df_week['year']==1998].plot.line(ax=axes[0, 1], x='week', y='Topic_5', legend=False)
_ = df_week[df_week['year']==2000].plot.line(ax=axes[0, 2], x='week', y='Topic_5', legend=False)
_ = df_week[df_week['year']==2002].plot.line(ax=axes[0, 3], x='week', y='Topic_5', legend=False)
_ = df_week[df_week['year']==2004].plot.line(ax=axes[1, 0], x='week', y='Topic_5', legend=False)
_ = df_week[df_week['year']==2006].plot.line(ax=axes[1, 1], x='week', y='Topic_5', legend=False)
_ = df_week[df_week['year']==2008].plot.line(ax=axes[1, 2], x='week', y='Topic_5', legend=False)
_ = df_week[df_week['year']==2010].plot.line(ax=axes[1, 3], x='week', y='Topic_5', legend=False)
_ = axes[0, 0].set_title('1996')
_ = axes[0, 1].set_title('1998')
_ = axes[0, 2].set_title('2000')
_ = axes[0, 3].set_title('2002')
_ = axes[1, 0].set_title('2004')
_ = axes[1, 1].set_title('2006')
_ = axes[1, 2].set_title('2008')
_ = axes[1, 3].set_title('2010')
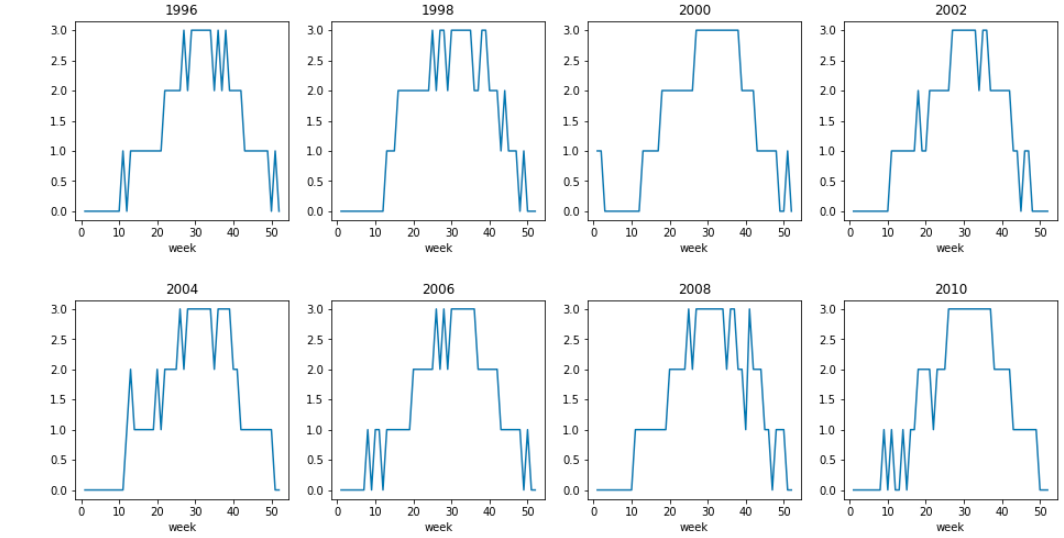
各年でクラスタの周期性がいい感じに確認できる。
なお、week番号の例は下表を参照のこと。

このときの各クラスタ内における文章ごとの確率分布間距離を総当りで計測し、その平均と標準偏差を求めた。
# 各TopicのDocにDPDのJS distanceを求め、距離平均と距離分散を求める
for t in range(topic_num):
wklst = [lst[0] for lst in dic[t]]
lst = [distance.jensenshannon(wklst[i], wklst[j])
for i in range(len(wklst)) for j in range(len(wklst))]
mean = statistics.mean(lst)
variance = statistics.variance(lst)
print('Topic{0}: mean= {1:.=5f}, var= {2:.=5f}'.format(t, mean, variance))
Topic0: mean= 0.088855, var= 0.006966
Topic1: mean= 0.088448, var= 0.009019
Topic2: mean= 0.106807, var= 0.009180
Topic3: mean= 0.066505, var= 0.006333
これはクラスタ数=5の結果と比較しなければなんとも言えない。
上記コードの、topic_num = 4を 5 に変更し同じことを繰り返した。結果のみ掲載する。
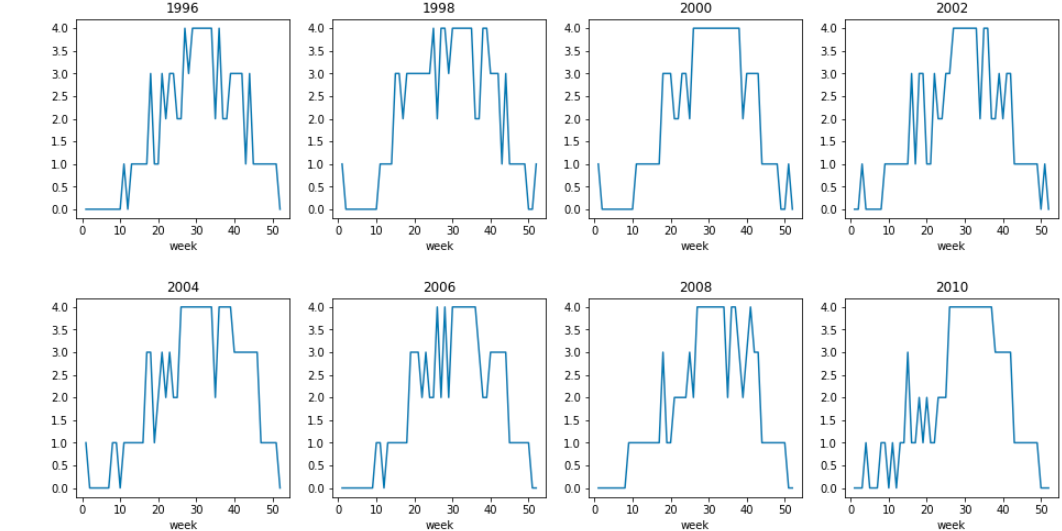
Topic0: mean= 0.108933, var= 0.011089
Topic1: mean= 0.114480, var= 0.010725
Topic2: mean= 0.094230, var= 0.008058
Topic3: mean= 0.069156, var= 0.007768
Topic4: mean= 0.069275, var= 0.007219
距離の平均は分布数が4vs5と異なるのでそもそも比較のできないと思う。
ただ標準偏差はクラスタ数=4のときのほうが全般に小さいので確率分布がクラスタ内で集約されているといって良いのではなかろうか。
つまり2011年以前において、日本には美しい四季があったと言えよう、ML的に。
以上