この記事はZOZOテクノロジーズ #2 Advent Calendar 2019 24日目の記事になります。
昨日は、@tsurumiiiさんの「変更データ(CDC)を利用したデータ同期検討」でした。
また、今年は全部で5つのAdvent Calendarが公開されています。
ZOZOテクノロジーズ #1 Advent Calendar 2019
ZOZOテクノロジーズ #2 Advent Calendar 2019
ZOZOテクノロジーズ #3 Advent Calendar 2019
ZOZOテクノロジーズ #4 Advent Calendar 2019
ZOZOテクノロジーズ #5 Advent Calendar 2019
はじめに
本記事は@gold-kouさんのECS+Fargateの環境でgRPCサーバのヘルスチェックをするために色々頑張った話で紹介されているgRPCヘルスチェックのインフラ面の設定の話になります。
前提やこの構成に至った背景については上記の記事に丁寧にまとめられておりますのでご確認いただければと思います。
構成
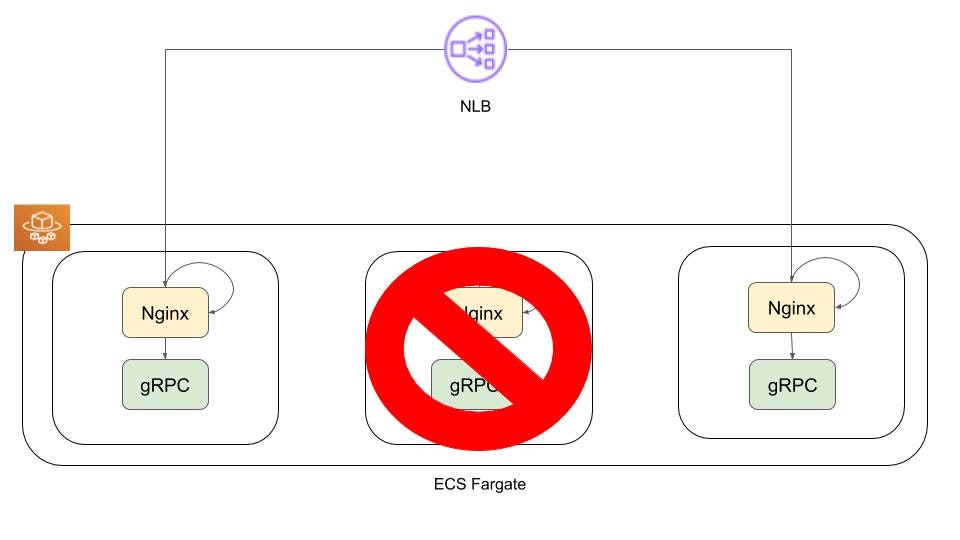
タイトルの通りですが、NLBとECS Fargateの構成となっており、FargateのタスクではNginxとgRPCアプリケーションが稼働する構成となっております。
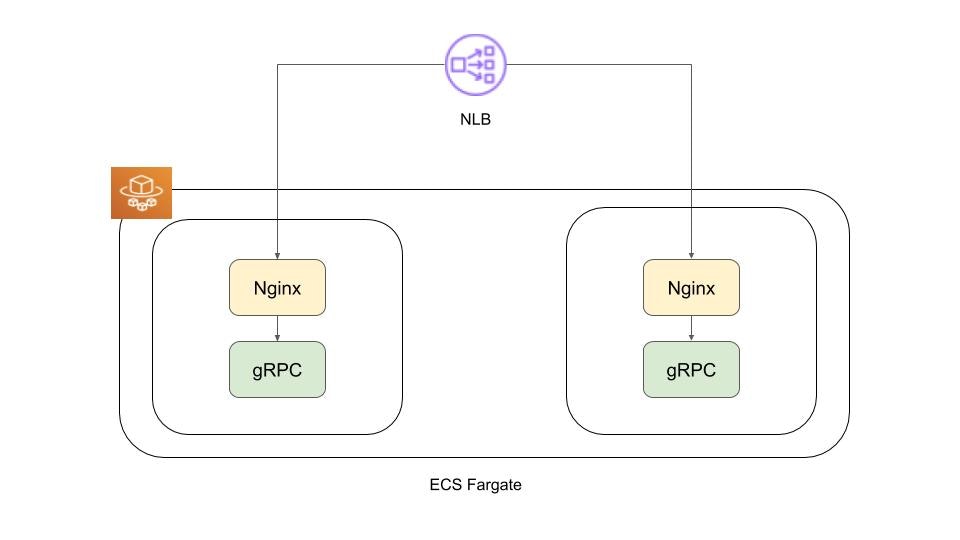
今回は内部通信の要件だったため、平文で通信しています。HTTP/2でTLS終端しようとすると、NLBはALPNに対応していないため問題となりうるのですが、今回は平文通信のためこの問題は回避できました。
ヘルスチェック問題
この構成で問題となるのがヘルスチェックです。
今回は平文のgRPCを採用しているためターゲットグループのプロトコルはTCPを選択する必要があるのですが、この場合、ヘルスチェックで使用できるオプションは、TCP、HTTP、HTTPSの三つのみです。HTTP、HTTPSはgRPCメソッドを呼び出すことはできず、TCPはポート監視のみとなり、アプリケーションの死活監視を行うことができません。
ECSのHEALTHCHECK機能
上記の問題があることから、ECSのHEALTHCHECK機能を利用して、ヘルスチェックを行うことにしました。
Nginxコンテナ内にgrpc-health-probeをインストールし、ECSのHEALTHCHECK機能でNginxコンテナからgrpc-health-probeを実行するようにしました。
CFnで設定する場合は以下のようになります。
ECSTaskDefinition:
Type: 'AWS::ECS::TaskDefinition'
Properties:
Family: !Sub ${Prefix}-${Environment}
RequiresCompatibilities:
- 'FARGATE'
Cpu: 1024
Memory: 2048
NetworkMode: 'awsvpc'
ExecutionRoleArn: !GetAtt IAMRoleECSTaskExecution.Arn
TaskRoleArn: !GetAtt IAMRoleAPI.Arn
ContainerDefinitions:
- Image: !Sub ${AWS::AccountId}.dkr.ecr.${AWS::Region}.amazonaws.com/${ECRRepositoryNginx}:latest
Name: 'nginx'
Cpu: 256
MemoryReservation: 512
PortMappings:
- ContainerPort: 10080
HostPort: 10080
Protocol: 'tcp'
# ここがHealthCheckの設定。指定したbashコマンドを実行できる。
HealthCheck:
Command:
- 'CMD-SHELL'
- 'grpc-health-probe -addr=localhost:10080 -rpc-timeout 2s'
Interval: 5
Retries: 2
StartPeriod: 10
Timeout: 3
LogConfiguration:
LogDriver: 'awslogs'
Options:
awslogs-group: !Sub /ecs/${ECRRepositoryNginx}
awslogs-region: !Ref AWS::Region
awslogs-stream-prefix: 'ecs'
awslogs-create-group: true
- Image: !Sub ${AWS::AccountId}.dkr.ecr.${AWS::Region}.amazonaws.com/${ECRRepositorygRPC}:latest
Name: 'grpc'
Cpu: 256
MemoryReservation: 512
PortMappings:
- ContainerPort: 8080
HostPort: 8080
Protocol: 'tcp'
LogConfiguration:
LogDriver: 'awslogs'
Options:
awslogs-group: !Sub /ecs/${ECRRepositorygRPC}
awslogs-region: !Ref AWS::Region
awslogs-stream-prefix: 'ecs'
awslogs-create-group: true
Essential: true
Environment:
- Name: 'AWS_DEFAULT_REGION'
Value: !Ref AWS::Region
この機能とNLBのTCPポート監視を組み合わせることで、異常のあるタスクがNLBから適切に切り離される挙動になることを期待しました。
実際の挙動
実際に検証してみたところ、想定通りに動きました。
ヘルスチェックの失敗からタスクのリタイアまでの流れとしては以下のようになります。
1. gRPCアプリケーションが応答不可状態に陥る
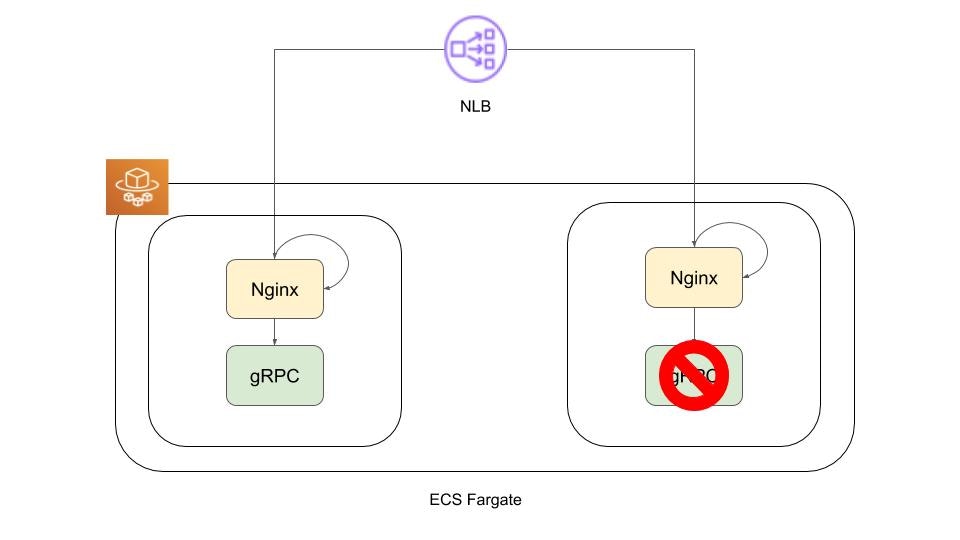
2. Nginxコンテナから実行されているヘルスチェックに失敗し、該当のタスクがUnhealthy状態になる
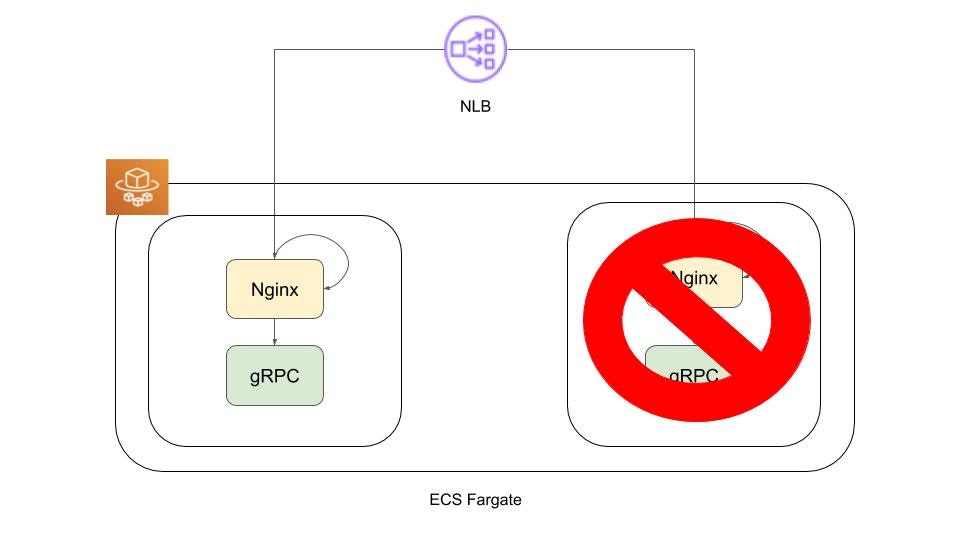
3. NLBのTCPポートヘルスチェックに失敗し、Unhealthyのタスクが切り離される
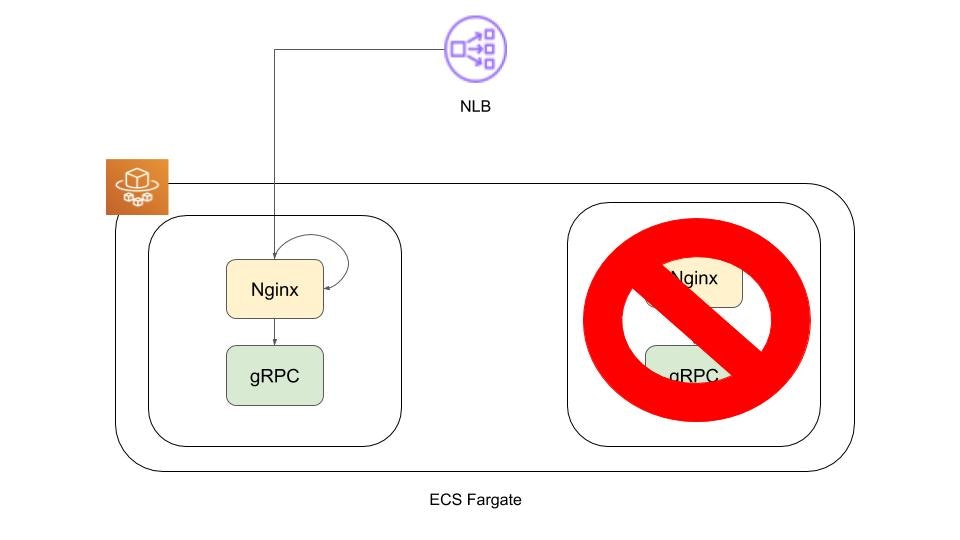
4. リタイアしたタスクに代わり、新規のタスクが起動する
さいごに
少々苦戦しましたが、結果的にヘルスチェックを設定することができました。一つ機能が足りていなくても他の機能で補填でき、工夫すればなんとかなる点にはAWSにありがたみを感じています。
ただ、AWSでgRPCを使う場合は、まだまだ機能が揃ってないと感じるケースが少なからずあるので、もう少し機能が充実してくるとありがたいなと思いました。
当記事の内容としては以上となります!
25日間に渡るアドベントカレンダーも明日で最後となります!!
弊社ではアドベントカレンダーが第5弾まであるので、5 * 25(日間)で全125記事となります。
是非とも他の記事にも目を通していただけますと幸いです!