はじめに
データ分析技術を学習する中で、自然言語解析(NLP)がさまざまな分野や現場で幅広く活用されていることを知りました。
顧客のフィードバック分析、ソーシャルメディアのトレンド調査、カスタマーサポートの自動化など、自然言語解析が持つ可能性は広い分野で活用され、業務効率化や意思決定の支援に大きく寄与しています。
AWSの数あるサービスの中でも自然言語処理で使用されているサービスがAmazon Comprehendです。
これは、AWSが提供する自然言語処理サービスで、キーフレーズ抽出や感情分析、エンティティ認識など、多様な解析機能を備えています。
今回の記事では、このAmazon Comprehendを用いて、基本的な特徴や使い方の理解を深めたいと思います。
Amazon Comprehendとは
Amazon Comprehendは、AWSが提供するフルマネージドの自然言語処理(NLP)サービスです。
このサービスは、テキストデータから有益な情報を自動的に抽出し、顧客対応の改善やコンテンツの分類など、様々な場面で活用できます。
以下に、主要な機能とその料金体系について詳しく説明します。
自然言語処理
機能
-
キーフレーズ抽出
テキストから重要なフレーズや単語を自動的に抽出し、文章の主なトピックを特定します。 -
感情分析
テキストがポジティブ、ネガティブ、ニュートラルのどの感情を表しているかを解析します。 -
エンティティ認識
テキスト中の固有名詞(例えば、人物名、場所、組織名など)を特定し、これらを分類します。 -
言語識別
複数の言語で書かれたテキストの言語を自動的に判別します。 -
文書分類
テキストをあらかじめ定義されたカテゴリに分類します。
料金
-
料金
100文字を1ユニットとして計算、各リクエストにつき3ユニット (300文字) からの料金が発生し、以降は使用量に応じて課金されます。
個人識別情報 (PII)
機能
-
Detect PII API
ドキュメント内の個人識別情報 (PII) エンティティの位置を特定し、PIIが除去されたドキュメントを生成するために使用されます。
料金
-
料金
100文字を1ユニットとして計算、各リクエストにつき3ユニット (300文字) からの料金が発生し、以降は使用量に応じて課金されます。
カスタム Comprehend
機能
-
カスタム分類とエンティティ API
カスタマイズした自然言語処理モデルをトレーニングすることで、特定のビジネスニーズに応じたテキストの分類やカスタムエンティティの抽出が可能です。
料金
-
非同期推論リクエスト
100文字を1ユニットとして計算、各リクエストにつき3ユニット (300文字) からの料金が発生し、以降は使用量に応じて課金されます。 -
モデルトレーニング
1時間に3 USD (秒単位で請求) -
カスタムモデル管理
1か月に0.50 USD -
同期推論リクエスト
エンドポイントのスループットに基づき課金
トピックモデリング
機能
-
トピックモデリング
Amazon S3に保存された複数のドキュメントから、関連するトピックを抽出し、グループ化します。
各ドキュメントがどのトピックに属するかを整理して表示します。
料金
-
料金
最初の100 MBは均一料金、100 MBを超える部分は1 MBごとに課金されます。
信頼と安全 (新規)
機能
-
毒性検出 API
テキスト内の有害なコンテンツを検出します。 -
プロンプト安全性分類機能
大規模な言語モデルやアプリケーションに対して、安全でない入力プロンプトを検出します。
料金
-
料金
100文字を1ユニットとして計算、各リクエストにつき3ユニット (300文字) からの料金が発生し、以降は使用量に応じて課金されます。
実際にやってみる
簡単に実行ができる「Real-time Analysis」と「Analysis job(job形式での分析)」を用いて分析を行い、使用方法を学んでいきたいと思います。
「Launch Amazon Comprehend」を押して、始めます。

1. Real-time Analysis
最初は、「Real-time Analysis」を使用し、分析を行います。
「Real-time Analysis」を選択します。
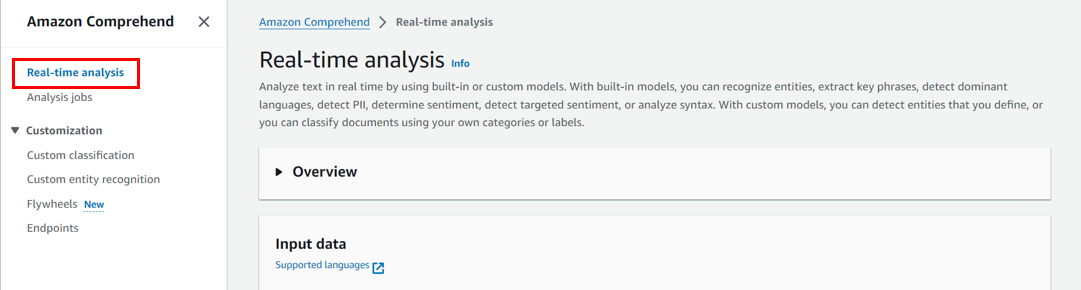
「Analysis type」は、Built-inを選択します。
「Input text」にデフォルトの文字が入っているので、削除します。

削除したら、分析したいテキストを入力します。
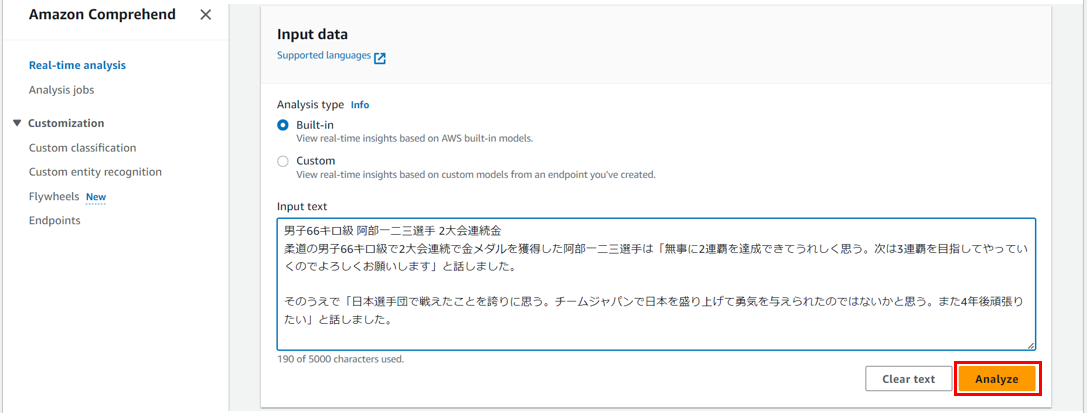
今回は、オリンピックのインタビュー記事の一部を使用します。
男子66キロ級 阿部一二三選手 2大会連続金
柔道の男子66キロ級で2大会連続で金メダルを獲得した阿部一二三選手は「無事に2連覇を達成できてうれしく思う。
次は3連覇を目指してやっていくのでよろしくお願いします」と話しました。
そのうえで「日本選手団で戦えたことを誇りに思う。チームジャパンで日本を盛り上げて勇気を与えられたのではないかと思う。また4年後頑張りたい」と話しました。[1]
「Analyze」を押して、分析を開始します。
「Entities」を押し、Entityの結果を確認します。

各単語のTypeとConfidenceの分析結果が確認できました。

「Sentiment」を押し、Sentimentの結果を確認します。

テキストのSentimentの分析結果が確認でき、テキストの内容がポジティブであることがわかりました。

続いて、他のテキストだと結果に違いが出るのかを確認します。
比較対象として、台風に関する記事の一部を使用し、同様の手順で分析します。
今日18日は関東甲信から九州は大気の状態が非常に不安定です。
関東甲信や九州を中心に発雷確率が高く、所々で雨や雷雨になりそうです。
局地的には滝のような非常に激しい雨が降るでしょう。
天気の急変にご注意ください。[2]
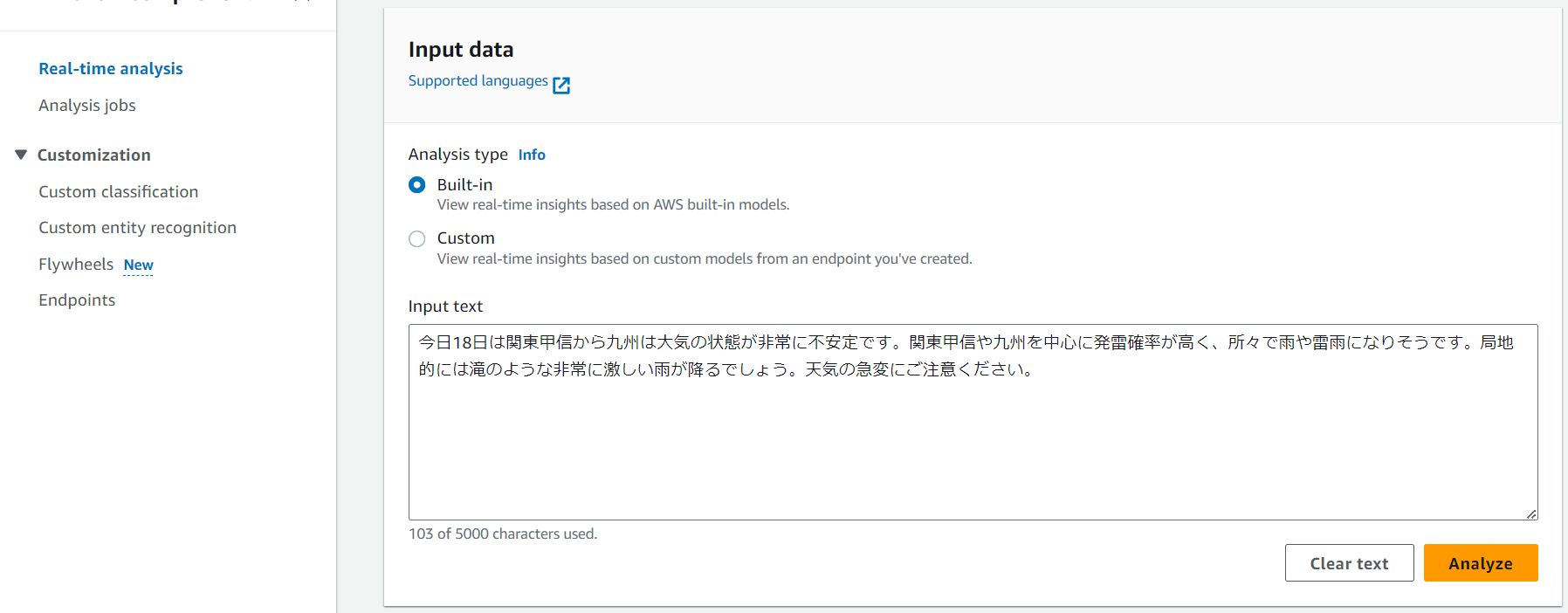



こちらの分析結果では、先ほどの結果とは異なり、テキスト内容に少しネガティブな要素があることを示しています。
このように「Real-time Analysis」を使用すると、コンソール上に分析したいテキストを入力するだけで簡単に分析することができます。
2. Analysis job(job形式での分析)
次に、「Analysis job」を使用し、分析を行います
テキストは、先程使用したオリンピックインタビュー記事を使用します。
最初にS3でバケットを作成します。(リージョンは任意の場所を選択してください)
「バケットを作成」を押します。
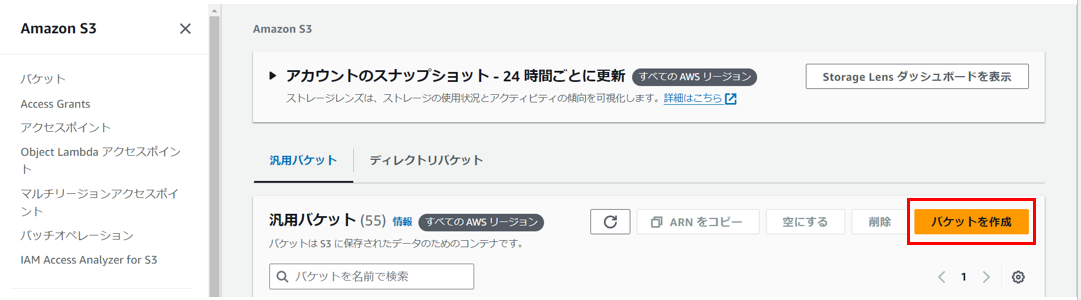
バケットタイプは、デフォルトで選択されている「汎用」を選択してください。
バケット名は任意のものを入力してください。

その他の設定は、全てデフォルトで選択されているものを選択してください。

「バケットを作成」を押して、バケットを作成します。

バケットの作成が完了したら、分析したいテキストファイルをアップロードします。
今回は、先ほど使用したインタビュー記事を使用します。
男子66キロ級 阿部一二三選手 2大会連続金
柔道の男子66キロ級で2大会連続で金メダルを獲得した阿部一二三選手は「無事に2連覇を達成できてうれしく思う。
次は3連覇を目指してやっていくのでよろしくお願いします」と話しました。
そのうえで「日本選手団で戦えたことを誇りに思う。チームジャパンで日本を盛り上げて勇気を与えられたのではないかと思う。また4年後頑張りたい」と話しました。[1]
「アップロード」を押します。

ComprehendのAnalys jobsの画面へ戻り「create job」をクリックし、jobを作成

「Name」に任意の文字を入力します。
感情分析を行うので、「Analysis type」は、Sentimentを選択します。
日本語のテキストを分析するので、「Language」は、Japaneseを選択します。

「Input data」は、先ほどアップロードしたバケットのファイルを選択します。
一行ごとの分析を行いたいので、「One document per line」を選択します。

「Output data」も先程作成したS3バケットを選択します。
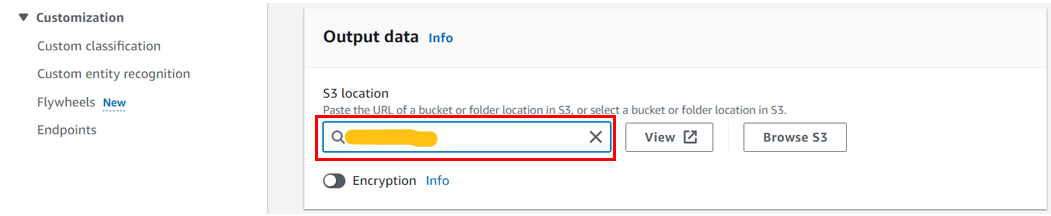
「IAM role」は、Create an IAM roleを選択し、新規でIAMロールを作成します。
同じS3バケットに結果を保存したいので、「Permissions to access」は、Input and Output S3 bucketsを選択します。
「Name suffix」は、任意のものを入力します。

「VPC settings」と「Tag」は、デフォルトで設定されているものを選択します。
「Create job」を押します。
実行が完了したら、S3のバケット画面に戻り、分析結果のフォルダを選択します。
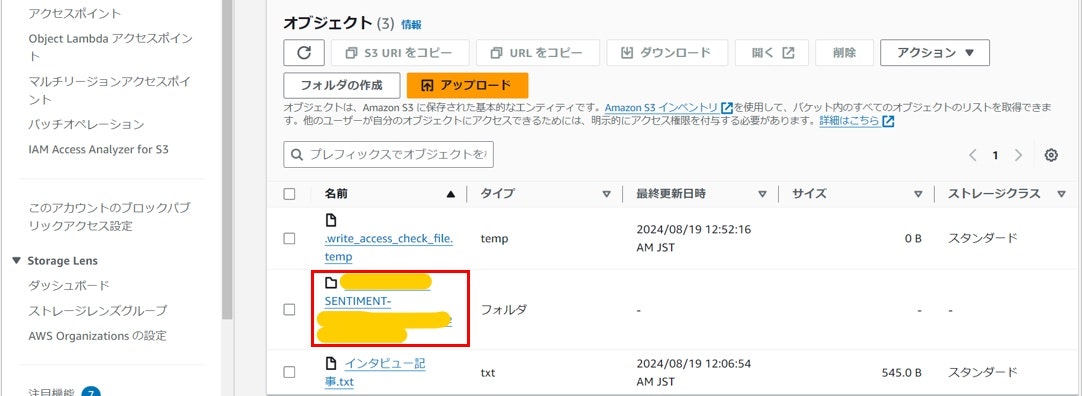
「output/」を選択します。

「output_tar.gz」を選択します。
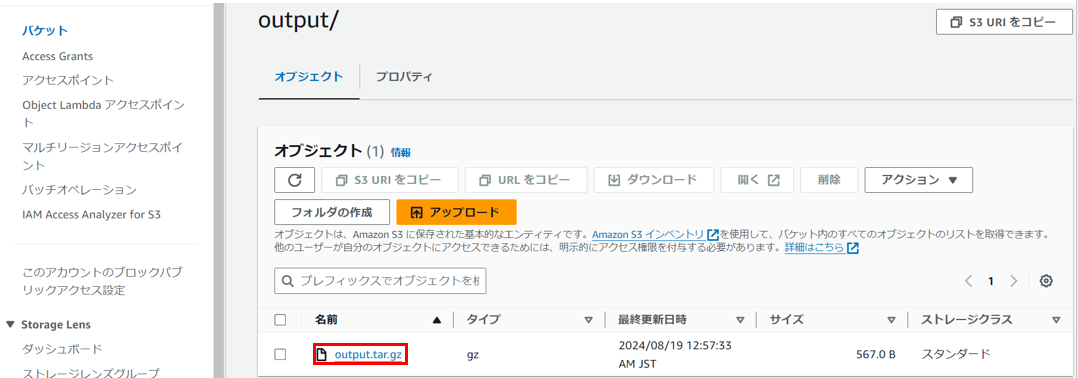
「ダウンロード」を選択して、分析結果のファイルをダウンロードします。

ダウンロードしたファイルをテキストエディタで確認します。

テキストの各行に対する、感情分析結果を確認できました。
1・4行目はニュートラル、2・3行目はポジティブであることを示しています。
このようにS3上のデータを取り扱うことで、他のサービスに渡しやすい形式で結果を出力することができます。
考察
「Real-time Analysis」と「Analysis Job」が、他のAWSサービスとどのように連携できるか考察します。
-
Real-time AnalysisとLambdaの連携
今回の記事では、Amazon Comprehendの「Real-time Analysis」機能をコンソール上で実行しました。
しかし、コンソール上で実行する場合、テキストを手動で入力する必要があり、また出力された分析結果もコンソール上に表示されるため、分析結果を他のシステムやプロセスで活用することは難しいと思われます。
そのため、実際にサービスとして利用する場合には、APIを使用することが多くなると考えられます。
利用方法としては、AWS Lambdaと組み合わせることでのリアルタイム解析の提供が考えられます。
これにより、手動入力の手間を省き、分析結果を他のシステムやプロセスで即座に活用することが容易になります。 -
Analysis JobとAmazon S3の連携
Real-time Analysisでは、データが入力されるたびに即座に解析結果が出力されますが、AnalysisJobはS3に解析結果を保存することができるため、大量のテキストデータの解析を行い、解析結果を集積するような用途に向いていると感じました。
利用方法としては、S3へのアップロードをトリガーに、LambdaからAnalysisJobのAPIを実行し、解析結果をS3に集積するようなシステムの構築が考えられます。
これにより、後から解析結果を再利用したり、長期間にわたってデータを保存・管理することが容易になります。
このように、他のAWSサービスと連携することで、さまざまなビジネスニーズに対応する柔軟なテキスト解析が可能になると考えられます。
まとめ
今回の記事では、Amazon Comprehendを利用した自然言語解析の基本的な知識や使い方を学習しました。
Amazon Comprehendを使用することで、感情分析などを簡単に実行できることを実感しました。
今後は、Amazon Comprehendを他のAWSサービスと組み合わせることで、より一層効果的なデータ分析環境を構築し、業務における自然言語解析の活用の理解をさらに深めていきたいと考えています。
この記事が、自然言語解析に興味を持つ方にとって、Amazon Comprehendを使った自然言語解析(NLP)の入門として役立つと幸いです。
備考
「Analysis job」で作成したジョブを削除できないため、AWSカスタマーサポートに問い合わせたところ、現時点では削除機能が実装されていないとの回答を受けました。
(2024年8月21日)
引用
[1]"パリオリンピック 日本選手団が会見【詳しく】選手たちの声は 【柔道】", NHK NEWSWEB , 2024年8月14日,
https://www3.nhk.or.jp/news/html/20240814/k10014548571000.html ,(アクセス日:2024年8月29日)
[2]吉田友海 , "関東甲信や九州を中心に急な雷雨や滝のような雨に注意 明日も大気の状態が不安定" , 日本気象協会 tenki.jp , 2024年8月18日,
https://tenki.jp/forecaster/t_yoshida/2024/08/18/30142.html ,(アクセス日:2024年8月29日)
参考サイト
・Amazon Comprehend公式チュートリアル
・Amazon Comprehend の特徴
・Amazon Comprehend の料金